
Heim >Technologie-Peripheriegeräte >KI >Google AI-Video ist wieder großartig! VideoPrism, ein universeller visueller All-in-One-Encoder, aktualisiert 30 SOTA-Leistungsfunktionen
Google AI-Video ist wieder großartig! VideoPrism, ein universeller visueller All-in-One-Encoder, aktualisiert 30 SOTA-Leistungsfunktionen

- WBOYnach vorne
- 2024-02-26 09:58:241206Durchsuche
Nachdem das KI-Videomodell Sora populär wurde, traten große Unternehmen wie Meta und Google beiseite, um Forschung zu betreiben und OpenAI nachzuholen.
Kürzlich haben Forscher des Google-Teams einen universellen Video-Encoder vorgeschlagen – VideoPrism.
Es kann verschiedene Videoverständnisaufgaben über ein einziges eingefrorenes Modell bewältigen.
 Bilder
Bilder
Papieradresse: https://arxiv.org/pdf/2402.13217.pdf
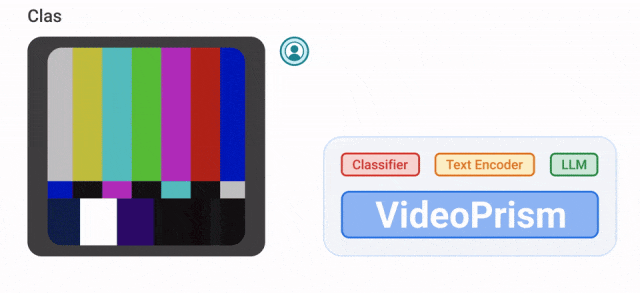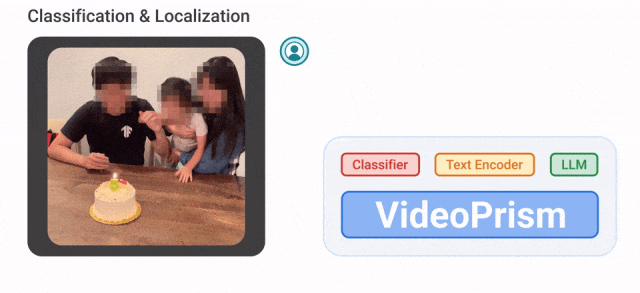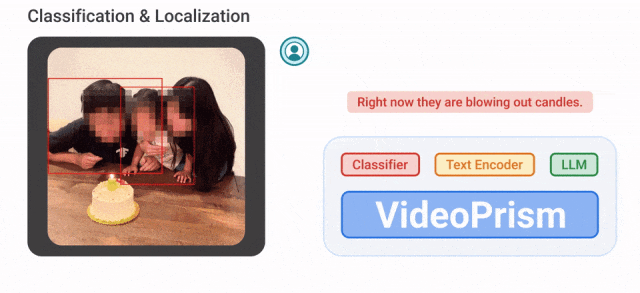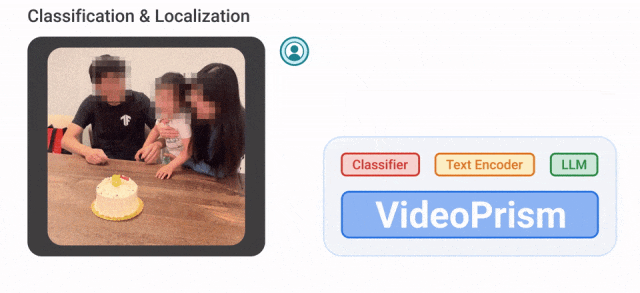
VideoPrism kann beispielsweise die Kerzen blasenden Personen im Video unten klassifizieren und lokalisieren.
 Bilder
Bilder
Video-Text-Abruf, basierend auf dem Textinhalt kann der entsprechende Inhalt im Video abgerufen werden.
 Bilder
Bilder
Beschreiben Sie als weiteres Beispiel das Video unten – ein kleines Mädchen spielt mit Bauklötzen.
Sie können auch Fragen und Antworten zur Qualitätssicherung durchführen.
- Welche Farbe hat der Block, den sie über den grünen Block gelegt hat?
- Lila.
 Bilder
Bilder
Die Forscher trainierten VideoPrism vorab anhand eines heterogenen Korpus, der 36 Millionen hochwertige Video-Untertitelpaare und 582 Millionen Videoclips mit verrauschtem Paralleltext (z. B. ASR-transkribierter Text) enthielt.
Es ist erwähnenswert, dass VideoPrism in 33 Benchmark-Tests zum Videoverständnis 30 SOTA aktualisiert hat.
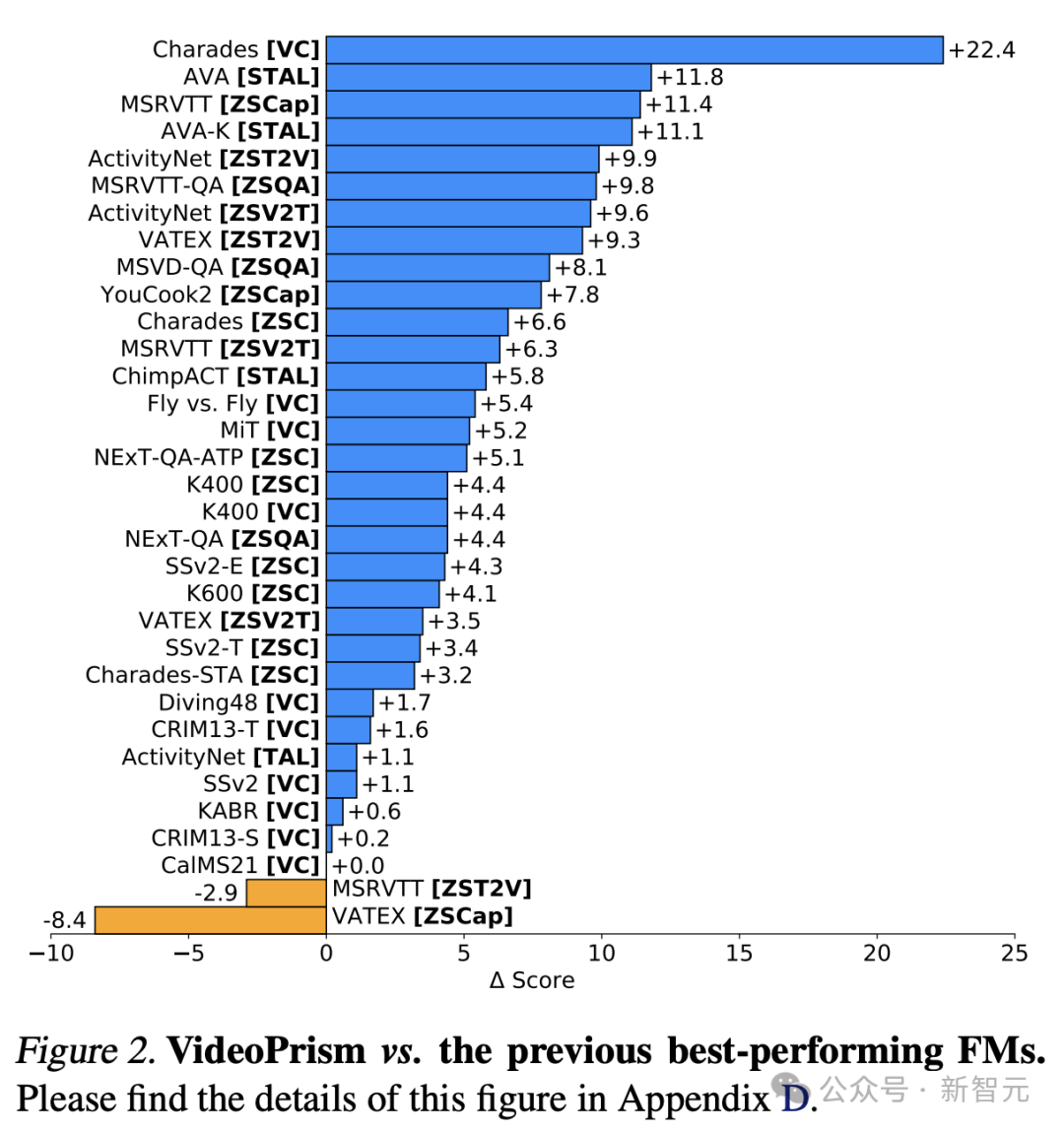 Bilder
Bilder
Universal Visual Encoder VideoPrism
Derzeit verfügt das Video Foundation Model (ViFM) über ein enormes Potenzial, neue Funktionen für große Unternehmen freizuschalten.
Obwohl frühere Forschungen beim allgemeinen Videoverständnis große Fortschritte gemacht haben, ist der Aufbau eines echten „grundlegenden Videomodells“ immer noch ein schwer erreichbares Ziel.
Als Reaktion darauf brachte Google VideoPrism auf den Markt, einen universellen visuellen Encoder, der eine Vielzahl von Videoverständnisaufgaben lösen soll, darunter Klassifizierung, Lokalisierung, Abruf, Untertitel und Fragebeantwortung (QA).
VideoPrism wird umfassend anhand von CV-Datensätzen sowie CV-Aufgaben in wissenschaftlichen Bereichen wie Neurowissenschaften und Ökologie evaluiert.
Erzielen Sie Spitzenleistungen bei minimaler Fitness, indem Sie ein einziges eingefrorenes Modell verwenden.
Darüber hinaus sagen Google-Forscher, dass diese eingefrorene Encoder-Einstellung gleichzeitig früheren Untersuchungen folgt und ihre praktische Anwendbarkeit sowie die hohen Kosten für die Berechnung und Feinabstimmung des Videomodells berücksichtigt.
 Bilder
Bilder
Designstruktur, zweistufige Trainingsmethode
Das Designkonzept hinter VideoPrism ist wie folgt.
Vortrainingsdaten sind die Grundlage des Basismodells (FM). Die idealen Vortrainingsdaten für ViFM sind eine repräsentative Stichprobe aller Videos auf der Welt.
In diesem Beispiel enthalten die meisten Videos keinen parallelen Text, der den Inhalt beschreibt.
Wenn es jedoch auf solchen Text trainiert wird, kann es unschätzbare semantische Hinweise auf den Videoraum liefern.
Daher sollte sich die Pre-Training-Strategie von Google in erster Linie auf den Videomodus konzentrieren und gleichzeitig alle verfügbaren Video-Text-Paare voll ausnutzen.
Auf der Datenseite haben Google-Forscher das erforderliche Vortraining angenähert, indem sie 36 Millionen hochwertige Video-Untertitelpaare und 582 Millionen Videoclips mit verrauschtem Paralleltext (z. B. ASR-Transkriptionen, generierte Untertitel und abgerufener Text) gebündelt haben.
 Bilder
Bilder
 Bilder
Bilder
In Bezug auf die Modellierung lernen die Autoren zunächst vergleichend semantische Videoeinbettungen aus allen Video-Text-Paaren unterschiedlicher Qualität.
Die semantischen Einbettungen werden dann global und mit umfangreichen reinen Videodaten verfeinert, wodurch die unten beschriebene maskierte Videomodellierung verbessert wird.
Trotz des Erfolgs in natürlicher Sprache bleibt die Modellierung maskierter Daten für CV aufgrund der fehlenden Semantik im rohen visuellen Signal eine Herausforderung.
Bestehende Forschung kombiniert hohe Maskierungsrate und geringes Gewicht, indem sie indirekte Semantik (z. B. die Verwendung von CLIP zur Führung von Modellen oder Tokenisierern oder implizite Semantik zur Bewältigung dieser Herausforderung) entlehnt oder sie implizit verallgemeinert (z. B. die Kennzeichnung visueller Patches) Decoder-Kombination.
Basierend auf den oben genannten Ideen hat das Google-Team einen zweistufigen Ansatz gewählt, der auf Daten vor dem Training basiert.
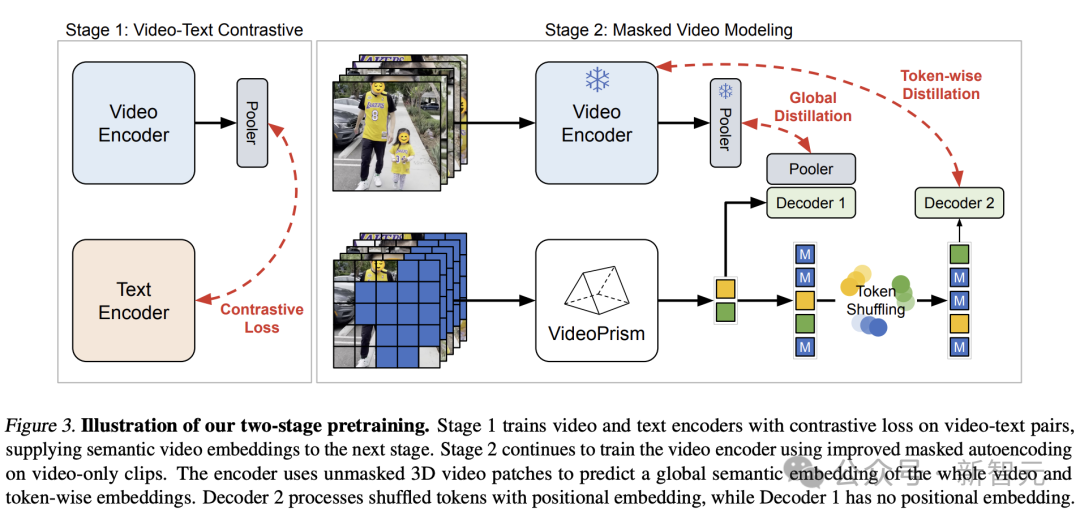 Bilder
Bilder
In der ersten Phase wird kontrastives Lernen durchgeführt, um den Video-Encoder unter Verwendung aller Video-Text-Paare am Text-Encoder auszurichten.
Basierend auf früheren Untersuchungen minimierte das Google-Team die Ähnlichkeitswerte aller Video-Text-Paare im Stapel und führte eine symmetrische Kreuzentropieverlustminimierung durch.
Und verwenden Sie das Bildmodell von CoCa, um das räumliche Kodierungsmodul zu initialisieren und WebLI in das Vortraining zu integrieren.
Vor der Berechnung des Verlusts werden die Funktionen des Video-Encoders durch Multi-Head Attention Pooling (MAP) aggregiert.
Diese Stufe ermöglicht es dem Video-Encoder, umfangreiche visuelle Semantik durch linguistische Aufsicht zu erlernen, und das resultierende Modell stellt semantische Videoeinbettungen für das Training der zweiten Stufe bereit.
 Bilder
Bilder
In der zweiten Stufe wird der Encoder weiter trainiert und es werden zwei Verbesserungen vorgenommen:
- Das Modell muss die globale Einbettung und das Token der ersten Stufe auf Videoebene basierend auf unmaskierten Eingaben vorhersagen Video-Patches einbetten
– Das Ausgabetoken des Encoders wird zufällig gemischt, bevor es an den Decoder übergeben wird, um das Lernen von Verknüpfungen zu vermeiden.
Bemerkenswert ist, dass das Vortraining der Forscher zwei Überwachungssignale nutzt: die Textbeschreibung des Videos und die kontextbezogene Selbstüberwachung, sodass VideoPrism bei erscheinungs- und aktionsorientierten Aufgaben eine gute Leistung erbringen kann.
Tatsächlich zeigen frühere Untersuchungen, dass Videountertitel hauptsächlich Hinweise auf das Aussehen offenbaren, während kontextbezogene Überwachung dabei hilft, Handlungen zu erlernen.
 Bilder
Bilder
Experimentelle Ergebnisse
Als nächstes bewerteten die Forscher VideoPrism anhand einer breiten Palette videozentrierter Verständnisaufgaben und demonstrierten seine Fähigkeiten und Allgemeingültigkeit.
Hauptsächlich in die folgenden vier Kategorien unterteilt:
(1) Im Allgemeinen nur Videoverständnis, einschließlich Klassifizierung und räumlich-zeitlicher Positionierung
(2) Zero-Shot-Videotextabruf
(3) Zero-Shot-Videountertitel und Qualitätsprüfung
(4) Lebenslaufaufgaben in der Wissenschaft
Klassifizierung und raumzeitliche Lokalisierung
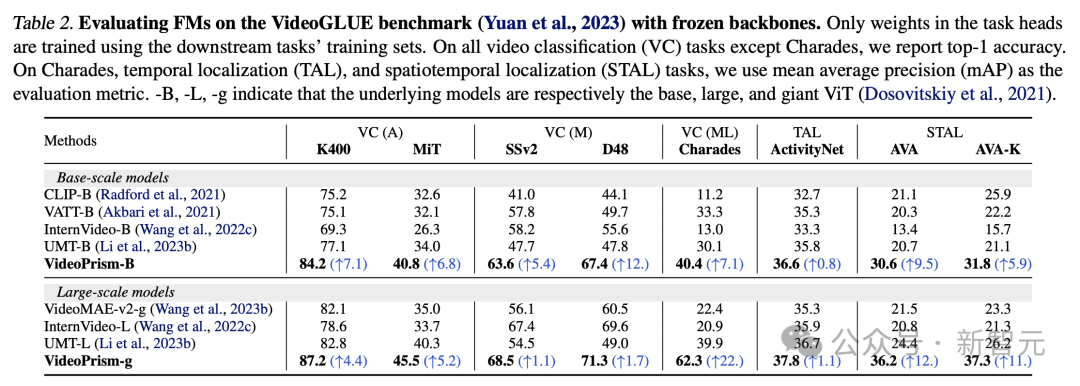
Tabelle 2 zeigt die Ergebnisse von Frozen Backbone auf VideoGLUE.
VideoPrism übertrifft die Basislinie bei allen Datensätzen deutlich. Darüber hinaus verbessert die Erhöhung der zugrunde liegenden Modellgröße von VideoPrism von ViT-B auf ViT-g die Leistung erheblich.
Es ist erwähnenswert, dass keine Basismethode bei allen Benchmarks das zweitbeste Ergebnis erzielt, was darauf hindeutet, dass frühere Methoden möglicherweise entwickelt wurden, um auf bestimmte Aspekte des Videoverständnisses abzuzielen.
Und VideoPrism verbessert dieses breite Aufgabenspektrum weiter.
Dieses Ergebnis zeigt, dass VideoPrism verschiedene Videosignale in einen Encoder integriert: Semantik mit mehreren Granularitäten, Erscheinungsbild- und Bewegungshinweise, räumlich-zeitliche Informationen und Robustheit gegenüber verschiedenen Videoquellen (z. B. Online-Videos und geskriptete Darbietungen).
 Bild
Bild
Zero-Shot-Videotextabruf und -klassifizierung
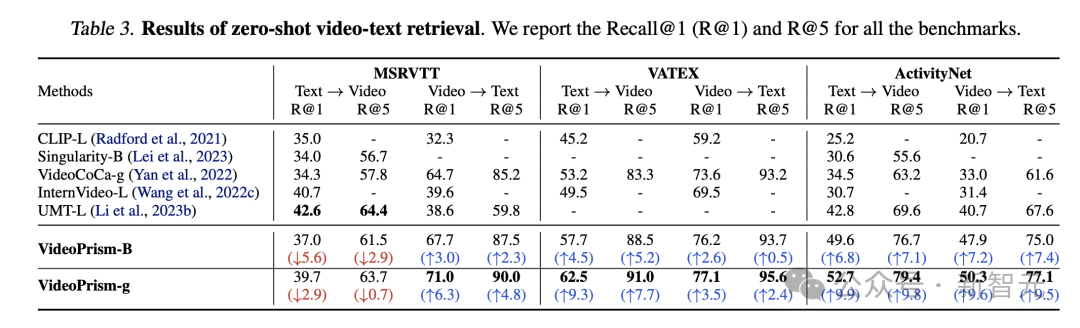
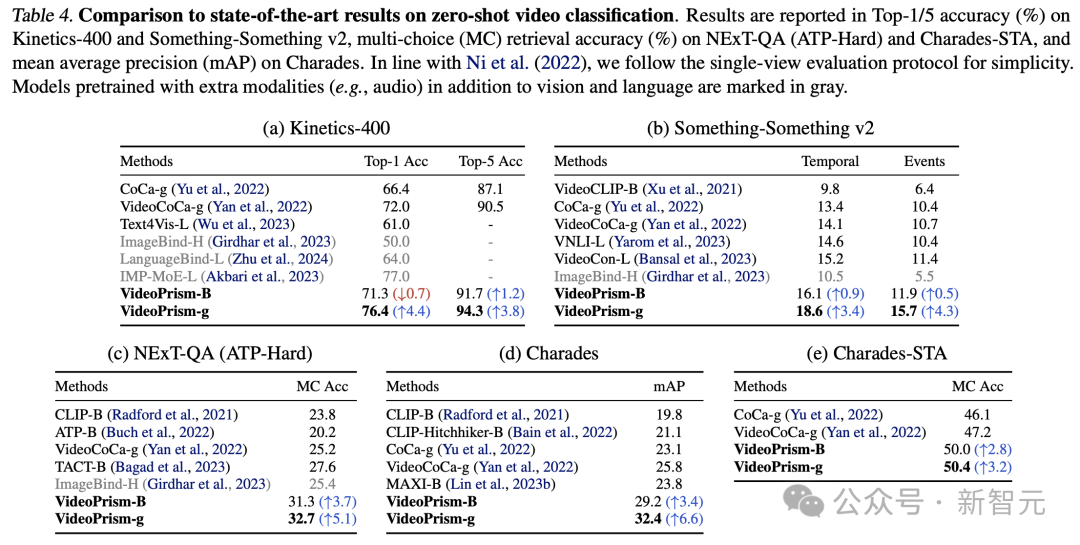
Tabelle 3 und Tabelle 4 fassen die Ergebnisse des Videotextabrufs bzw. der Videoklassifizierung zusammen.
Die Leistung von VideoPrism aktualisiert mehrere Benchmarks und bei anspruchsvollen Datensätzen hat VideoPrism im Vergleich zu früheren Technologien sehr deutliche Verbesserungen erzielt.
 Bilder
Bilder
Die meisten Ergebnisse für das Basismodell VideoPrism-B übertreffen tatsächlich bestehende größere Modelle.
Darüber hinaus ist VideoPrism mit den Modellen in Tabelle 4 vergleichbar oder sogar besser als diese, die mit domäneninternen Daten und zusätzlichen Modalitäten (z. B. Audio) vortrainiert wurden. Diese Verbesserungen bei Zero-Shot-Retrieval- und Klassifizierungsaufgaben spiegeln die leistungsstarken Generalisierungsfähigkeiten von VideoPrism wider.
 Bilder
Bilder
Zero-Sample-Videountertitel und Qualitätsprüfung
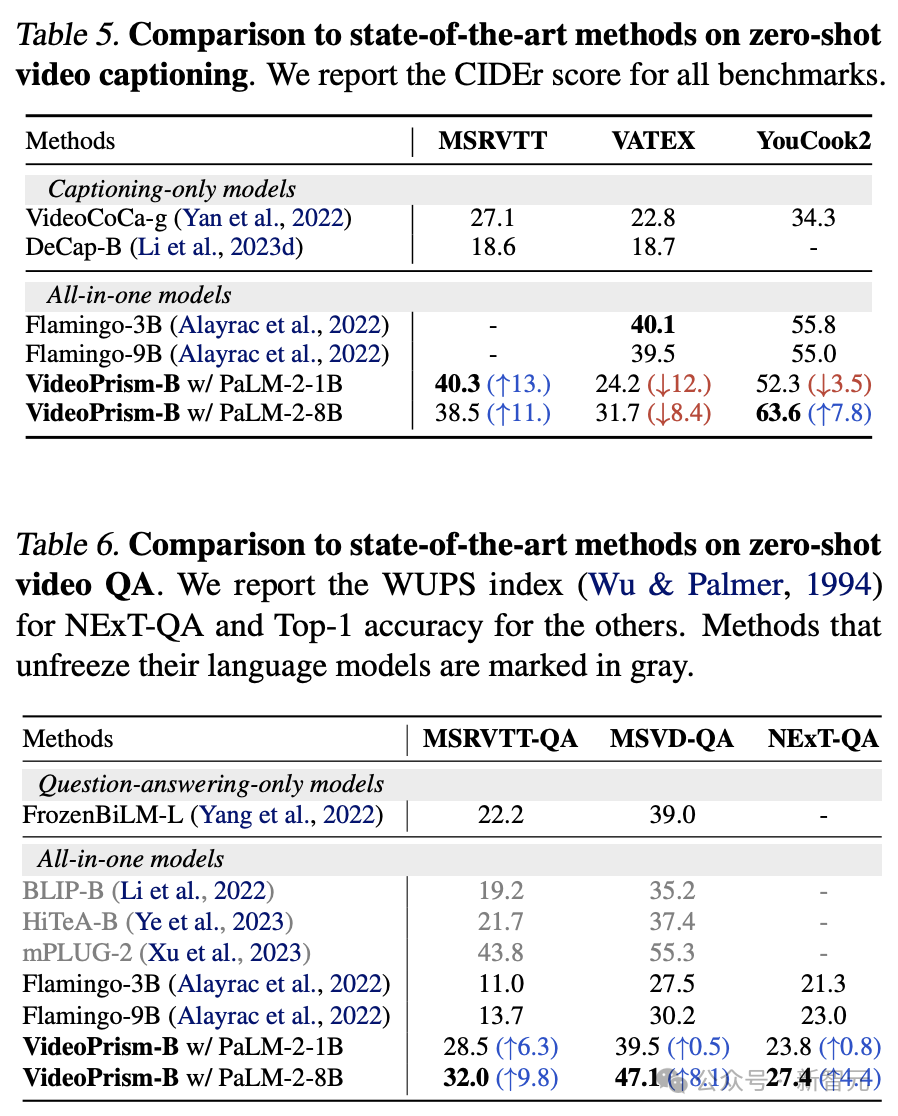
Tabelle 5 und Tabelle 6 zeigen jeweils die Ergebnisse von Zero-Sample-Videountertiteln und der Qualitätssicherung.
Trotz der einfachen Modellarchitektur und der geringen Anzahl an Adapterparametern sind die neuesten Modelle immer noch konkurrenzfähig und zählen mit Ausnahme von VATEX zu den Top-Methoden zum Einfrieren visueller und sprachlicher Modelle.
Die Ergebnisse zeigen, dass sich der VideoPrism-Encoder gut für Aufgaben zur Video-zu-Sprache-Generierung eignet.
 Bilder
Bilder
CV-Aufgaben in wissenschaftlichen Bereichen
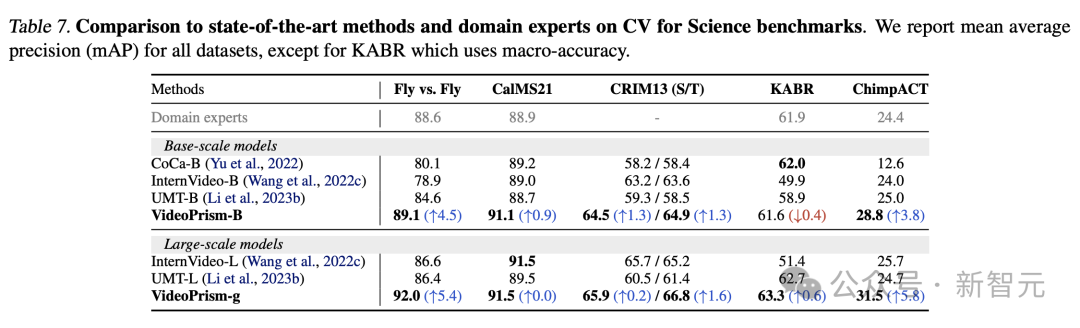
Universal ViFM verwendet einen gemeinsamen eingefrorenen Encoder für alle Auswertungen, mit einer Leistung, die mit domänenspezifischen Modellen für eine einzelne Aufgabe vergleichbar ist.
Insbesondere VideoPrism schneidet oft am besten ab und übertrifft Domänenexpertenmodelle mit Basismodellen.
Durch die Skalierung auf große Modelle kann die Leistung aller Datensätze weiter verbessert werden. Diese Ergebnisse zeigen, dass ViFM das Potenzial hat, die Videoanalyse in verschiedenen Bereichen erheblich zu beschleunigen.
Ablationsstudie
Abbildung 4 zeigt die Ablationsergebnisse. Insbesondere die kontinuierlichen Verbesserungen von VideoPrism gegenüber SSv2 zeigen die Wirksamkeit der Datenverwaltung und Modelldesignbemühungen bei der Förderung des Bewegungsverständnisses in Videos.
Obwohl die Vergleichsbasislinie auf K400 bereits konkurrenzfähige Ergebnisse erzielt hat, verbessern die vorgeschlagene globale Destillation und das Token-Shuffling die Genauigkeit weiter.
 Bilder
Bilder
Referenzen:
https://arxiv.org/pdf/2402.13217.pdf
https://blog.research.google/2024/02/videoprism-foundational-visual-encoder .html
Das obige ist der detaillierte Inhalt vonGoogle AI-Video ist wieder großartig! VideoPrism, ein universeller visueller All-in-One-Encoder, aktualisiert 30 SOTA-Leistungsfunktionen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!