
Heim >Technologie-Peripheriegeräte >KI >Erstellen Sie Ihre eigenen Tools für große Modelle wie GPT-4, um ChatGPT-Betrug zu erkennen
Erstellen Sie Ihre eigenen Tools für große Modelle wie GPT-4, um ChatGPT-Betrug zu erkennen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-05 16:03:401824Durchsuche
Inhaltsverzeichnis:
- Multiskalige positiv-unbeschriftete Erkennung von KI-generierten Texten
- Auf dem Weg zur Enthüllung des Geheimnisses hinter Chain of Thought: eine theoretische Perspektive
- Große Sprachmodelle als Werkzeugmacher
- SpecInfer: Beschleunigung der generativen LLM-Bereitstellung mit spekulativer Inferenz und Token-Baum-Verifizierung Bild und Video: Wo geht es als nächstes mit Empfehlungssystemen weiter? Autor: Yuchuan Tian, Hanting Chen usw.
- Papieradresse: https://arxiv.org/abs/2305.18149
- Zusammenfassung:
- Empfohlen: Identifizieren Sie „ChatGPT-Betrug“, der Effekt übertrifft OpenAI: Die von der Peking-Universität und Huawei generierten KI-Detektoren sind hier
- Papier 2: Auf dem Weg zur Enthüllung des Geheimnisses hinter der Gedankenkette: eine theoretische Perspektive
Autor: Guhao Feng, Bohang Zhang usw.
Papieradresse: https://arxiv.org/ abs /2305.15408
Zusammenfassung:
Chain of Thought Tips (CoT) ist eines der mysteriösesten Phänomene bei der Entstehung großer Modelle, insbesondere bei der Lösung mathematischer Argumentations- und Entscheidungsprobleme. Es hat erstaunliche Ergebnisse erzielt. Wie wichtig ist CoT? Was ist der Mechanismus hinter seinem Erfolg? In diesem Artikel beweisen mehrere Forscher der Peking-Universität, dass CoT für die Realisierung von LLM-Inferenzen (Large Language Model) unverzichtbar ist, und zeigen, wie CoT das enorme Potenzial von LLM aus theoretischer und experimenteller Sicht erschließt.In diesem Artikel werden zwei sehr grundlegende, aber zentrale Mathematikaufgaben ausgewählt: Arithmetik und Gleichungen (die folgende Abbildung zeigt Beispiele für die Eingabe und Ausgabe dieser beiden Aufgaben)
- Empfohlen: Thinking Chain How to die verborgene Kraft von Sprachmodellen erschließen? Die neueste theoretische Forschung enthüllt das Geheimnis dahinter
Autoren: Tianle Cai, Xuezhi Wang usw.
 Aufsatzadresse: https ://arxiv.org/pdf/2305.17126.pdf
Aufsatzadresse: https ://arxiv.org/pdf/2305.17126.pdf
Zusammenfassung:
Inspiriert von der Bedeutung der Herstellung von Werkzeugen für den Menschen haben Forscher von Google Deepmind, Princeton und der Stanford University in diesem Artikel das Konzept von „ „Evolution“ ins rechte Licht gerückt Auf den Bereich LLM übertragen, wurden Vorerkundungen durchgeführt. Sie schlagen ein Closed-Loop-Framework vor, in dem LLMs As Tool Makers (LATM) es ihnen ermöglichen, ihre eigenen wiederverwendbaren Werkzeuge zu generieren, um neue Aufgaben zu bewältigen.
- Papier 5: Günstig und schnell: Effiziente Vision-Language-Anweisungsoptimierung für große Sprachmodelle usw. # 🎜🎜#
- Zusammenfassung: Dieses Papier schlägt eine neuartige und erschwingliche Lösung für die effiziente Anpassung von LLMs an VL-Aufgaben (Visual Language) vor. Sie heißt MMA. Anstatt große neuronale Netze zu verwenden, um Bildencoder und LLMs zu verbinden, verwendet MMA leichtgewichtige Module, sogenannte Adapter, um die Lücke zwischen LLMs und VL-Aufgaben zu schließen und gleichzeitig eine gemeinsame Optimierung von Bildmodellen und Sprachmodellen zu ermöglichen. Gleichzeitig ist MMA auch mit einem Routing-Algorithmus ausgestattet, der LLM dabei helfen kann, automatisch zwischen monomodalen und multimodalen Anweisungen zu wechseln, ohne seine Fähigkeiten zum Verstehen natürlicher Sprache zu beeinträchtigen.
-
Empfohlen: ICML 2023 |. Basierend auf der modularen Idee schlug die Alibaba Damo Academy das multimodale Basismodell mPLUG-2 vor. basierte Recommender Models Revisited
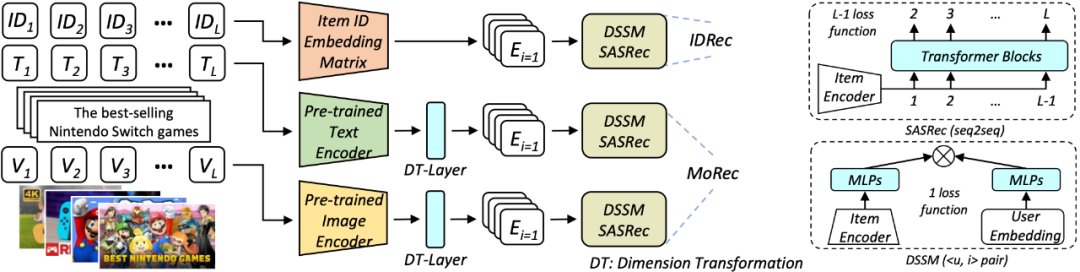
Autoren: Zheng Yuan, Fajie Yuan usw.
- Papieradresse: https://arxiv.org/abs/2303.13835
- Zusammenfassung: Umfrage zu diesem Artikel Es wird eine potenzielle Frage aufgeworfen, nämlich ob das multimodale Empfehlungssystem MoRec voraussichtlich die 10-jährige Dominanz von IDRec im Bereich der Empfehlungssysteme beenden wird. Auf dieser Grundlage führt das Papier eine eingehende Untersuchung durch. Entsprechende Ergebnisse wurden von SIGIR 2023 akzeptiert. Die folgende Abbildung zeigt die Netzwerkarchitektur.
SIGIR 2023 | Wo wird das klassische ID-Paradigma untergraben? Empfohlen:
Empfohlen:
Empfehlung: GPT-4 und andere große Modelle haben einen evolutionären Wendepunkt erreicht: Sie nutzen sie nicht nur, sondern stellen auch ihre eigenen Werkzeuge her #🎜🎜 ##🎜🏜 🎜🎜## 🎜🎜#Autoren: org/abs/2305.09781# 🎜🎜#
Zusammenfassung:
Vor kurzem hat das Catalyst Group-Team von der Carnegie Mellon University ( CMU hat einen SpecInfer veröffentlicht, eine Engine für „spekulatives Denken“, die leichte kleine Modelle verwenden kann, um große Modelle zu unterstützen, und dabei die zwei- bis dreifache Inferenzbeschleunigung erreicht, ohne die Genauigkeit des generierten Inhalts überhaupt zu beeinträchtigen. #🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#Empfohlen:- LLM Argumentation Geschwindigkeit Absolventen der CMU Tsinghua Yao-Klasse haben die Engine „Spekulatives Denken“ SpecInfer um das 2,8-fache vorgeschlagen. Kleine Modelle nutzen große Modelle für effizientes Denken
Empfohlen:
Trainingszeit verkürzt um 71,4 %, Einsparung von 99,9 % der Speicherkosten. Mit der neuen Lösung zur Unterrichtsoptimierung MMA kann das Alpaka-Modell Multimodalität erreichen -2: Ein modularisiertes multimodales Grundlagenmodell für Text, Bild und Video 🎜🎜#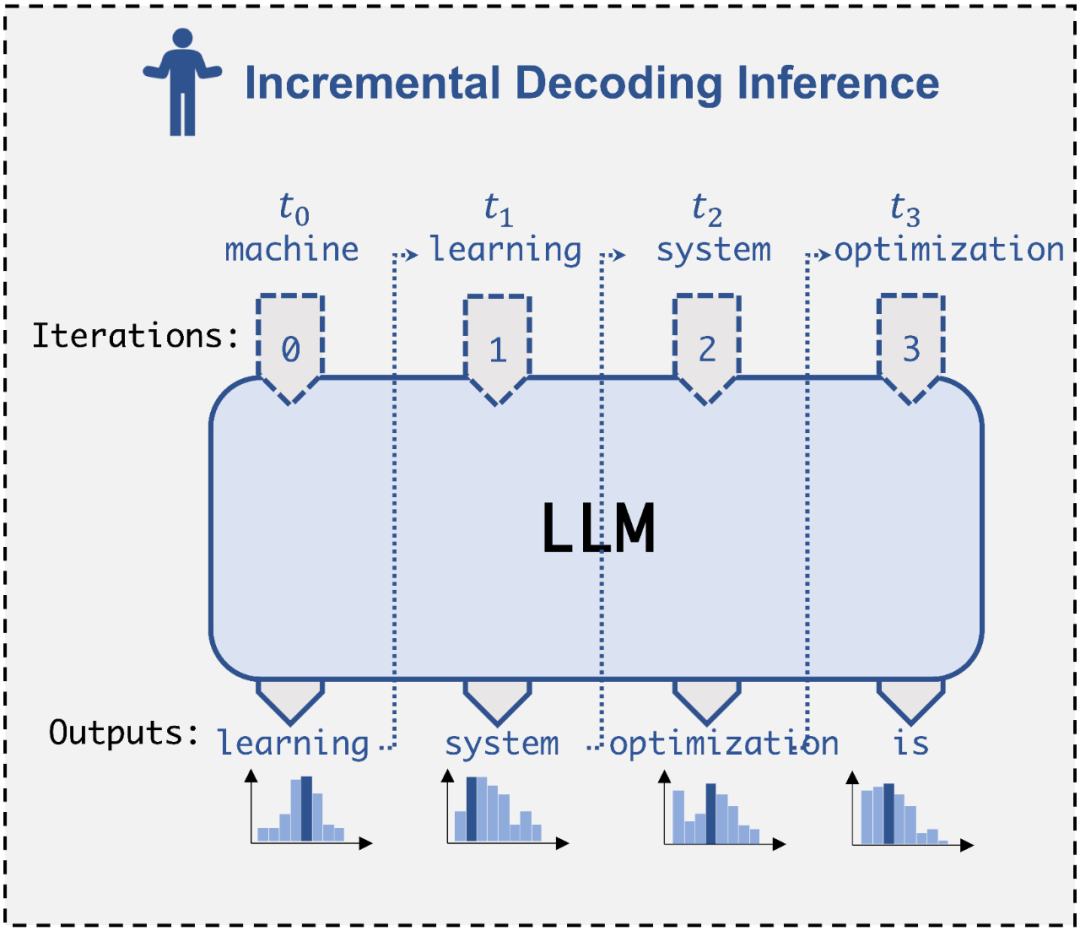
Papieradresse: https://arxiv.org/ pdf/2302.00402.pdf#🎜🎜 #
Zusammenfassung: Für das multimodale Basismodell hoffen wir, dass dies möglich ist Bewältigt nicht nur spezifische multimodale Aufgaben, sondern auch einzelne Modalitäten. Es weist auch eine hervorragende Leistung bei dynamischen Aufgaben auf. Das Team der Aidamo Academy stellte fest, dass bestehende Modelle die Probleme der modalen Zusammenarbeit und modalen Verflechtung oft nicht gut in Einklang bringen können, was die Leistung des Modells bei verschiedenen nachgelagerten einmodalen und modalübergreifenden Aufgaben einschränkt.
- Auf dieser Grundlage schlugen Forscher der DAMO Academy mPLUG-2 vor, das ein modulares Netzwerkstrukturdesign verwendet, um die Zusammenarbeit und Koordination zwischen mehreren Modi in Bezug auf das Verschränkungsproblem auszugleichen mPLUG-2 erreicht SOTA- oder vergleichbare Ergebnisse mit dem gleichen Datenvolumen und der gleichen Modellgröße in über 30 multi-/einzelmodalen Aufgaben und übertrifft sehr große Modelle wie Flamingo, VideoCoca und GITv2 in VideoQA und VideoCaption, um absolute SOTA zu erreichen. Darüber hinaus ist mPLUG-Owl das neueste Werk der mPLUG-Reihe der Alibaba Damo Academy. Es führt den modularen Trainingsgedanken der mPLUG-Reihe fort und erweitert LLM zu einem multimodalen Großmodell. Die Forschungsarbeit von mPLUG-2 wurde vom ICML 2023 angenommen.
 Empfohlen:
Empfohlen: Das obige ist der detaillierte Inhalt vonErstellen Sie Ihre eigenen Tools für große Modelle wie GPT-4, um ChatGPT-Betrug zu erkennen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr