
Heim >Technologie-Peripheriegeräte >KI >Voller nützlicher Informationen! Die erste Textversion des zweistündigen KI-Kurses von Master Karpathy, ein neuer Workflow wandelt Videos automatisch in Artikel um
Voller nützlicher Informationen! Die erste Textversion des zweistündigen KI-Kurses von Master Karpathy, ein neuer Workflow wandelt Videos automatisch in Artikel um

- PHPznach vorne
- 2024-02-26 11:00:201198Durchsuche
Vor einiger Zeit hat der Online-KI-Kurs von KI-Meister Karpathy 150.000 Aufrufe im gesamten Netzwerk erhalten.
Zu dieser Zeit sagten einige Internetnutzer, dass der Wert dieses zweistündigen Kurses dem Wert von 4 Jahren College entsprach.
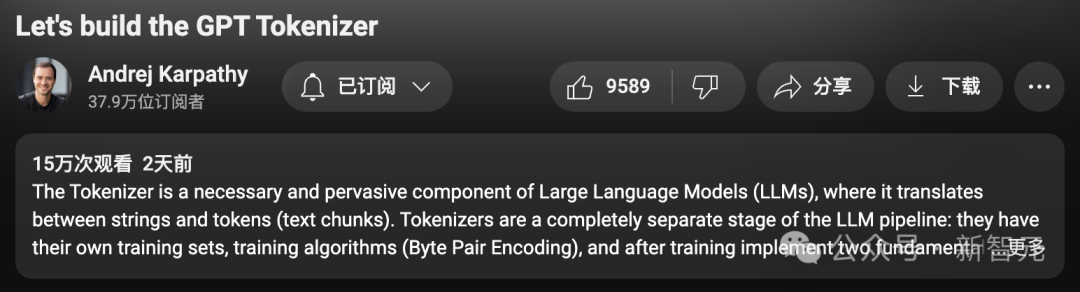
Erst in den letzten Tagen hatte Karpathy eine neue Idee:
Konvertieren Sie die 2 Stunden und 13 Minuten des Videoinhalts „Building a GPT Tokenizer from Scratch“ in ein Buchkapitel oder einen Blog Die Form des Artikels konzentriert sich auf das Thema „Wortsegmentierung“.
Die spezifischen Schritte sind wie folgt:
- Fügen Sie dem Video Untertitel oder Erzähltext hinzu.
- Schneiden Sie das Video in mehrere Absätze mit passenden Bildern und Texten.
- Nutzen Sie die Prompt-Engineering-Technologie großer Sprachmodelle, um Absatz für Absatz zu übersetzen.
– Geben Sie die Ergebnisse als Webseite mit Links zu Teilen des Originalvideos aus.
Im weiteren Sinne kann ein solcher Workflow auf jede Videoeingabe angewendet werden und automatisch „unterstützende Anleitungen“ für verschiedene Tutorials in einem Format generieren, das einfacher zu lesen, zu durchsuchen und zu durchsuchen ist.
Es klingt machbar, aber auch ziemlich herausfordernd.
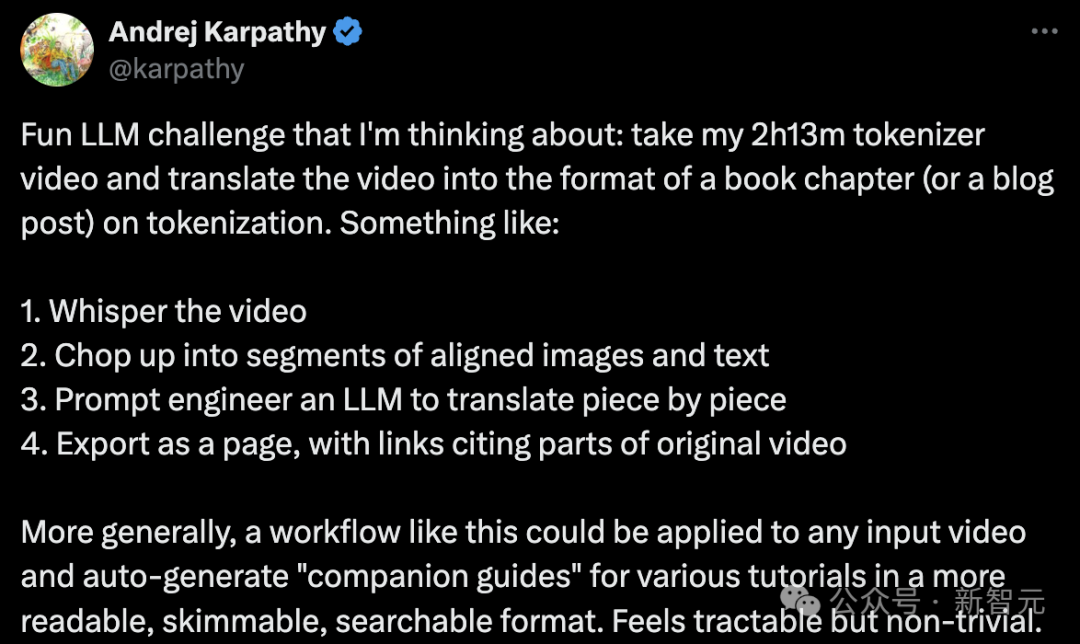
Er hat im Rahmen des GitHub-Projekts minbpe ein Beispiel geschrieben, um seine Fantasie zu veranschaulichen.
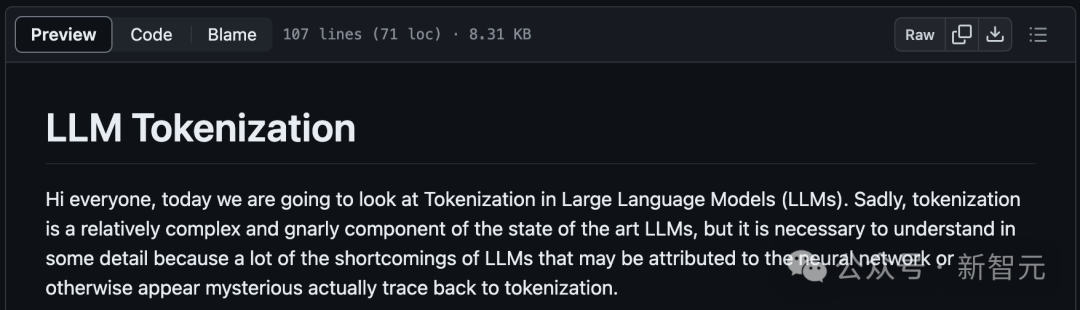
Adresse: https://github.com/karpathy/minbpe/blob/master/lecture.md
Karpathy sagte, dass dies eine manuelle Aufgabe sei, das heißt, das Video anzusehen und zu übersetzen Artikel im Markdown-Format.
„Ich habe mir nur etwa 4 Minuten des Videos angesehen (also 3 % fertig), und das Schreiben hat etwa 30 Minuten gedauert. Es wäre also großartig, wenn so etwas automatisch erledigt werden könnte.“
Als nächstes ist Unterrichtszeit!
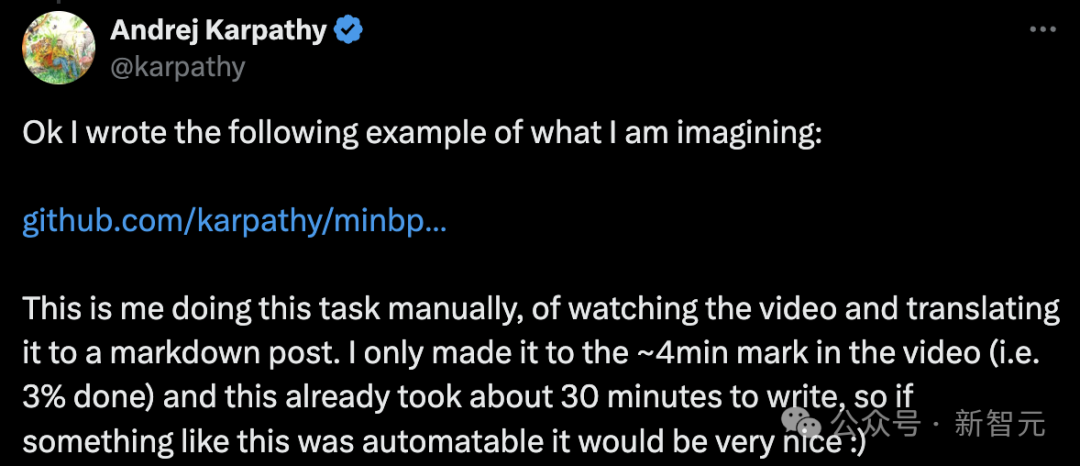
Textversion des Kurses „LLM-Wortsegmentierung“
Hallo zusammen, heute werden wir das Thema „Wortsegmentierung“ in LLM besprechen.
Leider ist die „Wortsegmentierung“ eine relativ komplexe und knifflige Komponente der fortschrittlichsten großen Modelle, aber wir müssen sie im Detail verstehen.
Denn viele Mängel des LLM können auf neuronale Netze oder andere scheinbar mysteriöse Faktoren zurückgeführt werden, diese Mängel können jedoch tatsächlich auf die „Wortsegmentierung“ zurückgeführt werden.
Wortsegmentierung auf Zeichenebene
Was ist also Wortsegmentierung?
Tatsächlich habe ich im vorherigen Video „Lasst uns GPT von Grund auf neu erstellen“ bereits die Tokenisierung eingeführt, aber das war nur eine sehr einfache Version auf Zeichenebene.
Wenn Sie zu Google Colab gehen und sich das Video ansehen, werden Sie sehen, dass wir mit den Trainingsdaten (Shakespeare) beginnen, die in Python nur eine große Zeichenfolge sind:
First Citizen: Before we proceed any further, hear me speak.All: Speak, speak.First Citizen: You are all resolved rather to die than to famish?All: Resolved. resolved.First Citizen: First, you know Caius Marcius is chief enemy to the people.All: We know't, we know't.
Aber wie Geben wir die Zeichenfolge in „Was ist mit LLM“ ein?
Wir können sehen, dass wir zunächst ein Vokabular für alle möglichen Zeichen im gesamten Trainingssatz erstellen müssen:
# here are all the unique characters that occur in this textchars = sorted(list(set(text)))vocab_size = len(chars)print(''.join(chars))print(vocab_size)# !$&',-.3:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz# 65Erstellen Sie dann basierend auf dem Vokabular oben ein Vokabular für die Nachschlagetabelle zwischen einzelnen Zeichen und ganzen Zahlen zur Konvertierung. Diese Nachschlagetabelle ist nur ein Python-Wörterbuch:
stoi = { ch:i for i,ch in enumerate(chars) }itos = { i:ch for i,ch in enumerate(chars) }# encoder: take a string, output a list of integersencode = lambda s: [stoi[c] for c in s]# decoder: take a list of integers, output a stringdecode = lambda l: ''.join([itos[i] for i in l])print(encode("hii there"))print(decode(encode("hii there")))# [46, 47, 47, 1, 58, 46, 43, 56, 43]# hii thereSobald wir eine Zeichenfolge in eine Folge von Ganzzahlen konvertieren, sehen wir, dass jede Ganzzahl als Index für die 2D-Einbettung der trainierbaren Parameter verwendet wird.
Da unser Vokabular die Größe vocab_size=65 hat, wird diese Einbettungstabelle auch 65 Zeilen haben:
class BigramLanguageModel(nn.Module):def __init__(self, vocab_size):super().__init__()self.token_embedding_table = nn.Embedding(vocab_size, n_embd)def forward(self, idx, targets=None):tok_emb = self.token_embedding_table(idx) # (B,T,C)
Hier „extrahiert“ die Ganzzahl eine Zeile aus der Einbettungstabelle, und diese Zeile ist der Vektor, der die Wortsegmentierung darstellt. Dieser Vektor wird dann als Eingabe für den entsprechenden Zeitschritt in den Transformer eingespeist.
Verwendung des BPE-Algorithmus für die „Character Chunk“-Segmentierung
Das ist alles schön und gut für einen naiven Aufbau eines Sprachmodells auf „Zeichenebene“.
Aber in der Praxis verwenden Menschen in modernen Sprachmodellen komplexere Schemata, um diese repräsentativen Vokabulare aufzubauen.
Konkret funktionieren diese Lösungen nicht auf der Zeichenebene, sondern auf der Ebene „Zeichenblock“. Die Art und Weise, wie diese Chunk-Vokabulare erstellt werden, basiert auf Algorithmen wie Byte Pair Encoding (BPE), die wir im Folgenden ausführlich beschreiben.
Lassen Sie uns kurz die historische Entwicklung dieser Methode betrachten. Der Artikel, der den BPE-Algorithmus auf Byte-Ebene für die Wortsegmentierung von Sprachmodellen verwendet, ist der GPT-2-Artikel „Language Models are Unsupervised Multitask Learners“, der 2019 von OpenAI veröffentlicht wurde. 🔜 . Am Ende dieses Abschnitts steht:

Denken Sie daran, dass in der Aufmerksamkeitsebene des Transformers jeder Token mit einer begrenzten Liste vorheriger Token in der Sequenz verknüpft ist.
In diesem Artikel wird darauf hingewiesen, dass die Kontextlänge des GPT-2-Modells von 512 Token in GPT-1 auf 1024 Token gestiegen ist.Mit anderen Worten, Token ist das grundlegende „Atom“ am Eingang von LLM.
„Tokenisierung“ ist der Prozess der Konvertierung von Originalzeichenfolgen in Python in Tokenlisten und umgekehrt.
Es gibt ein weiteres beliebtes Beispiel, das die Universalität dieser Abstraktion beweist. Wenn Sie im Artikel von Llama 2 auch nach „Token“ suchen, erhalten Sie 63 passende Ergebnisse.
 Zum Beispiel wird in der Zeitung behauptet, dass sie mit 2 Billionen Token usw. trainiert haben.
Zum Beispiel wird in der Zeitung behauptet, dass sie mit 2 Billionen Token usw. trainiert haben.
Papieradresse: https://arxiv.org/pdf/2307.09288.pdf
Ein kurzer Vortrag über die Komplexität der Wortsegmentierung

Bevor wir uns mit den Details befassen Implementierung, lassen Sie uns kurz erklären, dass es notwendig ist, den Prozess der „Wortsegmentierung“ im Detail zu verstehen.
Die Tokenisierung ist der Kern vieler, vieler seltsamer Probleme im LLM, und ich empfehle Ihnen, sie nicht zu ignorieren. Viele scheinbare Probleme mit der Architektur neuronaler Netzwerke hängen tatsächlich mit der Wortsegmentierung zusammen. Hier nur ein paar Beispiele:
- Warum kann LLM keine Wörter buchstabieren? ——Wortsegmentierung
- Warum kann LLM keine supereinfachen String-Verarbeitungsaufgaben ausführen, wie zum Beispiel das Umkehren von Strings? ——Wortsegmentierung
- Warum ist LLM bei nicht englischsprachigen Aufgaben (z. B. Japanisch) schlechter? ——Partizip
- Warum ist LLM nicht gut im einfachen Rechnen? ——Wortsegmentierung
- Warum stößt GPT-2 beim Codieren in Python auf mehr Probleme? ——Wortsegmentierung
- Warum stoppt mein LLM plötzlich, wenn es die Zeichenfolge sieht? ——Partizip
- Was ist diese seltsame Warnung, die ich bezüglich „nachgestellter Leerzeichen“ erhalten habe? ——Partizip
- Wenn ich LLM nach „SolidGoldMagikarp“ frage, warum stürzt es ab? ——Wortsegmentierung
- Warum sollte ich YAML mit LLM anstelle von JSON verwenden? ——Wortsegmentierung
- Warum ist LLM keine echte End-to-End-Sprachmodellierung? ——Partizip

Wir werden am Ende des Videos auf diese Fragen zurückkommen.
Visuelle Vorschau der Wortsegmentierung
Als nächstes laden wir diese Wortsegmentierungs-WebApp.
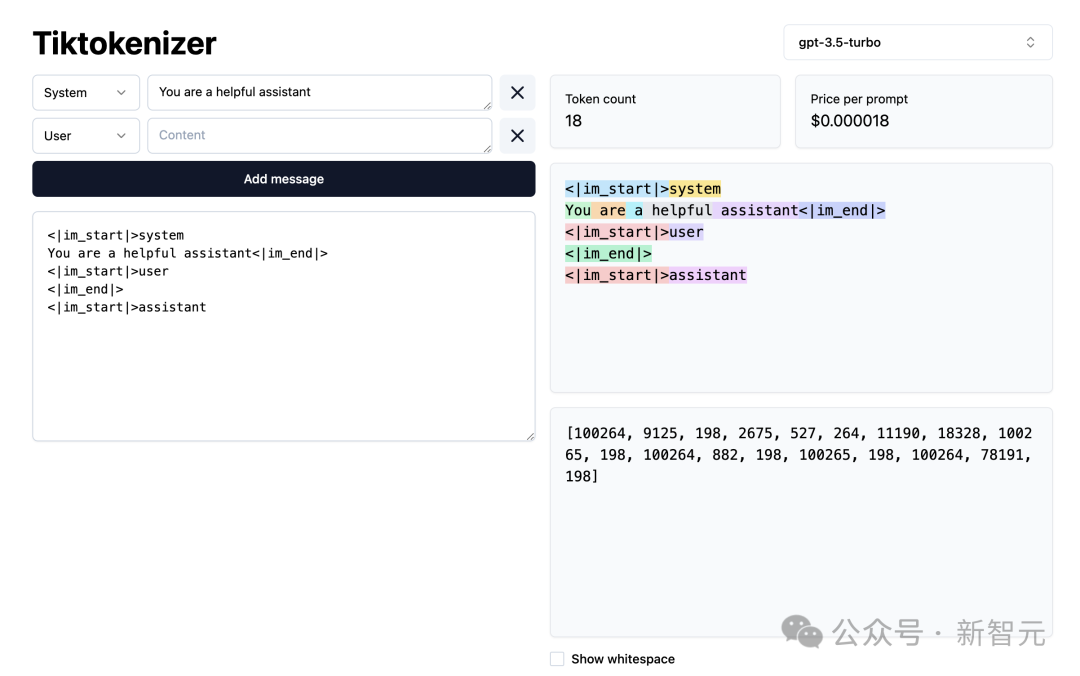
Adresse: https://tiktokenizer.vercel.app/
Der Vorteil dieser Webanwendung besteht darin, dass die Tokenisierung in Echtzeit im Webbrowser ausgeführt wird, sodass Sie problemlos Text eingeben können Geben Sie die Zeichenfolge auf der Eingabeseite ein und sehen Sie sich rechts die Ergebnisse der Wortsegmentierung an.
Oben können Sie sehen, dass wir derzeit den gpt2-Tokenizer verwenden, und Sie können sehen, dass die in diesem Beispiel eingefügte Zeichenfolge derzeit in 300 Tokens tokenisiert wird.
Hier sind sie deutlich farblich dargestellt:
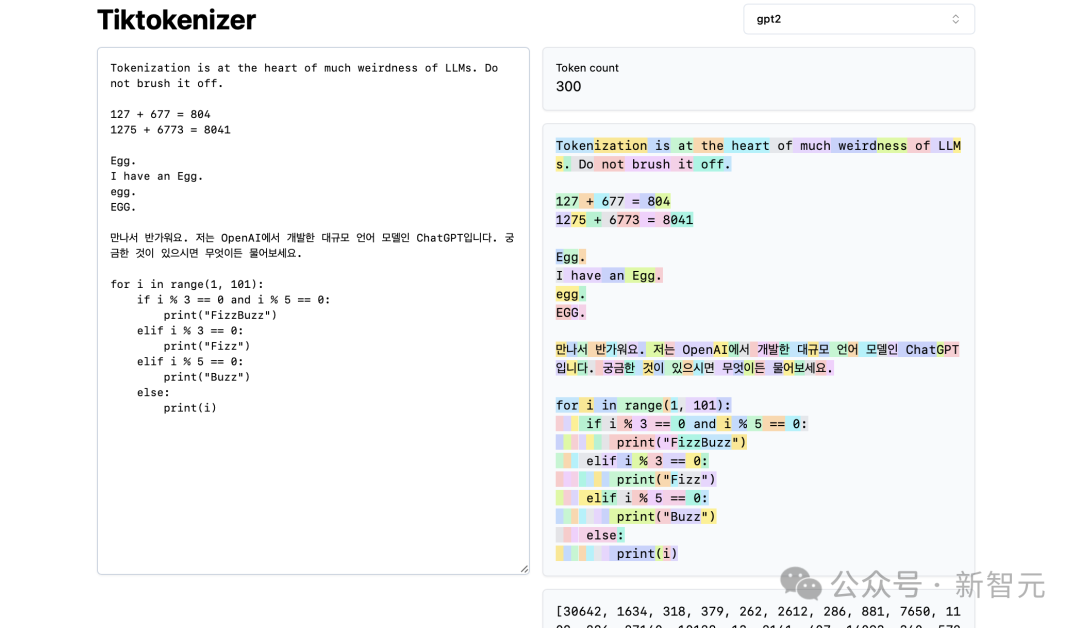
Zum Beispiel wird die Zeichenfolge „Tokenization“ in Token30642 codiert, gefolgt von Token 1634.
token „is“ (beachten Sie, dass dies aus drei Zeichen besteht, einschließlich des vorangehenden Leerzeichens, das ist wichtig!) ist 318.
Seien Sie vorsichtig bei der Verwendung von Leerzeichen, da diese unbedingt in der Zeichenfolge vorhanden sind und zusammen mit allen anderen Zeichen formuliert werden müssen. Aus Gründen der Übersichtlichkeit wird es bei der Visualisierung jedoch meist weggelassen.
Sie können die Visualisierungsfunktion unten in der App ein- und ausschalten. Ebenso ist das Token „at“ 379, „the“ 262 und so weiter.
Als nächstes haben wir ein einfaches Rechenbeispiel.
Hier sehen wir, dass der Tokenizer bei der Zerlegung von Zahlen inkonsistent sein kann. Beispielsweise ist die Zahl 127 ein Token mit drei Zeichen, aber die Zahl 677 liegt daran, dass es zwei Token gibt: 6 (beachten Sie auch hier das vorhergehende Leerzeichen) und 77.
Wir verlassen uns auf LLM, um diese Beliebigkeit zu erklären.
Es muss innerhalb seiner Parameter und während des Trainings etwas über diese beiden Token (6 und 77 ergeben zusammen die Zahl 677) lernen.
Ebenso können wir sehen, dass, wenn das LLM vorhersagen möchte, dass das Ergebnis dieser Summe die Zahl 804 ist, es diese in zwei Zeitschritten ausgeben muss:
Zuerst muss es den Token „8“ ausgeben , und dann ist es Token „04“.
Bitte beachten Sie, dass alle diese Aufteilungen völlig willkürlich aussehen. Im folgenden Beispiel können wir sehen, dass 1275 „12“ und dann „75“ ist, 6773 tatsächlich drei Token „6“, „77“ und „3“ sind und 8041 „8“ und „041“ ist.
(Fortsetzung folgt...)
(TODO: Wenn Sie mit der Textversion des Inhalts fortfahren möchten, es sei denn, wir finden heraus, wie wir ihn automatisch aus dem Video generieren können)

Netizens sind online, um Ratschläge zu geben
Netizens sagten: Großartig, ich lese diese Beiträge tatsächlich lieber, anstatt Videos anzusehen, es ist einfacher, meinen eigenen Rhythmus zu kontrollieren.

Einige Internetnutzer gaben Karpathy einen Rat:
„Es fühlt sich schwierig an, aber mit LangChain könnte es möglich sein. Ich habe mich gefragt, ob ich die Flüstertranskription verwenden könnte, um eine übergeordnete Gliederung mit klaren Kapiteln zu erstellen und diese Kapitelabschnitte dann parallel zu verarbeiten und mich dabei auf jedes einzelne Kapitel im Kontext zu konzentrieren.“ Der Gesamtinhalt des Kapitelblocks (für jedes parallel verarbeitete Kapitel werden auch Bilder generiert. Anschließend werden alle generierten Referenzmarken bis zum Ende des Artikels zusammengestellt.)

Jemand hat dafür eine Pipeline geschrieben, die bald Open Source sein wird.
Das obige ist der detaillierte Inhalt vonVoller nützlicher Informationen! Die erste Textversion des zweistündigen KI-Kurses von Master Karpathy, ein neuer Workflow wandelt Videos automatisch in Artikel um. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So konvertieren Sie während der Windows-Installation einen MBR-Datenträger in einen GPT-Datenträger
- Welche Software sind Ai, Ae und Ps?
- Was ist KI-Technologie?
- Empfehlung für das VSCode-Plugin: ChatGPT Plus chinesische Version, die die Entwicklereffizienz erheblich verbessert!
- 3-minütiges Kurz-Tutorial zur Verwendung von ChatGPT. Verwenden Sie es, um mir beim Schreiben meines Lebenslaufs zu helfen.