
Heim >Technologie-Peripheriegeräte >KI >100.000 US-Dollar für die Ausbildung des großen Llama-2-Modells! „Alle Chinesen bauen ein neues MoE', schaut Jia Yangqing, ehemaliger CEO von SD, zu
100.000 US-Dollar für die Ausbildung des großen Llama-2-Modells! „Alle Chinesen bauen ein neues MoE', schaut Jia Yangqing, ehemaliger CEO von SD, zu

- WBOYnach vorne
- 2024-04-07 09:04:01603Durchsuche
Wenn Sie mehr über AIGC erfahren möchten,
besuchen Sie bitte: 51CTO AI , trainieren Sie große Modelle auf Llama-2-Niveau.
Das
MoE-Modell ist kleiner, hat aber die gleiche Leistung:
Es heißt JetMoE und stammt von Forschungseinrichtungen wie MIT und Princeton. Die Leistung übertrifft die von Llama-2 derselben Größe bei weitem.
△Retweetet von Jia Yangqing
Sie müssen wissen, dass Letzteres Investitionskosten in Höhe vonMilliarden Dollar
hat.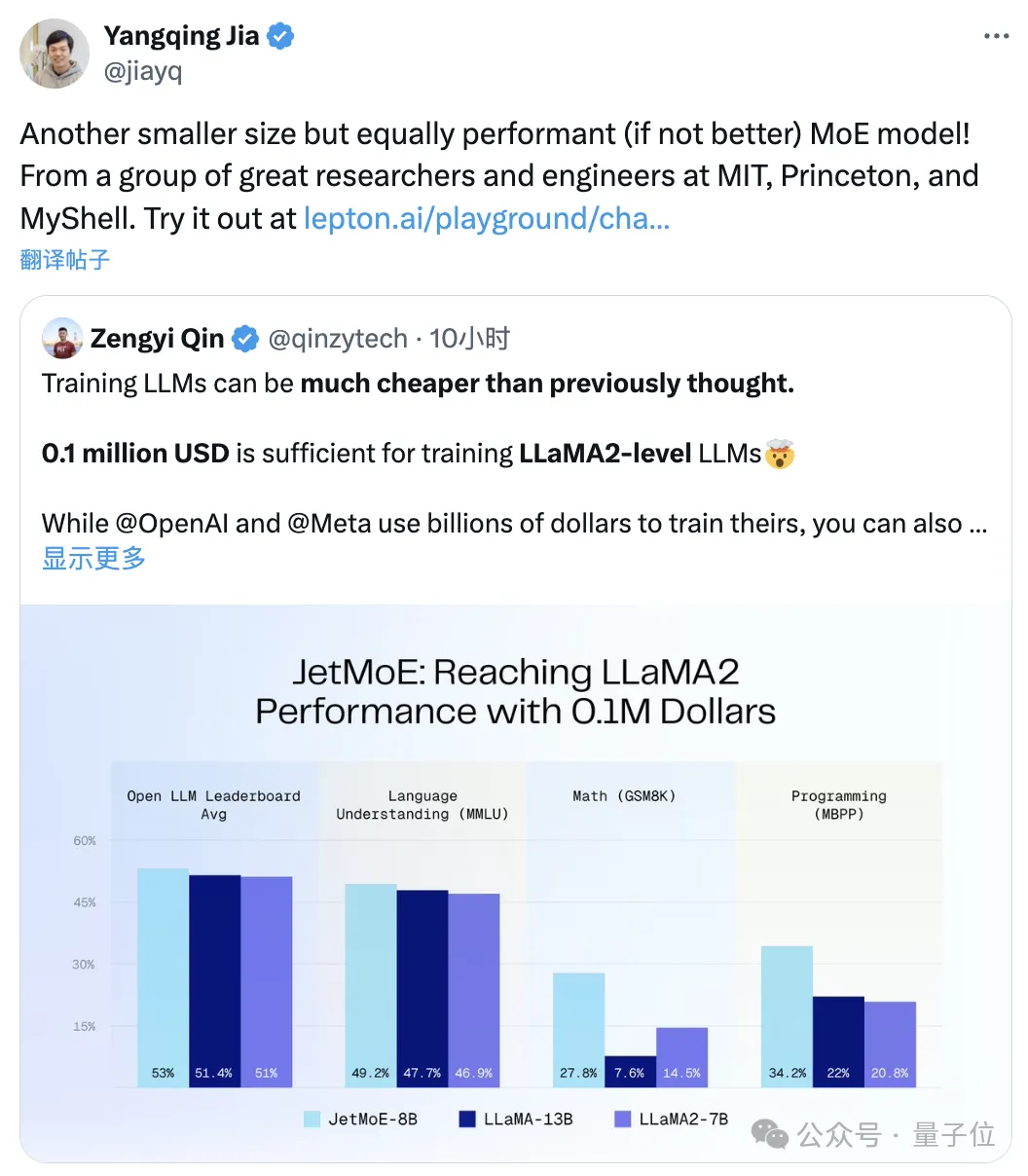
Man muss sagen, dass die Kosten für den Bau großer Modelle wirklich viel günstiger sind, als man denkt.
Ps. Emad, dem ehemaligen Chef von Stable Diffusion, hat es auch gefallen: 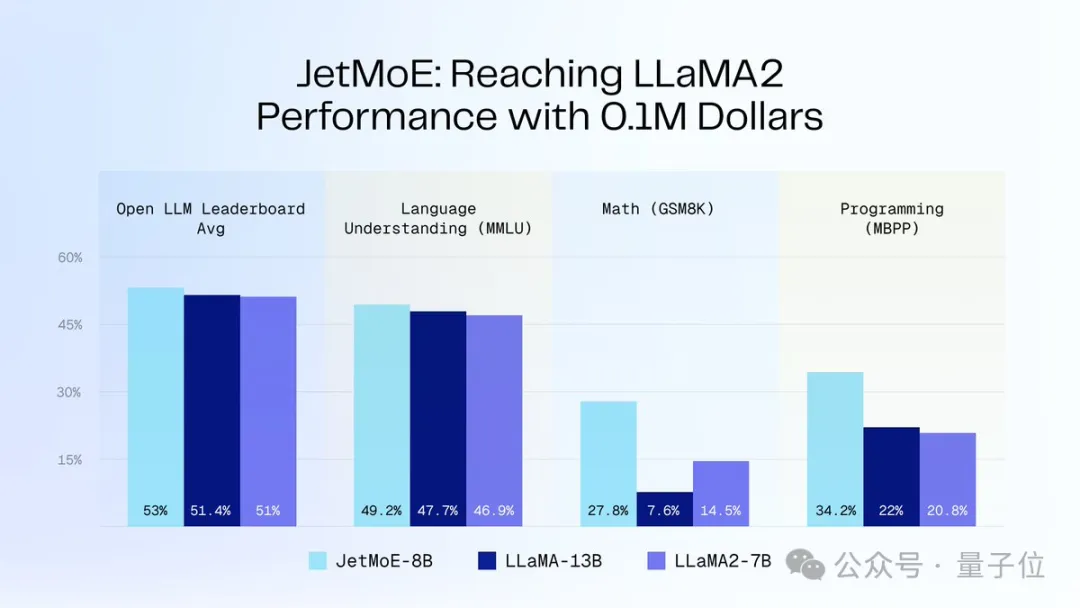
100.000 $, um die Leistung von Llama-2 zu erreichen
JetMoE ist von der spärlichen Aktivierungsarchitektur von ModuleFormer inspiriert.(ModuleFormer, eine modulare Architektur basierend auf Sparse Mixture of Experts (SMoE) zur Verbesserung der Effizienz und Flexibilität großer Modelle, vorgeschlagen im Juni letzten Jahres)
MoE wird immer noch in seiner Aufmerksamkeitsschicht verwendet: JetMoE mit 8 Milliarden Parameter hat insgesamt 24 Blöcke, jeder Block enthält 2 MoE-Schichten, nämlich Attention Head Mixing
JetMoE mit 8 Milliarden Parameter hat insgesamt 24 Blöcke, jeder Block enthält 2 MoE-Schichten, nämlich Attention Head Mixing
und MLP Expert Mixing
(MoE).
Jede MoA- und MoE-Schicht verfügt über 8 Experten, 2 werden bei jeder Token-Eingabe aktiviert.
JetMoE-8B verwendet1,25T-Token im öffentlichen Datensatz für das Training, mit einer Lernrate von 5,0 x 10-4 und einer globalen Stapelgröße von 4 Millionen Token.
Der spezifische Trainingsplan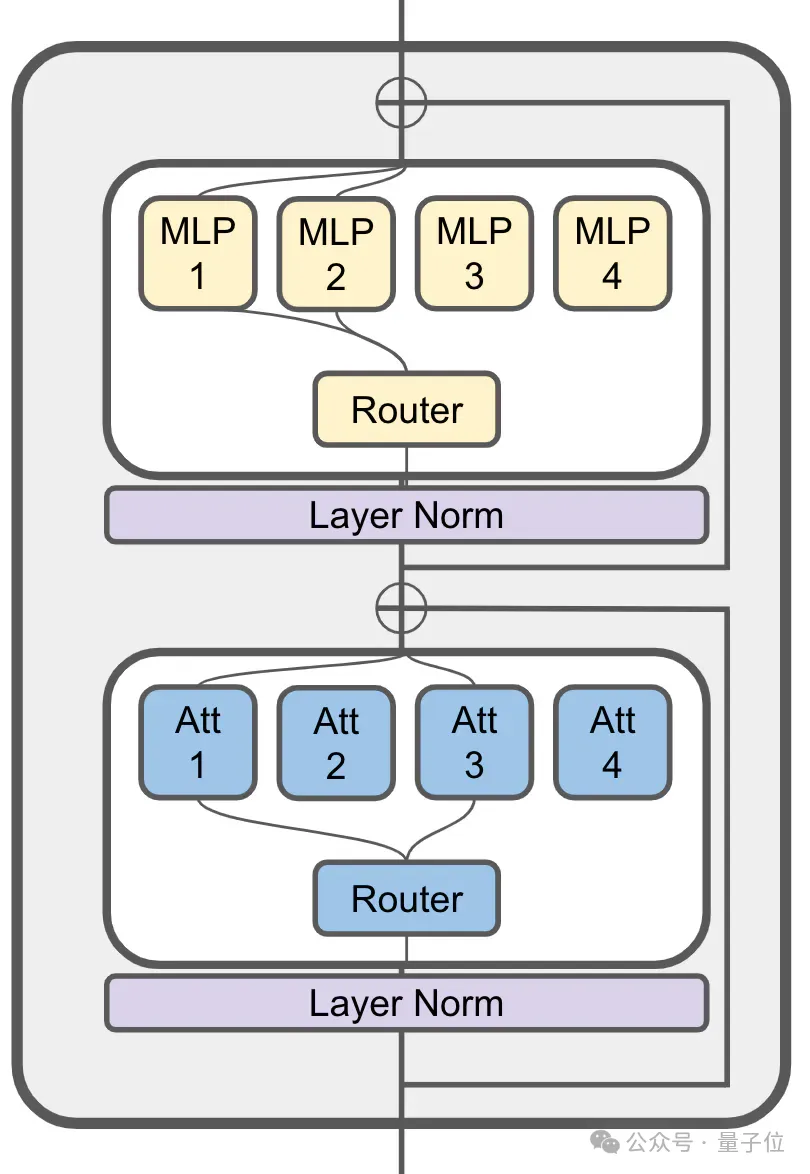 folgt der Idee von MiniCPM
folgt der Idee von MiniCPM
und umfasst zwei Phasen:
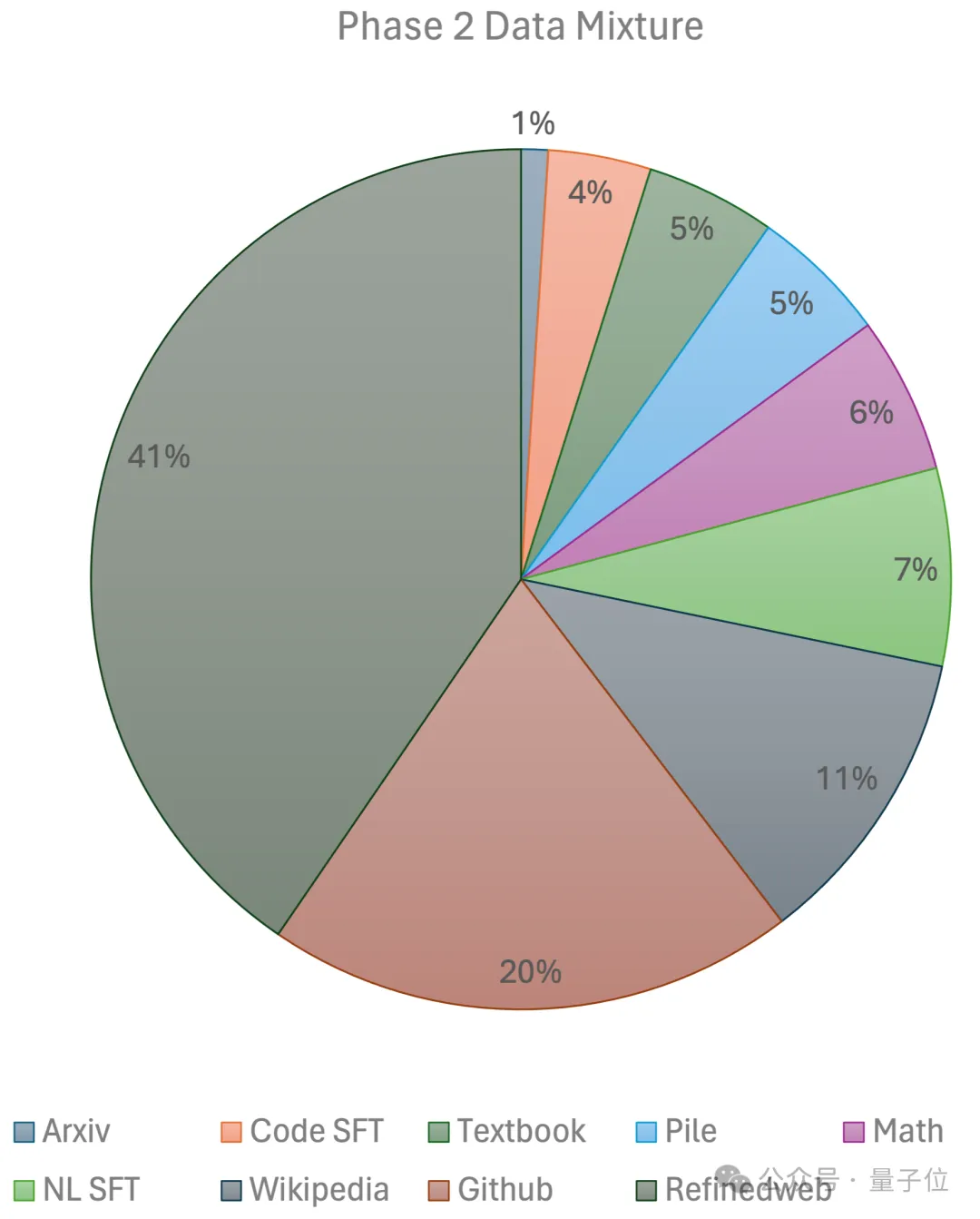
Die erste Stufe verwendet lineares Vorheizen Konstante Lernrate, trainiert mit 1 Billion Token aus großen Open-Source-Datensätzen vor dem Training, einschließlich RefinedWeb-, Pile-, Github-Daten usw. Die zweite Stufe nutzt den exponentiellen Lernratenabfall und verwendet 250 Milliarden Token, um Token aus dem Datensatz der ersten Stufe und hochqualitativen Open-Source-Datensätzen zu trainieren. Am Ende nutzte das Team
96×H100
GPU-Cluster, 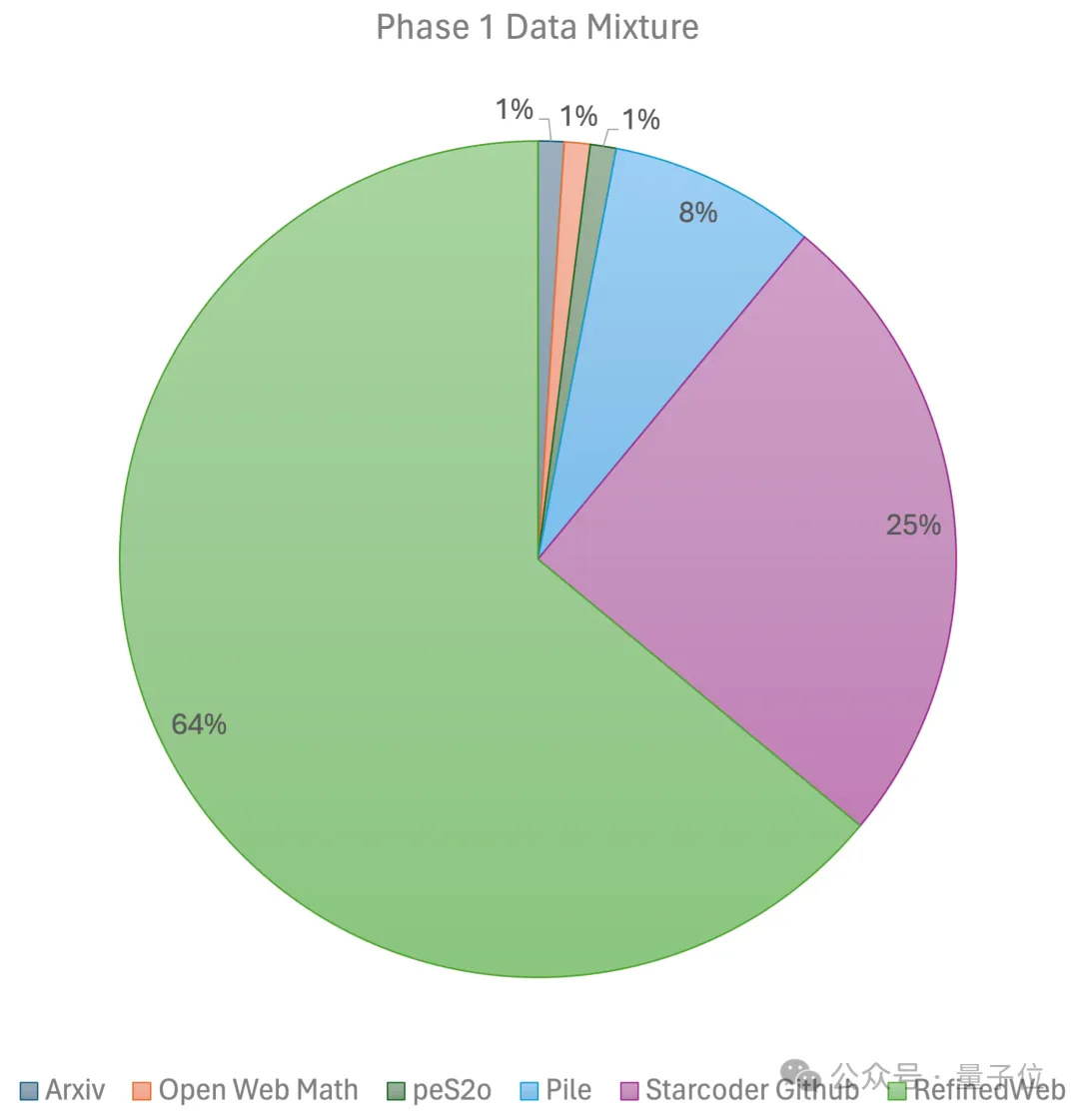
 Weitere technische Details werden im bald veröffentlichten technischen Bericht bekannt gegeben.
Weitere technische Details werden im bald veröffentlichten technischen Bericht bekannt gegeben.
Da JetMoE-8B während des Inferenzprozesses nur über 2,2 Milliarden Aktivierungsparameter verfügt, wird der Rechenaufwand erheblich reduziert – Gleichzeitig wurde auch eine gute Leistung erzielt. Wie in der Abbildung unten gezeigt:
JetMoE-8B erreichte 5 Sota
bei 8 Bewertungsbenchmarks (einschließlich der großen Modellarena Open LLM Leaderboard)und übertraf damit LLaMA-13B, LLaMA2-7B und DeepseekMoE-16B.
Erzielte im MT-Bench-Benchmark einen Wert von 6,681 und übertraf damit auch Modelle wie LLaMA2 und Vicuna mit 13 Milliarden Parametern.AutorenvorstellungJetMoE hat insgesamt 4 Autoren, das sind:
- Yikang Shen
Forscher am MIT-IBM Watson Lab, Forschungsrichtung NLP.
Abschluss an der Beihang-Universität mit einem Bachelor- und Master-Abschluss und Doktorarbeit am von Yoshua Bengio gegründeten Mila Research Institute.
- Guozhen (Gavin Guo)
ist Doktorand am MIT. Sein Forschungsschwerpunkt ist dateneffizientes maschinelles Lernen für die 3D-Bildgebung.
Er schloss sein Bachelor-Studium an der UC Berkeley ab. Letzten Sommer trat er als studentischer Forscher dem MIT-IBM Watson Lab bei.
- Cai Tianle
Ein Doktorand in Princeton mit einem Bachelor-Abschluss in angewandter Mathematik und Informatik von der Peking-Universität. Derzeit ist er auch Teilzeitforscher bei Together.ai und arbeitet mit Tri Dao zusammen .
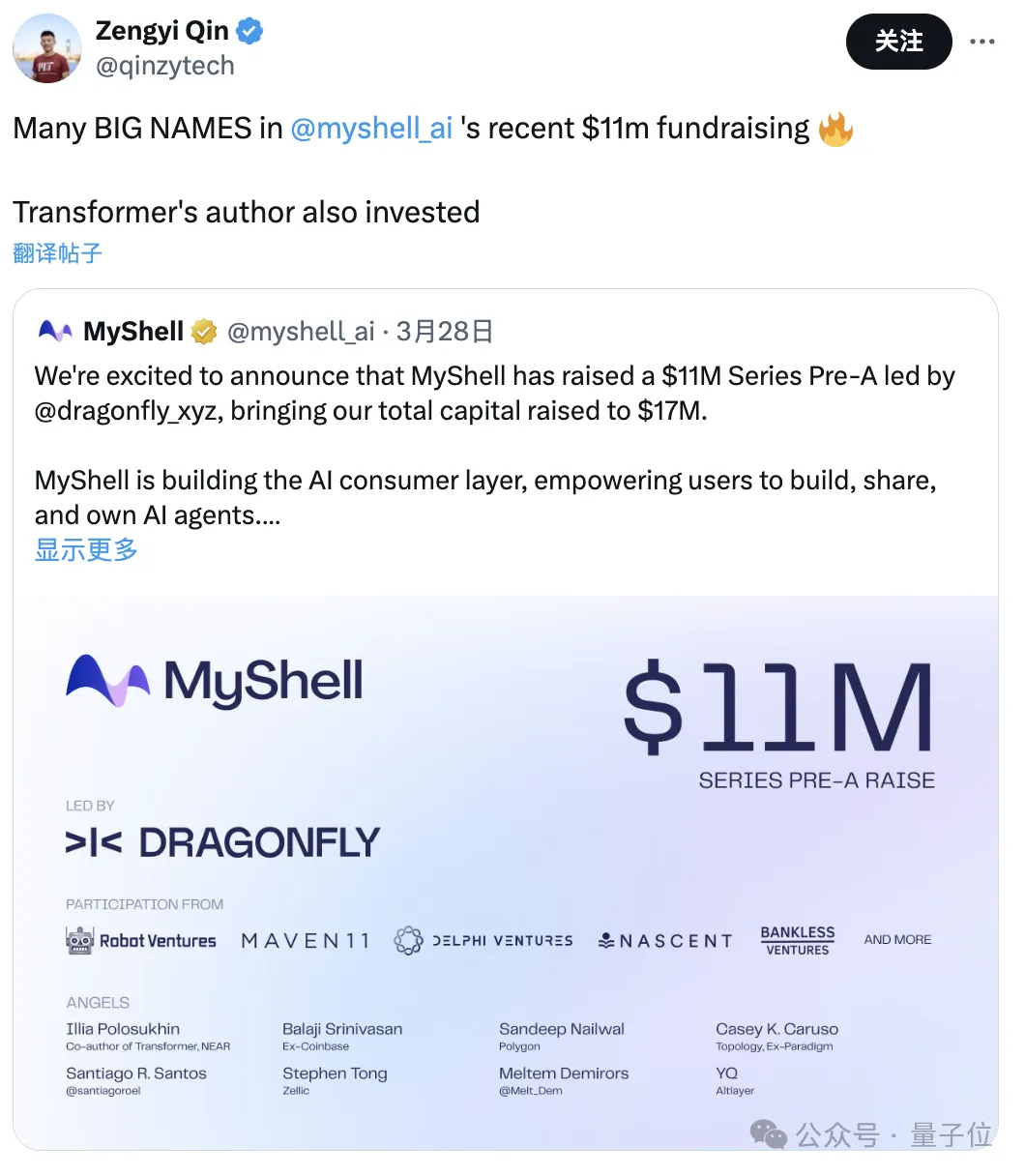
- Zengyi Qin
Ph.D.-Student am MIT und Gründer eines Unternehmens, der KI-Forschungs- und Entwicklungsdirektor von MyShell.
Dieses Unternehmen hat gerade 11 Millionen US-Dollar eingesammelt und zu den Investoren gehört der Autor von Transformer.
Portal: https://github.com/myshell-ai/JetMoE
Referenzlink: https://twitter.com/jiayq/status/1775935845205463292
Möchten Sie mehr über AIGC erfahren? Für Inhalte
besuchen Sie bitte: 51CTO AI.
Das obige ist der detaillierte Inhalt von100.000 US-Dollar für die Ausbildung des großen Llama-2-Modells! „Alle Chinesen bauen ein neues MoE', schaut Jia Yangqing, ehemaliger CEO von SD, zu. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was bedeutet das Python-IPO-Modell?
- Welches Farbmodell wird von Computermonitoren verwendet?
- Implementieren Sie Edge-Training mit weniger als 256 KB Speicher, und die Kosten betragen weniger als ein Tausendstel von PyTorch
- IBM entwickelt den Cloud-nativen KI-Supercomputer Vela, um zig Milliarden Parametermodelle flexibel einzusetzen und zu trainieren
- Trainingszeitproblem des Deep-Learning-Modells