
Heim >Technologie-Peripheriegeräte >KI >Sie können direkt mit Windows und Office loslegen. Es ist so einfach, einen Computer mit einem großen Modellagenten zu bedienen.
Sie können direkt mit Windows und Office loslegen. Es ist so einfach, einen Computer mit einem großen Modellagenten zu bedienen.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-19 23:33:221276Durchsuche
Wenn es um die Zukunft der KI-Assistenten geht, kann man leicht an den KI-Assistenten Jarvis in der „Iron Man“-Reihe denken. Jarvis zeigt im Film schillernde Funktionen. Er ist nicht nur Tony Starks rechte Hand, sondern auch seine Brücke zur Kommunikation mit fortschrittlicher Technologie. Mit dem Aufkommen großformatiger Modelle erfährt die Art und Weise, wie Menschen Werkzeuge nutzen, revolutionäre Veränderungen, und vielleicht sind wir einem Science-Fiction-Szenario einen Schritt näher gekommen. Stellen Sie sich einen multimodalen Agenten vor, der die Computer um uns herum wie Menschen direkt über Tastatur und Maus steuern kann.
KI-Assistent Jarvis
Die neueste Forschung „ScreenAgent: A Vision Language Model-driven Computer Control Agent“ von der School of Artificial Intelligence der Jilin University zeigt die Vorstellungskraft, ein großes visuelles Sprachmodell zu verwenden Steuern Sie direkt die Computer-GUI. In dieser Studie wurde das ScreenAgent-Modell vorgeschlagen, das erstmals die direkte Steuerung von Computermäusen und -tastaturen über den VLM-Agenten untersuchte, ohne dass zusätzliche Etikettenunterstützung erforderlich war, und so das Ziel der direkten Computerbedienung von Großmodellen erreichte. Darüber hinaus nutzt ScreenAgent erstmals einen automatisierten „Plan-Execute-Reflect“-Prozess, um eine kontinuierliche Kontrolle der GUI-Oberfläche zu erreichen. Diese Arbeit erforscht und innoviert Methoden der Mensch-Computer-Interaktion sowie Open-Source-Ressourcen, darunter Datensätze, Controller und Trainingscodes mit präzisen Positionierungsinformationen.

- Papieradresse: https://arxiv.org/abs/2402.07945
- Projektadresse: https://github.com/niuzaisheng/ScreenAgent
ScreenAgent bietet Benutzern bequeme Online-Unterhaltung, Einkaufs-, Reise- und Leseerlebnisse. Es kann auch als persönlicher Butler verwendet werden, um die Verwaltung von Personalcomputern zu erleichtern und schnelles Arbeiten zu ermöglichen. Es kann ohne großen Aufwand zu einem leistungsstarken Büroassistenten werden. Durch praktische Effekte können Benutzer seine Funktionalität verstehen.
führt Sie zum Surfen im Internet und zur Freiheit der Unterhaltung
ScreenAgent sucht online nach bestimmten Videos und spielt diese auf der Grundlage von Benutzertextbeschreibungen ab:
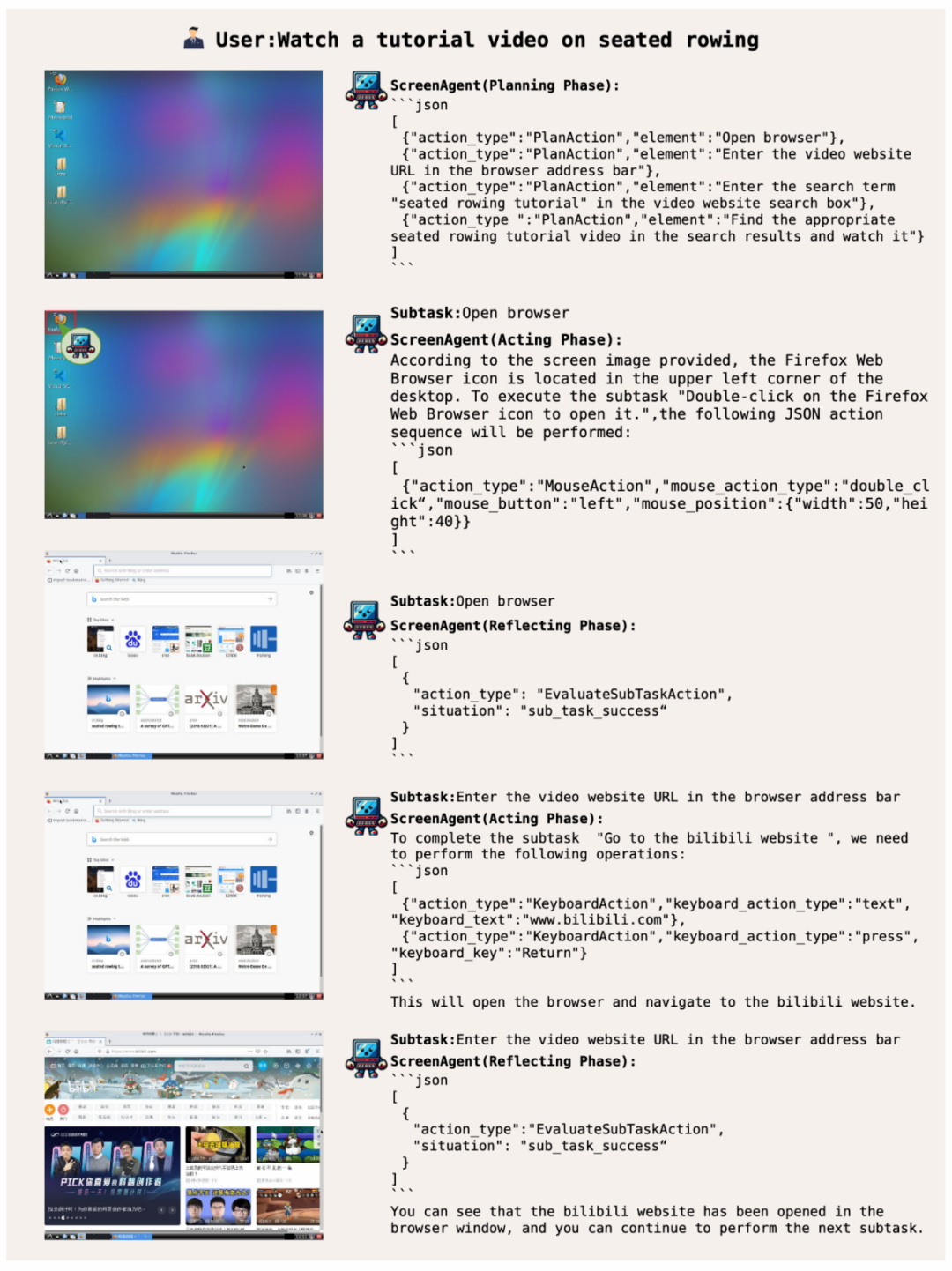
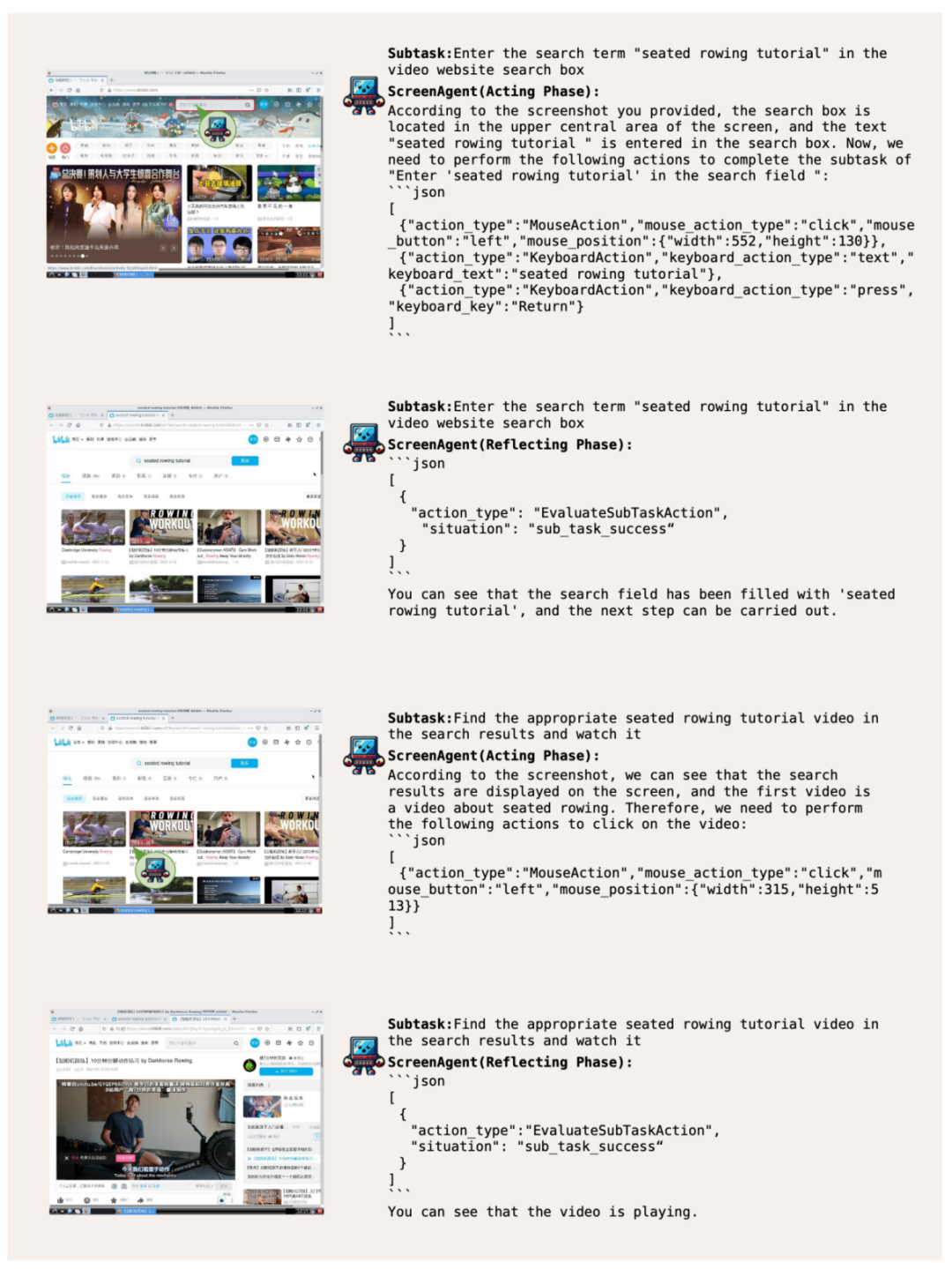
Systembetriebsmanager, Angabe Benutzer mit hochqualifizierten Fähigkeiten
Lassen Sie ScreenAgent die Windows-Ereignisanzeige öffnen:
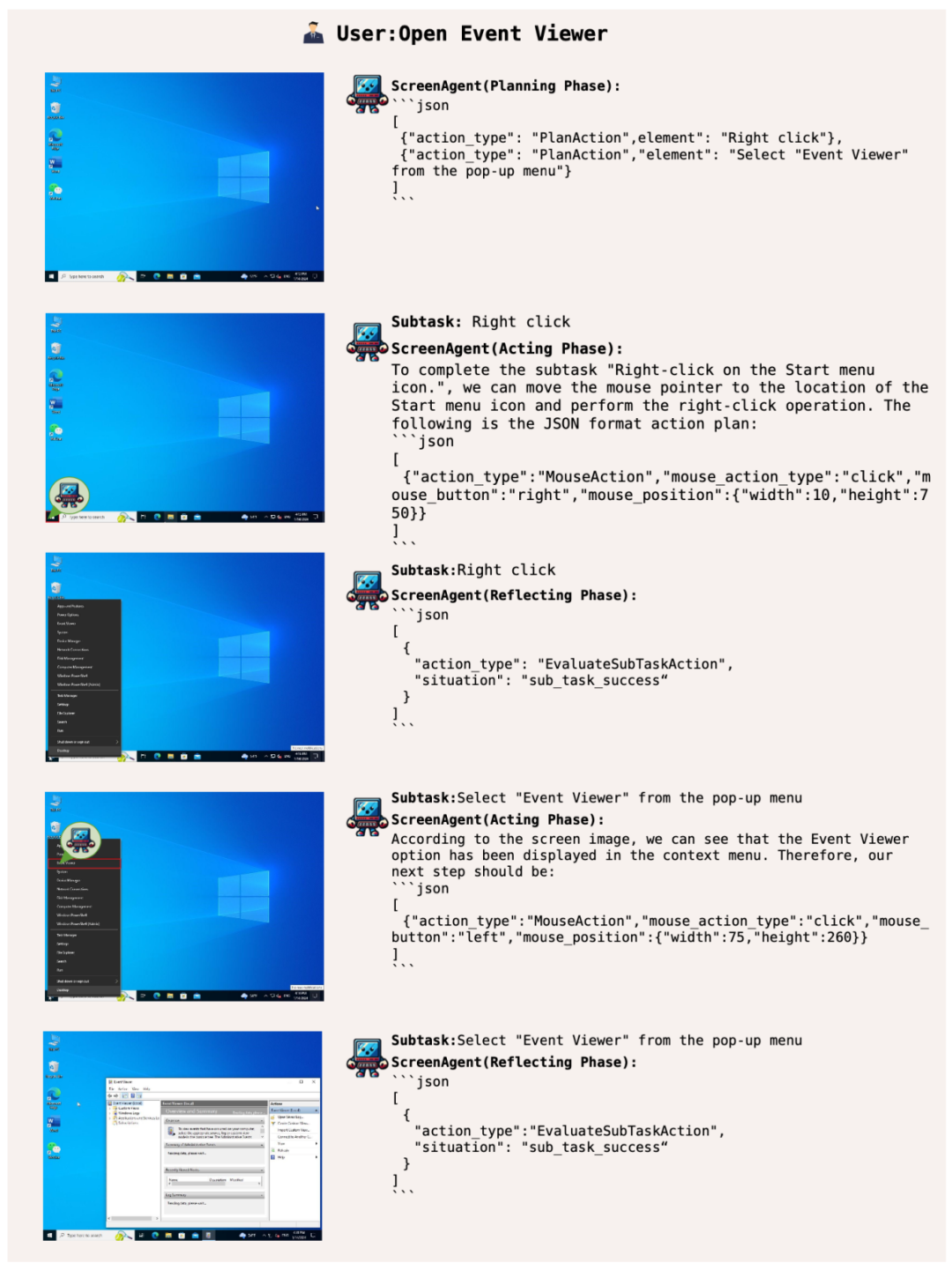
Beherrschen Sie Office-Kenntnisse und spielen Sie einfach mit Office
Darüber hinaus kann ScreenAgent Office-Software verwenden. Löschen Sie beispielsweise gemäß der Textbeschreibung des Benutzers die PPT auf der zweiten Seite, die geöffnet wird:
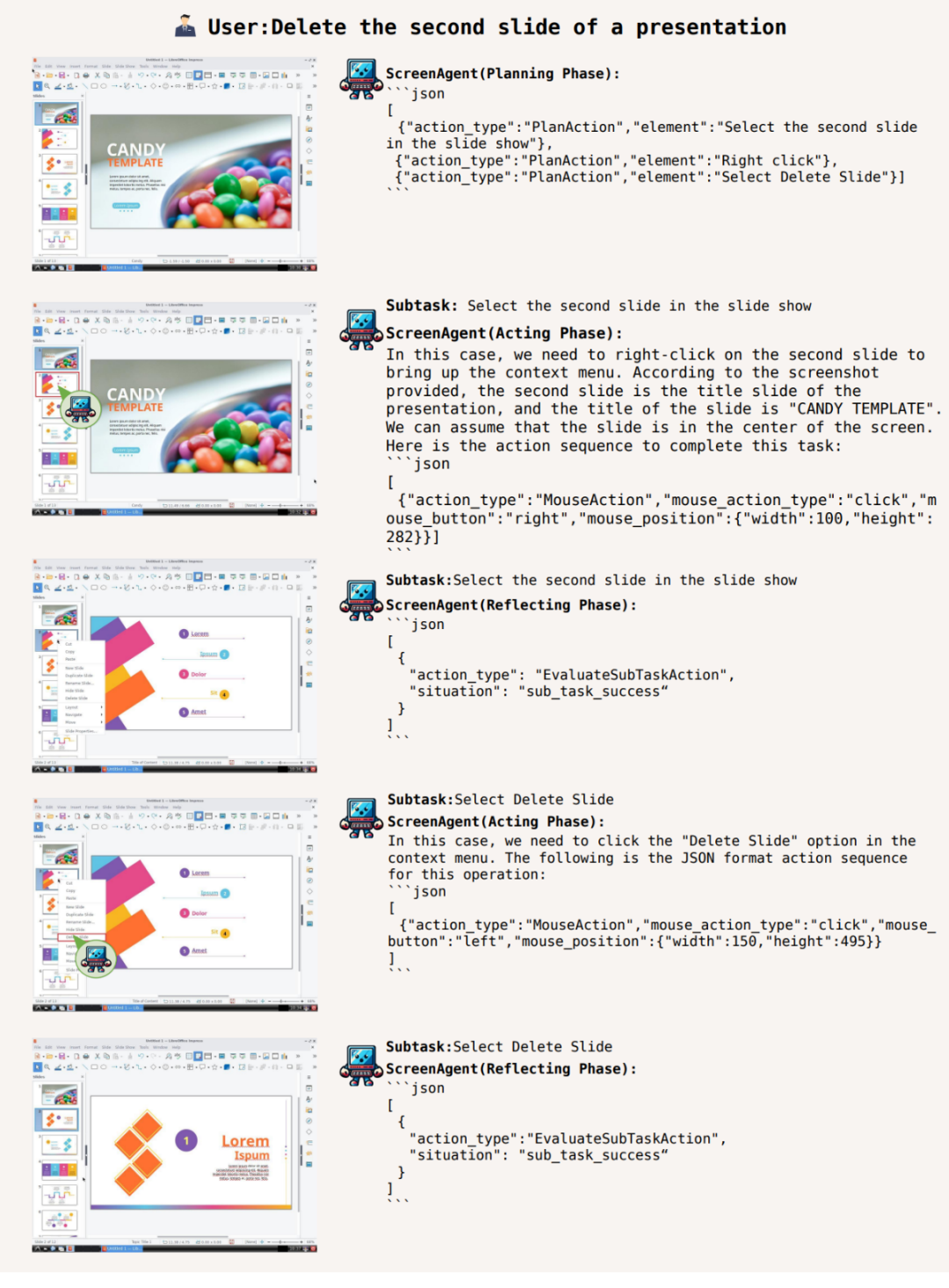
Planen Sie, bevor Sie Maßnahmen ergreifen, wissen Sie, wo Sie anhalten und gewinnen müssen
Um eine bestimmte Aufgabe abzuschließen , es muss getan werden, bevor die Aufgabe ausgeführt wird. Machen Sie bei der Planung der Aktivitäten gute Arbeit. ScreenAgent kann vor Beginn der Aufgabe Pläne auf der Grundlage der beobachteten Bilder und Benutzerbedürfnisse erstellen, zum Beispiel:
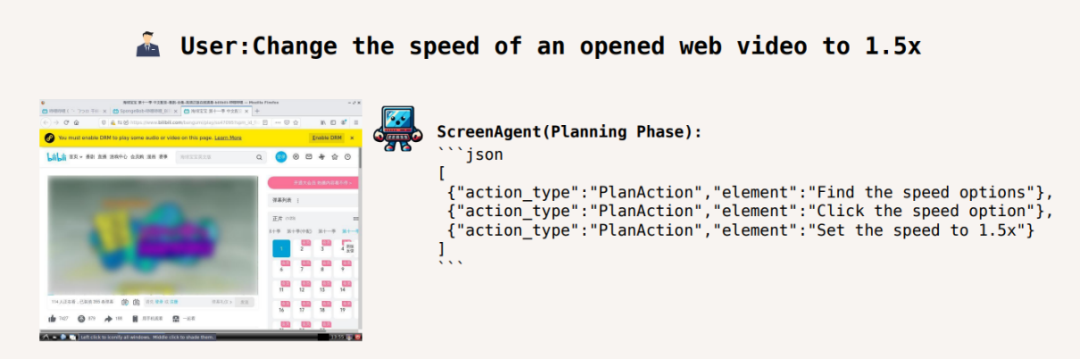
Passen Sie die Videowiedergabegeschwindigkeit auf das 1,5-fache an:
Suche nach gebrauchten Magotan-Autos in 58 Städten Websites Preis:

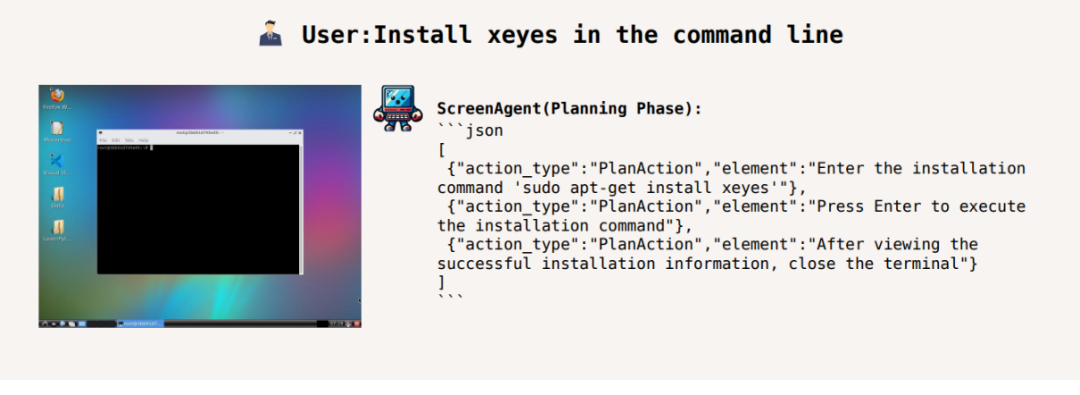
Installieren Sie xeyes in der Befehlszeile:
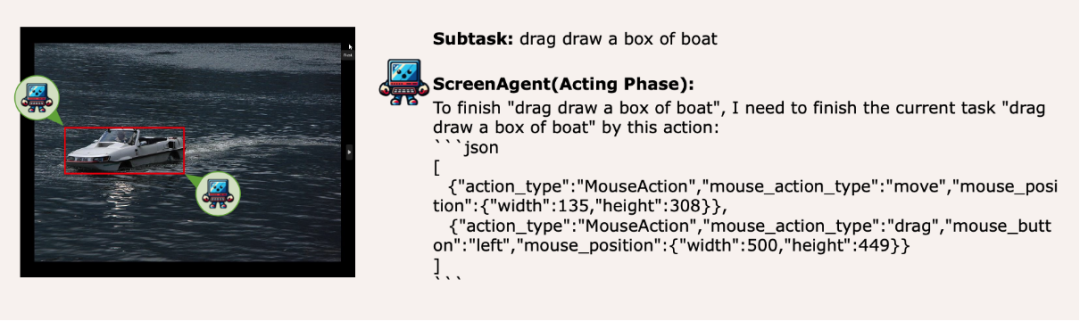
Migration der visuellen Positionierungsfähigkeit, Mausauswahl ist stressfrei
ScreenAgent behält auch die Fähigkeit, natürliche Objekte visuell zu lokalisieren, und kann durch Ziehen mit der Maus einen Auswahlrahmen eines Objekts zeichnen:

Methode
Tatsächlich muss der Agent sein Die direkte Interaktion mit der grafischen Benutzeroberfläche ist keine einfache Angelegenheit. Sie erfordert, dass der Agent über mehrere umfassende Fähigkeiten wie Aufgabenplanung, Bildverständnis, visuelle Positionierung und Werkzeugnutzung verfügt. Es gibt bestimmte Kompromisse bei bestehenden Modellen oder Interaktionslösungen. Beispielsweise mangelt es Modellen wie LLaVA-1.5 an präzisen visuellen Positionierungsfunktionen für großformatige Bilder, die jedoch nicht möglich sind Erhalten Sie genaue Koordinaten. Bestehende Lösungen erfordern die manuelle Annotation zusätzlicher digitaler Beschriftungen auf Bildern und ermöglichen dem Modell die Auswahl von UI-Elementen, die angeklickt werden müssen, wie z. B. Mobile-Agent, UFO und andere Projekte. Darüber hinaus können Modelle wie CogAgent und Fuyu-8B unterstützt werden Hochauflösende Bilder Es verfügt über Eingabe- und präzise visuelle Positionierungsfunktionen, CogAgent verfügt jedoch nicht über vollständige Funktionsaufruffunktionen und Fuyu-8B über keine Sprachfunktionen.
Um die oben genannten Probleme zu lösen, schlägt der Artikel vor, eine neue Umgebung für den Visual Language Model Agent (VLM Agent) zu erstellen, um mit dem realen Computerbildschirm zu interagieren. In dieser Umgebung kann der Agent Screenshots beobachten und die grafische Benutzeroberfläche durch die Ausgabe von Maus- und Tastaturaktionen manipulieren. Um den VLM-Agenten bei der kontinuierlichen Interaktion mit dem Computerbildschirm anzuleiten, wird in dem Artikel ein Betriebsprozess erstellt, der „Planung-Ausführung-Reflexion“ umfasst. Während der Planungsphase wird der Agent gebeten, Benutzeraufgaben in Teilaufgaben zu zerlegen. Während der Ausführungsphase beobachtet der Agent Screenshots und führt bestimmte Maus- und Tastaturaktionen aus, um Unteraufgaben auszuführen. Der Controller führt diese Aktionen aus und gibt die Ausführungsergebnisse an den Agenten zurück. Während der Reflexionsphase beobachtet der Agent die Ausführungsergebnisse, ermittelt den aktuellen Status und entscheidet, ob er die Ausführung fortsetzen, es erneut versuchen oder den Plan anpassen möchte. Dieser Vorgang wird fortgesetzt, bis die Aufgabe abgeschlossen ist. Es ist erwähnenswert, dass ScreenAgent keine Texterkennungs- oder Symbolerkennungsmodule verwenden muss und einen End-to-End-Ansatz verwendet, um alle Funktionen des Modells zu trainieren.
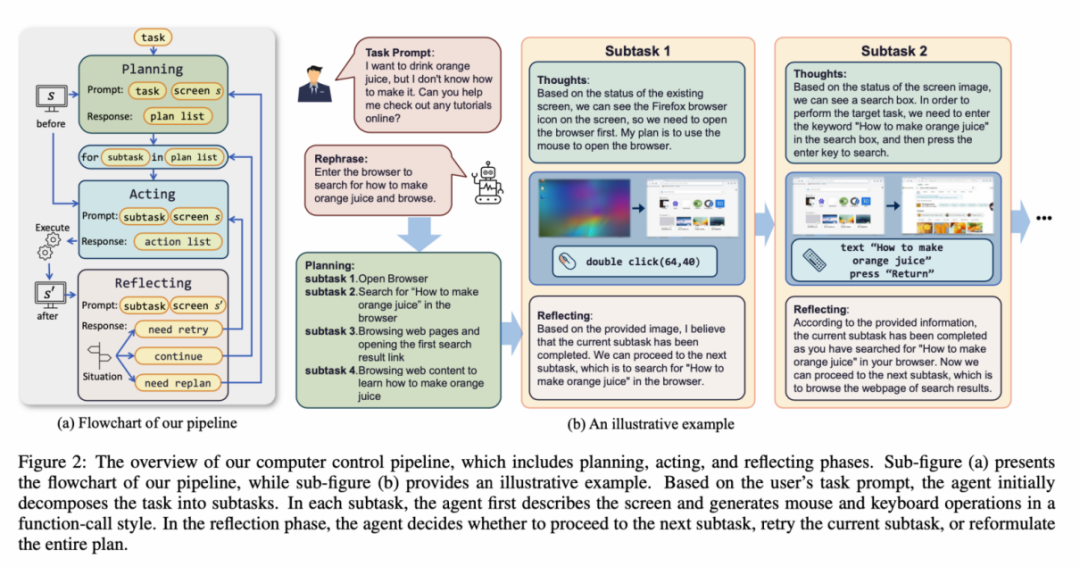
Die ScreenAgent-Umgebung bezieht sich auf das VNC-Remote-Desktop-Verbindungsprotokoll zur Gestaltung des Aktionsbereichs des Agenten, einschließlich der grundlegendsten Maus- und Tastaturoperationen, bei denen der Agent genaue Bildschirmkoordinaten angeben muss. Im Vergleich zum Aufrufen spezifischer APIs zum Erledigen von Aufgaben ist diese Methode allgemeiner und kann auf verschiedene Desktop-Betriebssysteme und -Anwendungen wie Windows und Linux Desktop angewendet werden.
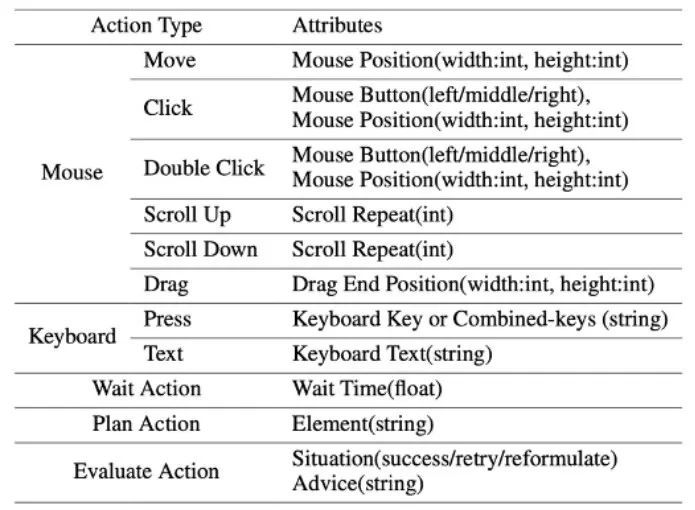
ScreenAgent-Datensatz
Um das ScreenAgent-Modell zu trainieren, hat der Artikel den ScreenAgent-Datensatz manuell mit präzisen visuellen Positionierungsinformationen versehen. Dieser Datensatz deckt ein breites Spektrum täglicher Computeraufgaben ab, darunter Dateivorgänge, Surfen im Internet, Spieleunterhaltung und andere Szenarien in Windows- und Linux-Desktopumgebungen.
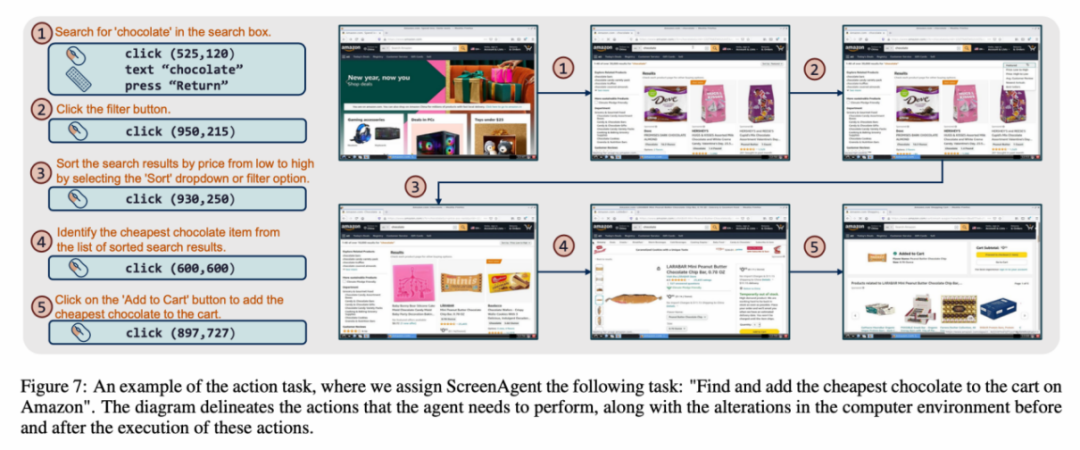
Jedes Beispiel im Datensatz ist ein vollständiger Prozess zur Erledigung einer Aufgabe, einschließlich Aktionsbeschreibungen, Screenshots und spezifischer ausgeführter Aktionen. Wenn Sie beispielsweise auf der Amazon-Website „die günstigste Schokolade in den Warenkorb legen“, müssen Sie zunächst im Suchfeld nach Schlüsselwörtern suchen, dann die Preise mithilfe von Filtern sortieren und schließlich die günstigsten Artikel zum Warenkorb hinzufügen Wagen. Der gesamte Datensatz enthält 273 vollständige Aufgabendatensätze.
Experimentelle Ergebnisse
Im Teil der experimentellen Analyse verglich der Autor ScreenAgent mit mehreren vorhandenen VLM-Modellen aus verschiedenen Blickwinkeln, hauptsächlich einschließlich zweier Ebenen, Fähigkeit zur Befehlsfolge und Genauigkeit der feinkörnigen Aktionsvorhersagerate. Die Fähigkeit zur Anweisungsfolge testet hauptsächlich, ob das Modell die Aktionssequenz und den Aktionstyp korrekt im JSON-Format ausgeben kann. Die Genauigkeit der Aktionsattributvorhersage vergleicht, ob der Attributwert jeder Aktion korrekt vorhergesagt wird, z. B. Mausklickposition, Tastaturtasten usw.
Befehl zum Befolgen
In Bezug auf die Befehlsfolge besteht die erste Aufgabe des Agenten darin, den richtigen Tool-Funktionsaufruf entsprechend dem Eingabeaufforderungswort auszugeben, also das richtige JSON-Format auszugeben. In dieser Hinsicht können sowohl ScreenAgent als auch GPT-4V folgen Der Befehl ist sehr gut und der ursprüngliche CogAgent Aufgrund der fehlenden Datenunterstützung in Form von API-Aufrufen während des visuellen Feinabstimmungstrainings geht die Möglichkeit zur Ausgabe von JSON verloren.
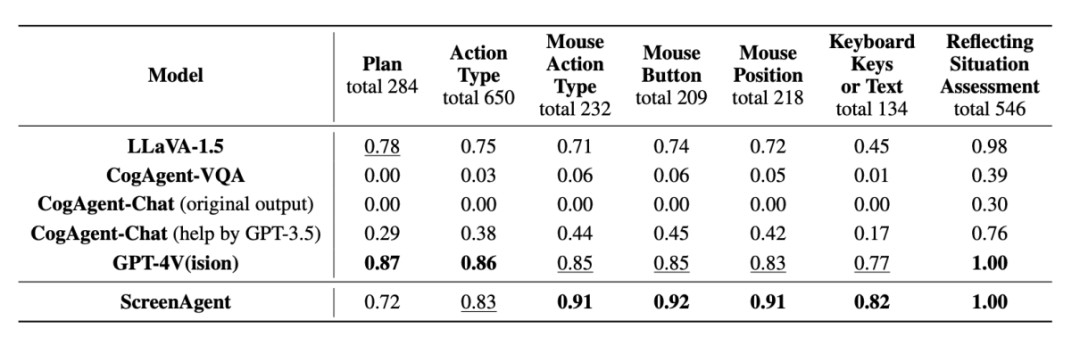
Vorhersage der Genauigkeitsrate der Aktionsattribute
Aus Sicht der Genauigkeitsrate der Aktionsattribute hat ScreenAgent ebenfalls ein mit GPT-4V vergleichbares Niveau erreicht. Bemerkenswert ist, dass ScreenAgent bestehende Modelle hinsichtlich der Mausklickgenauigkeit bei weitem übertrifft. Dies zeigt, dass die visuelle Feinabstimmung die präzise Positionierungsfähigkeit des Modells effektiv verbessert. Darüber hinaus beobachten wir auch eine deutliche Lücke zwischen ScreenAgent und GPT-4V bei der Missionsplanung, was das gesunde Menschenverstandswissen und die Missionsplanungsfähigkeiten von GPT-4V unterstreicht.
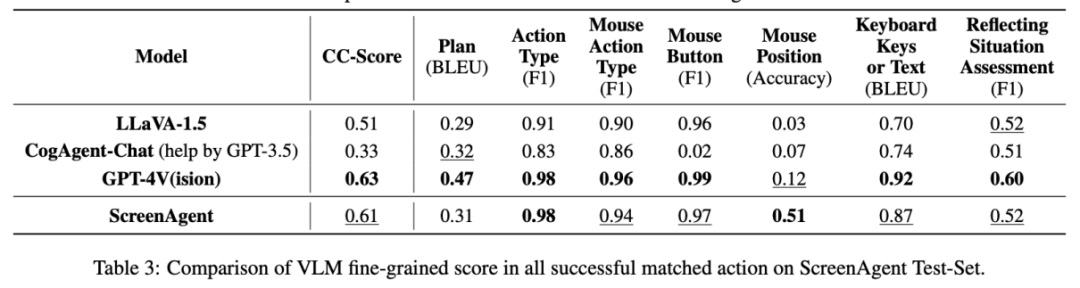
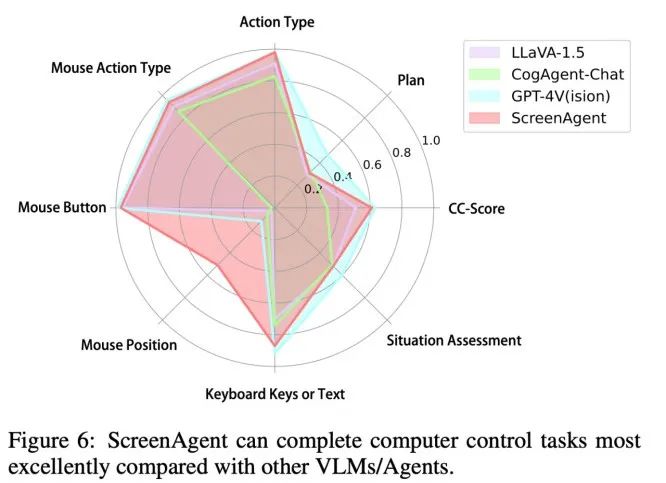
Fazit
Der vom Team der Jilin University School of Artificial Intelligence vorgeschlagene ScreenAgent kann Computer auf die gleiche Weise steuern wie Menschen, ist nicht auf andere APIs oder OCR-Modelle angewiesen und kann es sein weit verbreitet in verschiedenen Anwendungssoftware und Betriebssystemen. ScreenAgent kann vom Benutzer vorgegebene Aufgaben unter der Kontrolle des „Plan-Ausführung-Reflexion“-Prozesses autonom erledigen. Auf diese Weise können Benutzer jeden Schritt der Aufgabenerledigung sehen und die Verhaltensgedanken des Agenten besser verstehen.
Der Artikel enthält Open-Source-Steuerungssoftware, Modelltrainingscode und Datensatz. Auf dieser Grundlage können Sie innovativere Arbeiten zur allgemeinen künstlichen Intelligenz erkunden, z. B. verstärkendes Lernen unter Umgebungsrückmeldung, aktive Erkundung der offenen Welt durch Agenten, Aufbau von Weltmodellen, Bibliotheken für Agentenfähigkeiten usw.
Darüber hinaus haben von KI-Agenten gesteuerte persönliche Assistenten einen enormen sozialen Wert, indem sie beispielsweise Menschen mit eingeschränkten Gliedmaßen bei der Nutzung von Computern helfen, repetitive digitale Arbeit für Menschen reduzieren und die Computererziehung populärer machen. In Zukunft kann vielleicht nicht jeder ein Superheld wie Iron Man werden, aber wir haben vielleicht alle einen exklusiven Jarvis, einen intelligenten Partner, der uns in unserem Leben und bei unserer Arbeit begleiten, unterstützen und führen kann, was uns mehr Komfort und Möglichkeiten bietet.
Das obige ist der detaillierte Inhalt vonSie können direkt mit Windows und Office loslegen. Es ist so einfach, einen Computer mit einem großen Modellagenten zu bedienen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So importieren Sie Daten aus einer Excel-Tabelle in eine andere Tabelle
- Was ist die SQL-Anweisung zum Erstellen einer Datenbank?
- Was ist ein Virus, der speziell für die Bekämpfung weit verbreiteter Bürosoftware entwickelt wurde?
- Die zugrunde liegende Python-Technologie enthüllte: wie Modelltraining und -vorhersage implementiert werden
- Nutzen Sie die Vision, um zu motivieren! Shen Xiangyang stellte das neue Modell des IDEA Research Institute vor, das weder Schulung noch Feinabstimmung erfordert und sofort einsatzbereit ist.