


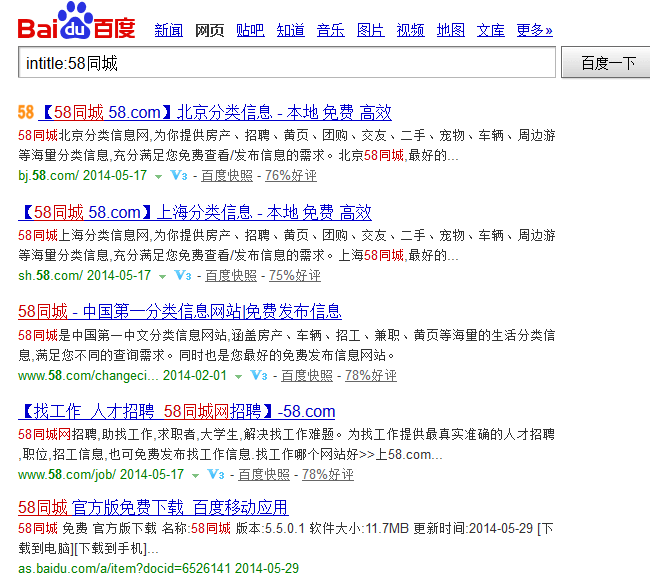
比如,你想采集标题中包含“58同城”的SERP结果,并过滤包含有“北京”或“厦门”等结果数据。
该Python脚本主要是实现以上功能。
其中,使用BeautifulSoup来解析HTML,可以参考我的另外一篇文章:Windows8下安装BeautifulSoup
代码如下:
__author__ = '曾是土木人'
# -*- coding: utf-8 -*-
#采集SERP搜索结果标题
import urllib2
from bs4 import BeautifulSoup
import time
#写文件
def WriteFile(fileName,content):
try:
fp = file(fileName,"a+")
fp.write(content + "\r")
fp.close()
except:
pass
#获取Html源码
def GetHtml(url):
try:
req = urllib2.Request(url)
response= urllib2.urlopen(req,None,3)#设置超时时间
data = response.read().decode('utf-8','ignore')
except:pass
return data
#提取搜索结果SERP的标题
def FetchTitle(html):
try:
soup = BeautifulSoup(''.join(html))
for i in soup.findAll("h3"):
title = i.text.encode("utf-8")
if any(str_ in title for str_ in ("北京","厦门")):
continue
else:
print title
WriteFile("Result.txt",title)
except:
pass
keyword = "58同城"
if __name__ == "__main__":
global keyword
start = time.time()
for i in range(0,8):
url = "http://www.baidu.com/s?wd=intitle:"+keyword+"&rn=100&pn="+str(i*100)
html = GetHtml(url)
FetchTitle(html)
time.sleep(1)
c = time.time() - start
print('程序运行耗时:%0.2f 秒'%(c))

 What are some common operations that can be performed on Python arrays?Apr 26, 2025 am 12:22 AM
What are some common operations that can be performed on Python arrays?Apr 26, 2025 am 12:22 AMPythonarrayssupportvariousoperations:1)Slicingextractssubsets,2)Appending/Extendingaddselements,3)Insertingplaceselementsatspecificpositions,4)Removingdeleteselements,5)Sorting/Reversingchangesorder,and6)Listcomprehensionscreatenewlistsbasedonexistin
 In what types of applications are NumPy arrays commonly used?Apr 26, 2025 am 12:13 AM
In what types of applications are NumPy arrays commonly used?Apr 26, 2025 am 12:13 AMNumPyarraysareessentialforapplicationsrequiringefficientnumericalcomputationsanddatamanipulation.Theyarecrucialindatascience,machinelearning,physics,engineering,andfinanceduetotheirabilitytohandlelarge-scaledataefficiently.Forexample,infinancialanaly
 When would you choose to use an array over a list in Python?Apr 26, 2025 am 12:12 AM
When would you choose to use an array over a list in Python?Apr 26, 2025 am 12:12 AMUseanarray.arrayoveralistinPythonwhendealingwithhomogeneousdata,performance-criticalcode,orinterfacingwithCcode.1)HomogeneousData:Arrayssavememorywithtypedelements.2)Performance-CriticalCode:Arraysofferbetterperformancefornumericaloperations.3)Interf
 Are all list operations supported by arrays, and vice versa? Why or why not?Apr 26, 2025 am 12:05 AM
Are all list operations supported by arrays, and vice versa? Why or why not?Apr 26, 2025 am 12:05 AMNo,notalllistoperationsaresupportedbyarrays,andviceversa.1)Arraysdonotsupportdynamicoperationslikeappendorinsertwithoutresizing,whichimpactsperformance.2)Listsdonotguaranteeconstanttimecomplexityfordirectaccesslikearraysdo.
 How do you access elements in a Python list?Apr 26, 2025 am 12:03 AM
How do you access elements in a Python list?Apr 26, 2025 am 12:03 AMToaccesselementsinaPythonlist,useindexing,negativeindexing,slicing,oriteration.1)Indexingstartsat0.2)Negativeindexingaccessesfromtheend.3)Slicingextractsportions.4)Iterationusesforloopsorenumerate.AlwayschecklistlengthtoavoidIndexError.
 How are arrays used in scientific computing with Python?Apr 25, 2025 am 12:28 AM
How are arrays used in scientific computing with Python?Apr 25, 2025 am 12:28 AMArraysinPython,especiallyviaNumPy,arecrucialinscientificcomputingfortheirefficiencyandversatility.1)Theyareusedfornumericaloperations,dataanalysis,andmachinelearning.2)NumPy'simplementationinCensuresfasteroperationsthanPythonlists.3)Arraysenablequick
 How do you handle different Python versions on the same system?Apr 25, 2025 am 12:24 AM
How do you handle different Python versions on the same system?Apr 25, 2025 am 12:24 AMYou can manage different Python versions by using pyenv, venv and Anaconda. 1) Use pyenv to manage multiple Python versions: install pyenv, set global and local versions. 2) Use venv to create a virtual environment to isolate project dependencies. 3) Use Anaconda to manage Python versions in your data science project. 4) Keep the system Python for system-level tasks. Through these tools and strategies, you can effectively manage different versions of Python to ensure the smooth running of the project.
 What are some advantages of using NumPy arrays over standard Python arrays?Apr 25, 2025 am 12:21 AM
What are some advantages of using NumPy arrays over standard Python arrays?Apr 25, 2025 am 12:21 AMNumPyarrayshaveseveraladvantagesoverstandardPythonarrays:1)TheyaremuchfasterduetoC-basedimplementation,2)Theyaremorememory-efficient,especiallywithlargedatasets,and3)Theyofferoptimized,vectorizedfunctionsformathematicalandstatisticaloperations,making


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

Zend Studio 13.0.1
Powerful PHP integrated development environment

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

WebStorm Mac version
Useful JavaScript development tools

