
Heim >Technologie-Peripheriegeräte >KI >Tokenisierung in einem Artikel verstehen!
Tokenisierung in einem Artikel verstehen!

- PHPznach vorne
- 2024-04-12 14:31:261026Durchsuche
Sprachmodelle basieren auf Text, der normalerweise in Form von Zeichenfolgen vorliegt. Die Eingabe in das Modell kann jedoch nur aus Zahlen bestehen, sodass der Text in eine numerische Form umgewandelt werden muss.
Die Tokenisierung ist eine grundlegende Aufgabe der Verarbeitung natürlicher Sprache. Sie kann eine fortlaufende Textsequenz (z. B. Sätze, Absätze usw.) nach bestimmten Kriterien in eine Zeichenfolge (z. B. Wörter, Phrasen, Zeichen, Satzzeichen usw.) unterteilen Unter ihnen wird die Einheit als Token oder Wort bezeichnet.
Gemäß dem in der Abbildung unten gezeigten spezifischen Prozess teilen Sie zunächst die Textsätze in Einheiten auf, digitalisieren Sie dann die einzelnen Elemente (bilden Sie sie in Vektoren ab), geben Sie diese Vektoren dann zur Codierung in das Modell ein und geben Sie sie schließlich an nachgelagerte Aufgaben aus um ein weiteres Endergebnis zu erzielen.
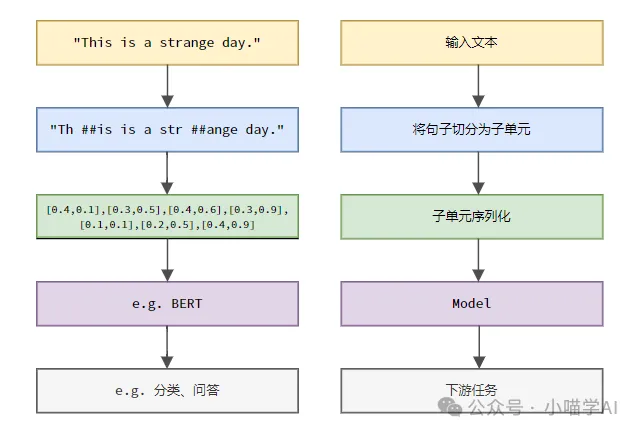
Textsegmentierung
Entsprechend der Granularität der Textsegmentierung kann die Tokenisierung in drei Kategorien unterteilt werden: granulare Tokenisierung für Wörter, granulare Tokenisierung für Zeichen und granulare Tokenisierung für Unterwörter.
1. Wortgranularitäts-Tokenisierung
Wortgranularitäts-Tokenisierung ist die intuitivste Wortsegmentierungsmethode, bei der der Text nach Vokabeln segmentiert wird. Beispiel:
The quick brown fox jumps over the lazy dog.词粒度Tokenized结果:['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.']
In diesem Beispiel wird der Text in unabhängige Wörter unterteilt, jedes Wort wird als Token verwendet und das Satzzeichen „.“ wird auch als unabhängiges Token betrachtet.
Chinesischer Text wird normalerweise entsprechend der im Wörterbuch enthaltenen Standardvokabelsammlung oder den Phrasen, Redewendungen, Eigennamen usw. segmentiert, die durch den Wortsegmentierungsalgorithmus erkannt werden.
我喜欢吃苹果。词粒度Tokenized结果:['我', '喜欢', '吃', '苹果', '。']
Dieser chinesische Text ist in fünf Wörter unterteilt: „Ich“, „Gefällt mir“, „Essen“, „Apfel“ und Punkt „.“; jedes Wort dient als Zeichen.
2. Granulare Zeichen-Tokenisierung
Die granulare Zeichen-Tokenisierung unterteilt Text in kleinste Zeicheneinheiten, d. h. jedes Zeichen wird als separates Token behandelt. Zum Beispiel:
Hello, world!字符粒度Tokenized结果:['H', 'e', 'l', 'l', 'o', ',', ' ', 'w', 'o', 'r', 'l', 'd', '!']
Zeichengranularitäts-Tokenisierung im Chinesischen besteht darin, den Text nach jedem unabhängigen chinesischen Zeichen zu segmentieren.
我喜欢吃苹果。字符粒度Tokenized结果:['我', '喜', '欢', '吃', '苹', '果', '。']
3.Subword-Granular-Tokenisierung
Subword-Granular-Tokenisierung liegt zwischen Wortgranularität und Zeichengranularität. Sie unterteilt den Text in Unterwörter (Unterwörter) zwischen Wörtern und Zeichen als Token. Zu den gängigen Unterwort-Tokenisierungsmethoden gehören Byte Pair Encoding (BPE), WordPiece usw. Diese Methoden generieren automatisch ein Wortsegmentierungswörterbuch durch Zählen der Teilzeichenfolgehäufigkeiten in Textdaten, das das Problem von Out-of-Service-Wörtern (OOV) effektiv lösen und gleichzeitig eine gewisse semantische Integrität aufrechterhalten kann. " hel“, „low“, „orld“, das sind alles hochfrequente Teilzeichenfolgenkombinationen, die in Wörterbüchern vorkommen. Diese Segmentierungsmethode kann nicht nur unbekannte Wörter verarbeiten (z. B. ist „helloworld“ kein englisches Standardwort), sondern auch bestimmte semantische Informationen beibehalten (durch die Kombination von Unterwörtern kann das ursprüngliche Wort wiederhergestellt werden).
helloworld
h, e, l, o, w, r, d, hel, low, wor, orld
['hel', 'low', 'orld']
In diesem Beispiel: „Ich esse gerne.“ Äpfel“ Es ist in vier Unterwörter „Ich“, „Gefällt mir“, „Essen“ und „Apfel“ unterteilt, und diese Unterwörter erscheinen alle im Wörterbuch. Obwohl chinesische Schriftzeichen nicht weiter wie englische Unterwörter kombiniert werden, hat die Unterwort-Tokenisierungsmethode bei der Erstellung des Wörterbuchs hochfrequente Wortkombinationen wie „Ich mag“ und „Äpfel essen“ berücksichtigt. Diese Segmentierungsmethode behält semantische Informationen auf Wortebene bei, während unbekannte Wörter verarbeitet werden.
Gehen Sie davon aus, dass ein Korpus oder Vokabular wie folgt erstellt wurde.
我喜欢吃苹果
kann den Index jedes Tokens in der Reihenfolge im Vokabular finden.
我, 喜, 欢, 吃, 苹, 果, 我喜欢, 吃苹果
Ausgabe: [0, 1, 2, 3, 4].
Das obige ist der detaillierte Inhalt vonTokenisierung in einem Artikel verstehen!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wo ist der E-Mail-Speicherort von Foxmail?
- Wo befindet sich die Hauptfunktion im C-Quellprogramm?
- Was bedeutet E-Mail-Adresse?
- Eine neu veröffentlichte Übersicht über groß angelegte Sprachmodelle: die umfassendste Übersicht von T5 bis GPT-4, gemeinsam verfasst von mehr als 20 inländischen Forschern
- Meta AI öffnet mehr als 600 Millionen metagenomische Proteinstrukturkarten und 15 Milliarden Sprachmodelle wurden in zwei Wochen fertiggestellt