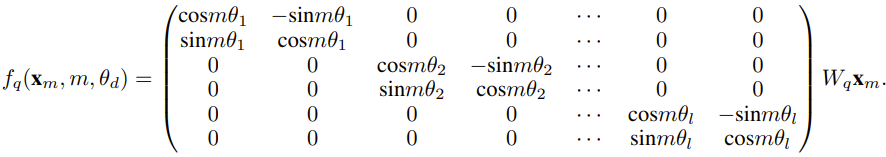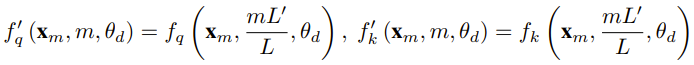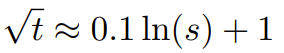Transformer-basierte Large-Language-Modelle (LLM) haben die leistungsstarke Fähigkeit zum kontextuellen Lernen (ICL) bewiesen und sind für viele Aufgaben der Verarbeitung natürlicher Sprache (NLP) fast zur einzigen Wahl geworden. Der Selbstaufmerksamkeitsmechanismus von Transformer ermöglicht eine hohe Parallelisierung des Trainings, sodass lange Sequenzen verteilt verarbeitet werden können. Die Länge der für das LLM-Training verwendeten Sequenz wird als Kontextfenster bezeichnet.
Das Kontextfenster von Transformer bestimmt direkt den Platz, in dem Beispiele bereitgestellt werden können, und schränkt somit seine ICL-Funktionen ein. Wenn das Kontextfenster des Modells begrenzt ist, gibt es weniger Platz, um dem Modell robuste Beispiele für die Durchführung von ICL bereitzustellen. Darüber hinaus werden auch andere Aufgaben wie die Zusammenfassung stark beeinträchtigt, wenn das Kontextfenster des Modells besonders kurz ist. In Bezug auf die Natur der Sprache selbst ist der Standort des Tokens entscheidend für eine effektive Modellierung, und die Selbstaufmerksamkeit codiert Standortinformationen aufgrund ihrer Parallelität nicht direkt. Die Transformer-Architektur führt die Positionskodierung ein, um dieses Problem zu lösen. Die ursprüngliche Transformer-Architektur verwendete eine absolute Sinuspositionskodierung, die später zu einer lernbaren absoluten Positionskodierung verbessert wurde. Seitdem haben Codierungsschemata für relative Positionen die Leistung von Transformer weiter verbessert. Derzeit sind die beliebtesten relativen Positionskodierungen T5 Relative Bias, RoPE, XPos und ALiBi. Die Positionskodierung weist eine wiederkehrende Einschränkung auf: die Unfähigkeit, auf das während des Trainings angezeigte Kontextfenster zu verallgemeinern. Obwohl einige Methoden wie ALiBi in der Lage sind, eine begrenzte Verallgemeinerung durchzuführen, wurde bisher noch keine Methode auf Sequenzen verallgemeinert, die wesentlich länger als ihre vorab trainierte Länge sind. Es gibt einige Forschungsergebnisse, die versuchen, diese Einschränkungen zu überwinden. Einige Untersuchungen schlagen beispielsweise vor, RoPE durch Positionsinterpolation (PI) leicht zu modifizieren und eine kleine Datenmenge zu optimieren, um die Kontextlänge zu erweitern. Vor zwei Monaten teilte Bowen Peng von Nous Research auf Reddit eine Lösung mit, die darin besteht, „NTK-fähige Interpolation“ durch Einbeziehung von Hochfrequenzverlusten zu implementieren. NTK bezieht sich hier auf Neural Tangent Kernel. Es wird behauptet, dass das NTK-fähige erweiterte RoPE das Kontextfenster des LLaMA-Modells erheblich erweitern kann (mehr als 8k), ohne dass eine Feinabstimmung erforderlich ist und die Verwirrung nur minimal beeinträchtigt wird. Kürzlich wurde ein verwandter Artikel von ihm und drei weiteren Mitarbeitern veröffentlicht!
- Papier: https://arxiv.org/abs/2309.00071
- Modell: https://github.com/jquesnelle/yarn
In diesem Papier haben sie gemacht zwei Verbesserungen der NTK-fähigen Interpolation, die sich auf verschiedene Aspekte konzentrieren:
- Dynamische NTK-Interpolationsmethode, die für vorab trainierte Modelle ohne Feinabstimmung verwendet werden kann.
- Partielle NTK-Interpolationsmethode. Das Modell kann die beste Leistung erzielen, wenn es mit einer kleinen Menge längerer Kontextdaten feinabgestimmt wird.
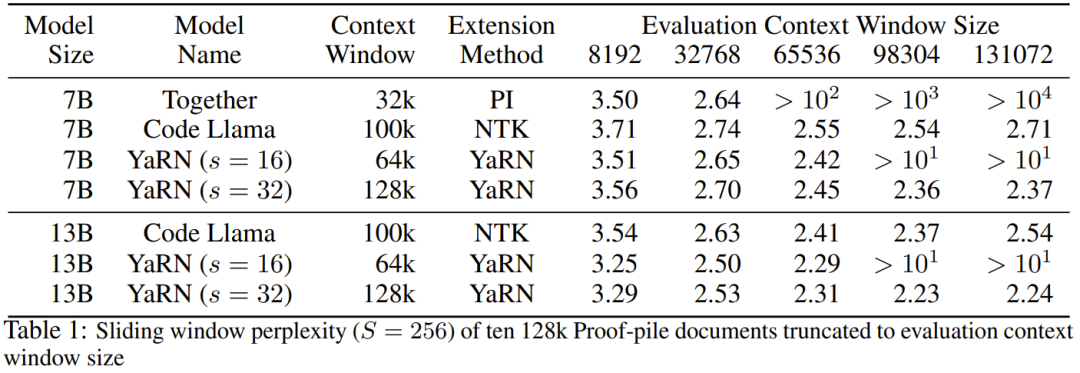
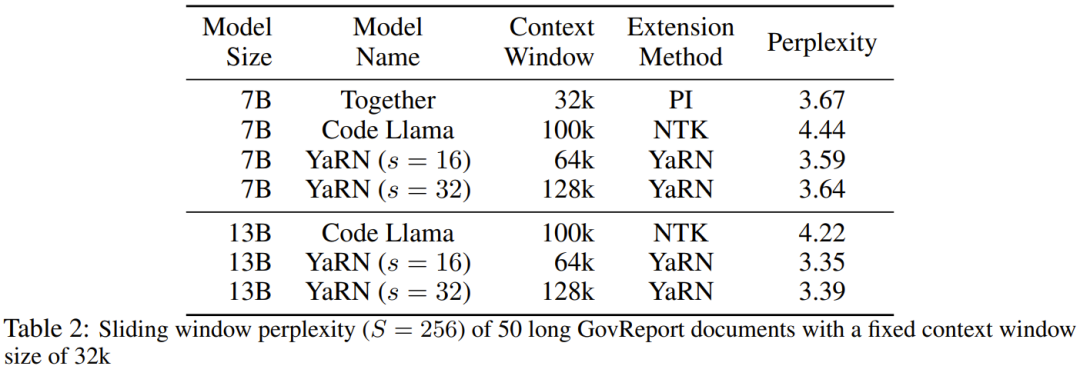
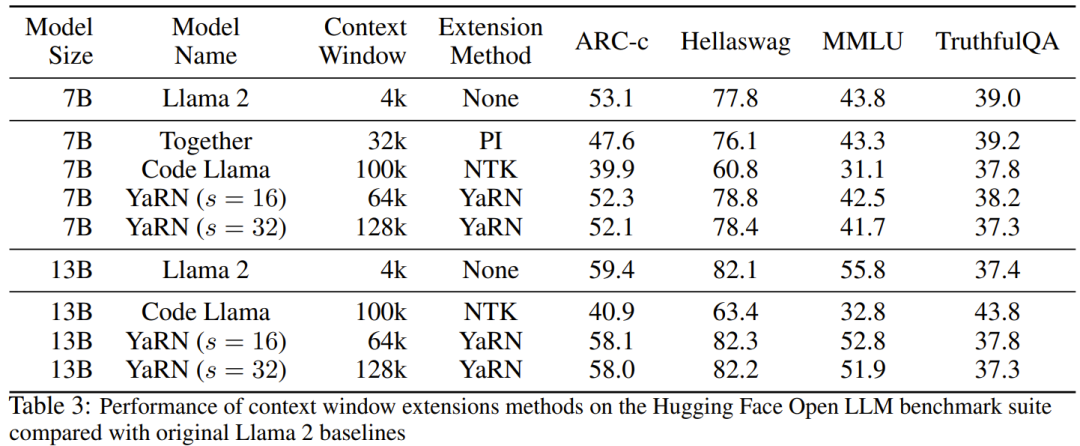
Der Forscher sagte, dass es vor der Geburt dieses Artikels bereits Forscher gab, die NTK-fähige Interpolation und dynamische NTK-Interpolation für einige Open-Source-Modelle verwendeten. Beispiele hierfür sind Code Llama (das NTK-fähige Interpolation verwendet) und Qwen 7B (das dynamische NTK-Interpolation verwendet). In diesem Artikel schlugen die Forscher basierend auf früheren Forschungsergebnissen zur NTK-fähigen Interpolation, dynamischen NTK-Interpolation und partiellen NTK-Interpolation YaRN (Yet another RoPE extensioN method) vor, eine Methode, die den Einsatz von Rotation effizient erweitern kann Die Kontextfenstermethode des Rotary Position Embeddings (RoPE)-Modells kann für Modelle der Serien LLaMA, GPT-NeoX und PaLM verwendet werden. Die Studie ergab, dass YaRN derzeit die beste Leistung bei der Erweiterung des Kontextfensters erzielen kann, indem für die Feinabstimmung nur repräsentative Stichproben verwendet werden, die etwa 0,1 % der Datengröße des ursprünglichen Modells vor dem Training ausmachen. Rotary Position Embeddings (RoPE) wurde erstmals durch den Artikel „RoFormer: Enhanced Transformer with Rotary Position Embedding“ eingeführt und ist auch die Grundlage von YaRN.Einfach ausgedrückt kann RoPE wie folgt geschrieben werden: Für vorab trainiertes LLM mit fester Kontextlänge kann die Verwendung von Positionsinterpolation (PI) zur Erweiterung der Kontextlänge wie folgt ausgedrückt werden: Es ist ersichtlich, dass PI alle RoPE-Dimensionen gleichermaßen erweitern wird. Die Forscher stellten fest, dass die im PI-Papier beschriebenen theoretischen Interpolationsgrenzen nicht ausreichten, um die komplexe Dynamik zwischen RoPE- und LLM-internen Einbettungen vorherzusagen. Im Folgenden werden die wichtigsten von Forschern entdeckten und gelösten PI-Probleme beschrieben, damit die Leser die Hintergründe, Ursachen und Gründe für die Lösung verschiedener neuer Methoden in YaRN verstehen können. Hochfrequenter Informationsverlust – NTK-bewusste Interpolation Wenn Sie RoPE nur aus der Perspektive der Informationskodierung betrachten, gemäß der Neural Tangent Kernel (NTK)-Theorie, wenn die Eingabedimension ist niedrig und der entsprechenden Einbettung fehlen Hochfrequenzkomponenten, dann ist es für tiefe neuronale Netze schwierig, Hochfrequenzinformationen zu lernen. Um das Problem des Verlusts von Hochfrequenzinformationen beim Einbetten der Interpolation für RoPE zu lösen, schlug Bowen Peng im obigen Reddit-Beitrag eine NTK-fähige Interpolation vor. Dieser Ansatz erweitert nicht jede Dimension des RoPE gleichermaßen, sondern verteilt den Interpolationsdruck auf mehrere Dimensionen, indem hohe Frequenzen weniger und niedrige Frequenzen stärker erweitert werden. In Tests stellten die Forscher fest, dass dieser Ansatz PI bei der Skalierung der Kontextgröße des Modells ohne Feinabstimmung übertraf. Dieser Ansatz hat jedoch einen großen Nachteil: Da es sich nicht nur um ein Interpolationsschema handelt, werden einige Dimensionen in einige „äußere“ Werte extrapoliert, sodass die Feinabstimmung mithilfe der NTK-fähigen Interpolation nicht so effektiv ist wie PI. Darüber hinaus kann der theoretische Erweiterungsfaktor aufgrund der Existenz „äußerer“ Werte den wahren Grad der Kontexterweiterung nicht genau beschreiben. In der Praxis muss für eine gegebene Kontextlängenerweiterung der Erweiterungswert s etwas höher als der erwartete Erweiterungswert eingestellt werden. Verlust des relativen lokalen Abstands – teilweise NTK-Interpolation Bei der RoPE-Einbettung gibt es eine interessante Beobachtung: Bei einer Kontextgröße L gibt es eine Dimension d, bei der die Wellenlänge λ länger als die Vorwellenlänge ist – Die größte während der Trainingsphase beobachtete Kontextlänge (λ > L), was darauf hinweist, dass Einbettungen bestimmter Dimensionen in der gedrehten Domäne ungleichmäßig verteilt sein können. PI- und NTK-fähige Interpolation behandelt alle verborgenen RoPE-Dimensionen gleich (als ob sie den gleichen Effekt auf das Netzwerk hätten). Aber Forscher haben durch Experimente herausgefunden, dass das Internet einige Dimensionen anders behandelt als andere Dimensionen. Wie bereits erwähnt, weisen einige Dimensionen bei gegebener Kontextlänge L Wellenlängen λ auf, die größer oder gleich L sind. Da alle Positionspaare einen bestimmten Abstand kodieren, wenn die Wellenlänge einer verborgenen Dimension größer oder gleich L ist, gehen die Forscher davon aus, dass die absoluten Positionsinformationen erhalten bleiben, wenn die Wellenlänge kürzer ist, und das Netzwerk nur die relative Position erhalten kann Position. Beim Strecken aller RoPE-Dimensionen mit der Erweiterungsskala s oder dem Basisänderungswert b' rücken alle Token näher zusammen, da das Skalarprodukt zweier Vektoren, die um einen kleineren Betrag gedreht werden, größer wird. Diese Erweiterung kann die Fähigkeit des LLM, kleine lokale Beziehungen zwischen seinen internen Einbettungen zu verstehen, erheblich beeinträchtigen. Die Forscher stellten die Hypothese auf, dass diese Komprimierung dazu führen würde, dass das Modell hinsichtlich der Positionsreihenfolge benachbarter Token verwirrt wird und dadurch die Fähigkeiten des Modells beeinträchtigt werden. Um dieses Problem zu lösen, haben sie sich aufgrund der von den Forschern beobachteten Phänomene entschieden, überhaupt keine höheren Frequenzdimensionen zu interpolieren. Sie schlugen außerdem vor, dass für alle Dimensionen d die Dimensionen von r β überhaupt nicht interpoliert (immer extrapoliert) werden. Mit der in diesem Abschnitt beschriebenen Technik wurde eine Methode namens partielle NTK-Interpolation geboren. Diese verbesserte Methode übertrifft frühere PI- und NTK-fähige Interpolationsmethoden und funktioniert sowohl bei nicht abgestimmten als auch bei fein abgestimmten Modellen. Da diese Methode die Extrapolation von Dimensionen vermeidet, bei denen die Rotationsdomäne ungleichmäßig verteilt ist, werden alle Feinabstimmungsprobleme früherer Methoden vermieden. Dynamische Skalierung – Dynamische NTK-Interpolation Bei der Skalierung der Kontextgröße ohne Feinabstimmung mit der RoPE-Interpolationsmethode erwarten wir, dass sich das Modell über längere Kontextgrößen langsam verschlechtert, anstatt Grad s zu skalieren über die gesamte Kontextgröße vollständig abgebaut, wenn sie den erforderlichen Wert überschreitet.Bei der dynamischen NTK-Methode wird die Erweiterung s dynamisch berechnet. Während des Inferenzprozesses, wenn die Kontextgröße überschritten wird, wird der Erweiterungsgrad s dynamisch geändert, was es allen Modellen ermöglicht, sich langsam zu verschlechtern, wenn sie die Trainingskontextgrenze L erreichen, anstatt plötzlich abzustürzen. Erhöhen Sie die durchschnittliche minimale Kosinusähnlichkeit für große Entfernungen – YaRN Auch wenn das zuvor beschriebene lokale Entfernungsproblem gelöst ist, muss zur Vermeidung einer Extrapolation eine größere Interpolation am Schwellenwert α durchgeführt werden . Intuitiv scheint dies kein Problem zu sein, da die globale Distanz keine hohe Genauigkeit zur Unterscheidung der Token-Positionen erfordert (d. h. das Netzwerk muss nur ungefähr wissen, ob sich der Token am Anfang, in der Mitte oder am Ende der Sequenz befindet). Die Forscher fanden jedoch heraus, dass die Aufmerksamkeits-Softmax-Verteilung spitzer wird (d. h. die durchschnittliche Entropie des Aufmerksamkeits-Softmax verringert), da der durchschnittliche Mindestabstand mit zunehmender Anzahl von Token enger wird. Mit anderen Worten: Da die Auswirkung der Langstreckendämpfung durch Interpolation verringert wird, „schenkt“ das Netzwerk mehr Token „mehr Aufmerksamkeit“. Diese Verteilungsverschiebung kann zu einer Verschlechterung der Qualität der LLM-Ergebnisse führen, was ein weiteres Problem ist, das nichts mit der vorherigen Frage zu tun hat. Da die Entropie in der Aufmerksamkeits-Softmax-Verteilung abnimmt, wenn RoPE-Einbettungen auf längere Kontextgrößen interpoliert werden, wollen wir diese Entropieabnahme umkehren (d. h. die „Temperatur“ des Aufmerksamkeits-Logits erhöhen). Dies kann durch Multiplizieren der Zwischenaufmerksamkeitsmatrix mit der Temperatur t > 1 vor der Anwendung von Softmax erreicht werden. Da die RoPE-Einbettung jedoch als Rotationsmatrix codiert ist, ist es möglich, die Länge der RoPE-Einbettung einfach um einen konstanten Faktor √t zu verlängern . Diese Technik der „Längenerweiterung“ ermöglicht Forschung ohne Änderung des Aufmerksamkeitscodes, was die Integration in bestehende Trainings- und Inferenzpipelines erheblich vereinfacht und eine zeitliche Komplexität von nur O(1) aufweist. Da dieses RoPE-Interpolationsschema ungleichmäßig über die RoPE-Dimensionen interpoliert, ist es schwierig, eine analytische Lösung für die erforderliche Temperaturskala t in Bezug auf den Ausdehnungsgrad s zu berechnen. Glücklicherweise haben die Forscher durch Experimente herausgefunden, dass durch die Minimierung der Verwirrung alle LLaMA-Modelle ungefähr derselben Anpassungskurve folgen: Die Forscher entdeckten diese Formel für LLaMA 7B, 13B, 33B und 65B. Sie fanden heraus, dass diese Formel mit geringfügigen Unterschieden auch für die LLaMA 2-Modelle (7B, 13B und 70B) gut funktionierte. Dies legt nahe, dass diese entropieerhöhende Eigenschaft häufig vorkommt und sich auf verschiedene Modelle und Trainingsdaten übertragen lässt. Diese letzte Änderung führte zur YaRN-Methode. Die neue Methode übertrifft alle bisherigen Methoden sowohl in fein abgestimmten als auch in nicht abgestimmten Szenarien, ohne dass Änderungen am Inferenzcode erforderlich sind. Lediglich der Algorithmus, der ursprünglich zum Generieren von RoPE-Einbettungen verwendet wurde, muss geändert werden. YaRN ist so einfach, dass es problemlos in allen Inferenz- und Trainingsbibliotheken implementiert werden kann, einschließlich der Kompatibilität mit Flash Attention 2. Das Experiment zeigt, dass YaRN das Kontextfenster von LLM erfolgreich erweitern kann. Darüber hinaus erzielten sie dieses Ergebnis nach einem Training von nur 400 Schritten, was etwa 0,1 % des ursprünglichen Korpus des Modells vor dem Training und einen deutlichen Rückgang gegenüber früheren Arbeiten entspricht. Dies zeigt, dass die neue Methode sehr recheneffizient ist und keine zusätzlichen Inferenzkosten verursacht. Um das resultierende Modell zu bewerten, berechneten die Forscher die Verwirrung langer Dokumente und bewerteten sie anhand vorhandener Benchmarks. Dabei stellten sie fest, dass die neue Methode alle anderen Methoden zur Kontextfenstererweiterung übertraf. Zuerst bewerteten die Forscher die Leistung des Modells bei Vergrößerung des Kontextfensters. Tabelle 1 fasst die experimentellen Ergebnisse zusammen. Tabelle 2 zeigt die endgültige Verwirrung über 50 unzensierte GovReport-Dokumente (mindestens 16.000 Token lang). Um die Verschlechterung der Modellleistung bei der Verwendung von Kontexterweiterungen zu testen, bewerteten die Forscher das Modell mithilfe der Hugging Face Open LLM Leaderboard-Suite und verglichen es mit dem LLaMA 2-Basismodell und den öffentlich verfügbaren PI- und NTK-fähigen Modellen. Es werden Punkte verglichen. Tabelle 3 fasst die experimentellen Ergebnisse zusammen. Das obige ist der detaillierte Inhalt vonWenn Sie möchten, dass das große Modell mehr Beispiele in der Eingabeaufforderung lernt, können Sie mit dieser Methode mehr Zeichen eingeben. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!