
Heim >Technologie-Peripheriegeräte >KI >Wie wendet man große NLP-Modelle auf Zeitreihen an? Eine Zusammenfassung der fünf Methodenkategorien!
Wie wendet man große NLP-Modelle auf Zeitreihen an? Eine Zusammenfassung der fünf Methodenkategorien!

- PHPznach vorne
- 2024-02-19 23:50:031015Durchsuche
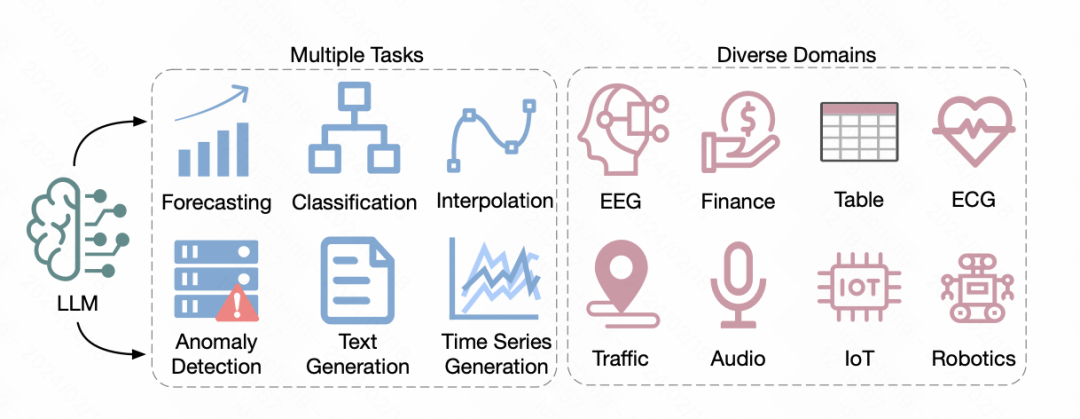
Kürzlich hat die University of California einen Übersichtsartikel veröffentlicht, in dem Methoden zur Anwendung vorab trainierter großer Sprachmodelle im Bereich der Verarbeitung natürlicher Sprache auf Zeitreihenvorhersagen untersucht werden. Dieser Artikel fasst die Anwendung von 5 verschiedenen NLP-Großmodellen im Zeitreihenbereich zusammen. Als Nächstes werden wir diese 5 in diesem Testbericht erwähnten Methoden kurz vorstellen.
 Bilder
Bilder
Papiertitel: Large Language Models for Time Series: A Survey
Download-Adresse: https://arxiv.org/pdf/2402.01801.pdf
 Bilder
Bilder
1 Prompt-Methode
Durch die direkte Verwendung der Prompt-Methode kann das Modell die Ausgabe für Zeitreihendaten vorhersagen. Bei der vorherigen Eingabeaufforderungsmethode bestand die Grundidee darin, einen Eingabeaufforderungstext vorab zu trainieren, ihn mit Zeitreihendaten zu füllen und das Modell Vorhersageergebnisse generieren zu lassen. Wenn Sie beispielsweise einen Text erstellen, der eine Zeitreihenaufgabe beschreibt, geben Sie die Zeitreihendaten ein und lassen Sie das Modell Vorhersageergebnisse direkt ausgeben.
 Bilder
Bilder
Bei der Verarbeitung von Zeitreihen werden Zahlen oft als Teil des Textes betrachtet, und auch das Thema der Tokenisierung von Zahlen hat große Aufmerksamkeit erregt. Einige Methoden fügen gezielt Leerzeichen zwischen Zahlen ein, um Zahlen klarer zu unterscheiden und unangemessene Unterscheidungen zwischen Zahlen in Wörterbüchern zu vermeiden.
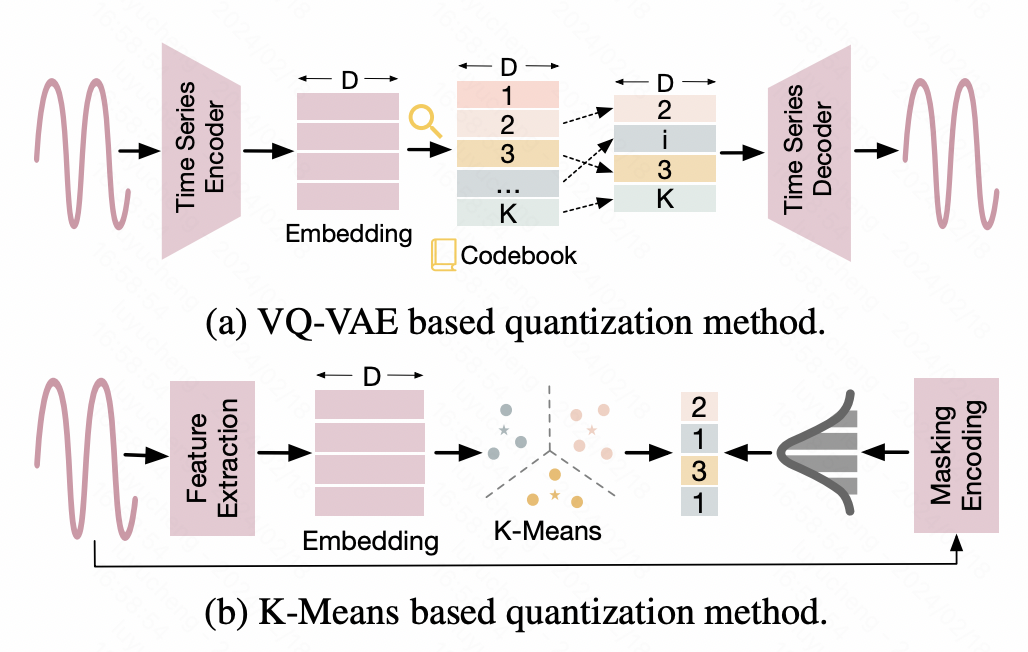
2. Diskretisierung
Diese Art von Methode diskretisiert Zeitreihen und wandelt kontinuierliche Werte in diskrete ID-Ergebnisse um, um sie an die Eingabeform großer NLP-Modelle anzupassen. Ein Ansatz besteht beispielsweise darin, Zeitreihen mit Hilfe der Vector Quantized-Variational AutoEncoder (VQ-VAE)-Technologie in diskrete Darstellungen abzubilden. VQ-VAE ist eine auf VAE basierende Autoencoder-Struktur, die die ursprüngliche Eingabe über den Encoder in einen Darstellungsvektor umwandelt und dann die ursprünglichen Daten über den Decoder wiederherstellt. VQ-VAE stellt sicher, dass der zwischenzeitlich generierte Darstellungsvektor diskretisiert wird. Auf der Grundlage dieses diskretisierten Darstellungsvektors wird ein Wörterbuch erstellt, um die Abbildung der Diskretisierung von Zeitreihendaten zu realisieren. Eine andere Methode basiert auf der K-Means-Diskretisierung und verwendet die von Kmeans generierten Schwerpunkte, um die ursprüngliche Zeitreihe zu diskretisieren. Darüber hinaus werden in einigen Arbeiten Zeitreihen auch direkt in Text umgewandelt. In einigen Finanzszenarien werden beispielsweise tägliche Preiserhöhungen, Preissenkungen und andere Informationen direkt in entsprechende Buchstabensymbole als Eingabe für das große NLP-Modell umgewandelt.
 Bilder
Bilder
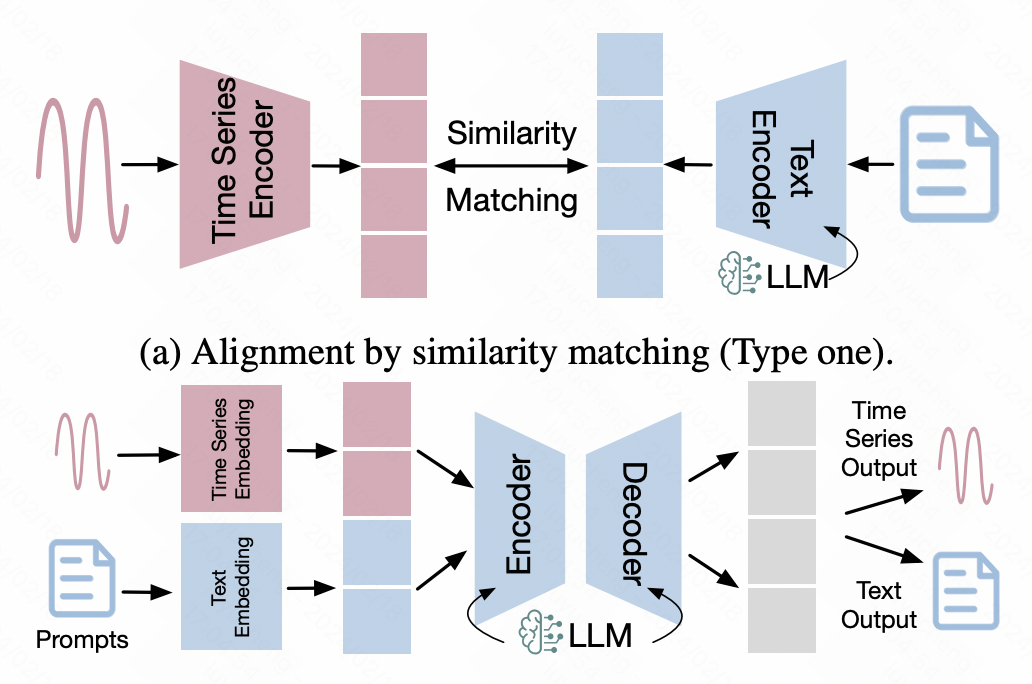
3. Zeitreihen-Textausrichtung
Diese Art von Methode basiert auf der Ausrichtungstechnologie im multimodalen Bereich, um die Darstellung von Zeitreihen im Textraum auszurichten, wodurch Zeitreihendaten direkt ausgerichtet werden können Eingabe in NLP-Großmodellziele.
Bei dieser Art von Methode werden häufig einige multimodale Ausrichtungsmethoden verwendet. Die typischste Variante ist die multimodale Ausrichtung, die auf kontrastivem Lernen basiert. Ähnlich wie bei CLIP werden ein Zeitreihen-Encoder und ein großes Modell verwendet, um die Darstellungsvektoren von Zeitreihen bzw. Text einzugeben, und dann wird kontrastives Lernen verwendet, um die Distanz zu verkürzen zwischen positiven Stichprobenpaaren. Ausrichtung von Darstellungen von Zeitreihen und Textdaten im latenten Raum.
Eine weitere Methode ist die Feinabstimmung basierend auf Zeitreihendaten, wobei das große NLP-Modell als Rückgrat verwendet wird und auf dieser Grundlage zusätzliche Zeitreihendaten zur Netzwerkanpassung eingeführt werden. Unter ihnen sind effiziente modalübergreifende Feinabstimmungsmethoden wie LoRA relativ verbreitet. Sie frieren die meisten Parameter des Backbones ein und optimieren nur eine kleine Anzahl von Parametern oder führen eine kleine Anzahl von Adapterparametern zur Feinabstimmung ein, um eine multimodale Ausrichtung zu erreichen.
 Bilder
Bilder
4. Einführung visueller Informationen
Diese Methode stellt normalerweise eine Verbindung zwischen Zeitreihen und visuellen Informationen her und führt dann multimodale Funktionen ein, die anhand von Bildern und Texten eingehend untersucht wurden . , um effektive Funktionen für nachgelagerte Aufgaben zu extrahieren. Beispielsweise richtet ImageBind die Daten von sechs Modalitäten, einschließlich Daten vom Typ Zeitreihe, einheitlich aus, um die Vereinheitlichung großer multimodaler Modelle zu erreichen. Einige Modelle im Finanzbereich wandeln Aktienkurse in Diagrammdaten um und verwenden dann CLIP, um Bilder und Texte auszurichten und diagrammbezogene Funktionen für nachgelagerte Zeitreihenaufgaben zu generieren.
5. Werkzeuge für große Modelle
Diese Art von Methode verbessert nicht mehr das NLP-Großmodell oder transformiert die Zeitreihendatenform für die Anpassung großer Modelle, sondern nutzt das NLP-Großmodell direkt als Werkzeug zur Lösung von Zeitreihenproblemen. Lassen Sie beispielsweise das große Modell Code generieren, um die Zeitreihenvorhersage zu lösen, und wenden Sie ihn auf die Zeitreihenvorhersage an, oder lassen Sie das große Modell die Open-Source-API aufrufen, um Zeitreihenprobleme zu lösen. Natürlich ist diese Methode eher auf praktische Anwendungen ausgerichtet.
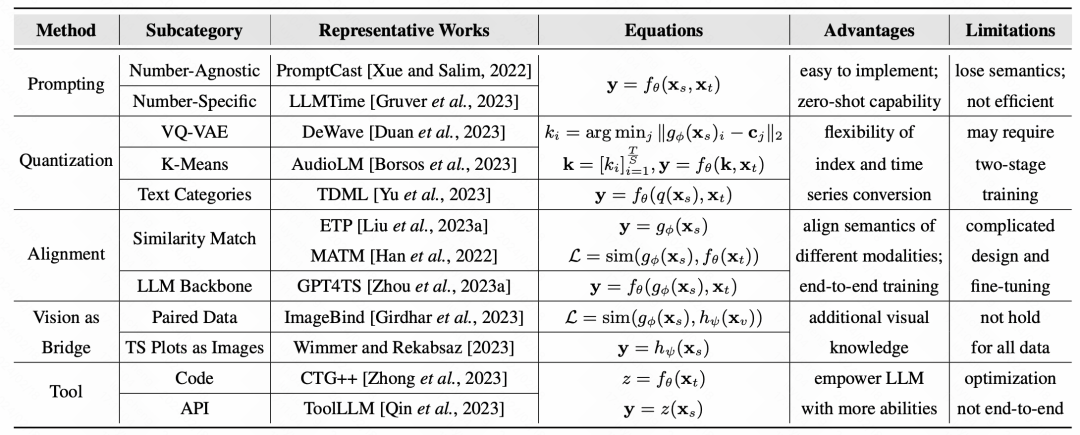
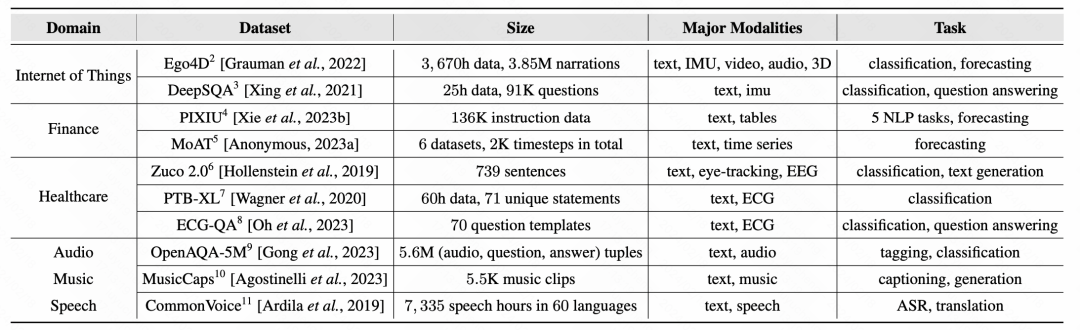
Abschließend fasst der Artikel die repräsentativen Arbeiten und repräsentativen Datensätze verschiedener Methoden zusammen:
 Bilder
Bilder
 Bilder
Bilder
Das obige ist der detaillierte Inhalt vonWie wendet man große NLP-Modelle auf Zeitreihen an? Eine Zusammenfassung der fünf Methodenkategorien!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- LeCun prognostiziert AGI: Sowohl große Modelle als auch verstärktes Lernen sind weit verbreitet! Mein „Weltmodell' ist der neue Weg
- Wie erkennt man im Zeitalter der großen Models unangemessene Inhalte? Der EU-Gesetzentwurf verpflichtet KI-Unternehmen, das Recht der Nutzer auf Information sicherzustellen
- Erstellen Sie Ihre eigenen Tools für große Modelle wie GPT-4, um ChatGPT-Betrug zu erkennen
- Wenn Sie möchten, dass das große Modell mehr Beispiele in der Eingabeaufforderung lernt, können Sie mit dieser Methode mehr Zeichen eingeben
- Themenmodellierungstechnologie im Bereich NLP