AniPortrait-Modelle sind Open Source und können frei gespielt werden.
„Ein neues Produktivitätstool für Xiaopozhan Ghost Zone.“ Kürzlich hat ein neues Projekt, das von Tencent Open Source veröffentlicht wurde, eine solche Bewertung erhalten. Bei diesem Projekt handelt es sich um AniPortrait, das hochwertige animierte Porträts basierend auf Audio und einem Referenzbild generiert. Werfen wir ohne Umschweife einen Blick auf die Demo, vor der möglicherweise ein Anwaltsschreiben warnt:  Anime-Bilder können auch leicht sprechen: Das Projekt ist gerade erst seit einem Jahr online Wenige Tage, und es hat bereits breites Lob erhalten: Die Zahl der GitHub-Stars hat 2.800 überschritten.
Anime-Bilder können auch leicht sprechen: Das Projekt ist gerade erst seit einem Jahr online Wenige Tage, und es hat bereits breites Lob erhalten: Die Zahl der GitHub-Stars hat 2.800 überschritten.
Werfen wir einen Blick auf die Innovationen von AniPortrait.
- Papiertitel: AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation
- Papieradresse: https://arxiv.org/pdf/2403.17694.pdf
- Codeadresse: https:/ /arxiv.org/pdf/2403.17694.pdf /github.com/Zejun-Yang/AniPortrait
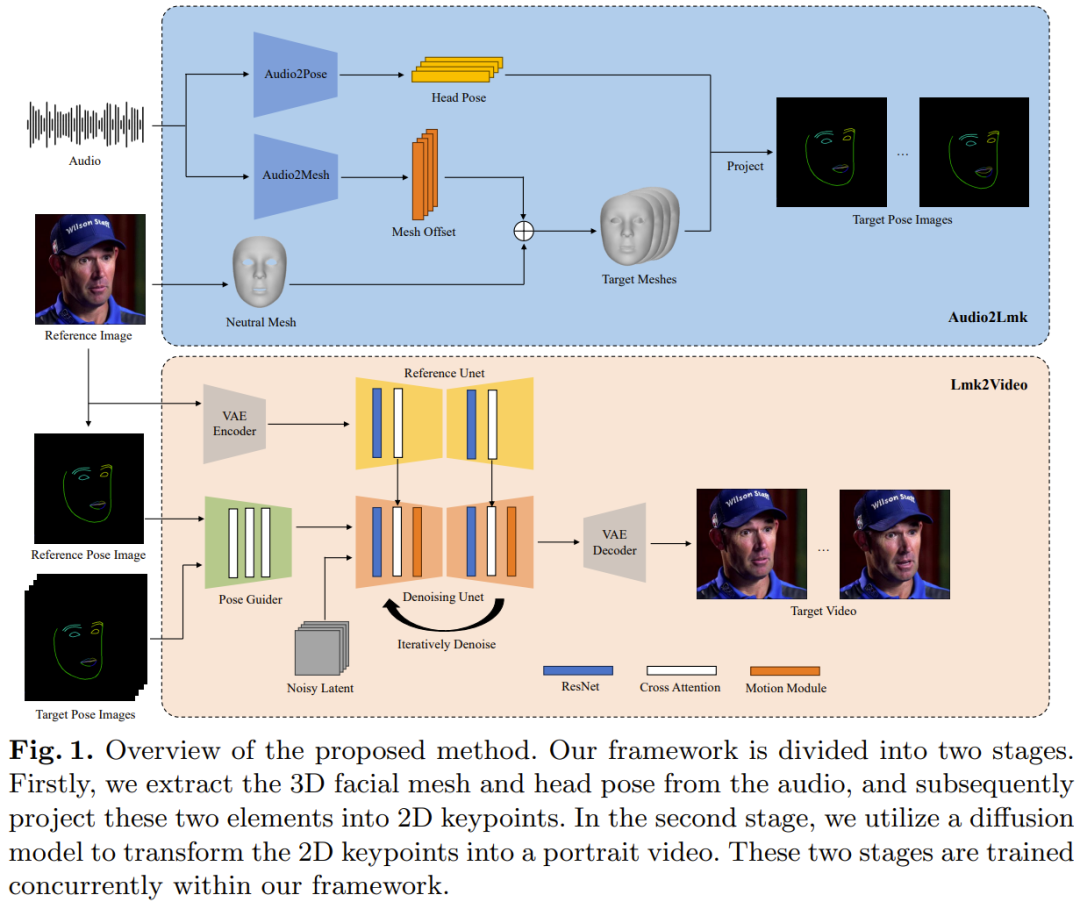
Tencents neu vorgeschlagenes AniPortrait-Framework enthält zwei Module: Audio2Lmk und Lmk2Video. Audio2Lmk wird zum Extrahieren von Landmark-Sequenzen verwendet, mit denen komplexe Gesichtsausdrücke und Lippenbewegungen aus der Audioeingabe erfasst werden können. Lmk2Video nutzt diese Landmark-Sequenz, um zeitlich stabile und konsistente Porträtvideos in hoher Qualität zu generieren. Abbildung 1 gibt einen Überblick über das AniPortrait-Framework.
Für eine Sequenz von Sprachclips besteht das Ziel hier darin, die entsprechende 3D-Gesichtsnetzsequenz und Gestensequenz vorherzusagen. Das Team verwendete vorab trainiertes wav2vec, um Audiofunktionen zu extrahieren. Das Modell lässt sich gut verallgemeinern und kann Aussprache und Intonation im Audio präzise erkennen – entscheidend für die Erstellung realistischer Gesichtsanimationen. Durch die Nutzung der erhaltenen robusten Sprachmerkmale können sie mithilfe einer einfachen Architektur, die aus zwei fc-Schichten besteht, effizient in 3D-Gesichtsnetze umgewandelt werden. Das Team stellte fest, dass dieses einfache und unkomplizierte Design nicht nur die Genauigkeit gewährleistet, sondern auch die Effizienz des Inferenzprozesses verbessert. Bei der Umwandlung von Audio in Gesten ist das vom Team verwendete Backbone-Netzwerk immer noch dasselbe wav2vec. Die Gewichtungen dieses Netzwerks unterscheiden sich jedoch vom Netzwerk des Audio-to-Mesh-Moduls. Dies liegt daran, dass Gesten enger mit Rhythmus und Tonhöhe im Audio verknüpft sind, wohingegen sich Audio-to-Grid-Aufgaben auf einen anderen Schwerpunkt konzentrieren (Aussprache und Intonation). Um die Auswirkungen früherer Zustände zu berücksichtigen, setzte das Team einen Transformator-Decoder ein, um die Gestensequenz zu dekodieren. Dabei nutzt das Modul einen Cross-Attention-Mechanismus, um Audiofunktionen in den Decoder zu integrieren. Für die beiden oben genannten Module ist die für das Training verwendete Verlustfunktion ein einfacher L1-Verlust. Nach Erhalt der Netz- und Posensequenz verwenden Sie die perspektivische Projektion, um sie in eine 2D-Gesichtsmarkierungssequenz umzuwandeln. Diese Landmarken sind die Eingangssignale für die nächste Stufe. Anhand eines Referenzporträts und einer Gesichts-Landmark-Sequenz kann das vom Team vorgeschlagene Lmk2Video zeitlich konsistente Porträtanimationen erstellen. Beim Animationsprozess geht es darum, die Bewegung an der Landmark-Sequenz auszurichten und gleichzeitig ein einheitliches Erscheinungsbild des Referenzbilds beizubehalten. Die Idee des Teams besteht darin, Porträtanimationen als eine Abfolge von Porträtbildern darzustellen. Dieses Netzwerkstrukturdesign von Lmk2Video ist von AnimateAnyone inspiriert. Das Backbone-Netzwerk ist SD1.5, das ein zeitliches Bewegungsmodul integriert, das Multi-Frame-Rauscheingaben effektiv in eine Folge von Video-Frames umwandelt. Darüber hinaus verwendeten sie auch ein ReferenceNet, das ebenfalls die SD1.5-Struktur verwendet. Seine Funktion besteht darin, die Erscheinungsbildinformationen des Referenzbilds zu extrahieren und in das Backbone-Netzwerk zu integrieren. Dieses strategische Design stellt sicher, dass Face ID im gesamten Ausgabevideo konsistent bleibt. Im Gegensatz zu AnimateAnyone wird hier die Komplexität des PoseGuider-Designs verbessert. In der Originalversion wurden lediglich mehrere Faltungsschichten integriert, und dann wurden die Landmark-Merkmale mit den latenten Merkmalen der Eingabeschicht des Backbone-Netzwerks verschmolzen. Das Tencent-Team stellte fest, dass dieses rudimentäre Design die komplexen Bewegungen der Lippen nicht erfassen konnte. Daher haben sie die Multiskalenstrategie von ControlNet übernommen: die Integration von Landmark-Funktionen entsprechender Skalen in verschiedene Module des Backbone-Netzwerks. Trotz dieser Verbesserungen ist die Anzahl der Parameter im endgültigen Modell immer noch recht gering. Das Team führte außerdem eine weitere Verbesserung ein: die Verwendung des Landmarks des Referenzbildes als zusätzliche Eingabe. Das Cross-Attention-Modul von PoseGuider erleichtert die Interaktion zwischen Referenz-Landmarken und Ziel-Landmarken in jedem Frame. Dieser Prozess liefert dem Netzwerk zusätzliche Hinweise, die es ihm ermöglichen, den Zusammenhang zwischen Gesichtsmerkmalen und Aussehen zu verstehen, was dazu beitragen kann, dass die Porträtanimation präzisere Bewegungen erzeugt. Das in der Audio2Lmk-Phase verwendete Backbone-Netzwerk ist wav2vec2.0. Das zum Extrahieren von 3D-Netzen und 6D-Posen verwendete Tool ist MediaPipe. Die Trainingsdaten von Audio2Mesh stammen aus dem internen Datensatz von Tencent, der fast eine Stunde hochwertige Sprachdaten von einem einzelnen Sprecher enthält. Um die Stabilität des von MediaPipe extrahierten 3D-Netzes zu gewährleisten, ist die Kopfposition des Darstellers während der Aufnahme stabil und zur Kamera gerichtet. Training Audio2Pose verwendet HDTF. Alle Trainingsvorgänge werden auf einem einzigen A100 unter Verwendung des Adam-Optimierers durchgeführt und die Lernrate ist auf 1e-5 eingestellt.Der Lmk2Video-Prozess verwendet eine zweistufige Trainingsmethode. Die erste Schrittphase konzentriert sich auf das Training des Backbone-Netzwerks ReferenceNet und der 2D-Komponente von PoseGuider, unabhängig vom Bewegungsmodul. In den folgenden Schritten werden alle anderen Komponenten eingefroren, um sich auf das Training des Bewegungsmoduls zu konzentrieren. Zum Trainieren des Modells werden hier zwei große, hochwertige Gesichtsvideodatensätze verwendet: VFHQ und CelebV-HQ. Alle Daten werden durch MediaPipe geleitet, um 2D-Gesichtsmarkierungen zu extrahieren. Um die Empfindlichkeit des Netzwerks gegenüber Lippenbewegungen zu verbessern, bestand der Ansatz des Teams darin, beim Rendern von Posenbildern basierend auf 2D-Landmarks die Ober- und Unterlippe mit unterschiedlichen Farben zu kommentieren. Alle Bilder wurden auf 512x512 verkleinert.Das Modell wurde mit 4 A100-GPUs trainiert, wobei jeder Schritt 2 Tage dauerte. Der Optimierer ist AdamW und die Lernrate ist auf 1e-5 festgelegt. Experimentelle ErgebnisseWie in Abbildung 2 gezeigt, ist die mit der neuen Methode erhaltene Animation von ausgezeichneter Qualität und Realismus.
Darüber hinaus können Benutzer die 3D-Darstellung in der Mitte bearbeiten, um die endgültige Ausgabe zu ändern. Benutzer können beispielsweise Sehenswürdigkeiten aus einer Quelle extrahieren und ihre ID-Informationen ändern, um eine Gesichtsreproduktion zu erreichen, wie im folgenden Video gezeigt: Weitere Informationen finden Sie im Originalpapier. Das obige ist der detaillierte Inhalt vonUp-Besitzer haben bereits begonnen, mit Tencents Open-Source-Programm „AniPortrait' herumzuspielen, um Fotos zum Singen und Sprechen zu bringen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!






 Weitere Informationen finden Sie im Originalpapier.
Weitere Informationen finden Sie im Originalpapier.