
Heim >Technologie-Peripheriegeräte >KI >Das Bild stimmt nicht mit dem Code überein. Im Transformer-Papier wurde ein Fehler gefunden: Es hätte 1.000 Mal darauf hingewiesen werden sollen.
Das Bild stimmt nicht mit dem Code überein. Im Transformer-Papier wurde ein Fehler gefunden: Es hätte 1.000 Mal darauf hingewiesen werden sollen.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-25 15:01:06935Durchsuche
Im Jahr 2017 hat das Google Brain-Team die Transformer-Architektur in seinem Artikel „Attention Is All You Need“ kreativ vorgeschlagen. Seitdem ist diese Forschung bahnbrechend und hat sich heute zu einem der beliebtesten Modelle im Bereich NLP entwickelt Es wurde häufig auf verschiedene Sprachaufgaben angewendet und erzielte viele SOTA-Ergebnisse.
Darüber hinaus hat Transformer, das im Bereich NLP eine Vorreiterrolle spielt, schnell Bereiche wie Computer Vision (CV) und Spracherkennung durchschritten und bei Aufgaben wie Bildklassifizierung und Zielerkennung gute Ergebnisse erzielt und Spracherkennung.

Papieradresse: https://arxiv.org/pdf/1706.03762.pdf
Seit seiner Einführung ist Transformer zum Kernmodul vieler Modelle geworden, wie z Bekannte BERT, T5 usw. haben alle Transformatoren. Sogar das in letzter Zeit populär gewordene ChatGPT setzt auf Transformer, das bereits von Google patentiert wurde.

Bildquelle: https://patentimages.storage.googleapis.com/05/e8/f1/cd8eed389b7687/US10452978.pdf
Darüber hinaus hat OpenAI eine Reihe veröffentlicht Beim Modell GPT (Generative Pre-Trained Transformer) mit Transformer im Namen ist ersichtlich, dass Transformer der Kern des GPT-Serienmodells ist.
Gleichzeitig sagte OpenAI-Mitbegründer Ilya Stutskever kürzlich, als er über Transformer sprach, dass die Erstveröffentlichung von Transformer tatsächlich am zweiten Tag nach der Veröffentlichung des Papiers erfolgte und sie es kaum erwarten konnten, ihre vorherige Version zu wechseln Forschung zu Transformer. Transformer, gefolgt von GPT. Es ist ersichtlich, dass die Bedeutung von Transformer offensichtlich ist.
In 6 Jahren hat sich das auf Transformer basierende Modell immer weiter entwickelt und ist gewachsen. Jetzt hat jedoch jemand einen Fehler im ursprünglichen Transformer-Papier entdeckt.
Transformer-Architekturdiagramm und Code sind „inkonsistent“
Die Person, die den Fehler entdeckte, war Sebastian Raschka, ein bekannter Forscher für maschinelles Lernen und KI und Chef-KI-Ausbilder des Startups Lightning AI. Er wies darauf hin, dass das Architekturdiagramm im ursprünglichen Transformer-Papier falsch sei und eine Layer-Normalisierung (LN) zwischen Restblöcken platziert habe, was nicht mit dem Code übereinstimme.
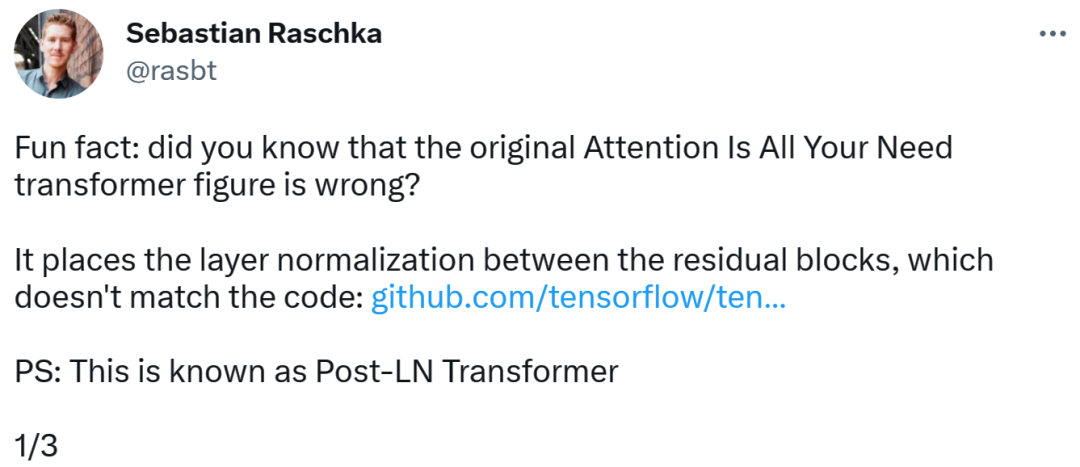
Das Diagramm der Transformatorarchitektur sieht wie folgt auf der linken Seite aus, und auf der rechten Seite befindet sich die Post-LN-Transformatorschicht (aus dem Artikel „On Layer Normalization in the Transformer Architecture“ [1]).
Der inkonsistente Codeteil lautet wie folgt: Zeile 82 schreibt die Ausführungssequenz „layer_postprocess_sequence="dan"", was bedeutet, dass die Nachverarbeitung Dropout, Residual_Add und Layer_norm nacheinander ausführt. Wenn add&norm in der linken Mitte des obigen Bildes so verstanden wird: add liegt über der Norm, also zuerst normieren und dann addieren, dann stimmt der Code tatsächlich nicht mit dem Bild überein.
Code-Adresse:
https://github.com/tensorflow/tensor2tensor/commit/f5c9b17e617ea9179b7d84d36b1e8162cb369f25#diff-76e2b94ef1 68 71bdbf46bf04dfe7f1477bafb884748f08197c9cf1b10a4dd78e…
Als nächstes sagte Sebastian, dass das Papier „On Layer „Normalisierung in der Transformatorarchitektur“ geht davon aus, dass Pre-LN eine bessere Leistung erbringt und das Gradientenproblem lösen kann. Dies ist bei vielen oder den meisten Architekturen in der Praxis der Fall, kann jedoch zum Zusammenbruch der Darstellung führen.
Bessere Farbverläufe können erreicht werden, wenn die Ebenennormalisierung in der Restverbindung vor den Aufmerksamkeits- und vollständig verbundenen Ebenen platziert wird.
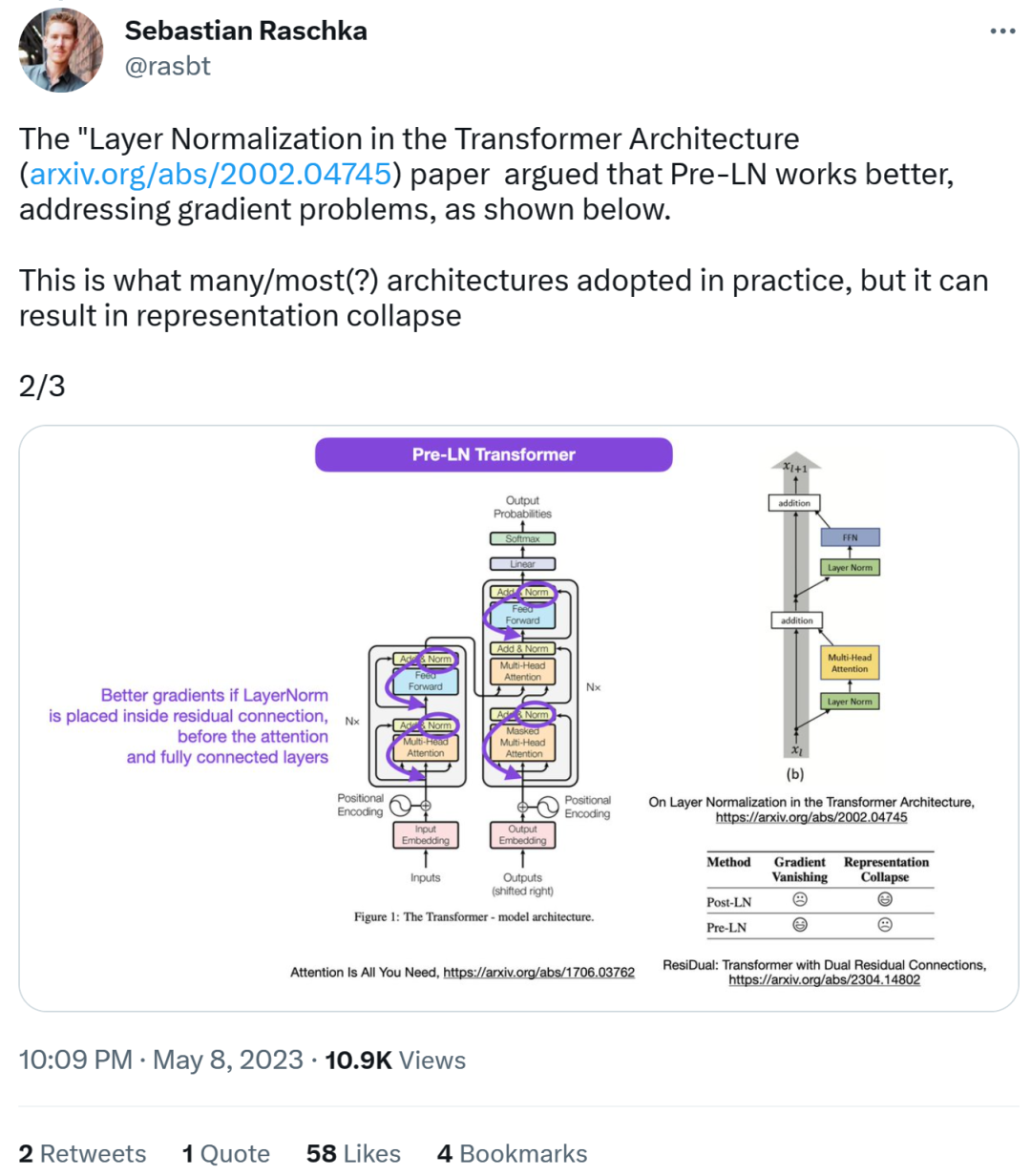
Während also die Debatte über Post-LN oder Pre-LN weitergeht, kombiniert ein anderer Artikel diese beiden Punkte, nämlich „ResiDual: Transformer with Dual Residual Connections“ [2] .
In Bezug auf Sebastians Entdeckung denken einige Leute, dass wir oft auf Papiere stoßen, die nicht mit dem Code oder den Ergebnissen übereinstimmen. Das meiste davon ist ehrlich, aber manchmal ist es seltsam. Angesichts der Popularität des Transformer-Papiers hätte diese Inkonsistenz tausendfach erwähnt werden müssen.
Sebastian antwortete, dass der „originellste“ Code zwar fairerweise mit dem Architekturdiagramm übereinstimmt, die 2017 eingereichte Codeversion jedoch geändert und das Architekturdiagramm nicht aktualisiert wurde. Das ist also wirklich verwirrend.
Ein Internetnutzer sagte: „Das Schlimmste am Lesen von Code ist, dass man oft kleine Änderungen wie diese findet und nicht weiß, ob sie beabsichtigt oder unbeabsichtigt sind. Sie können' Ich teste es nicht einmal, weil Sie nicht genug Rechenleistung haben, um das Modell zu trainieren.“
Ich weiß nicht, ob Google den Code oder das Architekturdiagramm in Zukunft aktualisieren wird, wir werden abwarten und sehen!
Das obige ist der detaillierte Inhalt vonDas Bild stimmt nicht mit dem Code überein. Im Transformer-Papier wurde ein Fehler gefunden: Es hätte 1.000 Mal darauf hingewiesen werden sollen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr