
Heim >Technologie-Peripheriegeräte >KI >UCLA-Chinesen schlagen einen neuen Selbstspielmechanismus vor! LLM trainiert sich selbst und der Effekt ist besser als der der GPT-4-Expertenanleitung.
UCLA-Chinesen schlagen einen neuen Selbstspielmechanismus vor! LLM trainiert sich selbst und der Effekt ist besser als der der GPT-4-Expertenanleitung.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-03 08:00:161400Durchsuche
Synthetische Daten sind zum wichtigsten Eckpfeiler in der Entwicklung großer Sprachmodelle geworden.
Ende letzten Jahres enthüllten einige Internetnutzer, dass der ehemalige OpenAI-Chefwissenschaftler Ilya wiederholt erklärt habe, dass es bei der Entwicklung von LLM keine Datenengpässe gebe und synthetische Daten die meisten Probleme lösen könnten.
 Bilder
Bilder
Nach dem Studium der neuesten Arbeiten kam Jim Fan, ein leitender Wissenschaftler bei NVIDIA, zu dem Schluss, dass die Kombination synthetischer Daten mit traditioneller Spiel- und Bilderzeugungstechnologie es LLM ermöglichen kann, eine enorme Selbstentwicklung zu erreichen.
 Bilder
Bilder
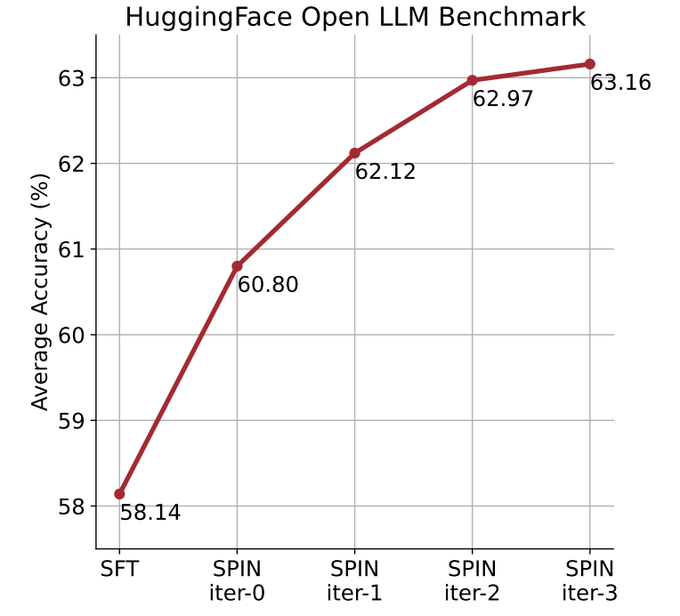
Der Artikel, der diese Methode offiziell vorschlug, wurde von einem chinesischen Team der UCLA verfasst. ? durch das Selbst- Feinabstimmungsmethode, nein Basierend auf dem neuen Datensatz wird die durchschnittliche Punktzahl des schwächeren LLM im Open LLM Leaderboard Benchmark von 58,14 auf 63,16 verbessert.

Die Forscher schlugen eine selbstverfeinernde Methode namens SPIN vor, die selbstspielendes Schach verwendet – LLM konkurriert mit seiner vorherigen Iterationsversion, um die Leistung des Sprachmodells schrittweise zu verbessern.
Bilder
 Auf diese Weise kann die Selbstentwicklung des Modells abgeschlossen werden, ohne dass zusätzliche menschliche Annotationsdaten oder Feedback von übergeordneten Sprachmodellen erforderlich sind.
Auf diese Weise kann die Selbstentwicklung des Modells abgeschlossen werden, ohne dass zusätzliche menschliche Annotationsdaten oder Feedback von übergeordneten Sprachmodellen erforderlich sind.
Die Parameter des Hauptmodells und des Gegnermodells sind genau gleich. Spielen Sie mit zwei verschiedenen Versionen gegen sich selbst.
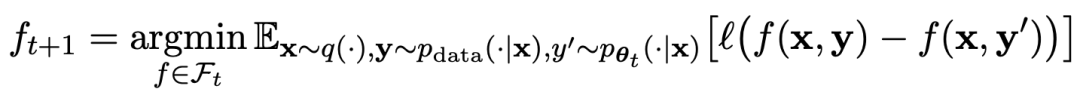 Der Spielablauf kann durch die Formel zusammengefasst werden:
Der Spielablauf kann durch die Formel zusammengefasst werden:
Bilder
Die Trainingsmethode des Selbstspiels. Zusammenfassend ist die Idee ungefähr so:
Unterscheiden Sie die Antworten Das Gegnermodell wird vom Gegnermodell durch Training des Hauptmodells und menschlicher Zielreaktionen generiert. Das Gegnermodell ist ein Sprachmodell, das iterativ in Runden erhalten wird, mit dem Ziel, Antworten zu generieren, die möglichst nicht unterscheidbar sind.
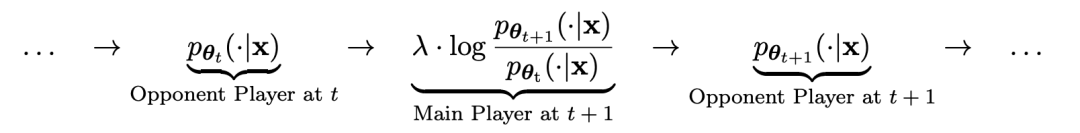 Angenommen, die in der t-ten Iteration erhaltenen Sprachmodellparameter sind θt. Verwenden Sie dann in der t + 1-Iteration θt als Gegenspieler und verwenden Sie θt, um die Antwort y' für jede Eingabeaufforderung x in zu generieren überwachter Feinabstimmungsdatensatz.
Angenommen, die in der t-ten Iteration erhaltenen Sprachmodellparameter sind θt. Verwenden Sie dann in der t + 1-Iteration θt als Gegenspieler und verwenden Sie θt, um die Antwort y' für jede Eingabeaufforderung x in zu generieren überwachter Feinabstimmungsdatensatz.
Optimieren Sie dann die neuen Sprachmodellparameter θt+1, damit sie y' von der menschlichen Antwort y im überwachten Feinabstimmungsdatensatz unterscheiden können. Dies kann einen schrittweisen Prozess bilden und sich schrittweise der Zielreaktionsverteilung nähern.
Hier verwendet die Verlustfunktion des Hauptmodells einen logarithmischen Verlust und berücksichtigt dabei den Unterschied in den Funktionswerten zwischen y und y‘.
Fügen Sie dem Gegnermodell eine KL-Divergenz-Regularisierung hinzu, um zu verhindern, dass die Modellparameter zu stark abweichen.
Die spezifischen Trainingsziele für gegnerische Spiele sind in Formel 4.7 dargestellt. Aus der theoretischen Analyse ist ersichtlich, dass der Optimierungsprozess konvergiert, wenn die Antwortverteilung des Sprachmodells gleich der Zielantwortverteilung ist.
Wenn Sie die nach dem Spiel generierten synthetischen Daten für das Training verwenden und dann SPIN zur Selbstoptimierung verwenden, kann die Leistung von LLM effektiv verbessert werden.
Bilder
Aber dann führt eine einfache erneute Feinabstimmung der anfänglichen Feinabstimmungsdaten zu Leistungseinbußen.
SPIN erfordert lediglich das Ausgangsmodell selbst und den vorhandenen fein abgestimmten Datensatz, damit sich LLM durch SPIN verbessern kann.
Insbesondere übertrifft SPIN sogar Modelle, die mit zusätzlichen GPT-4-Präferenzdaten über DPO trainiert wurden.
 Bilder
Bilder
Und Experimente zeigen auch, dass iteratives Training die Modellleistung effektiver verbessern kann als Training mit mehr Epochen.
 Bilder
Bilder
Durch die Verlängerung der Trainingsdauer einer einzelnen Iteration wird die Leistung von SPIN nicht beeinträchtigt, es stößt jedoch an seine Grenzen.
Je mehr Iterationen, desto offensichtlicher ist die Wirkung von SPIN.
Nach der Lektüre dieses Artikels seufzten die Internetnutzer:
Synthetische Daten werden die Entwicklung großer Sprachmodelle dominieren, was für Forscher großer Sprachmodelle eine sehr gute Nachricht sein wird!
 Bilder
Bilder
Selbstspielen ermöglicht es LLM, sich kontinuierlich zu verbessern
Konkret handelt es sich bei dem von den Forschern entwickelten SPIN-System um ein System, bei dem sich zwei sich gegenseitig beeinflussende Modelle gegenseitig fördern.
bezeichnet durch 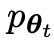 das LLM der vorherigen Iteration t, das die Forscher verwendet haben, um die Antwort y auf den Hinweis x im vom Menschen kommentierten SFT-Datensatz zu generieren.
das LLM der vorherigen Iteration t, das die Forscher verwendet haben, um die Antwort y auf den Hinweis x im vom Menschen kommentierten SFT-Datensatz zu generieren.
Das nächste Ziel besteht darin, ein neues LLM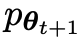 zu finden, das in der Lage ist, zwischen der
zu finden, das in der Lage ist, zwischen der 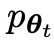 generierten Antwort y und der vom Menschen generierten Antwort y‘ zu unterscheiden.
generierten Antwort y und der vom Menschen generierten Antwort y‘ zu unterscheiden.
Dieser Prozess kann als ein Spiel für zwei Spieler angesehen werden:
Der Hauptspieler oder das neue LLM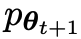 versucht, die Reaktion des gegnerischen Spielers und die vom Menschen erzeugte Reaktion zu erkennen, während der Gegner oder das alte LLM
versucht, die Reaktion des gegnerischen Spielers und die vom Menschen erzeugte Reaktion zu erkennen, während der Gegner oder das alte LLM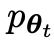 generiert Antworten, die den Daten im manuell kommentierten SFT-Datensatz so ähnlich wie möglich sind.
generiert Antworten, die den Daten im manuell kommentierten SFT-Datensatz so ähnlich wie möglich sind.
Das neue LLM 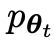 , das durch Feinabstimmung des alten
, das durch Feinabstimmung des alten 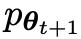 erhalten wurde, bevorzugt die Reaktion von
erhalten wurde, bevorzugt die Reaktion von 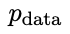 , was zu einer konsistenteren Verteilung
, was zu einer konsistenteren Verteilung 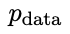 mit
mit 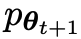 führt.
führt.
In der nächsten Iteration wird das neu erworbene LLM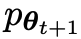 zum Gegner der Antwortgenerierung, und das Ziel des selbstspielenden Prozesses besteht darin, dass das LLM schließlich zu
zum Gegner der Antwortgenerierung, und das Ziel des selbstspielenden Prozesses besteht darin, dass das LLM schließlich zu 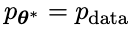 konvergiert, so dass das stärkste LLM dazu nicht mehr in der Lage ist Unterscheiden Sie zwischen der zuvor generierten Antwortversion und der vom Menschen generierten Version.
konvergiert, so dass das stärkste LLM dazu nicht mehr in der Lage ist Unterscheiden Sie zwischen der zuvor generierten Antwortversion und der vom Menschen generierten Version.
So nutzen Sie SPIN zur Verbesserung der Modellleistung
Die Forscher entwickelten ein Spiel für zwei Spieler, bei dem das Hauptziel des Modells darin besteht, zwischen LLM-generierten Antworten und von Menschen generierten Antworten zu unterscheiden. Gleichzeitig besteht die Rolle des Gegners darin, Reaktionen hervorzurufen, die nicht von denen des Menschen zu unterscheiden sind. Im Mittelpunkt des Ansatzes der Forscher steht das Training des Primärmodells.
Erklären Sie zunächst, wie Sie das Hauptmodell trainieren, um LLM-Antworten von menschlichen Antworten zu unterscheiden.
Im Mittelpunkt des Ansatzes der Forscher steht ein Selbstspielmechanismus, bei dem sowohl der Hauptspieler als auch der Gegner aus demselben LLM stammen, jedoch aus unterschiedlichen Iterationen.
Genauer gesagt ist der Gegner der alte LLM aus der vorherigen Iteration, und der Hauptakteur ist der neue LLM, der in der aktuellen Iteration gelernt werden muss. Die Iteration t+1 umfasst die folgenden zwei Schritte: (1) Training des Hauptmodells, (2) Aktualisierung des Gegenmodells.
Training des Master-Modells
Zunächst erklären die Forscher, wie man dem Master-Spieler beibringt, zwischen LLM-Reaktionen und menschlichen Reaktionen zu unterscheiden. Inspiriert durch das integrale Wahrscheinlichkeitsmaß (IPM) formulierten die Forscher die Zielfunktion:
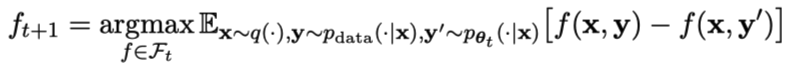 Bild
Bild
Aktualisieren Sie das Gegnermodell.
Das Ziel des Gegnermodells besteht darin, ein besseres LLM zu finden erzeugt Die Antwort von unterscheidet sich nicht von den p-Daten des Hauptmodells.
Experimente
SPIN verbessert effektiv die Benchmark-Leistung
Die Forscher nutzten das HuggingFace Open LLM Leaderboard als umfassende Bewertung, um die Wirksamkeit von SPIN zu beweisen.
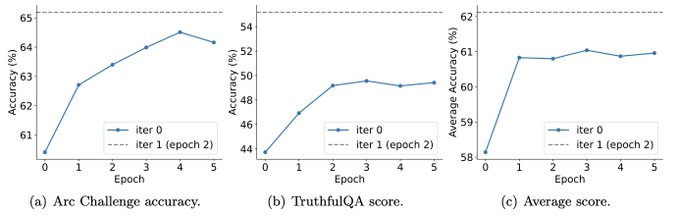
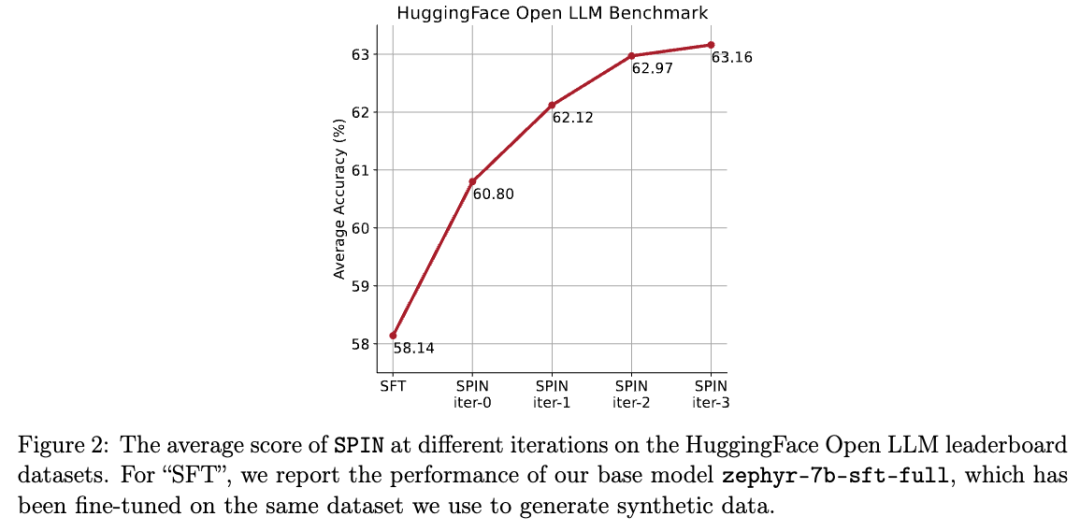
In der folgenden Abbildung verglichen die Forscher die Leistung des von SPIN fein abgestimmten Modells nach 0 bis 3 Iterationen mit dem Basismodell zephyr-7b-sft-full.
Forscher können beobachten, dass SPIN signifikante Ergebnisse bei der Verbesserung der Modellleistung zeigt, indem es den SFT-Datensatz weiter nutzt, auf dem das Basismodell vollständig verfeinert wurde.
In Iteration 0 wurde die Modellantwort aus zephyr-7b-sft-full generiert, und die Forscher beobachteten eine Gesamtverbesserung der durchschnittlichen Punktzahl um 2,66 %.
Diese Verbesserung macht sich besonders bei den Benchmarks TruthfulQA und GSM8k bemerkbar, mit Steigerungen von über 5 % bzw. 10 %.
In Iteration 1 verwendeten die Forscher das LLM-Modell aus Iteration 0, um eine neue Antwort für SPIN zu generieren, indem sie dem in Algorithmus 1 beschriebenen Prozess folgten.
Diese Iteration führt zu einer weiteren Verbesserung von durchschnittlich 1,32 %, was besonders bei den Arc Challenge- und TruthfulQA-Benchmarks von Bedeutung ist.
Nachfolgende Iterationen setzten den Trend schrittweiser Verbesserungen für verschiedene Aufgaben fort. Gleichzeitig ist die Verbesserung bei Iteration t+1 natürlich geringer ausgebildet.
 Die Forscher weisen darauf hin, dass DPO menschliche Eingaben oder Rückmeldungen von Hochsprachenmodellen erfordert, um Präferenzen zu ermitteln, sodass die Datengenerierung ein ziemlich kostspieliger Prozess ist.
Die Forscher weisen darauf hin, dass DPO menschliche Eingaben oder Rückmeldungen von Hochsprachenmodellen erfordert, um Präferenzen zu ermitteln, sodass die Datengenerierung ein ziemlich kostspieliger Prozess ist.
Im Gegensatz dazu benötigt der SPIN der Forscher nur das Ausgangsmodell selbst.
Darüber hinaus nutzt die Methode der Forscher im Gegensatz zu DPO, das neue Datenquellen erfordert, vollständig vorhandene SFT-Datensätze.
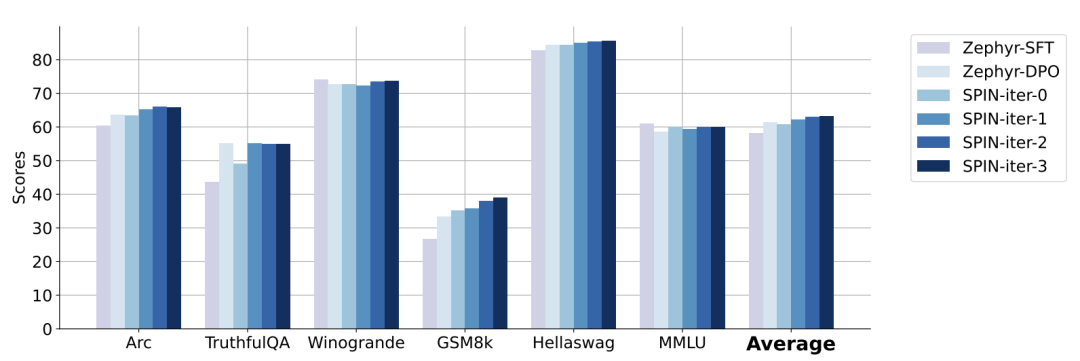
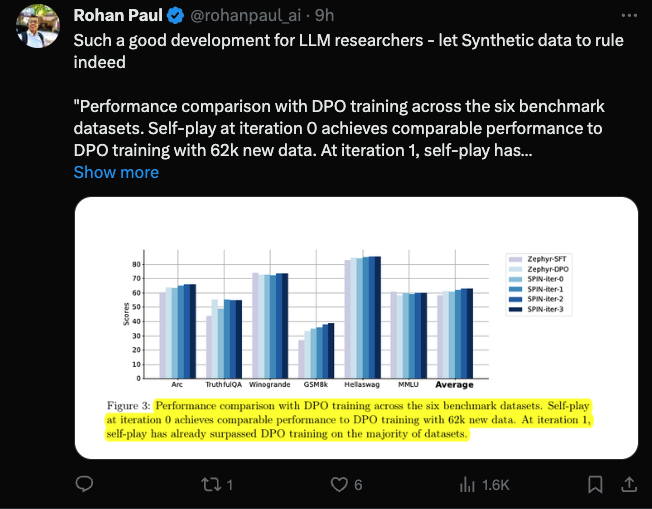
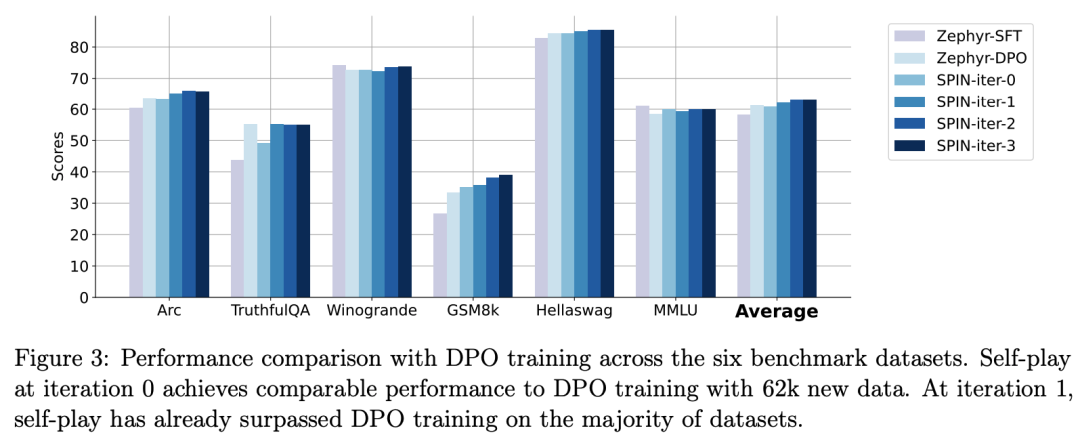
Die folgende Abbildung zeigt den Leistungsvergleich von SPIN mit dem DPO-Training bei den Iterationen 0 und 1 (unter Verwendung von 50.000 SFT-Daten).
 Bilder
Bilder
Die Forscher können beobachten, dass SPIN auf der Grundlage vorhandener SFT-Daten ab Iteration 1 beginnt, obwohl DPO mehr Daten aus neuen Quellen nutzt. SPIN übertrifft in der Rangliste sogar die Leistung von DPO und SPIN Benchmark-Tests übertreffen sogar die von DPO.
Referenz:
Das obige ist der detaillierte Inhalt vonUCLA-Chinesen schlagen einen neuen Selbstspielmechanismus vor! LLM trainiert sich selbst und der Effekt ist besser als der der GPT-4-Expertenanleitung.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Zum ersten Mal: Microsoft verwendet GPT-4 zur Feinabstimmung großer Modellanweisungen und die Zero-Sample-Leistung neuer Aufgaben wird weiter verbessert.
- GPT-4 gibt Anlass zur Sorge, und Tausende von Technologieexperten, darunter Musk, fordern ein Moratorium für eine stärkere KI-Entwicklung
- watchGPT wurde in „Petey' umbenannt und auf GPT-4 aktualisiert, um die Überprüfung im App Store zu umgehen
- Alibaba Cloud AnalyticDB (ADB) + LLM: Aufbau eines unternehmensspezifischen Chatbots im AIGC-Zeitalter