
Heim >Technologie-Peripheriegeräte >KI >ICLR 2024 |. Modellieren Sie kritische Schichten für föderierte Lern-Backdoor-Angriffe
ICLR 2024 |. Modellieren Sie kritische Schichten für föderierte Lern-Backdoor-Angriffe

- PHPznach vorne
- 2024-04-07 09:04:081227Durchsuche
Federated Learning nutzt mehrere Parteien zum Trainieren von Modellen, während der Datenschutz geschützt ist. Da der Server jedoch den von den Teilnehmern lokal durchgeführten Schulungsprozess nicht überwachen kann, können Teilnehmer das lokale Schulungsmodell manipulieren, was Sicherheitsrisiken für das gesamte föderierte Lernmodell mit sich bringt, beispielsweise durch Hintertürangriffe.
Dieser Artikel konzentriert sich darauf, wie man Hintertürangriffe auf föderiertes Lernen unter einem defensiv geschützten Trainingsrahmen startet. In diesem Artikel wird festgestellt, dass die Implementierung von Backdoor-Angriffen enger mit einigen neuronalen Netzwerkschichten zusammenhängt, und diese Schichten werden als Schlüsselschichten für Backdoor-Angriffe bezeichnet. Beim föderierten Lernen werden die am Training teilnehmenden Clients auf verschiedene Geräte verteilt. Sie trainieren jeweils ihre eigenen Modelle und laden dann die aktualisierten Modellparameter zur Aggregation auf den Server hoch. Da der an der Schulung teilnehmende Client nicht vertrauenswürdig ist und ein gewisses Risiko besteht, wird der Server
Basierend auf der Entdeckung der Schlüsselschicht der Hintertür wird in diesem Artikel vorgeschlagen, die Erkennung des Verteidigungsalgorithmus durch einen Angriff auf die Schlüsselschicht der Hintertür zu umgehen , so dass eine kleine Anzahl von Teilnehmern kontrolliert werden kann, um effiziente Backdoor-Angriffe durchzuführen.

Papiertitel: Backdoor Federated Learning By Poisoning Backdoor-Critical Layers
Papierlink: https://openreview.net/pdf?id=AJBGSVSTT2
Codelink: https://github.com/zhmzm/ Poisoning_Backdoor-critical_Layers_Attack
Methode
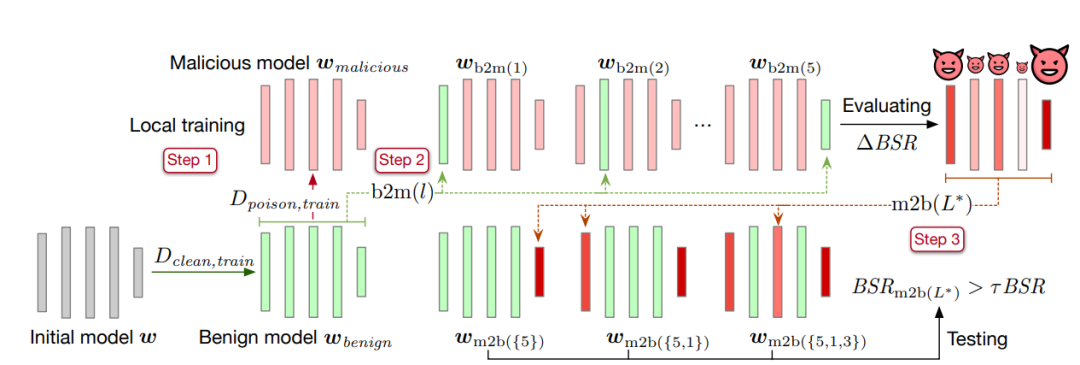
Dieser Artikel schlägt eine Methode zum Ersetzen von Schichten vor, um kritische Schichten für die Hintertür zu identifizieren. Die spezifische Methode ist wie folgt:
Der erste Schritt besteht darin, das Modell auf einem sauberen Datensatz bis zur Konvergenz zu trainieren und die Modellparameter als harmloses Modell zu speichern
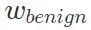 . Kopieren Sie dann das harmlose Modell und trainieren Sie es anhand des Datensatzes, der die Hintertür enthält. Speichern Sie nach der Konvergenz die Modellparameter und zeichnen Sie es als bösartiges Modell auf.
. Kopieren Sie dann das harmlose Modell und trainieren Sie es anhand des Datensatzes, der die Hintertür enthält. Speichern Sie nach der Konvergenz die Modellparameter und zeichnen Sie es als bösartiges Modell auf. 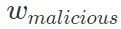
- Der zweite Schritt besteht darin, eine Parameterschicht im harmlosen Modell durch das bösartige Modell zu ersetzen, das die Hintertür enthält, und die Erfolgsrate des Hintertürangriffs des resultierenden Modells zu berechnen
. Die Differenz zwischen der erhaltenen Erfolgsrate des Backdoor-Angriffs und der Backdoor-Angriffs-Erfolgsrate BSR des Schadmodells beträgt ΔBSR, mit der die Auswirkung dieser Schicht auf Backdoor-Angriffe ermittelt werden kann. Mit der gleichen Methode für jede Schicht im neuronalen Netzwerk können Sie eine Liste der Auswirkungen aller Schichten auf Backdoor-Angriffe erhalten.
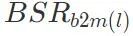
- Der dritte Schritt besteht darin, alle Ebenen nach ihrer Auswirkung auf Backdoor-Angriffe zu sortieren. Nehmen Sie die Ebene mit der größten Auswirkung aus der Liste und fügen Sie sie dem kritischen Ebenensatz für Hintertürangriffe hinzu
und betten Sie die kritischen Ebenenparameter für Hintertürangriffe (Ebenen im Satz
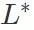 ) aus dem bösartigen Modell in das harmlose Modell ein. Berechnen Sie die Erfolgsquote des Backdoor-Angriffs des erhaltenen Modells
) aus dem bösartigen Modell in das harmlose Modell ein. Berechnen Sie die Erfolgsquote des Backdoor-Angriffs des erhaltenen Modells . Wenn die Erfolgsrate des Backdoor-Angriffs größer ist als der festgelegte Schwellenwert τ multipliziert mit der Erfolgsrate des Backdoor-Angriffs des bösartigen Modells
. Wenn die Erfolgsrate des Backdoor-Angriffs größer ist als der festgelegte Schwellenwert τ multipliziert mit der Erfolgsrate des Backdoor-Angriffs des bösartigen Modells 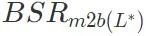 , wird der Algorithmus gestoppt. Wenn dies nicht der Fall ist, fügen Sie weiterhin die größte Schicht unter den verbleibenden Schichten in der Liste zur Schlüsselschicht für Backdoor-Angriffe hinzu
, wird der Algorithmus gestoppt. Wenn dies nicht der Fall ist, fügen Sie weiterhin die größte Schicht unter den verbleibenden Schichten in der Liste zur Schlüsselschicht für Backdoor-Angriffe hinzu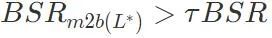 , bis die Bedingungen erfüllt sind.
, bis die Bedingungen erfüllt sind. 
 . Wenn die Erfolgsrate des Backdoor-Angriffs größer ist als der festgelegte Schwellenwert τ multipliziert mit der Erfolgsrate des Backdoor-Angriffs des bösartigen Modells
. Wenn die Erfolgsrate des Backdoor-Angriffs größer ist als der festgelegte Schwellenwert τ multipliziert mit der Erfolgsrate des Backdoor-Angriffs des bösartigen Modells Experimentelle Ergebnisse
Dieser Artikel überprüft die Wirksamkeit von Backdoor-Key-Layer-Angriffen auf mehrere Verteidigungsmethoden auf die CIFAR-10- und MNIST-Datensätze. Das Experiment wird die Erfolgsrate des Backdoor-Angriffs BSR und die Akzeptanzrate bösartiger Modelle MAR (Benign Model Acceptance Rate BAR) als Indikatoren verwenden, um die Wirksamkeit des Angriffs zu messen.
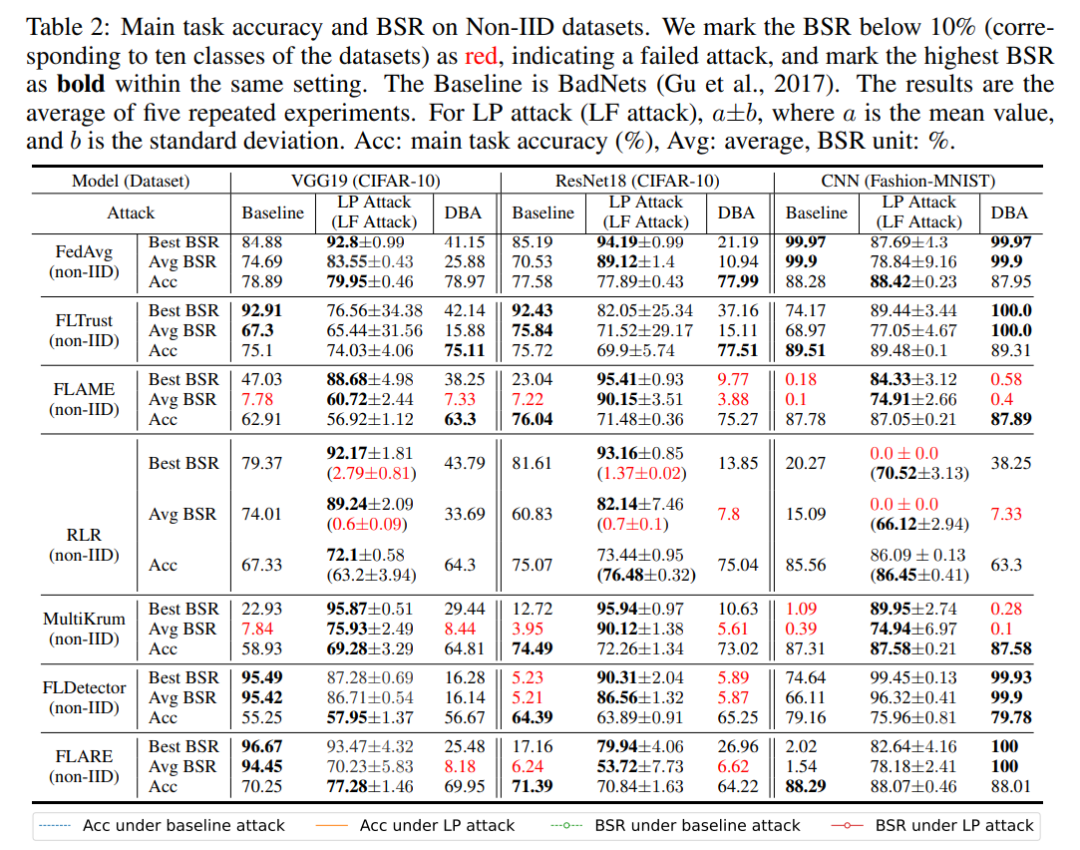
Zuallererst kann der schichtbasierte LP-Angriff böswilligen Clients eine hohe Auswahlrate ermöglichen. Wie in der folgenden Tabelle gezeigt, erreichte LP Attack eine Empfangsrate von 90 % beim CIFAR-10-Datensatz, was viel höher ist als die 34 % der harmlosen Benutzer.
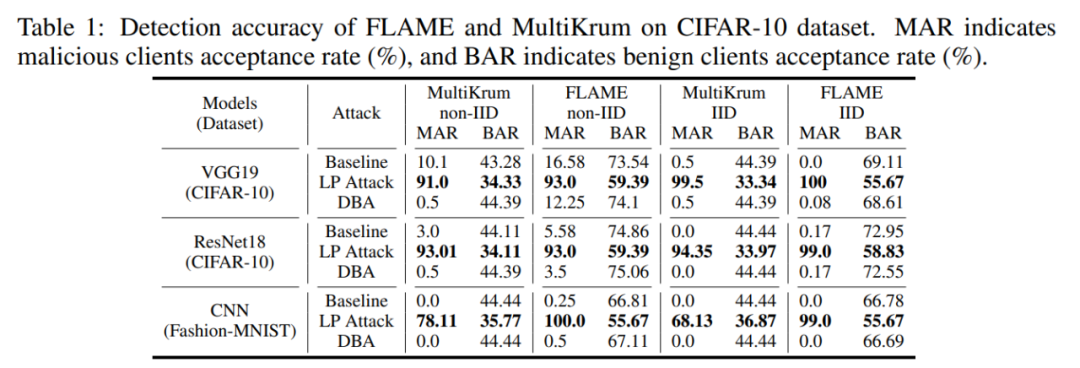
Dann kann LP Attack eine hohe Erfolgsquote bei Backdoor-Angriffen erzielen, selbst in einer Umgebung mit nur 10 % böswilligen Clients. Wie in der folgenden Tabelle gezeigt, kann LP Attack unter dem Schutz verschiedener Datensätze und verschiedener Verteidigungsmethoden eine hohe Erfolgsquote bei Backdoor-Angriffen (BSR) erzielen.
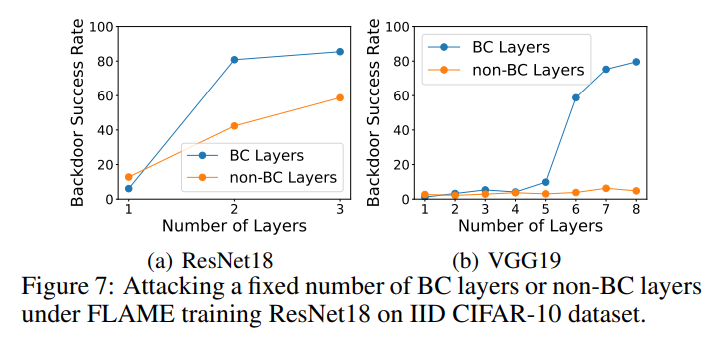
Im Ablationsexperiment hat dieser Artikel die Hintertür-Schlüsselschicht bzw. die Nicht-Hintertür-Schlüsselschicht vergiftet und die Erfolgsrate der Hintertür-Angriffe der beiden Experimente gemessen. Wie in der Abbildung unten gezeigt, ist die Erfolgsrate bei der Vergiftung von Nicht-Hintertür-Schlüsselschichten viel geringer als bei der Vergiftung von Hintertür-Schlüsselschichten. Dies zeigt, dass der Algorithmus in diesem Artikel einen wirksamen Hintertür-Angriffsschlüssel auswählen kann Lagen.
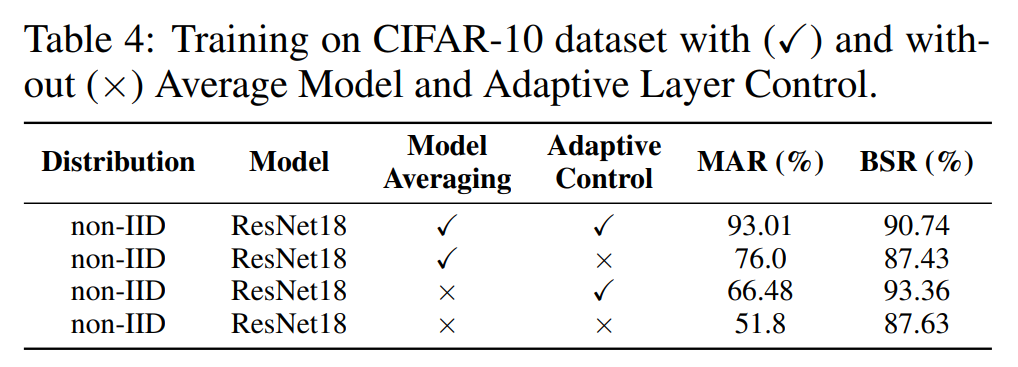
Darüber hinaus führen wir Ablationsexperimente zum Modellaggregationsmodul Model Averaging und zum adaptiven Steuerungsmodul Adaptive Control durch. Wie in der folgenden Tabelle gezeigt, verbessern beide Module die Auswahlrate und die Erfolgsquote von Backdoor-Angriffen, was die Wirksamkeit dieser beiden Module beweist.
Zusammenfassung
In diesem Artikel wurde festgestellt, dass Backdoor-Angriffe eng mit einigen Ebenen verbunden sind, und es wurde ein Algorithmus zur Suche nach Schlüsselebenen von Backdoor-Angriffen vorgeschlagen. In diesem Artikel wird ein schichtweiser Angriff auf den Schutzalgorithmus beim föderierten Lernen vorgeschlagen, bei dem Hintertüren zum Angriff auf Schlüsselschichten verwendet werden. Der vorgeschlagene Angriff deckt die Schwachstellen der aktuellen drei Arten von Verteidigungsmethoden auf, was darauf hindeutet, dass in Zukunft ausgefeiltere Verteidigungsalgorithmen erforderlich sein werden, um die Sicherheit des föderierten Lernens zu schützen.
Vorstellung des Autors
Zhuang Haomin hat einen Bachelor-Abschluss von der South China University of Technology. Er arbeitete als wissenschaftlicher Mitarbeiter im IntelliSys Laboratory der Louisiana State University und studiert derzeit an der University of Notre Dame. Die Hauptforschungsrichtungen sind Backdoor-Angriffe und gegnerische Musterangriffe.
Das obige ist der detaillierte Inhalt vonICLR 2024 |. Modellieren Sie kritische Schichten für föderierte Lern-Backdoor-Angriffe. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!