
Heim > Artikel > Technologie-Peripheriegeräte > Business-KI meistern: Aufbau einer KI-Plattform der Enterprise-Klasse mit RAG und CRAG
Business-KI meistern: Aufbau einer KI-Plattform der Enterprise-Klasse mit RAG und CRAG

- 王林nach vorne
- 2024-02-26 10:46:051131Durchsuche
Durchsuchen Sie unseren Leitfaden, um zu erfahren, wie Sie die KI-Technologie optimal für Ihr Unternehmen nutzen können. Erfahren Sie mehr über Dinge wie RAG- und CRAG-Integration, Vektoreinbettung, LLM und Prompt Engineering, die für Unternehmen von Vorteil sein werden, die künstliche Intelligenz verantwortungsvoll einsetzen möchten.
Aufbau KI-fähiger Plattformen für Unternehmen
Unternehmen Bei der Einführung generativer künstlicher Intelligenz stoßen sie auf viele Geschäftsrisiken, die ein strategisches Management erfordern. Diese Risiken hängen häufig miteinander zusammen und reichen von potenzieller Voreingenommenheit, die zu Compliance-Problemen führt, bis hin zu mangelndem Fachwissen. Zu den Hauptthemen gehören Reputationsschäden, die Einhaltung gesetzlicher und regulatorischer Standards (insbesondere in Bezug auf Kundeninteraktionen), Verletzungen des geistigen Eigentums, ethische Fragen und Datenschutzfragen (insbesondere bei der Verarbeitung personenbezogener oder identifizierbarer Daten).
Um diese Herausforderungen anzugehen, werden Hybridstrategien wie Retrieval-Augmented Generation (RAG) vorgeschlagen. Die RAG-Technologie kann die Qualität von durch künstliche Intelligenz generierten Inhalten verbessern und Unternehmenspläne für künstliche Intelligenz sicherer und zuverlässiger machen. Diese Strategie geht effektiv auf Probleme wie mangelndes Wissen und Fehlinformationen ein und gewährleistet gleichzeitig die Einhaltung rechtlicher und ethischer Richtlinien sowie die Vermeidung von Reputationsschäden und Nichteinhaltung.
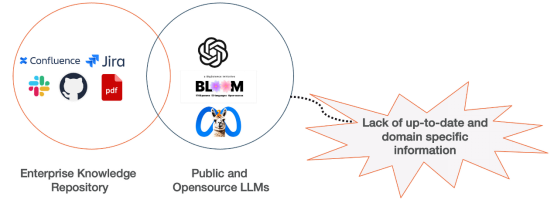
Verstehen Sie Retrieval Augmentation Generation (RAG)
Retrieval Augmentation Generation (RAG) ist ein fortschrittlicher Ansatz zur Leistungsverbesserung. Integration von Informationen aus der Wissensdatenbank eines Unternehmens. Genauigkeit und Zuverlässigkeit bei der Erstellung von KI-Inhalten. Stellen Sie sich RAG als einen Meisterkoch vor, der auf angeborenes Talent, gründliche Ausbildung und kreatives Gespür setzt, gestützt auf ein umfassendes Verständnis der Grundlagen des Kochens. Wenn es darum geht, ungewöhnliche Gewürze zu verwenden oder Wünsche nach neuartigen Gerichten zu erfüllen, ziehen Köche zuverlässige kulinarische Referenzen zu Rate, um die optimale Verwendung der Zutaten sicherzustellen.
So wie ein Koch eine Vielzahl von Küchen kochen kann, können auch künstliche Intelligenzsysteme wie GPT und LLaMA-2 Inhalte zu verschiedenen Themen generieren. Wenn es jedoch darum geht, detaillierte und genaue Informationen bereitzustellen, insbesondere wenn es um neuartige Küchen oder das Durchsuchen großer Mengen von Unternehmensdaten geht, greifen sie auf spezielle Tools zurück, um die Genauigkeit und Tiefe der Informationen sicherzustellen.
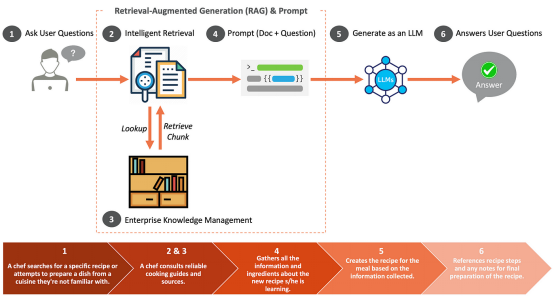
Was ist, wenn die Abrufphase von RAG nicht ausreicht?
CRAG ist eine korrigierende Intervention zur Verbesserung der Stabilität von RAG-Einstellungen. CRAG nutzt T5, um die Relevanz der abgerufenen Dokumente zu bewerten. Wenn von Unternehmen stammende Dokumente als irrelevant erachtet werden, können Websuchen genutzt werden, um Informationslücken zu schließen.
Architektonische Überlegungen für generative KI-Lösungen der Enterprise-Klasse
Die Architektur basiert im Wesentlichen auf drei Grundpfeilern: Datenaufnahme, Abfrage und intelligenter Abruf, Generate Prompt Engineering und Big Data-Sprachmodell . ? ein leicht abfragbares Format. Diese Transformation erfolgt mithilfe eines Einbettungsmodells, das der folgenden Abfolge von Vorgängen folgt:
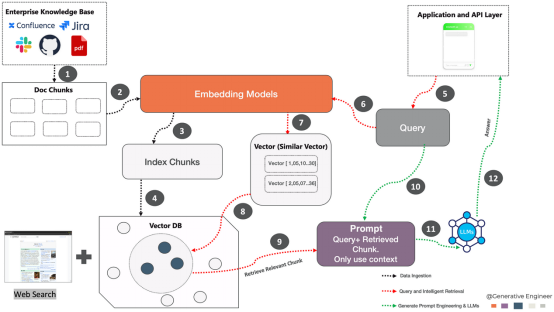
Verschiedene Dokumente aus Unternehmenswissensquellen wie Confluence, Jira und PDF werden extrahiert in System. Bei diesem Schritt wird das Dokument in überschaubare Teile zerlegt, die oft als „Blöcke“ bezeichnet werden. Einbettungsmodell: Übergeben Sie diese Dokumentblöcke dann an das Einbettungsmodell. Ein Einbettungsmodell ist ein neuronales Netzwerk, das Text in eine numerische Form (Vektor) umwandelt, die die Semantik des Textes darstellt und ihn so für Maschinen verständlich macht.
- Indexblock: Der vom Einbettungsmodell erzeugte Vektor wird dann indiziert. Bei der Indizierung werden Daten so organisiert, dass sie effizient abgerufen werden können.
- Vektordatenbank: Speichern Sie alle Vektoreinbettungen in einer Vektordatenbank. Und speichern Sie den durch jede Einbettung dargestellten Text in einer anderen Datei und achten Sie darauf, einen Verweis auf die entsprechende Einbettung einzufügen.
-
Abfrage und Smart Retrieval: Sobald der Inferenzserver die Frage des Benutzers empfängt, wandelt er sie durch einen Einbettungsprozess in einen Vektor um, der dasselbe Modell verwendet, um das Dokument in die Wissensdatenbank einzubetten. Anschließend wird die Vektordatenbank durchsucht, um Vektoren zu identifizieren, die in engem Zusammenhang mit der Absicht des Benutzers stehen, und sie werden einem großen Sprachmodell (LLM) zugeführt, um den Kontext anzureichern.
5.Abfragen: Abfragen aus der Anwendungs- und API-Ebene. Die Abfrage ist das, was ein Benutzer oder eine andere Anwendung bei der Suche nach Informationen eingibt.
6.Abruf eingebetteter Abfragen: Verwenden Sie die generierte Vector.Embedding, um eine Suche im Index der Vektordatenbank zu starten. Wählen Sie die Anzahl der Vektoren aus, die Sie aus der Vektordatenbank abrufen möchten. Diese Anzahl ist proportional zur Anzahl der Kontexte, die Sie kompilieren und zur Lösung des Problems verwenden möchten.
7. Vektoren (Ähnlichkeitsvektoren): Dieser Prozess identifiziert ähnliche Vektoren, die Teile von Dokumenten darstellen, die für den Abfragekontext relevant sind.
8.Verwandte Vektoren abrufen:
Verwandte Vektoren aus der Vektordatenbank abrufen. Im Kontext eines Kochs könnte es sich beispielsweise um zwei verwandte Vektoren handeln: ein Rezept und einen Zubereitungsschritt. Entsprechende Fragmente werden gesammelt und mit der Eingabeaufforderung versehen.9. Zugehörige Blöcke abrufen: Das System ruft Teile des Dokuments ab, die mit Vektoren übereinstimmen, die als relevant für die Abfrage identifiziert wurden. Sobald die Relevanz der Informationen beurteilt wurde, bestimmt das System die nächsten Schritte. Wenn die Informationen vollständig konsistent sind, werden sie nach Wichtigkeit geordnet. Wenn die Informationen falsch sind, verwirft das System sie und sucht online nach besseren Informationen. ...
Eingabeaufforderungen generieren
Technik ist entscheidend, um große Sprachmodelle so zu steuern, dass sie die richtigen Antworten geben . Dabei geht es darum, klare und präzise Fragen zu erstellen, die etwaige Datenlücken berücksichtigen. Dieser Prozess ist fortlaufend und erfordert regelmäßige Anpassungen für eine bessere Reaktion. Es ist auch wichtig, sicherzustellen, dass die Fragen ethisch und voreingenommen sind und sensible Themen vermieden werden.
10. Prompt Engineering: Die abgerufenen Blöcke werden dann mit der ursprünglichen Abfrage verwendet, um den Prompt zu erstellen. Dieser Hinweis dient dazu, dem Sprachmodell den Abfragekontext effektiv zu übermitteln. 11. LLM (Large Scale Language Model): Technische Tipps werden von großen Sprachmodellen verarbeitet. Diese Modelle können basierend auf den empfangenen Eingaben menschenähnlichen Text generieren.
12. Antwort: Schließlich verwendet das Sprachmodell den durch den Hinweis bereitgestellten Kontext und die abgerufenen Blöcke, um die Antwort auf die Abfrage zu generieren. Diese Antwort wird dann über die Anwendungs- und API-Ebene an den Benutzer zurückgesendet.
Fazit Dieser Blog untersucht den komplexen Prozess der Integration von KI in die Softwareentwicklung und hebt das transformative Potenzial des Aufbaus einer von CRAG inspirierten unternehmensweiten generativen KI-Plattform hervor. Indem wir uns mit der Komplexität von Just-in-Time-Engineering, Datenmanagement und innovativen RAG-Ansätzen (Retrieval-Augmented Generation) befassen, skizzieren wir Möglichkeiten, KI-Technologie in den Kern des Geschäftsbetriebs zu integrieren. Zukünftige Diskussionen werden sich weiter mit dem
Generative Artificial Intelligence Framework for Intelligent Development befassen und spezifische Tools, Techniken und Strategien zur Maximierung des Einsatzes künstlicher Intelligenz untersuchen, um eine intelligentere und effizientere Entwicklungsumgebung sicherzustellen. Quelle |
https://www.php.cn/link/1f3e9145ab192941f32098750221c602Autor |Venkat Rangasamy
Das obige ist der detaillierte Inhalt vonBusiness-KI meistern: Aufbau einer KI-Plattform der Enterprise-Klasse mit RAG und CRAG. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was sind die Entwicklungstrends der künstlichen Intelligenz?
- Zu welchem Studienfach gehört Künstliche Intelligenz?
- Wie ordne ich Text in KI entsprechend seiner Form an?
- Was sind die Anwendungsmerkmale der Technologie der künstlichen Intelligenz im Militär?
- Was sind die Klassifizierungen künstlicher Intelligenz?