
Heim > Artikel > Technologie-Peripheriegeräte > Entwurf und Implementierung eines leistungsstarken LLM-Inferenz-Frameworks
Entwurf und Implementierung eines leistungsstarken LLM-Inferenz-Frameworks

- WBOYnach vorne
- 2024-02-26 09:52:29657Durchsuche
1. Überblick über die Inferenz großer Sprachmodelle. Der nach der Initiierung jeder Anfrage generierte Argumentationsprozess durchläuft zunächst einen Prefill-Prozess. Der Prefill-Prozess berechnet alle Eingaben des Benutzers und generiert den entsprechenden KV-Cache. Anschließend durchläuft der Server mehrere Decodierungsprozesse Generieren Sie ein Zeichen, legen Sie es in den KV-Cache und iterieren Sie dann nacheinander.

Im Prefill-Prozess müssen zwar viele Berechnungen durchgeführt werden, da alle vom Benutzer eingegebenen Wörter gleichzeitig berechnet werden müssen, dies ist jedoch nur ein einmaliger Vorgang. Daher macht Prefill im gesamten Inferenzprozess nur weniger als 10 % der Zeit aus.
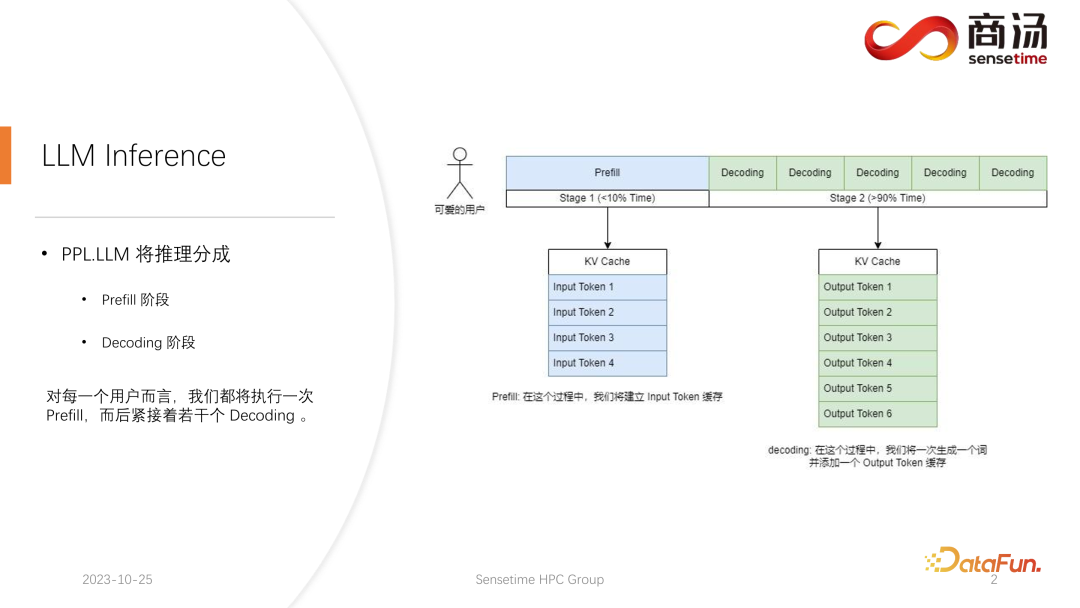
Bei der groß angelegten Sprachmodellinferenz gibt es normalerweise vier Schlüsselmetriken, auf die man sich konzentrieren muss: Durchsatz, Latenz des ersten Wortes, Gesamtlatenz und Anfragen pro Sekunde (QPS). Diese Leistungsindikatoren bewerten die Servicefähigkeiten des Systems aus verschiedenen Perspektiven. Der Durchsatz misst, wie schnell und effizient ein System Anfragen bearbeitet, während sich die Latenz des ersten Wortes auf die Zeit bezieht, die das System benötigt, um sein erstes Token zu generieren. Die Gesamtlatenz ist die Zeit, die das System benötigt, um die gesamte Inferenzaufgabe abzuschließen. Schließlich stellt QPS die Anzahl der Anfragen dar, die das System pro Sekunde verarbeitet. Diese Metriken spielen eine Schlüsselrolle bei der Bewertung der Modellleistung und Systemoptimierung und tragen dazu bei, sicherzustellen, dass das System verschiedene Inferenzaufgaben effizient bewältigen kann.
Lassen Sie uns zunächst den Durchsatz vorstellen. Auf der Modellinferenzebene sollte man sich zunächst auf den Durchsatz konzentrieren. Der Durchsatz bezieht sich darauf, wie viele Dekodierungen pro Zeiteinheit durchgeführt werden können, wenn die Systemlast ihr Maximum erreicht, also wie viele Zeichen generiert werden. Um den Durchsatz zu testen, wird davon ausgegangen, dass alle Benutzer gleichzeitig ankommen und dass diese Benutzer dieselbe Frage stellen. Diese Benutzer können gleichzeitig beginnen und enden sowie die Länge des von ihnen generierten Textes Der Eingabetext ist derselbe. Eine vollständige Charge wird gebildet, indem genau derselbe Input verwendet wird. In diesem Fall wird der Systemdurchsatz maximiert. Diese Situation ist jedoch unrealistisch, es handelt sich also um ein theoretisches Maximum. Wir messen, wie viele unabhängige Dekodierungsschritte das System in einer Sekunde durchführen kann.
Ein weiterer wichtiger Indikator ist die First Token Latency, also die Zeit, die ein Benutzer benötigt, um die Prefill-Phase nach dem Eintritt in das Inferenzsystem abzuschließen. Dies bezieht sich auf die Reaktionszeit des Systems zur Generierung des ersten Zeichens. Viele Benutzer erwarten, innerhalb von 2-3 Sekunden nach Eingabe einer Frage in das System eine Antwort zu erhalten.
Eine weitere wichtige Kennzahl ist die Latenz. Die Latenz stellt die für jeden Dekodierungsvorgang erforderliche Zeit dar, die das Zeitintervall widerspiegelt, das ein großes Sprachmodellsystem benötigt, um jedes Zeichen während der Echtzeitverarbeitung zu generieren, sowie die Glätte des Generierungsprozesses. Normalerweise möchten wir, dass die Latenz unter 50 Millisekunden bleibt, was bedeutet, dass wir 20 Zeichen pro Sekunde generieren können. Auf diese Weise wird der Generierungsprozess großer Sprachmodelle reibungsloser.
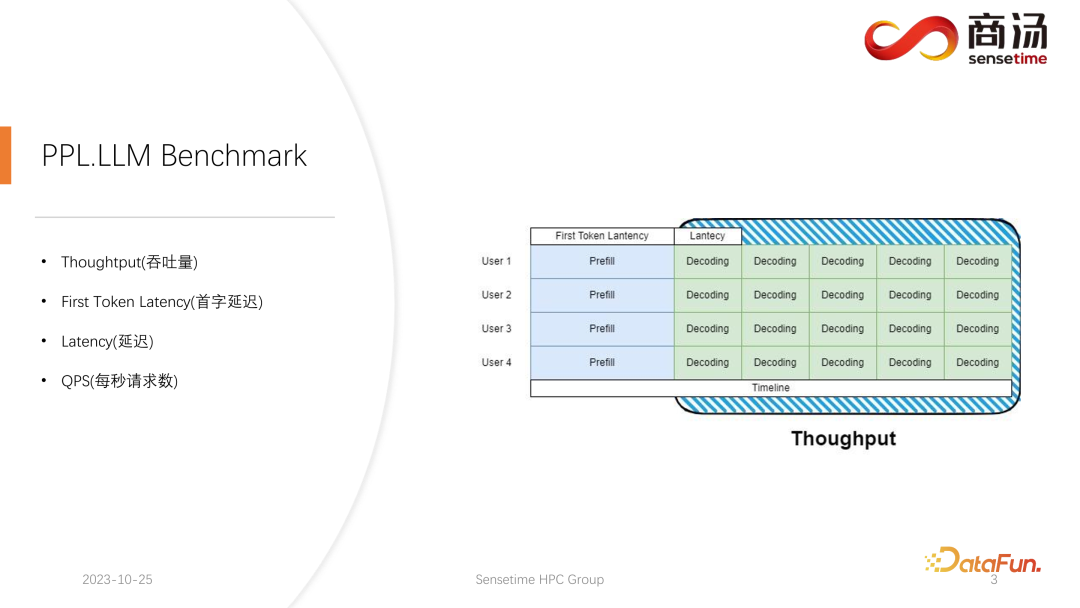
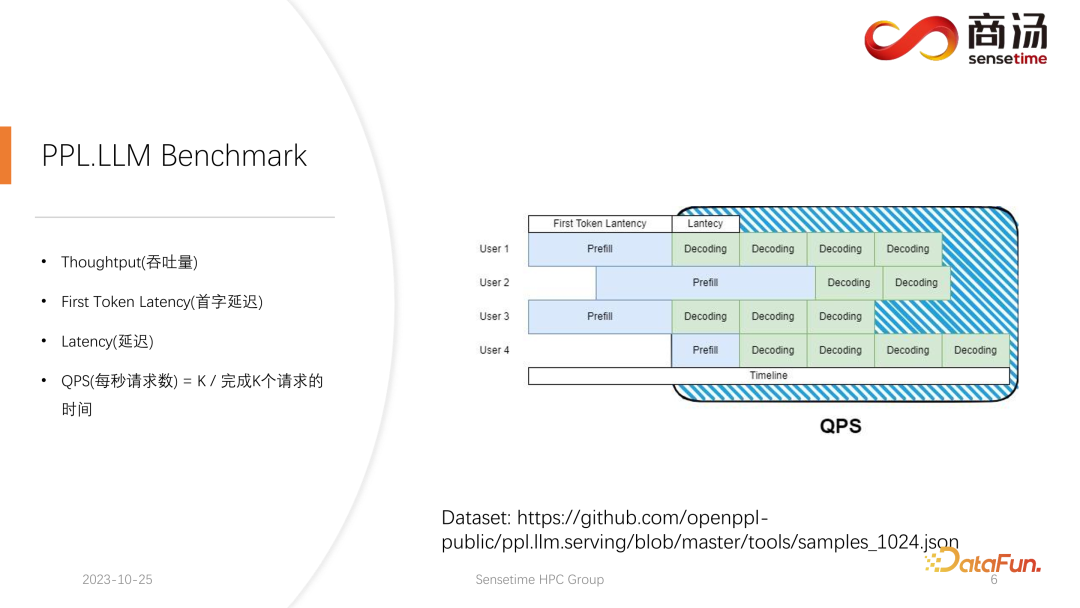
Die letzte Metrik ist QPS (Anfragen pro Sekunde). Sie gibt an, wie viele Benutzeranfragen in Online-Systemdiensten in einer Sekunde verarbeitet werden können. Die Messmethode dieses Indikators ist relativ komplex und wird später vorgestellt.
Wir haben relativ vollständige Tests sowohl für die Latenz des ersten Tokens als auch für die Latenzindikatoren durchgeführt. Diese beiden Indikatoren werden sich aufgrund der unterschiedlichen Länge der Benutzereingaben und der unterschiedlichen Chargengrößen stark ändern.
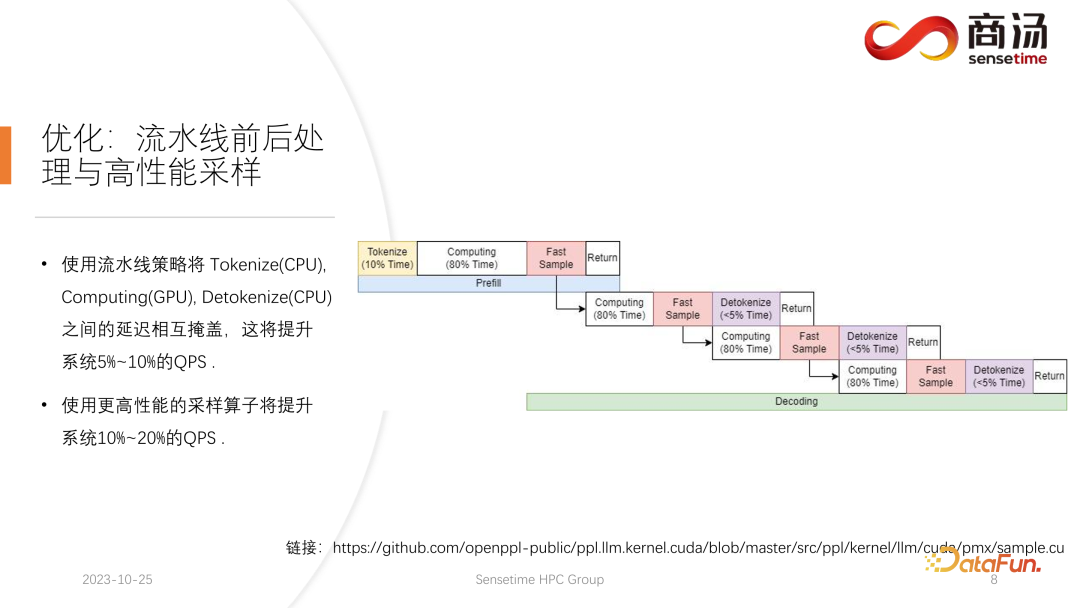
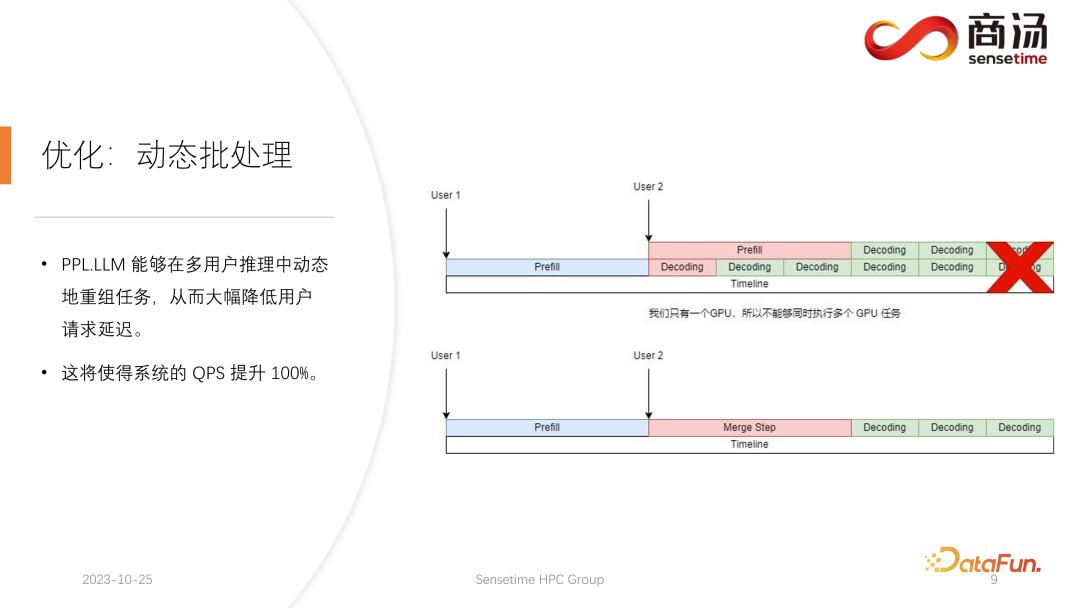
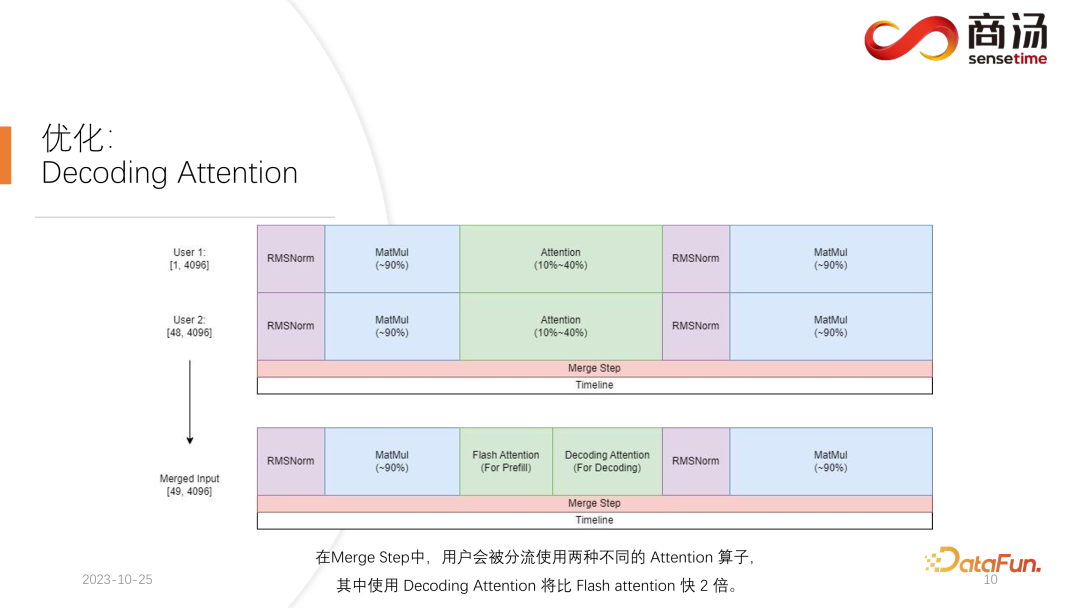
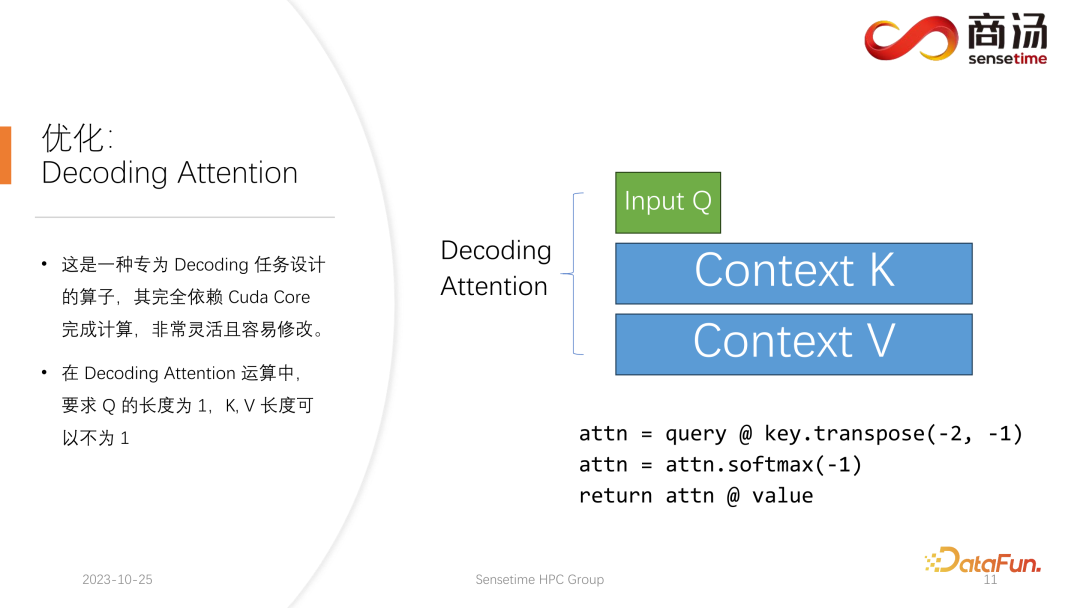
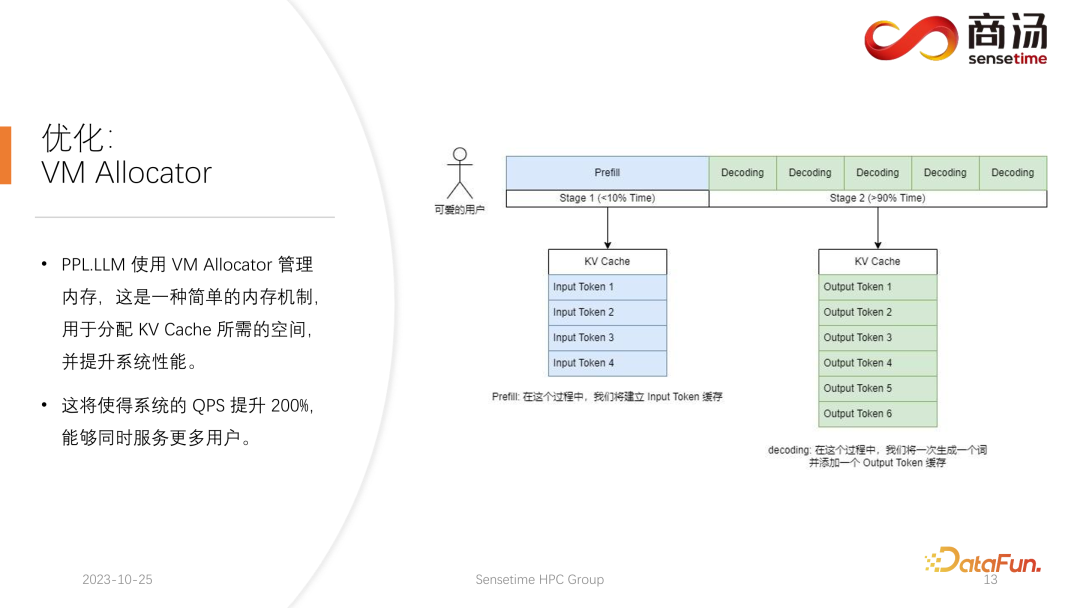
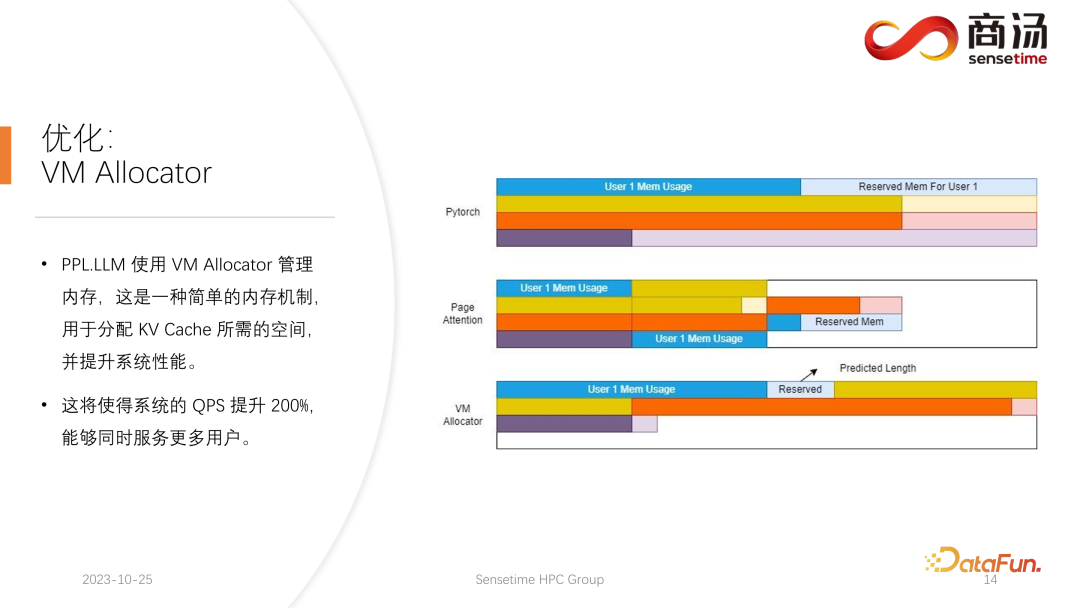
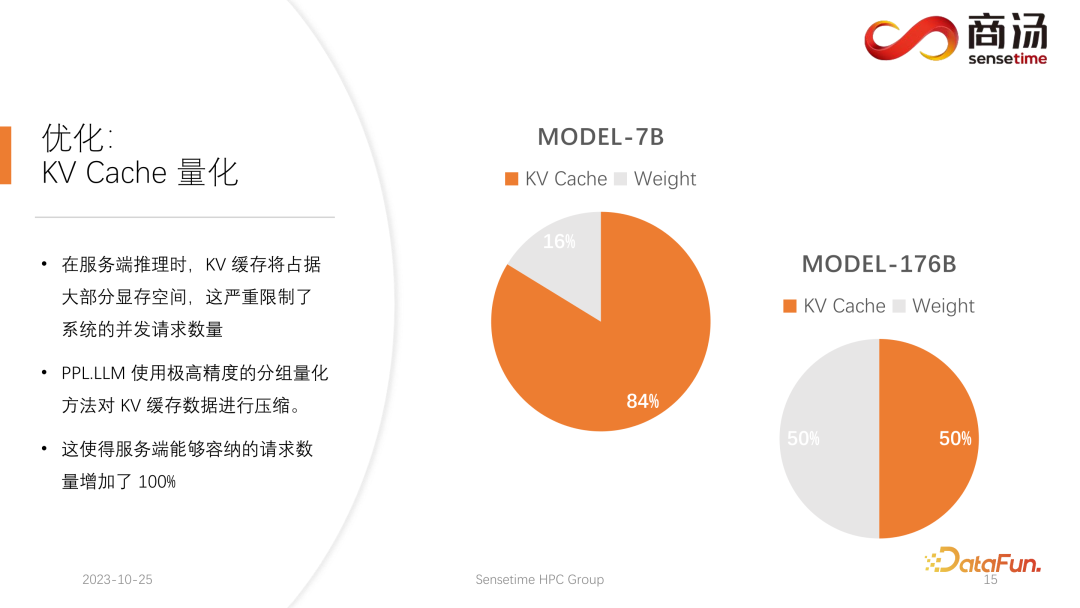
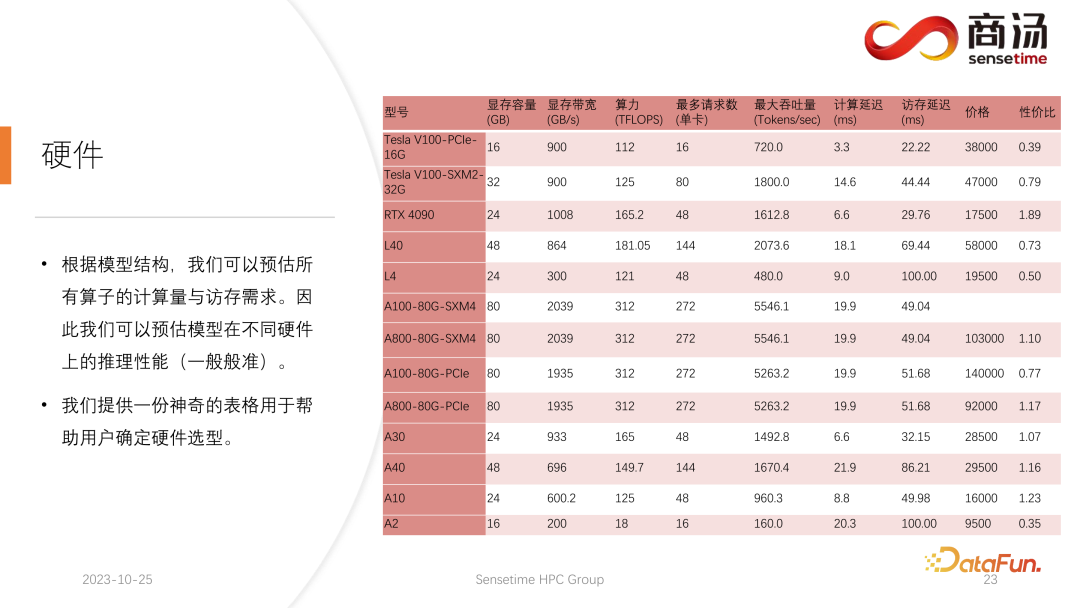
Wie Sie in der obigen Tabelle sehen können, beträgt die Vorfüllzeit für dasselbe 7B-Modell, wenn sich die Eingabelänge des Benutzers von 8 auf 2048 ändert, von 6,78 Millisekunden bis sie 2078 Millisekunden erreicht, was 2 Sekunden entspricht. Wenn es 80 Benutzer gibt und jeder Benutzer 1.024 Wörter eingibt, dauert die Ausführung von Prefill auf dem Server etwa 2 Sekunden, was außerhalb des akzeptablen Bereichs liegt. Wenn die Benutzereingabelänge jedoch sehr kurz ist, beispielsweise nur 8 Wörter pro Besuch eingegeben werden, beträgt die Verzögerung des ersten Wortes selbst bei gleichzeitigem Eintreffen von 768 Benutzern nur etwa 165 Millisekunden. Das Wichtigste für die Verzögerung des ersten Wortes ist die Eingabelänge des Benutzers. Je länger die Eingabelänge des Benutzers ist, desto höher ist die Verzögerung des ersten Wortes. Wenn die Benutzereingabelänge kurz ist, wird die Verzögerung des ersten Wortes nicht zu einem Engpass im gesamten Inferenzprozess des großen Sprachmodells. Was die nachfolgende Dekodierungsverzögerung betrifft, so wird die Dekodierungsverzögerung normalerweise innerhalb von 50 Millisekunden gesteuert, solange es sich nicht um ein 100-Milliarden-Level-Modell handelt. Dies wird hauptsächlich von der Chargengröße beeinflusst, desto größer ist die Inferenzverzögerung, aber im Grunde wird der Anstieg nicht sehr hoch sein. Der Durchsatz wird tatsächlich von diesen beiden Faktoren beeinflusst. Wenn die Länge der Benutzereingabe und die generierte Länge sehr groß sind, ist der Systemdurchsatz nicht sehr hoch. Wenn sowohl die vom Benutzer eingegebene Länge als auch die generierte Länge nicht sehr lang sind, kann der Systemdurchsatz ein sehr lächerliches Niveau erreichen. Schauen wir uns noch einmal QPS an. QPS ist eine sehr spezifische Kennzahl, die angibt, wie viele Anfragen pro Sekunde das System verarbeiten kann. Bei der Durchführung dieses Tests verwenden wir tatsächliche Daten. (Wir haben diese Daten bereits abgetastet und auf Github gestellt.) Die QPS-Messung unterscheidet sich vom Durchsatz, denn wenn tatsächlich ein großes Sprachmodellsystem verwendet wird, kommt jeder Benutzer. Die Zeit ist ungewiss. Einige Benutzer kommen möglicherweise zu früh, andere zu spät, und die Länge der Generation, nachdem jeder Benutzer Prefill abgeschlossen hat, ist ebenfalls ungewiss. Einige Benutzer brechen möglicherweise ab, nachdem sie 4 Wörter generiert haben, während andere möglicherweise mehr als 20 Wörter generieren müssen. Da Benutzer in der Prefill-Phase tatsächlich unterschiedliche Längen generieren, stoßen sie in der tatsächlichen Online-Inferenz auf ein Problem: Einige Benutzer generieren sie im Voraus, während andere erst dann aufhören, wenn sie eine große Länge generieren. Während eines Builds wie diesem gibt es viele Stellen, an denen die GPU im Leerlauf ist. Daher kann unser QPS im eigentlichen Inferenzprozess den Durchsatz nicht voll ausnutzen. Unser Durchsatz mag groß sein, aber die tatsächliche Rechenleistung ist möglicherweise schlecht, da die Verarbeitung voller Lücken ist und die Grafikkarte nicht genutzt werden kann. Daher verfügen wir in Bezug auf den QPS-Indikator über viele spezifische Optimierungslösungen, um Berechnungslücken oder die Unfähigkeit, die Grafikkarte effektiv zu nutzen, zu vermeiden, sodass der Durchsatz den Benutzern voll zur Verfügung stehen kann. Geben Sie als Nächstes den Inferenzprozess des großen Sprachmodells ein, um zu sehen, welche Optimierungen wir vorgenommen haben, damit das System vergleichbare Ergebnisse in Bezug auf QPS, Durchsatz und anderes erzielt Indikatoren. Hervorragende Situation. Lassen Sie uns zunächst den Inferenzprozess des großen Sprachmodells im Detail vorstellen. Wie im vorherigen Artikel erwähnt, muss jede Anfrage die beiden Phasen des Vorfüllens und der Dekodierung durchlaufen . In der Vorabfüllungsphase müssen mindestens vier Dinge getan werden: Der erste Schritt besteht darin, die Eingabe des Benutzers in einen Vektor umzuwandeln In der ersten Phase nimmt es wahrscheinlich 10 % der Zeit in Anspruch, aber das hat seinen Preis. Die eigentliche Vorbelegungsberechnung wird dann durchgeführt und dieser Vorgang wird etwa 80 % der Zeit in Anspruch nehmen. Nach der Berechnung wird die Probenahme durchgeführt. Dieser Prozess verwendet im Allgemeinen Probe und Top-P in Pytorch. Argmax wird bei der Inferenz großer Sprachmodelle verwendet. Alles in allem handelt es sich um einen Prozess, bei dem das endgültige Wort auf der Grundlage der Ergebnisse des Modells generiert wird. Dieser Vorgang nimmt 10 % der Zeit in Anspruch. Abschließend wird das Nachfüllergebnis an den Kunden zurückgesendet, was relativ kurze Zeit in Anspruch nimmt, etwa 2 % bis 5 % der Zeit. Die Dekodierungsphase erfordert keine Tokenisierung. Jedes Mal, wenn Sie eine Dekodierung durchführen, wird der gesamte Dekodierungsprozess 80 % der Zeit in Anspruch nehmen, und das anschließende Abtasten, also der Prozess des Abtastens und Generierens von Wörtern , wird auch 10 % der Zeit in Anspruch nehmen. Das Detokenisieren bedeutet jedoch, dass das generierte Wort ein Vektor ist und wieder in Text umgewandelt werden muss. Dieser Vorgang nimmt schließlich etwa 5 % der Zeit in Anspruch be Zurück zum Benutzer. Wenn nach dem Vorabfüllen eine neue Anfrage eingeht, wird die Dekodierung iterativ durchgeführt. Nach jeder Dekodierungsstufe werden die Ergebnisse sofort an den Kunden zurückgegeben. Dieser Generierungsprozess ist in großen Sprachmodellen sehr verbreitet und wir nennen diese Methode Streaming. Die erste Optimierung, die hier vorgestellt wird, ist die Pipeline-Optimierung, deren Zweck darin besteht, die Grafikkartenauslastung zu maximieren. Im Prozess der Inferenz großer Sprachmodelle haben die Prozesse Tokenisieren, schnelles Abtasten und Detokenisieren nichts mit der Berechnung des Modells zu tun. Wir können uns die Argumentation des gesamten großen Sprachmodells als einen solchen Prozess vorstellen, nachdem ich den Wortvektor des schnellen Beispiels erhalten habe, kann ich sofort mit der nächsten Dekodierungsstufe beginnen, ohne auf das Ergebnis warten zu müssen zurückgegeben, da das Ergebnis bereits auf der GPU vorhanden war. Wenn eine Dekodierung abgeschlossen ist, muss nicht auf den Abschluss der Detokenisierung gewartet werden, und die nächste Dekodierung kann sofort gestartet werden. Da es sich bei der Detokenisierung um einen CPU-Prozess handelt, beinhalten die beiden letztgenannten Prozesse nur die Rückgabe von Ergebnissen an den Benutzer und keine GPU-Vorgänge. Und nachdem wir den Sampling-Prozess ausgeführt haben, wissen wir bereits, was das nächste generierte Wort ist. Wir haben alle benötigten Daten erhalten und können sofort mit der nächsten Operation beginnen, ohne auf den Abschluss der nächsten beiden Prozesse warten zu müssen. Bei der Implementierung von PPL.LLM werden drei Thread-Pools verwendet: Der erste Thread-Pool ist für die Ausführung des Tokenisierungsprozesses verantwortlich; Der dritte Thread-Pool ist für die Ausführung des nachfolgenden schnellen Beispiels verantwortlich Rückgabe der Ergebnisse Der Prozess und Detokenisierung Der Thread-Pool in der Mitte wird zum Ausführen des Rechenprozesses verwendet. Diese drei Thread-Pools isolieren diese drei Teile der Verzögerung asynchron voneinander und maskieren so diese drei Teile der Verzögerung so weit wie möglich. Dies führt zu einer QPS-Verbesserung des Systems um 10 bis 20 %. Dies ist die erste Optimierung, die wir durchführen. Danach kann PPL.LLM auch eine interessantere Optimierung namens dynamische Stapelverarbeitung durchführen. Wie bereits erwähnt, ist im eigentlichen Argumentationsprozess die Länge der Benutzergenerierung unterschiedlich und auch die Ankunftszeit des Benutzers ist unterschiedlich. Daher kann es vorkommen, dass, wenn sich die aktuelle GPU im Inferenzprozess befindet, bereits in der Mitte der Inferenz eine zweite Anfrage eingefügt wird Konflikte mit dem Generierungsprozess der ersten Anfrage. Da wir nur eine GPU haben und Aufgaben nur seriell auf dieser GPU ausführen können, können wir sie nicht einfach auf der GPU parallelisieren. Was wir tun, ist, zu dem Zeitpunkt, an dem die zweite Anfrage eingeht, ihre Vorfüllphase mit der Decodierungsphase zu mischen, die der ersten Anfrage entspricht, und eine neue Phase namens Merge Step zu generieren. In diesem Merge-Schritt wird nicht nur die Dekodierung der ersten Anfrage durchgeführt, sondern auch das Prefill der zweiten Anfrage. Diese Funktion ist in vielen großen Sprachmodell-Inferenzsystemen vorhanden und ihre Implementierung hat die QPS großer Sprachmodelle um 100 % erhöht. Der spezifische Prozess besteht darin, dass der erste Anforderungsgenerierungsprozess zur Hälfte abgeschlossen ist, was bedeutet, dass beim Dekodieren eine Eingabe mit der Länge 1 erfolgt, während die zweite Anforderung neu eingegeben wird und sich im Vorabfüllungsprozess befindet eine Eingabe der Länge 48 sein. Wenn diese beiden Eingaben entlang der ersten Dimension miteinander verbunden werden, beträgt die Länge der gespleißten Eingabe 49 und die Länge der verborgenen Dimension beträgt 4096. Bei dieser Eingabe der Länge 49 wird zuerst das erste Wort und dann die restlichen 48 Wörter angefordert. Denn in der Argumentation großer Modelle müssen die Operatoren, die erlebt werden müssen, wie RMSNorm, Matrixmultiplikation und Aufmerksamkeit, dieselbe Struktur haben, unabhängig davon, ob sie zum Dekodieren oder Vorfüllen verwendet werden. Daher kann der gespleißte Eingang direkt in das gesamte Netzwerk eingefügt und ausgeführt werden. Wir müssen nur an einer Stelle unterscheiden, und das ist die Aufmerksamkeit. Während des Aufmerksamkeitsprozesses oder während der Ausführung des Selbstaufmerksamkeitsoperators führen wir einen Datenshunt durch, leiten alle Dekodierungsanforderungen in eine Welle, alle Vorausfüllungsanforderungen in eine andere Welle und führen zwei verschiedene Operationen aus. Alle Prefill-Anfragen führen Flash Attention aus; alle Dekodierungsbenutzer führen einen ganz besonderen Operator namens Decoding Attention aus. Nachdem der Aufmerksamkeitsoperator separat ausgeführt wurde, werden diese Benutzereingaben erneut zusammengefügt, um die Berechnung anderer Operatoren abzuschließen. Für den Zusammenführungsschritt werden wir tatsächlich jede Anfrage mit der Eingabe aller derzeit im System vorhandenen Anfragen zusammenfügen, diese Berechnung abschließen und dann mit der Dekodierung fortfahren Implementierung der dynamischen Stapelverarbeitung in großen Sprachmodellen. Der Decoding Attention-Operator ist nicht so bekannt wie der Flash Attention-Operator, aber er ist bei der Verarbeitung von Decodierungsaufgaben tatsächlich viel schneller als Flash Attention. Dies ist ein Operator, der speziell für Dekodierungsaufgaben entwickelt wurde. Er basiert vollständig auf Cuda Core und ist nicht auf Tensor Core angewiesen, um Berechnungen durchzuführen. Es ist sehr flexibel und leicht zu ändern, weist jedoch eine Einschränkung auf, da es durch die Operation des Tensordecodierens gekennzeichnet ist und daher erfordert, dass die Länge der Eingabe q 1 sein muss, die Längen von k und v jedoch variabel sind. Dies ist eine Einschränkung der Dekodierung der Aufmerksamkeit. Unter dieser Einschränkung können wir einige spezifische Optimierungen vornehmen. Diese spezielle Optimierung macht die Implementierung des Aufmerksamkeitsoperators in der Dekodierungsphase schneller als Flash Attention. Diese Implementierung ist jetzt Open Source und Sie können sie unter der URL im Bild oben besuchen. Eine weitere Optimierung ist Virtual Memory Allocator, entsprechend der Page Attention-Optimierung. Wenn eine Anfrage eintrifft, durchläuft sie die Vorfüllphase und die Dekodierungsphase. Alle ihre Eingabetoken generieren einen KV-Cache, der alle historischen Informationen dieser Anfrage aufzeichnet. Wie viel KV-Cache-Speicherplatz sollte einer solchen Anforderung zugewiesen werden, um diese Generierungsaufgabe abzuschließen? Wenn es zu stark geteilt wird, wird der Videospeicher verschwendet. Wenn es zu wenig geteilt wird, erreicht es während der Dekodierungsphase die Grenzposition des KV-Cache und es gibt keine Möglichkeit, es weiter zu generieren. Um dieses Problem zu lösen, gibt es 3 Lösungen. Pytorchs Speicherverwaltungsmethode besteht darin, für jede Anfrage ausreichend Speicherplatz zu reservieren, normalerweise 2048 oder 4096, um sicherzustellen, dass 4096 Wörter generiert werden. Die tatsächliche generierte Länge der meisten Benutzer wird jedoch nicht so groß sein, sodass viel Speicherplatz verschwendet wird. Page Attention verwendet eine andere Methode zur Videospeicherverwaltung. Ermöglicht dem Benutzer, während des Generierungsprozesses kontinuierlich Videospeicher hinzuzufügen. Ähnlich wie Paging-Speicher oder Speicher-Paging im Betriebssystem. Wenn eine Anfrage eingeht, reserviert das System einen kleinen Teil des Videospeichers für die Anfrage. Dieser kleine Teil des Videospeichers reicht normalerweise nur aus, um 8 Zeichen zu generieren. Wenn die Anfrage 8 Zeichen generiert, fügt das System einen Teil des Videospeichers hinzu , und das Ergebnis kann wiederverwendet werden. Beim Schreiben in diesen Videospeicher verwaltet das System eine verknüpfte Liste zwischen dem Videospeicherblock und dem Videospeicherblock, sodass der Bediener eine normale Ausgabe durchführen kann. Wenn die generierte Länge weiter zunimmt, wird die Zuweisung von Videospeicherblöcken dem Benutzer weiterhin hinzugefügt, und die Liste der Zuweisungen von Videospeicherblöcken kann dynamisch verwaltet werden, sodass das System nicht viele Ressourcen verschwendet und muss für diese Anfrage nicht zu viel Videospeicher reservieren. PPL.LLM verwendet den Verwaltungsmechanismus des virtuellen Speichers, um die erforderliche Generierungslänge für jede Anforderung vorherzusagen. Nachdem jede Anfrage eingegangen ist, wird ihr direkt ein fortlaufender Speicherplatz zugewiesen und die Länge dieses fortlaufenden Speicherplatzes wird vorhergesagt. Allerdings kann es theoretisch schwierig sein, dies zu erreichen, insbesondere in der Phase der Online-Begründung. Es ist unmöglich, genau zu wissen, wie lange der Inhalt für jede Anfrage generiert wird. Daher empfehlen wir, hierfür ein Modell zu trainieren. Denn selbst wenn wir ein Modell wie Page Attention übernehmen, werden wir immer noch auf Probleme stoßen. Seite Achtung Während des laufenden Prozesses liegen zu einem bestimmten Zeitpunkt beispielsweise bereits vier Anfragen auf dem aktuellen System vor und es sind noch 6 Blöcke Videospeicher im System übrig, die nicht allokiert wurden. Derzeit können wir nicht wissen, ob neue Anfragen eingehen und ob wir weiterhin Dienste für sie bereitstellen können, da die aktuellen vier Anfragen noch nicht abgeschlossen sind und ihnen möglicherweise weiterhin neue Videospeicherblöcke hinzugefügt werden die Zukunft. Selbst mit dem Page-Attention-Mechanismus ist es also immer noch notwendig, die tatsächliche Generationslänge jedes Benutzers vorherzusagen. Nur so können wir wissen, ob wir zu einem bestimmten Zeitpunkt Eingaben eines neuen Benutzers akzeptieren können. Das ist etwas, was keines unserer aktuellen Argumentationssysteme kann, einschließlich PPL. Der Verwaltungsmechanismus des virtuellen Speichers ermöglicht es uns jedoch immer noch, die Verschwendung von Videospeicher weitgehend zu vermeiden und so die Gesamt-QPS des Systems auf etwa 200 % zu erhöhen. Eine weitere Optimierung, die PPL.LLM durchführt, ist die Quantifizierung des KV-Cache Videospeicherplatz, wodurch die Anzahl gleichzeitiger Anforderungen auf dem System erheblich eingeschränkt wird. Sie können sehen, dass beim Ausführen eines großen Sprachmodells wie dem 7B-Modell auf dem Server, insbesondere auf Servern mit großem Speicher wie A100 und H100, der KV-Cache 84 % des Speicherplatzes belegt. und für große Modelle wie 176B, deren KV-Cache ebenfalls mehr als 50 % des Cache-Speicherplatzes belegt. Dadurch wird die Anzahl der Parallelitätsvorgänge des Modells erheblich eingeschränkt. Nach dem Eintreffen jeder Anforderung muss ihm eine große Menge Videospeicher zugewiesen werden. Auf diese Weise kann die Anzahl der Anfragen nicht erhöht und somit QPS und Durchsatz nicht verbessert werden. PPL.LLM verwendet eine ganz spezielle Quantisierungsmethode, die Gruppenquantisierung, um die Daten im KV-Cache zu komprimieren. Das heißt, für die ursprünglichen FP16-Daten wird versucht, sie auf INT8 zu quantisieren. Dadurch wird die Größe des KV-Cache um 50 % reduziert und die Anzahl der Anfragen, die der Server verarbeiten kann, um 100 % erhöht. Der Grund, warum der Durchsatz im Vergleich zu Faster Transformer um etwa 50 % gesteigert werden kann, liegt genau in der durch die KV-Cache-Quantisierung verursachten Erhöhung der Stapelgröße. Nach der KV-Cache-Quantisierung führten wir eine detailliertere Quantisierung der Matrixmultiplikation durch. Im gesamten serverseitigen Inferenzprozess macht die Matrixmultiplikation mehr als 70 % der gesamten Inferenzzeit aus. PPL.LLM verwendet eine dynamische, abwechselnde Hybridquantisierungsmethode pro Kanal/pro Token, um die Matrixmultiplikation zu beschleunigen. Diese Quantisierungen sind außerdem äußerst genau und können die Leistung um nahezu 100 % verbessern. Die spezifische Methode besteht darin, einen Quantisierungsoperator auf der Grundlage des RMSNorm-Operators zu integrieren. Dieser Quantisierungsoperator zählt die Token-Informationen basierend auf der Funktion des RMSNorm-Operators und zählt die Maximal- und Minimalwerte jedes Tokens und quantifizieren Sie diese Daten entlang der Dimensionen des Tokens. Das heißt, die Daten nach RMSNorm werden von FP16 in INT8 konvertiert, und diesmal ist die Quantisierung vollständig dynamisch und erfordert keine Kalibrierung. Bei der anschließenden QKV-Matrixmultiplikation werden diese drei Matrixmultiplikationen pro Kanal quantisiert. Die empfangenen Daten sind INT8 und ihre Gewichte sind ebenfalls INT8, sodass diese Matrixmultiplikationen vollständige INT8-Matrixmultiplikationen durchführen können. Ihre Ausgabe wird von Soft Attention akzeptiert, aber vor der Annahme wird ein Dequantisierungsprozess durchgeführt. Dieses Mal wird der Dequantisierungsprozess mit dem Soft Attention-Operator zusammengeführt. Die anschließende O-Matrix-Multiplikation führt keine Quantisierung durch, und der Berechnungsprozess von Soft Attention selbst führt keine Quantisierung durch. Im anschließenden FeedForward-Prozess werden diese beiden Matrizen ebenfalls auf die gleiche Weise quantisiert, mit der obigen RMSNorm oder mit Aktivierungsfunktionen wie Silu und Mul oben fusioniert. Ihre Lösungsquantisierungsoperatoren werden mit ihren nachgeschalteten Operatoren fusioniert. Der aktuelle quantitative Fokus akademischer Kreise auf große Sprachmodelle konzentriert sich möglicherweise hauptsächlich auf INT4, aber im Prozess der serverseitigen Inferenz ist INT8 tatsächlich besser geeignet . Quantifizierung. INT4-Quantisierung wird auch als Nur-Gewicht-Quantisierung bezeichnet. Die Bedeutung dieser Quantisierungsmethode besteht darin, dass 90 % der Zeit zum Laden während der Matrixmultiplikationsberechnung verwendet werden, wenn der Stapel während des Inferenzprozesses für große Sprachmodelle relativ klein ist Prozess. Gewichte. Da die Gewichte sehr groß sind und die Zeit zum Laden der Eingabe sehr kurz ist, ist ihre Eingabe, dh ihre Aktivierung, ebenfalls sehr kurz, die Berechnungszeit ist nicht sehr lang und die Zeit zum Zurückschreiben der Ergebnisse ist ebenfalls sehr kurz auch nicht sehr lang, was bedeutet, dass dieser Berechnungsteil ein speicherzugriffsintensiver Operator ist. In diesem Fall wählen wir die INT4-Quantisierung, sofern die Charge klein genug ist. Nachdem jedes Gewicht mit der INT4-Quantisierung geladen wurde, folgt ein Dequantisierungsprozess. Durch diese Dequantisierung wird das Gewicht von INT4 auf FP16 dequantisiert. Nach dem Durchlaufen des Dequantisierungsprozesses sind die nachfolgenden Berechnungen genau die gleichen wie bei FP16. Das heißt, die Quantisierung von INT4 Weight Only ist für die speicherzugriffsintensive Matrixmultiplikation geeignet seine Berechnung Der Prozess wird noch vom FP16-Rechengerät abgeschlossen. Wenn der Stapel groß genug ist, z. B. 64 oder 128, führt die Nur-Gewicht-Quantisierung von INT4 zu keiner Leistungsverbesserung. Denn wenn die Charge groß genug ist, ist die Berechnungszeit sehr lang. Und die INT4-Gewichtsquantisierung hat einen sehr schlechten Punkt. Der für den Dequantisierungsprozess erforderliche Rechenaufwand nimmt mit zunehmender Menge an Eingabemengen zu . Es wird immer länger. Wenn die Stapelgröße 128 erreicht, gleichen sich der Zeitverlust durch die Dequantisierung und der Leistungsvorteil durch das Laden von Gewichten gegenseitig aus. Das heißt, wenn der Stapel 128 erreicht, ist die INT4-Matrixquantisierung nicht schneller als die FP16-Matrixquantisierung und der Leistungsvorteil ist minimal. Wenn der Batch etwa 64 beträgt, ist die Nur-Gewicht-Quantisierung von INT4 nur 30 % schneller als die von FP16. Wenn der Batch 128 beträgt, ist sie nur etwa 20 % schneller oder sogar weniger. Aber für INT8 besteht der größte Unterschied zwischen der INT8-Quantisierung und der INT4-Quantisierung darin, dass kein Dequantisierungsprozess erforderlich ist und die Berechnung zeitlich verdoppelt werden kann. Wenn Batch gleich 128 ist, wird von der FP16-Quantisierung auf INT8 die Zeit zum Laden der Gewichte halbiert, und auch die Berechnungszeit wird halbiert, was zu einer Beschleunigung von etwa 100 % führt. In einem serverseitigen Szenario sind die meisten Matrixmultiplikationen rechenintensiv, insbesondere weil es einen ständigen Zustrom von Anfragen gibt. Wenn Sie in diesem Fall den ultimativen Durchsatz anstreben möchten, ist die Effizienz von INT8 tatsächlich höher als die von INT4. Dies ist auch einer der Gründe, warum wir in der bisher abgeschlossenen Implementierung INT8 hauptsächlich serverseitig vorantreiben. Auf H100, H800, 4090 führen wir möglicherweise eine FP8-Quantisierung durch. Datenformate wie FP8 wurden in Nvidias neuester Grafikkartengeneration eingeführt. Die Genauigkeit von INT8 ist theoretisch höher als die von FP8, aber FP8 ist benutzerfreundlicher und bietet eine bessere Leistung. Wir werden die Implementierung von FP8 auch in nachfolgenden Updates des serverseitigen Inferenzprozesses fördern. Wie in der Abbildung oben zu sehen ist, ist der Fehler von FP8 etwa zehnmal größer als der von INT8. INT8 verfügt über einen quantisierten Größenfaktor, und der Quantisierungsfehler von INT8 kann durch Anpassen des Größenfaktors reduziert werden. Der Quantisierungsfehler von FP8 ist grundsätzlich unabhängig vom Größenfaktor. Er wird durch den Größenfaktor nicht beeinflusst, was bedeutet, dass wir grundsätzlich keine Kalibrierung daran vornehmen müssen. Aber sein Fehler ist im Allgemeinen höher als INT8. PPL.LLM wird in nachfolgenden Updates auch die Matrixquantisierung von INT4 aktualisieren. Diese Nur-Gewicht-Matrixquantisierung dient hauptsächlich der Terminalseite, für Geräte wie mobile Terminals, bei denen der Batch auf 1 festgelegt ist. In nachfolgenden Updates wird schrittweise von INT4 auf nichtlineare Quantisierung umgestellt. Denn im Berechnungsprozess von „Weight Only“ wird es einen Dequantisierungsprozess geben, der tatsächlich anpassbar ist und möglicherweise kein linearer Dequantisierungsprozess ist. Die Verwendung anderer Dequantisierungsprozesse und Quantisierungsprozesse führt zu einer höheren Berechnungsgenauigkeit. Ein typisches Beispiel ist die in einem Artikel erwähnte Quantisierung von NF4. Diese Quantifizierung wird tatsächlich durch eine Tabellenmethode quantisiert. In nachfolgenden Updates von PPL.LLM werden wir versuchen, eine solche Quantisierung zu nutzen, um die geräteseitige Inferenz zu optimieren. Abschließend stellen wir die Hardware für die Verarbeitung großer Sprachmodelle vor. Sobald die Modellstruktur festgelegt ist, kennen wir den spezifischen Berechnungsumfang, wie viel Speicherzugriff erforderlich ist und wie viel Berechnungsumfang erforderlich ist. Gleichzeitig kennen Sie auch die Bandbreite, Rechenleistung, den Preis usw. jeder Grafikkarte. Nachdem wir die Struktur des Modells und die Hardwareindikatoren bestimmt haben, können wir anhand dieser Indikatoren den maximalen Durchsatz für die Ableitung eines großen Modells auf dieser Grafikkarte, die Berechnungsverzögerung und die erforderliche Speicherzugriffszeit berechnen spezifische Tabelle berechnet werden kann. Wir werden diese Tabelle in den folgenden Informationen veröffentlichen. Sie können auf diese Tabelle zugreifen, um zu sehen, welche Grafikkartenmodelle für die Inferenz großer Sprachmodelle am besten geeignet sind. Da bei der Inferenz großer Sprachmodelle die meisten Operatoren speicherzugriffsintensiv sind, ist die Speicherzugriffslatenz immer höher als die Berechnungslatenz. Da die Parametermatrix des großen Sprachmodells tatsächlich zu groß ist, ist die Berechnungsverzögerung selbst beim A100 / 80G gering, wenn die Stapelgröße auf 272 geöffnet wird, die Verzögerung beim Speicherzugriff ist jedoch höher. Daher beginnen viele unserer Optimierungen mit dem Speicherzugriff. Bei der Auswahl der Hardware besteht unsere Hauptrichtung darin, Geräte mit relativ hoher Bandbreite und großem Videospeicher auszuwählen. Dadurch kann das große Sprachmodell mehr Anforderungen und einen schnelleren Speicherzugriff während der Inferenz unterstützen, und der entsprechende Durchsatz wird höher sein. Das Obige ist der Inhalt, der dieses Mal geteilt wurde. Alle relevanten Informationen werden auf der Netzwerkfestplatte abgelegt, siehe Link oben. Unser gesamter Code wurde auch als Open Source auf Github bereitgestellt. Gerne können Sie jederzeit mit uns kommunizieren. A1: Decoding Attention ist ein ganz besonderer Operator. Die Länge seines Q beträgt immer 1, daher ist in Softmax kein sehr großer Speicherzugriff wie bei Flash Attention erforderlich. Tatsächlich handelt es sich bei der Ausführung von Decoding Attention um die vollständige Ausführung von Softmax und muss nicht so schnell ausgeführt werden wie Flash Attention. A2: Erstens ist diese Lösungsquantisierung nicht so, wie alle denken. Wenn Sie dies nur tun, ist die Lösung so groß Gewichte. Tatsächlich ist dies nicht der Fall, da es sich um eine in die Matrixmultiplikation integrierte Lösungsquantisierung handelt. Sie können nicht alle Gewichtslösungen quantisieren, bevor Sie die Matrixmultiplikation durchführen, sie dort ablegen und dann lesen. Auf diese Weise ist die Quantisierung von INT4, die wir vorgenommen haben, bedeutungslos. Da wir während des Ausführungsprozesses eine Blockmatrixmultiplikation durchführen, beträgt die Anzahl der Lese- und Schreibvorgänge nicht 1. Diese Zahl muss tatsächlich kontinuierlich berechnet werden. Das heißt, anders als bei den vorherigen Methoden zur Optimierung der Quantisierung wird es separate Quantisierungsoperatoren und Lösungsquantisierungsoperatoren geben. Bei der Einfügung zweier Operatoren wird die Lösungsquantisierung direkt in den Operator integriert. Wir führen eine Matrixmultiplikation durch, daher ist die Häufigkeit, mit der wir die Quantisierung lösen müssen, nicht einmal. A3: Laut unseren Tests lässt es sich vertuschen, und tatsächlich ist noch viel mehr übrig. Die inverse Quantisierung und die Quantisierung in der KV-Berechnung werden in den Selbstaufmerksamkeitsoperator integriert, insbesondere in die Dekodierung der Aufmerksamkeit. Tests zufolge kann dieser Operator maskiert sein, selbst wenn er den 10-fachen Rechenaufwand erfordert. Selbst die Verzögerung des Speicherzugriffs kann dies nicht verdecken. Sein Hauptengpass ist der Speicherzugriff, und sein Berechnungsumfang erreicht bei weitem nicht das Niveau, das den Speicherzugriff verdecken kann. Daher ist die inverse Quantisierungsberechnung im KV-Cache grundsätzlich eine gut abgedeckte Sache für diesen Operator. 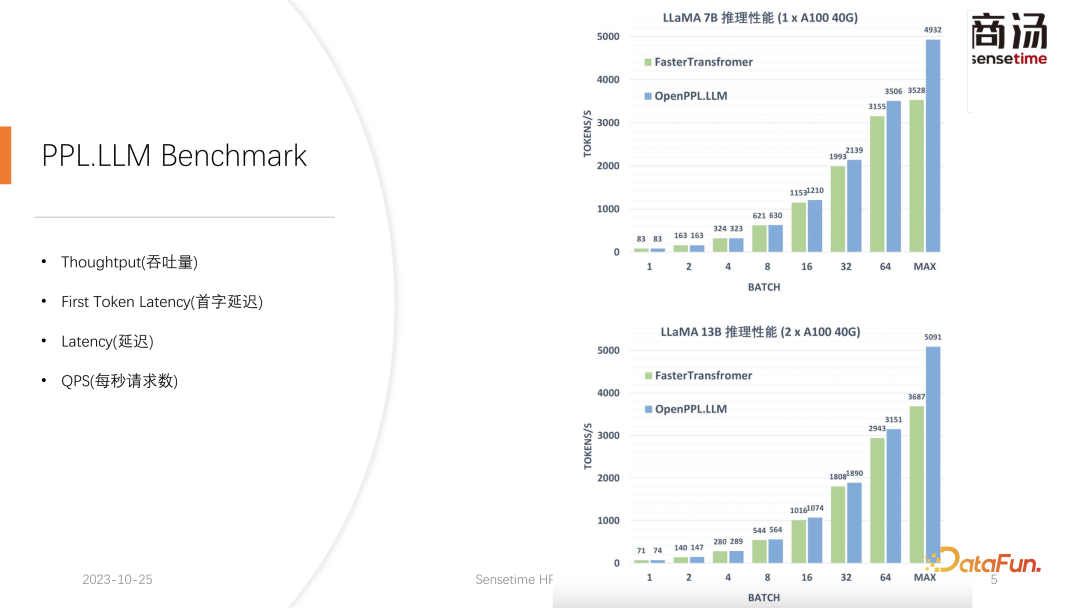
2. Optimierung der Inferenzleistung großer Sprachmodelle
1. LLM-Inferenzprozess
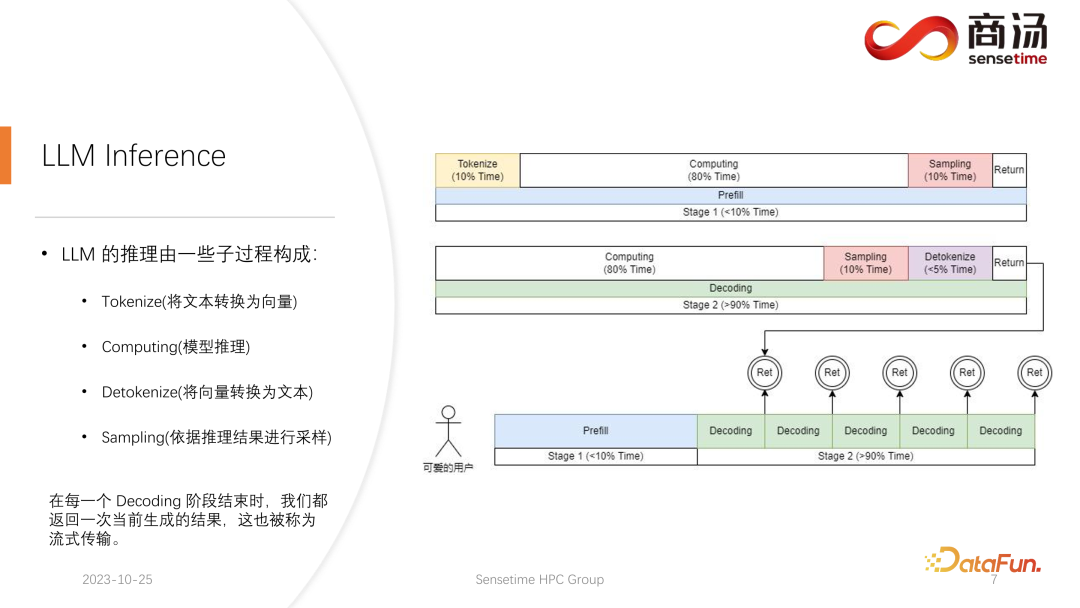
2. Optimierung: Pipeline-Vor- und Nachbearbeitung und Hochleistungs-Sampling
3. Optimierung: Dynamische Stapelverarbeitung
4. Optimierung: Decoding Attention

5. Optimierung: VM Allocator
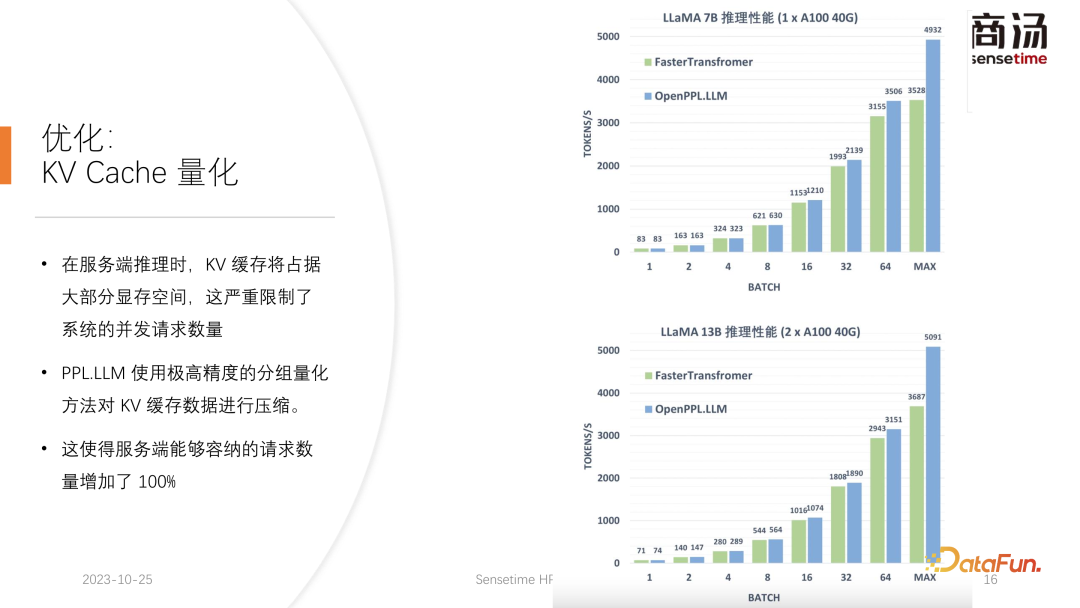
6. Optimierung: KV-Cache-Quantifizierung
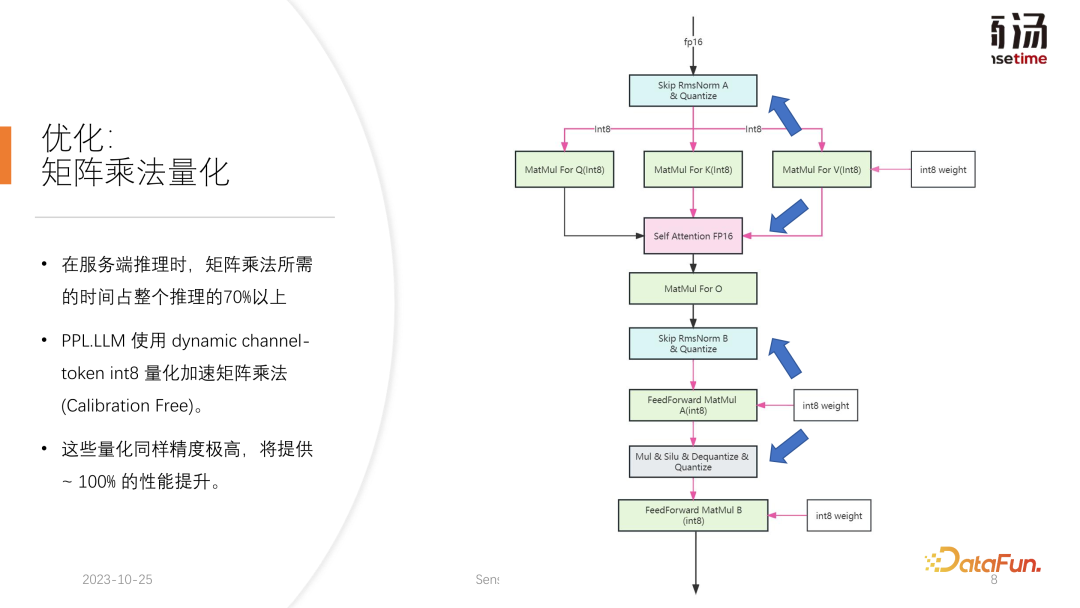
7. Optimierung: Matrixmultiplikationsquantisierung

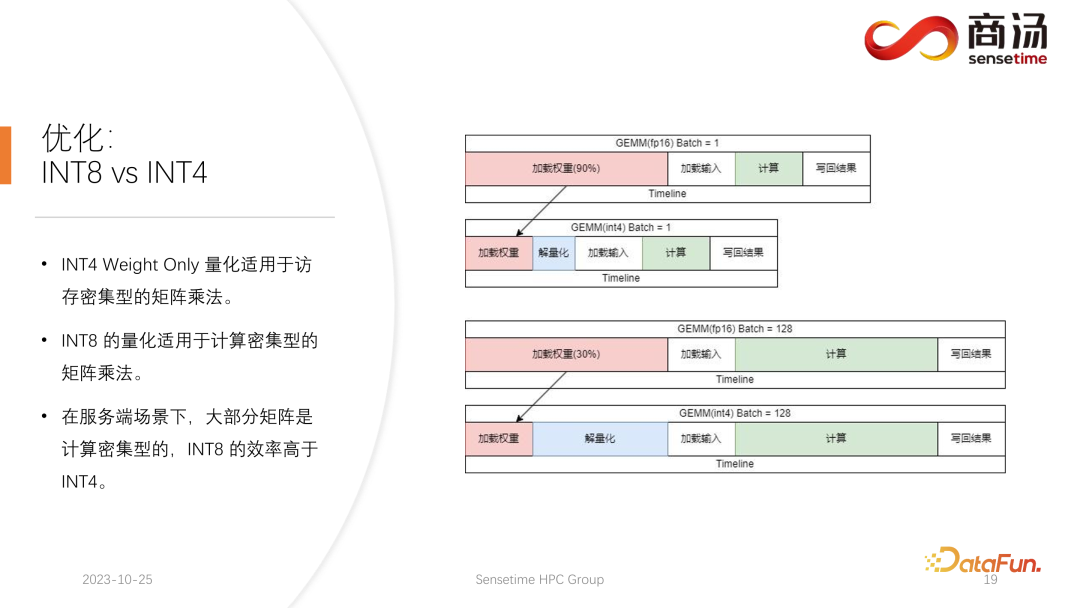
8. Optimierung: INT8 vs. INT4
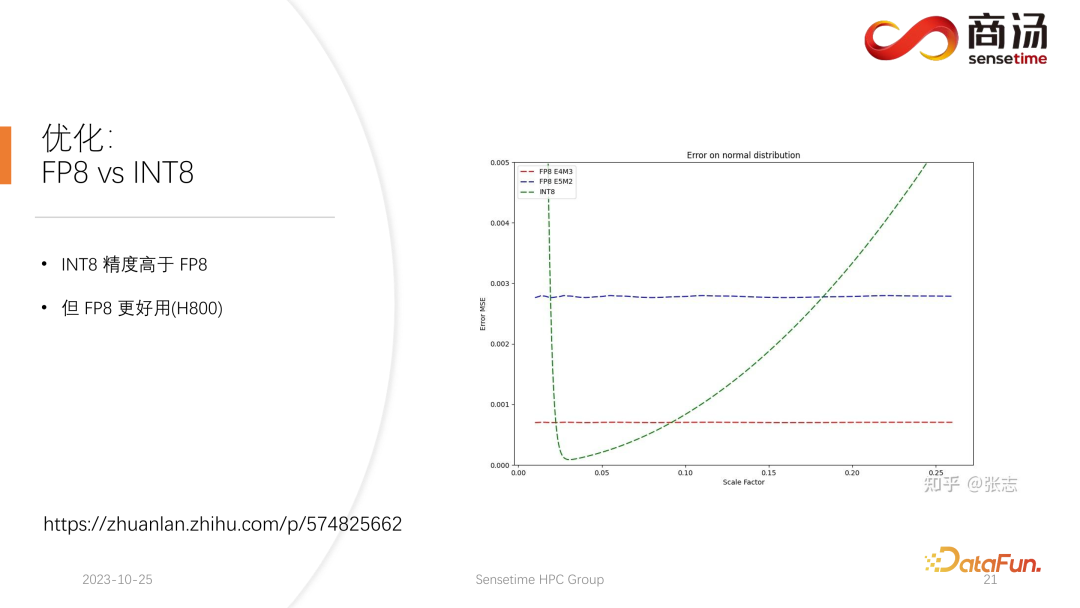
9. Optimierung: FP8 vx INT8
10. Optimierung: INT4 vs. nichtlineare Quantisierung

3. Hardware für die Inferenz großer Sprachmodelle

IV. Fragen und Antworten
F1: Gibt es ein Speicherzugriffsproblem wie bei Softmax in Flash Attention, das in PPL.LLM optimiert ist?
F2: Warum hängt die Nur-Gewicht-Quantisierung von INT4 linear mit der Charge zusammen? Ist das eine feste Zahl?
F3: Kann die inverse Quantisierungsberechnung im KV-Cache durch Nachahmung maskiert werden?
Das obige ist der detaillierte Inhalt vonEntwurf und Implementierung eines leistungsstarken LLM-Inferenz-Frameworks. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Verwenden von curl_multi zum Implementieren der Analyse gleichzeitiger Anforderungsschritte
- Es sind keine manuellen Anmerkungen erforderlich, das selbstgenerierte Anweisungs-Framework überwindet den Kostenengpass von LLMs wie ChatGPT
- Durch MAmmoT wird LLM zum mathematischen Generalisten: von der formalen Logik bis zu vier arithmetischen Operationen
- Das Team der Fudan-Universität veröffentlichte DISC-LawLLM, ein chinesisches intelligentes Rechtssystem, um einen Benchmark für die gerichtliche Bewertung zu erstellen und 300.000 fein abgestimmte Daten als Open Source bereitzustellen