
Heim >Technologie-Peripheriegeräte >KI >Nicht so gut wie GAN! Google, DeepMind und andere haben Artikel veröffentlicht: Diffusionsmodelle werden direkt aus dem Trainingssatz „kopiert'.
Nicht so gut wie GAN! Google, DeepMind und andere haben Artikel veröffentlicht: Diffusionsmodelle werden direkt aus dem Trainingssatz „kopiert'.

- PHPznach vorne
- 2023-04-16 14:10:031339Durchsuche
Letztes Jahr wurden Bildererzeugungsmodelle populär. Nach einem beliebten Kunstkarneval folgten Urheberrechtsfragen.
Deep-Learning-Modelle wie DALL-E 2, Imagen und Stable Diffusion werden auf Hunderten Millionen Daten trainiert. Es gibt keine Möglichkeit, den Einfluss des Trainingssatzes zu beseitigen, aber ob einige generierte Bilder vorhanden sind Komplett aus dem Trainingsset? Wenn das generierte Bild dem Originalbild sehr ähnlich ist, Wem gehört das Urheberrecht?
Kürzlich veröffentlichten Forscher vieler namhafter Universitäten und Unternehmen wie Google, Deepmind und der ETH Zürich gemeinsam einen Artikel. Sie fanden heraus, dass sich das „Diffusionsmodell“ tatsächlich an die Proben im Trainingssatz erinnern kann Während des Generierungsprozesses reproduzieren.

In dieser Arbeit zeigen die Forscher, wie sich das Diffusionsmodell in seinen Trainingsdaten ein einzelnes Bild merkt und reproduzieren es, wenn es generiert wird.
 Der Artikel schlägt eine
Der Artikel schlägt eine
Im Allgemeinen zeigen die experimentellen Ergebnisse, dass das Diffusionsmodell einen viel schlechteren Datenschutz für den Trainingssatz bietet als frühere generative Modelle (wie GANs).
Ich erinnere mich daran, aber nicht vielDas Entrauschungs-Diffusionsmodell ist ein neues generatives neuronales Netzwerk, das vor kurzem aufgetaucht ist. Es generiert Bilder aus der Trainingsverteilung durch einen iterativen Entrauschungsprozess, der besser ist als das zuvor häufig verwendete GAN Oder die VAE-Modellgenerierung ist besser und es ist einfacher, das Modell zu erweitern und die Bildgenerierung zu steuern, sodass es sich schnell zu einer gängigen Methode für die Generierung verschiedener hochauflösender Bilder entwickelt hat.
Vor allem nach der Veröffentlichung von DALL-E 2 durch OpenAI wurde das Diffusionsmodell schnell im gesamten Bereich der KI-Generierung populär.
Der Reiz generativer Diffusionsmodelle beruht auf ihrer Fähigkeit, neue Bilder zu synthetisieren, die sich scheinbar von allem im Trainingssatz unterscheiden. Tatsächlich haben frühere groß angelegte Trainingsbemühungen „keine Probleme mit der Überanpassung festgestellt“, berichten Forscher Der sensible Bereich schlug sogar vor, dass das Diffusionsmodell durch die Synthese von Bildern „die Privatsphäre realer Bilder schützen“ kann.
Diese Arbeiten basieren jedoch alle auf einer Annahme: Das heißt, das Diffusionsmodell speichert und regeneriert keine Trainingsdaten, da es sonst die Datenschutzgarantie verletzt und viele Probleme hinsichtlich der Modellverallgemeinerung und der digitalen Fälschung verursacht.
Aber ist das wirklich so?

.
Frühere verwandte Arbeiten konzentrierten sich hauptsächlich auf Textsprachmodelle. Wenn das Modell eine wörtlich aufgezeichnete Sequenz aus dem Trainingssatz wiederherstellen kann, wird diese Sequenz als „Extraktion“ und „Speicher“ bezeichnet Bilder mit hoher Auflösung, daher ist ein Wort-für-Wort-Abgleich von Speicherdefinitionen nicht geeignet. Das Folgende ist eine Erinnerung, die auf von Forschern definierten Bildähnlichkeitsmaßen basiert.
Wenn der Abstand zwischen einem generierten Bild x und mehreren Proben im Trainingssatz kleiner als ein bestimmter Schwellenwert ist, wird davon ausgegangen, dass die Probe aus dem Trainingssatz stammt, d. h. eidetische Memorisierung.
Dann entwarf der Artikel einen zweistufigen DatenextraktionsangriffMethode:
1. Generieren Sie eine große Anzahl von Bildern
Der erste Schritt ist zwar sehr einfach, aber rechenintensiv Sehr hoch: Erzeugt Bilder im Black-Box-Stil unter Verwendung der ausgewählten Eingabeaufforderung als Eingabe.
Die Forscher generierten 500 Kandidatenbilder für jede Textaufforderung, um die Wahrscheinlichkeit zu erhöhen, Erinnerungen zu entdecken.
2. Führen Sie eine Mitgliedschaftsinferenz durch
und markieren Sie die Bilder, von denen vermutet wird, dass sie basierend auf dem Trainingssatzspeicher generiert werden.
Die von den Forschern entwickelte Member-Inference-Angriffsstrategie basiert auf der folgenden Idee: Für zwei verschiedene zufällige Anfangssamen ist die Wahrscheinlichkeit einer Ähnlichkeit zwischen den beiden durch das Diffusionsmodell erzeugten Bildern sehr groß, und das ist auch möglich werden basierend auf dem Speicher unter der generierten Distanzmetrik berücksichtigt.
Extraktionsergebnisse
Um die Wirksamkeit des Angriffs zu bewerten, wählten die Forscher die 350.000 am häufigsten wiederholten Beispiele aus dem Trainingsdatensatz aus und generierten 500 Kandidatenbilder für jede Eingabeaufforderung (insgesamt wurden 175 Millionen Bilder generiert).
Sortieren Sie zunächst alle diese generierten Bilder nach dem durchschnittlichen Abstand zwischen den Bildern in der Clique, um diejenigen zu identifizieren, die wahrscheinlich durch das Speichern der Trainingsdaten generiert wurden.
Dann wurden diese generierten Bilder mit den Trainingsbildern verglichen und jedes Bild als „extrahiert“ und „nicht extrahiert“ markiert. Schließlich wurden 94 Bilder gefunden, bei denen der Verdacht bestand, dass sie aus dem Trainingssatz extrahiert wurden.
Durch visuelle Analyse wurden die Top 1000 Bilder manuell als „gespeichert“ oder „nicht gespeichert“ gekennzeichnet und es wurde festgestellt, dass 13 Bilder durch Kopieren von Trainingsbeispielen generiert wurden.
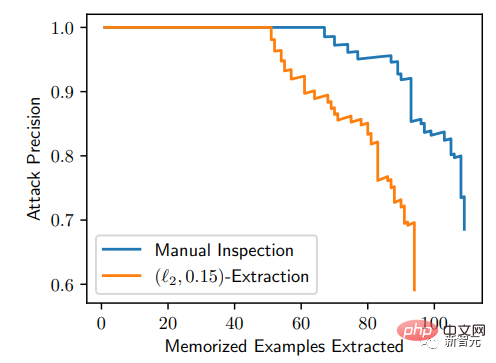
Anhand der P-R-Kurve ist diese Angriffsmethode sehr genau: Von 175 Millionen generierten Bildern können 50 gespeicherte Bilder identifiziert werden, und die Falsch-Positiv-Rate beträgt 0. Und alle generierten Bilder basieren auf dem Speicher kann mit einer Genauigkeit von mehr als 50 % extrahiert werden
Um besser zu verstehen, wie und warum Gedächtnis auftritt, trainierten die Forscher außerdem Hunderte von Vergleichsbildern auf dem CIFAR10 Small Diffusion Model, um die Auswirkungen von Modellgenauigkeit, Hyperparametern, Augmentation, und Deduplizierung beim Datenschutz.

Diffusion vs. GAN
Im Gegensatz zu Diffusionsmodellen werden GANs nicht explizit darauf trainiert, sich ihre Trainingsdatensätze zu merken und zu rekonstruieren.
GANs bestehen aus zwei konkurrierenden neuronalen Netzen: einem Generator und einem Diskriminator. Der Generator empfängt auch zufälliges Rauschen als Eingabe, muss dieses Rauschen jedoch im Gegensatz zum Diffusionsmodell in einem Vorwärtsdurchlauf in ein gültiges Bild umwandeln.
Während des Trainings von GAN muss der Diskriminator vorhersagen, ob das Bild vom Generator stammt, und der Generator muss sich selbst verbessern, um den Diskriminator zu täuschen.
Der Unterschied zwischen den beiden besteht also darin, dass der GAN-Generator nur indirekte Informationen über die Trainingsdaten für das Training verwendet (d. h. den Gradienten vom Diskriminator verwendet) und die Trainingsdaten nicht direkt als Eingabe erhält.

1 Million bedingungslos generierte Trainingsbilder, extrahiert aus verschiedenen vorab trainierten Generationsmodellen, dann wird das nach FID sortierte GAN-Modell (je niedriger, desto besser) oben platziert und das Diffusionsmodell wird unten platziert.
Die Ergebnisse zeigen, dass sich das Diffusionsmodell mehr als das GAN-Modell erinnert und bessere generative Modelle (niedrigere FID) dazu neigen, sich mehr Daten zu merken, das heißt, das Diffusionsmodell ist das am wenigsten private Bildmodell, dessen Form mehr als doppelt so hoch ist viele Trainingsdaten als GANs.

Und aus den oben genannten Ergebnissen lässt sich auch feststellen, dass die bestehende Technologie zur Verbesserung der Privatsphäre keinen akzeptablen Datenschutz bieten kann - Leistungskompromiss: Wenn Sie die Qualität der Generierung verbessern möchten, müssen Sie sich mehr Daten im Trainingssatz merken. Insgesamt beleuchtet dieses Papier die immer leistungsfähigeren Generationsmodelle und den Datenschutz und wirft Fragen darüber auf, wie Diffusionsmodelle funktionieren und wie sie verantwortungsvoll eingesetzt werden können.
Urheberrechtsproblem

Künstler haben mehrfach über ihre Urheberrechtsprobleme gestritten, da die vom Diffusionsmodell erzeugten Bilder übermäßig ähnlich sind und die Trainingsdaten vorliegen.
Zum Beispiel ist es AI verboten, seine eigenen Werke für das Training zu verwenden, und den veröffentlichten Werken werden zahlreiche Wasserzeichen hinzugefügt, und Stable Diffusion hat dies ebenfalls angekündigt Es ist geplant, nur Dateien zu verwenden, die einen Trainingsdatensatz mit lizenzierten Inhalten enthalten, und bietet einen Opt-out-Mechanismus für Künstler.
Auch im Bereich NLP stehen wir vor diesem Problem. Einige Internetnutzer sagten, dass seit 1993 Millionen von Textwörtern veröffentlicht wurden, und zwar bei allen KI-Anwendungen, einschließlich ChatGPT-3 Es wird auf „gestohlene Inhalte“ trainiert und es ist unethisch, KI-basierte generative Modelle zu verwenden.
Obwohl es viele Artikel auf der Welt gibt, für normale Leute , Plagiat ist nur eine verzichtbare Abkürzung; für die Urheber ist der plagiierte Inhalt jedoch ihre harte Arbeit.
Wird das Diffusionsmodell in Zukunft noch Vorteile haben? 
Das obige ist der detaillierte Inhalt vonNicht so gut wie GAN! Google, DeepMind und andere haben Artikel veröffentlicht: Diffusionsmodelle werden direkt aus dem Trainingssatz „kopiert'.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr