
Heim >Technologie-Peripheriegeräte >KI >Es sind keine manuellen Anmerkungen erforderlich, das selbstgenerierte Anweisungs-Framework überwindet den Kostenengpass von LLMs wie ChatGPT
Es sind keine manuellen Anmerkungen erforderlich, das selbstgenerierte Anweisungs-Framework überwindet den Kostenengpass von LLMs wie ChatGPT

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-16 13:52:031461Durchsuche
ChatGPT ist Ende dieses Jahres der neue Top-Player im KI-Kreis. Die Menschen sind von seinen leistungsstarken Frage- und Antwortsprachenfähigkeiten und Programmierkenntnissen begeistert. Doch je leistungsstärker das Modell, desto höher sind die technischen Anforderungen, die dahinter stehen.

ChatGPT basiert auf der GPT 3.5-Modellreihe und führt „manuelle Annotationsdaten + Reinforcement Learning“ (RLHF) ein, um das vorab trainierte Sprachmodell kontinuierlich zu verfeinern, mit dem Ziel, große Sprachmodelle (LLM) zu ermöglichen ), um zu lernen, menschliche Befehle zu verstehen und basierend auf der gegebenen Aufforderung die optimale Antwort zu geben.
Diese technische Idee ist der aktuelle Entwicklungstrend von Sprachmodellen. Obwohl dieser Modelltyp große Entwicklungsaussichten hat, sind die Kosten für das Modelltraining und die Feinabstimmung sehr hoch.
Nach den derzeit von OpenAI veröffentlichten Informationen ist der Trainingsprozess von ChatGPT in drei Phasen unterteilt:
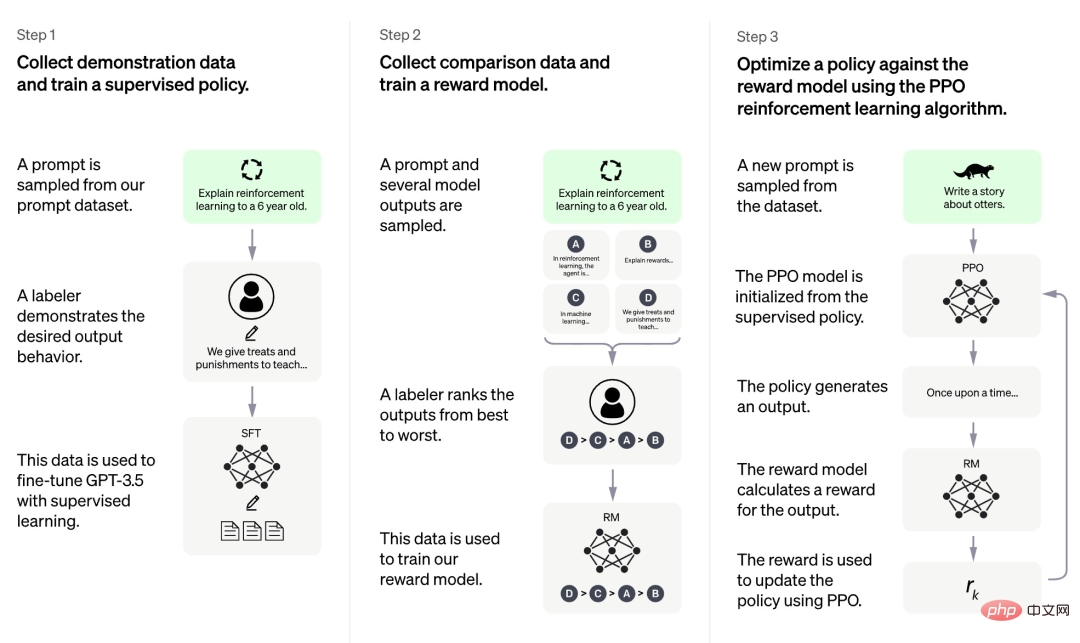
Die erste Phase ist zunächst ein überwachtes Richtlinienmodell ähnlich GPT 3.5. Auf dieser Grundlage ist es für das Modell schwierig, die in verschiedenen Arten menschlicher Anweisungen enthaltenen Absichten zu verstehen, und es ist für das Modell auch schwierig, die Qualität des generierten Inhalts zu beurteilen. Die Forscher wählten zufällig einige Stichproben aus dem Eingabeaufforderungsdatensatz aus und baten dann professionelle Kommentatoren, qualitativ hochwertige Antworten auf der Grundlage der angegebenen Eingabeaufforderung zu geben. Die durch diesen manuellen Prozess erhaltenen Eingabeaufforderungen und die entsprechenden qualitativ hochwertigen Antworten wurden zur Feinabstimmung des anfänglichen überwachten Richtlinienmodells verwendet, um ein grundlegendes Verständnis der Eingabeaufforderungen zu ermöglichen und zunächst die Qualität der generierten Antworten zu verbessern.
In der zweiten Phase extrahiert das Forschungsteam mehrere vom Modell basierend auf einer bestimmten Eingabeaufforderung generierte Ausgaben, lässt dann menschliche Forscher diese Ausgaben sortieren und verwendet die sortierten Daten dann zum Trainieren eines Belohnungsmodells (RM). ChatGPT verwendet paarweisen Verlust, um RM zu trainieren.
In der dritten Phase nutzt das Forschungsteam Reinforcement Learning, um die Fähigkeiten des Pre-Training-Modells zu verbessern, und nutzt das in der vorherigen Phase erlernte RM-Modell, um die Parameter des Pre-Training-Modells zu aktualisieren.
Wir können feststellen, dass von den drei Phasen des ChatGPT-Trainings nur die dritte Phase keine manuelle Annotation von Daten erfordert, während sowohl die erste als auch die zweite Phase eine große Menge an manueller Annotation erfordern. Obwohl Modelle wie ChatGPT eine sehr gute Leistung erbringen, ist der Arbeitsaufwand für die Verbesserung ihrer Fähigkeit, Anweisungen zu befolgen, sehr hoch. Je größer der Maßstab des Modells und je größer der Funktionsumfang wird, desto schwerwiegender wird dieses Problem und schließlich wird es zu einem Engpass, der die Entwicklung des Modells behindert.
Einige Forschungen versuchen, Methoden zur Lösung dieses Engpasses vorzuschlagen. Beispielsweise haben die University of Washington und andere Institutionen kürzlich gemeinsam einen Artikel „SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions“ veröffentlicht. INSTRUCT basiert auf dem modelleigenen Generierungsprozess und verbessert die Befehlsfolgefähigkeit des vorab trainierten Sprachmodells.

Papieradresse: https://arxiv.org/pdf/2212.10560v1.pdf
SELF-INSTRUCT ist ein halbautomatischer Prozess, der Anweisungssignale vom Modell selbst verwendet, um vorab Zug LM führt die Befehlsanpassung durch. Wie in der folgenden Abbildung dargestellt, handelt es sich bei dem gesamten Prozess um einen iterativen Bootstrapping-Algorithmus.
SELBSTANLEITUNG beginnt mit einem begrenzten Satz Samen und leitet den gesamten Generierungsprozess mit handgeschriebenen Anweisungen. In der ersten Phase wird das Modell zur Erstellung neuer Anweisungen zur Aufgabengenerierung aufgefordert. Dieser Schritt nutzt den vorhandenen Befehlssatz, um umfassendere Anweisungen zur Definition der neuen Aufgabe zu erstellen. SELF-INSTRUCT erstellt außerdem Eingabe- und Ausgabeinstanzen für den neu generierten Befehlssatz zur Verwendung bei der Überwachung von Befehlsanpassungen. Schließlich beschneidet SELF-INSTRUCT auch minderwertige und doppelte Anweisungen. Der gesamte Prozess wird iterativ ausgeführt und das endgültige Modell kann Anweisungen für eine große Anzahl von Aufgaben generieren.
Um die Wirksamkeit der neuen Methode zu überprüfen, wandte die Studie das SELF-INSTRUCT-Framework auf GPT-3 an, was letztendlich etwa 52.000 Anweisungen, 82.000 Instanzeingaben und Zielausgaben hervorbrachte. Wir haben beobachtet, dass GPT-3 bei der neuen Aufgabe im SUPER-NATURALINSTRUCTIONS-Datensatz eine absolute Verbesserung von 33,1 % gegenüber dem Originalmodell erreichte, was mit der Leistung von InstructGPT_001 vergleichbar war, das mit privaten Benutzerdaten und menschlichen Anmerkungen trainiert wurde.
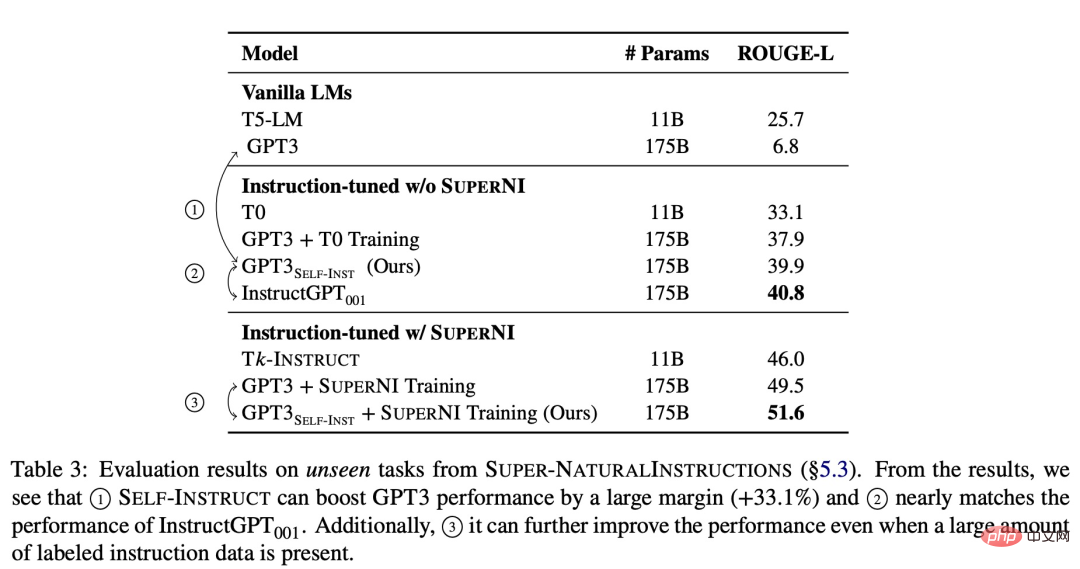
Zur weiteren Auswertung stellte die Studie eine Reihe von von Experten verfassten Anweisungen für die neue Aufgabe zusammen und zeigte durch menschliche Auswertung, dass die GPT-3-Leistung mit SELF-INSTRUCT deutlich besser sein wird als bestehende öffentliche Methoden mit Modell auf dem Anweisungsdatensatz und liegt nur 5 % hinter InstructGPT_001.
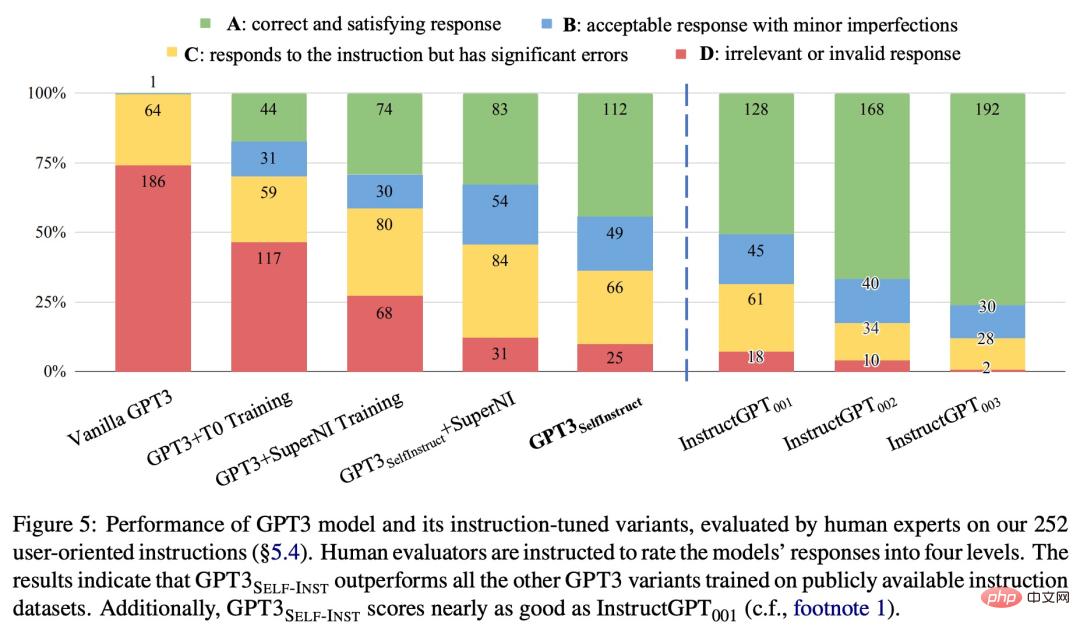
SELF-INSTRUCT bietet eine Methode, die fast keine manuelle Annotation erfordert und eine Ausrichtung vorab trainierter Sprachmodelle an Anweisungen erreicht. Es wurden mehrere Arbeiten in ähnlicher Richtung durchgeführt, und alle haben gute Ergebnisse erzielt. Es ist ersichtlich, dass diese Art von Methode das Problem der hohen manuellen Kennzeichnungskosten für große Sprachmodelle sehr effektiv löst. Dadurch werden LLMs wie ChatGPT stärker und gehen weiter.
Das obige ist der detaillierte Inhalt vonEs sind keine manuellen Anmerkungen erforderlich, das selbstgenerierte Anweisungs-Framework überwindet den Kostenengpass von LLMs wie ChatGPT. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr