
Heim >Technologie-Peripheriegeräte >KI >Ist das „RL' in RLHF erforderlich? Einige Leute verwenden binäre Kreuzentropie, um LLM direkt zu optimieren, und der Effekt ist besser.
Ist das „RL' in RLHF erforderlich? Einige Leute verwenden binäre Kreuzentropie, um LLM direkt zu optimieren, und der Effekt ist besser.

- 王林nach vorne
- 2023-06-05 16:03:33837Durchsuche
Vor kurzem haben unbeaufsichtigte Sprachmodelle, die auf großen Datensätzen trainiert wurden, überraschende Fähigkeiten erreicht. Diese Modelle werden jedoch auf Daten trainiert, die von Menschen mit unterschiedlichen Zielen, Prioritäten und Fähigkeiten generiert werden, von denen einige nicht unbedingt nachgeahmt werden können.
Die Auswahl der gewünschten Reaktionen und Verhaltensweisen eines Modells aus seinem sehr breiten Wissen und seinen Fähigkeiten ist entscheidend für den Aufbau sicherer, leistungsstarker und kontrollierbarer KI-Systeme. Viele bestehende Methoden vermitteln gewünschte Verhaltensweisen in Sprachmodelle, indem sie sorgfältig kuratierte menschliche Präferenzsätze verwenden, die die Verhaltensweisen darstellen, die Menschen als sicher und vorteilhaft erachten. Diese Präferenzlernphase findet nach einer anfänglichen Phase umfangreicher unbeaufsichtigter Datensätze statt -Ausbildung.
Während die einfachste Methode des Präferenzlernens die überwachte Feinabstimmung hochwertiger, von Menschen demonstrierter Antworten ist, ist das verstärkende Lernen aus menschlichem (oder künstlichem Intelligenz-)Feedback (RLHF/RLAIF) in letzter Zeit eine relativ beliebte Methodenklasse. Die RLHF-Methode ordnet ein Belohnungsmodell einem Datensatz menschlicher Präferenzen zu und optimiert dann mithilfe von RL eine Sprachmodellrichtlinie, um Antworten zu erzeugen, die hohe Belohnungen zuweisen, ohne übermäßig vom ursprünglichen Modell abzuweichen.
Während RLHF Modelle mit beeindruckenden Konversations- und Codierungsfähigkeiten produziert, ist die RLHF-Pipeline viel komplexer als überwachtes Lernen, da sie das Training mehrerer Sprachmodelle und das Sampling aus Sprachmodellrichtlinien in einer trainierten Schleife erfordert, was einen hohen Rechenaufwand verursacht.
Und eine aktuelle Studie zeigt, dass: Das von vorhandenen Methoden verwendete RL-basierte Ziel kann mit einem einfachen binären Kreuzentropieziel genau optimiert werden, wodurch die Präferenzlernpipeline erheblich vereinfacht wird. Das heißt, es ist durchaus möglich, Sprachmodelle direkt zu optimieren, um den menschlichen Vorlieben zu entsprechen, ohne dass explizite Belohnungsmodelle oder verstärkendes Lernen erforderlich sind.

Link zum Papier: https://arxiv.org/pdf/2305.18290.pdf
Forscher der Stanford University und anderer Institutionen haben diesen Algorithmus (Direct Preference Optimization, DPO) vorgeschlagen Optimiert implizit das gleiche Ziel wie der bestehende RLHF-Algorithmus (Belohnungsmaximierung mit KL – Divergenzbeschränkungen), ist jedoch einfach zu implementieren und direkt trainierbar.
Experimente zeigen, dass DPO mindestens so effektiv ist wie bestehende Methoden, einschließlich PPO-basiertes RLHF, wenn es für Präferenzlernaufgaben wie Stimmungsregulierung, Zusammenfassung und Dialog mit 6 Milliarden Parameter-Sprachmodellen verwendet wird.
DPO-Algorithmus
Wie bestehende Algorithmen stützt sich DPO auch auf theoretische Präferenzmodelle (wie das Bradley-Terry-Modell), um zu messen, wie gut eine bestimmte Belohnungsfunktion mit empirischen Präferenzdaten übereinstimmt. Bestehende Methoden verwenden jedoch ein Präferenzmodell, um einen Präferenzverlust zu definieren, um ein Belohnungsmodell zu trainieren und dann eine Richtlinie zu trainieren, die das erlernte Belohnungsmodell optimiert, während DPO Änderungen in Variablen verwendet, um den Präferenzverlust direkt als Funktion der Richtlinie zu definieren. Angesichts des menschlichen Präferenzdatensatzes für Modellantworten kann DPO daher die Richtlinie mithilfe eines einfachen binären Kreuzentropieziels optimieren, ohne dass während des Trainings explizit eine Belohnungsfunktion oder ein Beispiel aus der Richtlinie gelernt werden muss. Das Update auf
DPO erhöht die relative Log-Wahrscheinlichkeit bevorzugter Antworten im Vergleich zu nicht bevorzugten Antworten, enthält jedoch eine dynamische Wichtigkeitsgewichtung pro Stichprobe, um eine Modellverschlechterung zu verhindern, die die Forscher bei einem naiven Wahrscheinlichkeitsverhältnisziel festgestellt haben .
Um DPO mechanistisch zu verstehen, ist es sinnvoll, den Gradienten der Verlustfunktion zu analysieren  . Der Gradient in Bezug auf den Parameter θ kann wie folgt geschrieben werden:
. Der Gradient in Bezug auf den Parameter θ kann wie folgt geschrieben werden:
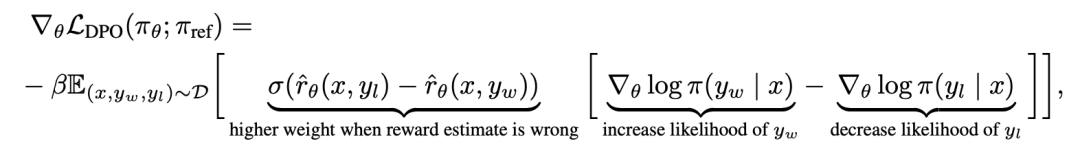
wobei 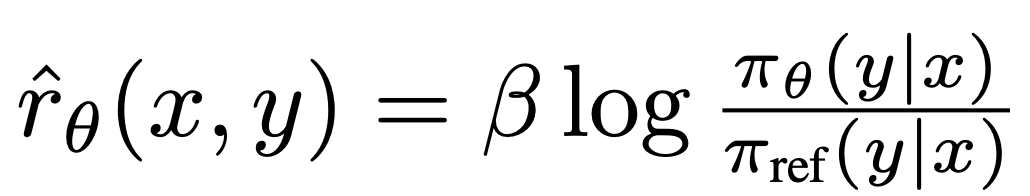 aus dem Sprachmodell
aus dem Sprachmodell 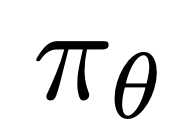 und dem Referenzmodell
und dem Referenzmodell 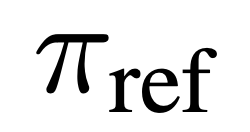 # besteht 🎜 🎜#Implizit definierte Belohnungen. Intuitiv erhöht der Gradient der Verlustfunktion
# besteht 🎜 🎜#Implizit definierte Belohnungen. Intuitiv erhöht der Gradient der Verlustfunktion  die Wahrscheinlichkeit des bevorzugten Abschlusses y_w und verringert die Wahrscheinlichkeit des nicht bevorzugten Abschlusses y_l.
die Wahrscheinlichkeit des bevorzugten Abschlusses y_w und verringert die Wahrscheinlichkeit des nicht bevorzugten Abschlusses y_l.
Wichtig ist, dass die Gewichte dieser Proben durch das implizite Belohnungsmodell bestimmt werden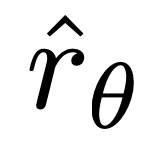 Die Bewertung des nicht gefallenen Abschlusses Das Niveau ist bestimmt durch β als Skala, das heißt, wie falsch das implizite Belohnungsmodell den Grad der Fertigstellung einstuft, was auch die Stärke der KL-Beschränkung widerspiegelt. Experimente zeigen die Bedeutung dieser Gewichtung, da eine naive Version dieser Methode ohne Gewichtungskoeffizienten zu einer Verschlechterung des Sprachmodells führt (Anhang Tabelle 2).
Die Bewertung des nicht gefallenen Abschlusses Das Niveau ist bestimmt durch β als Skala, das heißt, wie falsch das implizite Belohnungsmodell den Grad der Fertigstellung einstuft, was auch die Stärke der KL-Beschränkung widerspiegelt. Experimente zeigen die Bedeutung dieser Gewichtung, da eine naive Version dieser Methode ohne Gewichtungskoeffizienten zu einer Verschlechterung des Sprachmodells führt (Anhang Tabelle 2).
In Kapitel 5 der Arbeit erläuterte der Forscher die DPO-Methode weiter, lieferte theoretische Unterstützung und verglich die Vorteile von DPO mit dem in RLHF-Critic-Algorithmen verwendeten Actor (z. B. PPO) sind mit Problemen verbunden. Einzelheiten entnehmen Sie bitte dem Originalpapier.
ExperimentIn dem Experiment bewerteten die Forscher die Fähigkeit von DPO, Richtlinien direkt auf der Grundlage von Präferenzen zu trainieren.
Zunächst untersuchten sie in einer gut kontrollierten Textgenerierungsumgebung die Frage: Im Vergleich zu gängigen Präferenzlernalgorithmen wie PPO ist DPO in Referenzstrategien besser. Wie effizient Gibt es einen Kompromiss zwischen Belohnungsmaximierung und KL-Divergenzminimierung? Anschließend bewerteten wir die Leistung des DPO bei größeren Modellen und schwierigeren RLHF-Aufgaben, einschließlich Zusammenfassung und Dialog.
Letztendlich wurde festgestellt, dass DPO ohne Hyperparameter-Tuning häufig genauso gut oder sogar besser als leistungsstarke Basislinien wie RLHF mit PPO abschnitt Zeitlich werden die besten Ergebnisse der N-Probentrajektorie unter der Lernbelohnungsfunktion zurückgegeben.
In Bezug auf die Aufgaben untersuchten die Forscher drei verschiedene Aufgaben zur offenen Textgenerierung. In allen Experimenten lernt der Algorithmus die Richtlinie aus dem Präferenzdatensatz 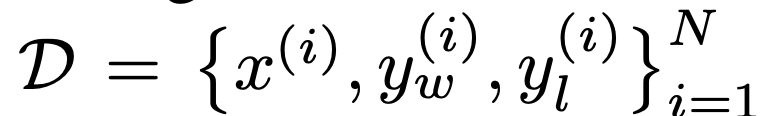 .
.
Bei der kontrollierten Emotionsgenerierung ist x das Präfix von Filmrezensionen aus dem IMDb-Datensatz, und die Strategie muss y generieren. Zur vergleichenden Auswertung verwendet das Experiment einen vorab trainierten Sentiment-Klassifikator, um Präferenzpaare zu generieren, wobei 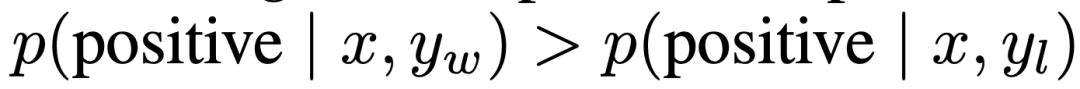 .
.
Für SFT haben die Forscher GPT-2-large verfeinert, bis es mit den Kommentaren zur Trainingsaufteilung der IMDB übereinstimmte Datensatz. Zusammenfassend lässt sich sagen, dass x ein Forumsbeitrag von Reddit ist und die Strategie eine Zusammenfassung der wichtigsten Punkte des Beitrags generieren muss. Aufbauend auf früheren Arbeiten verwendeten die Experimente den Reddit TL;DR-Zusammenfassungsdatensatz und menschliche Vorlieben, die von Stiennon et al. gesammelt wurden. Die Experimente verwendeten auch ein SFT-Modell, das auf der Grundlage von von Menschen verfassten Forumsartikelzusammenfassungen 2 und dem TRLX-Framework von RLHF verfeinert wurde. Der menschliche Präferenzdatensatz ist eine Stichprobe, die von Stiennon et al. aus einem anderen, aber ähnlich trainierten SFT-Modell gesammelt wurde.
Abschließend ist x in einem einmaligen Gespräch eine menschliche Frage, die von Astrophysik bis hin zu Beziehungsratschlägen alles Mögliche sein kann. Eine Richtlinie muss eine ansprechende und hilfreiche Antwort auf die Anfrage des Benutzers liefern. Das Experiment verwendet den Anthropic-Konversationssatz „Hilfreich und Harmlos“, der 170.000 Konversationen zwischen menschlichen und automatisierten Assistenten enthält. Jeder Text endet mit einem Antwortpaar, das von einem großen (wenn auch unbekannten) Sprachmodell generiert wird, und einer Präferenzbezeichnung, die die vom Menschen bevorzugte Antwort darstellt. In diesem Fall ist kein vorab trainiertes SFT-Modell verfügbar. Daher optimieren Experimente handelsübliche Sprachmodelle nur auf bevorzugte Vervollständigungen, um SFT-Modelle zu bilden.
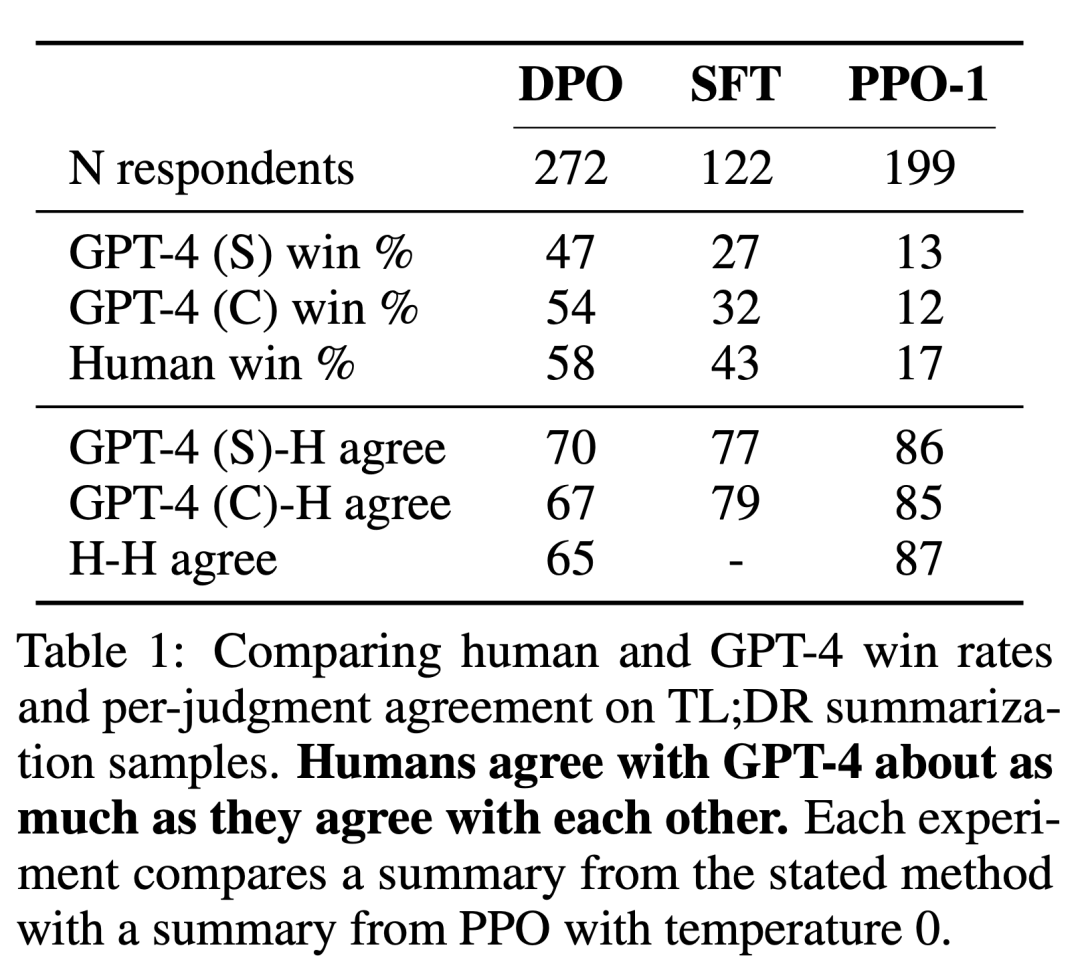
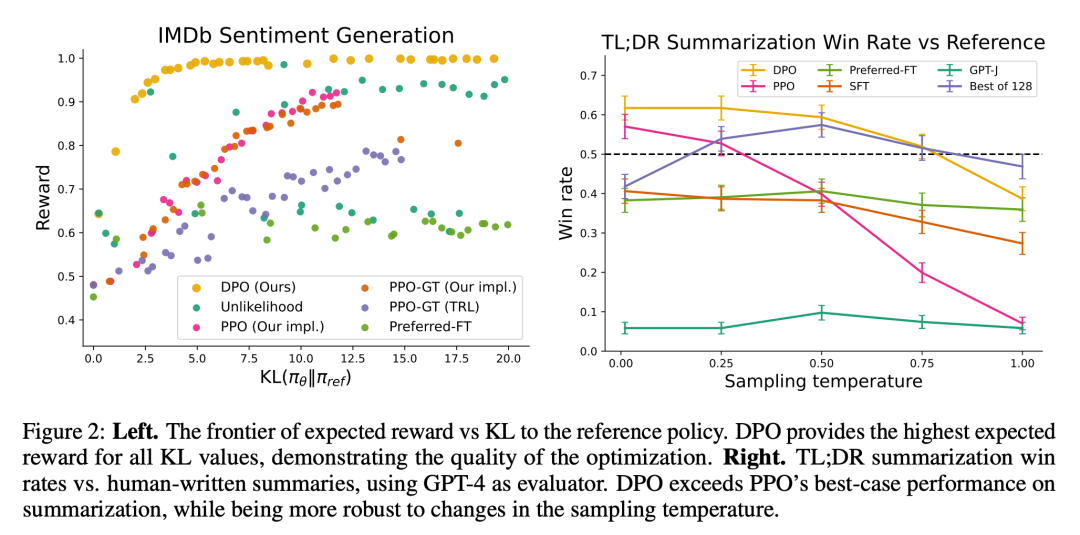
Die Forscher verwendeten zwei Bewertungsmethoden. Um die Effizienz jedes Algorithmus bei der Optimierung des Ziels der eingeschränkten Belohnungsmaximierung zu analysieren, bewerten Experimente jeden Algorithmus anhand seiner Grenzen für das Erreichen von Belohnungen und der KL-Divergenz von einer Referenzstrategie in einer kontrollierten Emotionserzeugungsumgebung. Experimente können Ground-Truth-Belohnungsfunktionen (Stimmungsklassifikatoren) verwenden, sodass diese Grenze berechnet werden kann. Tatsächlich ist die Ground-Truth-Belohnungsfunktion jedoch unbekannt. Wir bewerten daher die Gewinnrate des Algorithmus anhand der Gewinnrate der Basisstrategie und verwenden GPT-4 als Proxy für die menschliche Bewertung der Zusammenfassungsqualität und des Antwortnutzens bei Zusammenfassungen und Einzelrunden-Dialogeinstellungen. Für Abstracts verwendet das Experiment die Referenzzusammenfassung in der Testmaschine als Grenze für den Dialog; die bevorzugte Antwort im Testdatensatz wird als Basislinie ausgewählt. Während bestehende Forschungsergebnisse darauf hindeuten, dass Sprachmodelle bessere automatische Evaluatoren sein können als bestehende Metriken, führten die Forscher eine menschliche Studie durch, die die Machbarkeit der Verwendung von GPT-4 zur Bewertung von GPT-4 demonstrierte ist im Allgemeinen ähnlich oder höher als die Übereinstimmung zwischen menschlichen Annotatoren.
Zusätzlich zu DPO bewerteten die Forscher auch mehrere vorhandene Trainingssprachen Modelle müssen den menschlichen Vorlieben entsprechen. Im einfachsten Fall untersuchen Experimente die Zero-Shot-Eingabeaufforderungen von GPT-J bei der Zusammenfassungsaufgabe und die 2-Shot-Eingabeaufforderungen von Pythia-2.8B bei der Konversationsaufgabe. Darüber hinaus werden in Experimenten das SFT-Modell und Preferred-FT evaluiert. Preferred-FT ist ein Modell, das durch überwachtes Lernen auf Vervollständigungen abgestimmt wird, die aus SFT-Modellen (kontrollierte Stimmung und Zusammenfassung) oder allgemeinen Sprachmodellen (Single-Turn-Dialog) ausgewählt werden. Eine weitere pseudoüberwachte Methode ist Unwahrscheinlichkeit, die einfach die Richtlinie optimiert, um die y_w zugewiesene Wahrscheinlichkeit zu maximieren und die y_l zugewiesene Wahrscheinlichkeit zu minimieren. Das Experiment verwendet einen optionalen Koeffizienten α∈[0,1] für „Unlikehood“. Sie berücksichtigten auch PPO, wobei eine aus Präferenzdaten erlernte Belohnungsfunktion verwendet wurde, und PPO-GT. PPO-GT ist ein Orakel, das aus Ground-Truth-Belohnungsfunktionen gelernt wird, die in kontrollierten Emotionseinstellungen verfügbar sind. In seinen Emotionsexperimenten verwendete das Team zwei Implementierungen von PPO-GT, eine Standardversion und eine modifizierte Version. Letzteres normalisiert die Belohnungen und optimiert die Hyperparameter weiter, um die Leistung zu verbessern (in den Experimenten wurden diese Modifikationen auch verwendet, wenn „normales“ PPO mit Lernbelohnungen ausgeführt wurde). Schließlich betrachten wir die besten von N Basislinien, proben N Antworten aus dem SFT-Modell (oder Preferred-FT im Konversationsbegriff) und geben die Antwort mit der höchsten Bewertung basierend auf einer Belohnungsfunktion zurück, die aus dem Präferenzdatensatz gelernt wurde. Dieser Hochleistungsansatz entkoppelt die Qualität des Belohnungsmodells von der PPO-Optimierung, ist jedoch selbst für moderate N rechnerisch unpraktisch, da er N Stichprobenabschlüsse pro Abfrage zum Testzeitpunkt erfordert.
Abbildung 2 zeigt die Belohnungs-KL-Grenzen für verschiedene Algorithmen in der Emotionseinstellung. Abbildung 3 zeigt die relative Geschwindigkeit, mit der DPO schneller seine optimale Leistung erreicht.
Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonIst das „RL' in RLHF erforderlich? Einige Leute verwenden binäre Kreuzentropie, um LLM direkt zu optimieren, und der Effekt ist besser.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr