
Heim >Technologie-Peripheriegeräte >KI >Wird für die selbstüberwachte SOTA-Vorschulung von LIDAR-Punktwolken verwendet!
Wird für die selbstüberwachte SOTA-Vorschulung von LIDAR-Punktwolken verwendet!

- 王林nach vorne
- 2023-09-15 09:53:071476Durchsuche

Thesis-Idee:
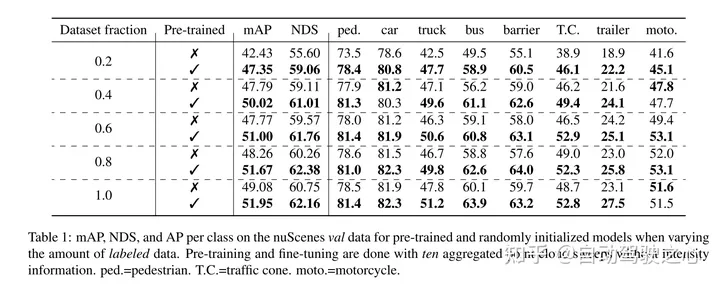
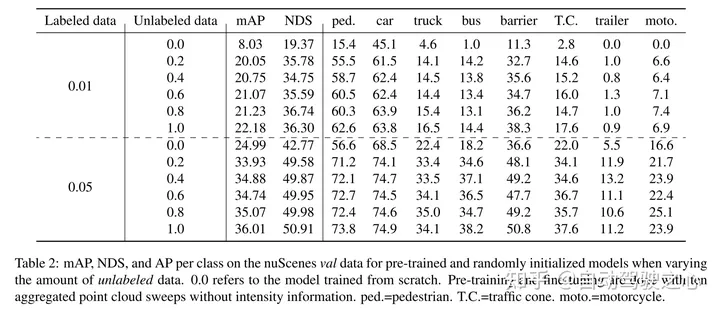
maskierte automatische Kodierung ist zu einem erfolgreichen Pre-Training-Paradigma für Transformer-Modelle von Text, Bildern und seit neuestem Punktwolken geworden. Rohe Fahrzeugdatensätze eignen sich für das selbstüberwachte Vortraining, da ihre Erfassung im Allgemeinen kostengünstiger ist als die Annotation für Aufgaben wie die 3D-Objekterkennung (OD). Die Entwicklung maskierter Autoencoder für Punktwolken konzentrierte sich jedoch nur auf synthetische und Indoor-Daten. Daher haben bestehende Methoden ihre Darstellungen und Modelle auf kleine und dichte Punktwolken mit gleichmäßiger Punktdichte zugeschnitten. In dieser Arbeit untersuchen wir die maskierte Autokodierung an Punktwolken in Automobilumgebungen, die dünn besiedelt sind und deren Dichte zwischen verschiedenen Objekten in derselben Szene erheblich variieren kann. Zu diesem Zweck schlägt dieser Artikel Voxel-MAE vor, ein einfaches maskiertes Autoencoding-Vortrainingsschema, das für die Voxeldarstellung entwickelt wurde. In diesem Artikel wird ein Transformer-basiertes 3D-Objektdetektor-Backbone vorab trainiert, um maskierte Voxel zu rekonstruieren und leere Voxel von nicht leeren Voxeln zu unterscheiden. Unsere Methode verbessert die 3D-OD-Leistung um 1,75 mAP und 1,05 NDS für den anspruchsvollen nuScenes-Datensatz. Darüber hinaus zeigen wir, dass wir durch die Verwendung von Voxel-MAE für das Vortraining nur 40 % annotierte Daten benötigen, um die entsprechenden Daten mit zufälliger Initialisierung zu übertreffen.
Hauptbeiträge:
Dieses Papier schlägt Voxel-MAE vor (eine Methode zur Bereitstellung eines selbstüberwachten Vortrainings im MAE-Stil auf voxelisierten Punktwolken) und führt es auf dem großen Automobil-Punktwolkendatensatz nuScenes durch . Die Methode in diesem Artikel ist das erste selbstüberwachte Vortrainingsschema, das das Automotive-Punktwolken-Transformer-Backbone verwendet.
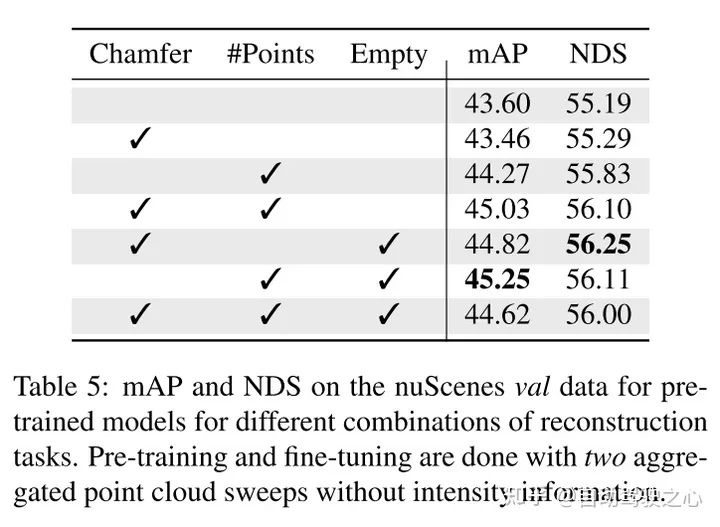
Dieser Artikel passt unsere Methode zur Voxeldarstellung an und verwendet einen einzigartigen Satz von Rekonstruktionsaufgaben, um die Eigenschaften voxelisierter Punktwolken zu erfassen.
Dieser Artikel beweist, dass unsere Methode dateneffizient ist und den Bedarf an annotierten Daten reduziert. Mit Vortraining übertrifft dieses Papier vollständig überwachte Daten, wenn nur 40 % der annotierten Daten verwendet werden.
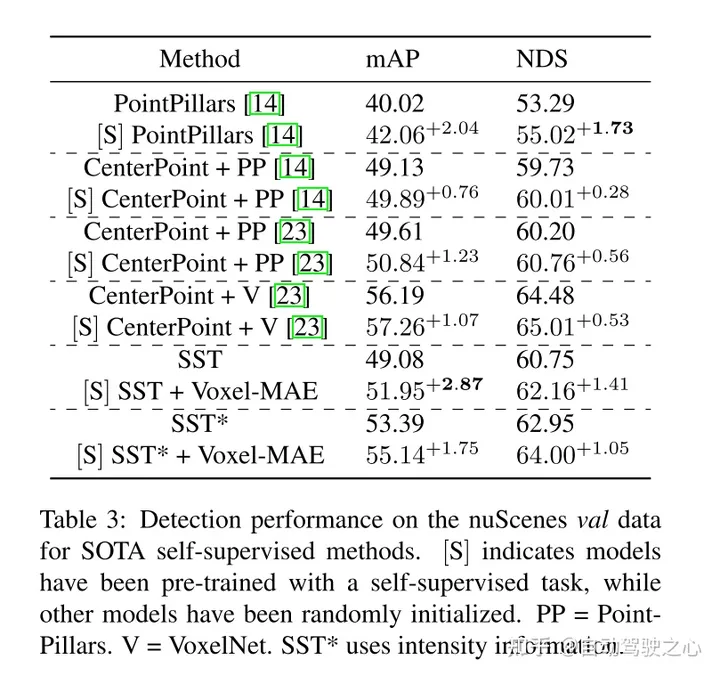
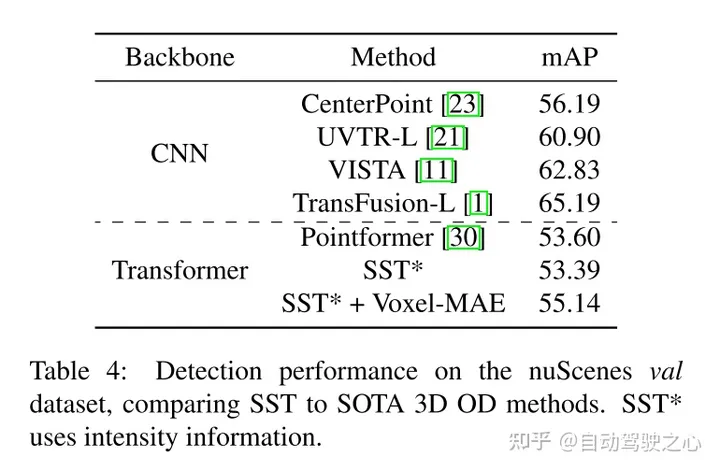
Darüber hinaus stellt dieses Papier fest, dass Voxel-MAE die Leistung transformatorbasierter Detektoren um 1,75 Prozentpunkte bei mAP und 1,05 Prozentpunkte bei NDS verbessert und damit die Leistung im Vergleich zu bestehenden selbstüberwachten Methoden um das Zweifache verbessert.
Netzwerkdesign:
Der Zweck dieser Arbeit besteht darin, das Vortraining im MAE-Stil auf voxelisierte Punktwolken auszudehnen. Die Kernidee besteht immer noch darin, einen Encoder zu verwenden, um aus Teilbeobachtungen der Eingabe eine reichhaltige latente Darstellung zu erstellen, und dann einen Decoder zu verwenden, um die ursprüngliche Eingabe zu rekonstruieren, wie in Abbildung 2 dargestellt. Nach dem Vortraining wird der Encoder als Rückgrat des 3D-Objektdetektors verwendet. Aufgrund grundlegender Unterschiede zwischen Bildern und Punktwolken sind jedoch einige Modifikationen für ein effizientes Training von Voxel-MAE erforderlich.
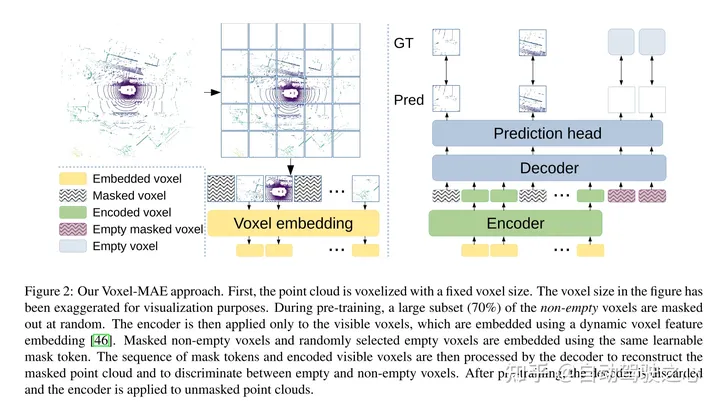
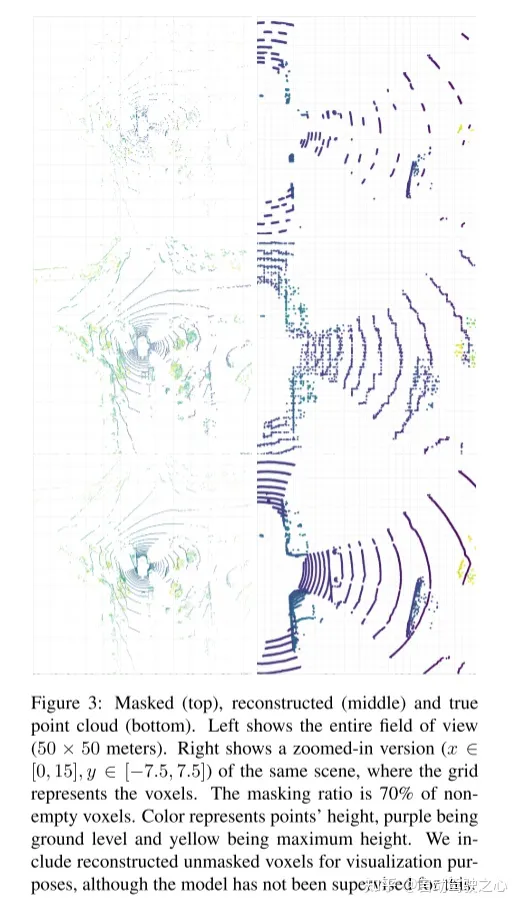
Abbildung 2: Voxel-MAE-Methode dieses Artikels. Zunächst wird die Punktwolke mit einer festen Voxelgröße voxelisiert. Die Voxelgrößen in den Abbildungen wurden zur Visualisierung übertrieben dargestellt. Vor dem Training wird ein großer Teil (70 %) der nicht leeren Voxel zufällig maskiert. Der Encoder wird dann nur auf sichtbare Voxel angewendet und diese Voxel mithilfe der dynamischen Einbettung von Voxelmerkmalen eingebettet [46]. Maskierte nicht leere Voxel und zufällig ausgewählte leere Voxel werden mithilfe derselben lernbaren Maskentokens eingebettet. Der Decoder verarbeitet dann die Sequenz der Masken-Tokens und die codierte Sequenz sichtbarer Voxel, um die maskierte Punktwolke zu rekonstruieren und leere Voxel von nicht leeren Voxeln zu unterscheiden. Nach dem Vortraining wird der Decoder verworfen und der Encoder auf die unmaskierte Punktwolke angewendet.

Abbildung 1: MAE (links) unterteilt das Bild in nicht überlappende Patches fester Größe. Bestehende maskierte Punktmodellierungsmethoden (Mitte) erstellen eine feste Anzahl von Punktwolkenfeldern, indem sie die Stichprobenentnahme am weitesten entfernten Punkt und k-nächste Nachbarn verwenden. Unsere Methode (rechts) verwendet nicht überlappende Voxel und eine dynamische Anzahl von Punkten.
Experimentelle Ergebnisse:
引用:
Hess G, Jaxing J, Svensson E, et al. Maskierter Autoencoder für selbstüberwachtes Vortraining auf Lidar-Punktwolken[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2023: 350-359.
Das obige ist der detaillierte Inhalt vonWird für die selbstüberwachte SOTA-Vorschulung von LIDAR-Punktwolken verwendet!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!