
Heim >Technologie-Peripheriegeräte >KI >Brechen Sie in die unterste Schicht der KI ein! Das Team von NUS Youyang verwendet ein Diffusionsmodell, um neuronale Netzwerkparameter zu konstruieren, LeCun gefällt es
Brechen Sie in die unterste Schicht der KI ein! Das Team von NUS Youyang verwendet ein Diffusionsmodell, um neuronale Netzwerkparameter zu konstruieren, LeCun gefällt es

- PHPznach vorne
- 2024-02-26 10:43:131209Durchsuche
Das Diffusionsmodell hat eine wichtige neue Anwendung eröffnet –
Genau wie Sora Videos generiert, generiert es Parameter für neuronale Netze und dringt direkt in die unterste Schicht der KI ein!
Dies ist das neueste Open-Source-Forschungsergebnis des Teams von Professor You Yang an der National University of Singapore zusammen mit UCB, Meta AI Laboratory und anderen Institutionen.

Konkret schlug das Forschungsteam ein Diffusionsmodell p(arameter)-diff zur Generierung neuronaler Netzwerkparameter vor.
Verwenden Sie es zum Generieren von Netzwerkparametern. Die Geschwindigkeit ist bis zu 44-mal schneller als beim direkten Training und die Leistung ist nicht minderwertig.
Nachdem das Modell veröffentlicht wurde, löste es schnell hitzige Diskussionen in der KI-Community aus. Experten im Kreis zeigten die gleiche erstaunliche Einstellung wie normale Menschen, als sie Sora sahen.
Einige Leute behaupteten sogar direkt, dies sei im Grunde gleichbedeutend mit der Schaffung neuer KI durch KI.

Sogar der KI-Riese LeCun lobte diese Leistung, nachdem er sie gesehen hatte, und sagte, dass es wirklich eine nette Idee sei.
Tatsächlich hat p-diff die gleiche Bedeutung wie Sora macht Sora zu einem Weltsimulator (der AGI aus einer Dimension annähert).
Und diese Arbeit, die Diffusion neuronaler Netze, kann Parameter im Modell generieren und hat das Potenzial, ein Meta-Weltklasse-Lerner/Optimierer zu werden, der sich von einer anderen neuen wichtigen Dimension in Richtung AGI bewegt.
 Zurück zum Thema: Wie generiert p-diff neuronale Netzwerkparameter?
Zurück zum Thema: Wie generiert p-diff neuronale Netzwerkparameter?
Kombination des Autoencoders mit dem Diffusionsmodell
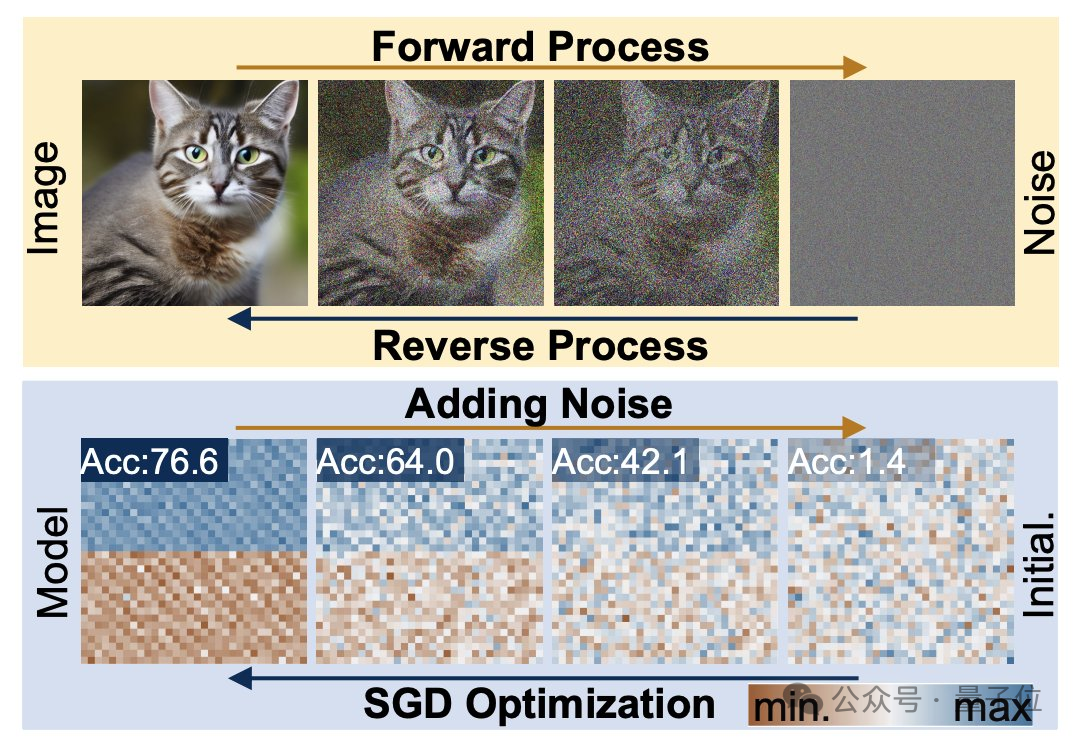
Um dieses Problem zu verstehen, müssen wir zunächst die Arbeitseigenschaften des Diffusionsmodells und des neuronalen Netzwerks verstehen.
Der Diffusionserzeugungsprozess ist die Umwandlung von einer Zufallsverteilung in eine hochspezifische Verteilung. Durch die Hinzufügung von zusammengesetztem Rauschen werden die visuellen Informationen auf eine einfache Rauschverteilung reduziert.
Das Training neuronaler Netze folgt ebenfalls diesem Transformationsprozess und kann durch Hinzufügen von Rauschen ebenfalls beeinträchtigt werden. Inspiriert durch diese Funktion schlugen Forscher die p-diff-Methode vor.
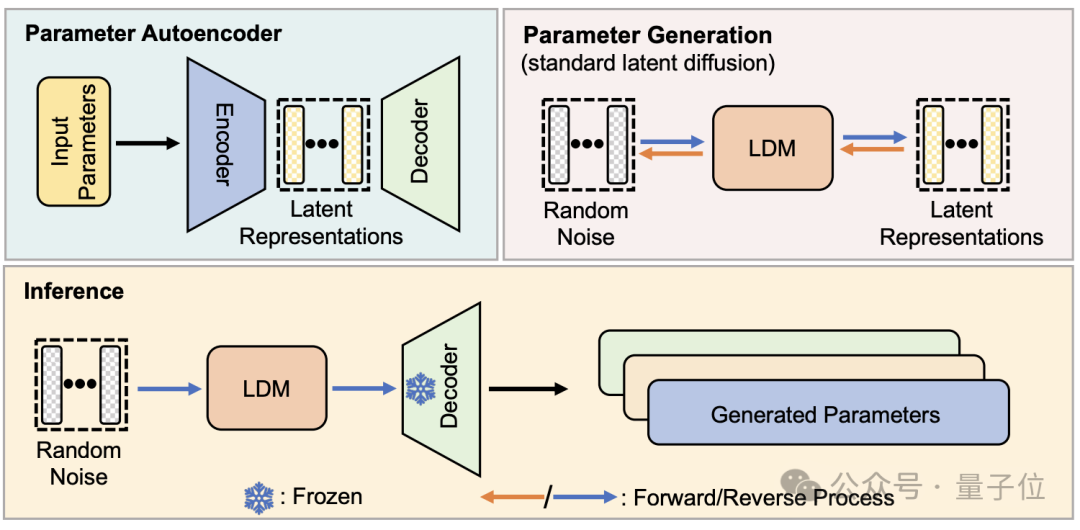
 Aus struktureller Sicht wurde p-diff vom Forschungsteam auf der Grundlage des Standardmodells der latenten Diffusion entworfen und mit dem Autoencoder kombiniert.
Aus struktureller Sicht wurde p-diff vom Forschungsteam auf der Grundlage des Standardmodells der latenten Diffusion entworfen und mit dem Autoencoder kombiniert.
Der Forscher wählt zunächst einen Teil der Netzwerkparameter aus, die gut trainiert und ausgeführt wurden, und erweitert sie in eine eindimensionale Vektorform.
Dann verwenden Sie den Autoencoder, um die latente Darstellung aus dem eindimensionalen Vektor als Trainingsdaten für das Diffusionsmodell zu extrahieren. Dadurch können die Schlüsselmerkmale der ursprünglichen Parameter erfasst werden.
Während des Trainingsprozesses ließen die Forscher p-diff die Verteilung von Parametern durch Vorwärts- und Rückwärtsprozesse erlernen. Nach Abschluss synthetisiert das Diffusionsmodell diese potenziellen Darstellungen aus zufälligem Rauschen, ähnlich dem Prozess der Generierung visueller Informationen.
Schließlich wird die neu generierte latente Darstellung durch den dem Encoder entsprechenden Decoder auf Netzwerkparameter zurückgesetzt und zum Erstellen eines neuen Modells verwendet.
 Die folgende Abbildung zeigt die Parameterverteilung des von Grund auf trainierten ResNet-18-Modells unter Verwendung von 3 zufälligen Startwerten durch p-diff und zeigt das Verteilungsmuster zwischen verschiedenen Schichten und zwischen verschiedenen Parametern in derselben Schicht.
Die folgende Abbildung zeigt die Parameterverteilung des von Grund auf trainierten ResNet-18-Modells unter Verwendung von 3 zufälligen Startwerten durch p-diff und zeigt das Verteilungsmuster zwischen verschiedenen Schichten und zwischen verschiedenen Parametern in derselben Schicht.
 Um die Qualität der von p-diff generierten Parameter zu bewerten, testeten die Forscher es an 8 Datensätzen unter Verwendung von 3 Arten neuronaler Netze mit jeweils zwei Größen.
Um die Qualität der von p-diff generierten Parameter zu bewerten, testeten die Forscher es an 8 Datensätzen unter Verwendung von 3 Arten neuronaler Netze mit jeweils zwei Größen.
In der folgenden Tabelle stellen die drei Zahlen in jeder Gruppe die Bewertungsergebnisse des Originalmodells, des integrierten Modells und des mit p-diff generierten Modells dar.
Wie Sie den Ergebnissen entnehmen können, liegt die Leistung des mit p-diff generierten Modells grundsätzlich nahe bei oder sogar besser als die Leistung des manuell trainierten Originalmodells.
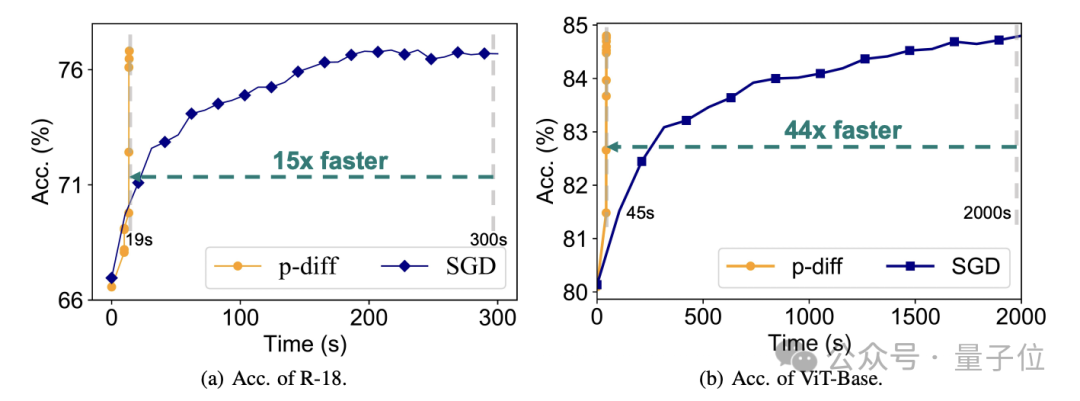
Was die Effizienz betrifft, ohne an Genauigkeit zu verlieren, generiert p-diff das ResNet-18-Netzwerk 15-mal schneller als herkömmliches Training und generiert Vit-Base 44-mal schneller.
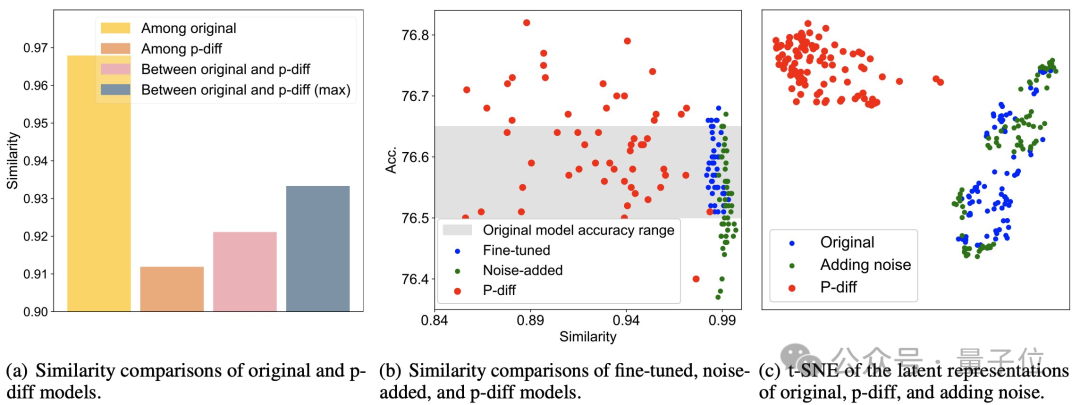
Zusätzliche Testergebnisse belegen, dass sich das von p-diff generierte Modell deutlich von den Trainingsdaten unterscheidet.
Wie Sie der Abbildung (a) unten entnehmen können, ist die Ähnlichkeit zwischen den von p-diff generierten Modellen geringer als die Ähnlichkeit zwischen den Originalmodellen sowie die Ähnlichkeit zwischen p-diff und dem Originalmodell.
Wie aus (b) und (c) ersichtlich ist, ist die Ähnlichkeit von p-diff im Vergleich zu Feinabstimmungs- und Rauschadditionsmethoden ebenfalls geringer.
Diese Ergebnisse zeigen, dass p-diff tatsächlich ein neues Modell generiert, anstatt nur Trainingsbeispiele zu speichern. Es zeigt auch, dass es über eine gute Generalisierungsfähigkeit verfügt und neue Modelle generieren kann, die sich von den Trainingsdaten unterscheiden.
Derzeit ist der Code von p-diff Open Source. Wenn Sie interessiert sind, können Sie ihn auf GitHub ausprobieren.
Papieradresse: https://arxiv.org/abs/2402.13144
GitHub: https://github.com/NUS-HPC-AI-Lab/Neural-Network-Diffusion
Das obige ist der detaillierte Inhalt vonBrechen Sie in die unterste Schicht der KI ein! Das Team von NUS Youyang verwendet ein Diffusionsmodell, um neuronale Netzwerkparameter zu konstruieren, LeCun gefällt es. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie schreibe ich einen Simulator mit JS?
- Welche Software ist KI?
- In welchem Jahr veröffentlichte Google sein maschinelles Übersetzungssystem für neuronale Netze?
- So legen Sie den Standard-Terminalemulator für Debian11 fest
- Liste der Blaufisch-Rezepte und -Effekte in „Demon Doll: Reincarnation Simulator'