
Heim >Technologie-Peripheriegeräte >KI >Gibt es auch Diebe in großen Modellen? Um Ihre Parameter zu schützen, übermitteln Sie das große Modell, um einen „für Menschen lesbaren Fingerabdruck' zu erstellen.
Gibt es auch Diebe in großen Modellen? Um Ihre Parameter zu schützen, übermitteln Sie das große Modell, um einen „für Menschen lesbaren Fingerabdruck' zu erstellen.

- PHPznach vorne
- 2024-02-02 21:33:301504Durchsuche
symbolisiert verschiedene Basismodelle als unterschiedliche Hunderassen, wobei der gleiche „hundeförmige Fingerabdruck“ anzeigt, dass sie vom gleichen Basismodell abgeleitet sind.
Das Vortraining großer Modelle erfordert eine große Menge an Rechenressourcen und Daten. Daher sind die Parameter vorab trainierter Modelle zu den zentralen Wettbewerbsfähigkeiten und Vermögenswerten geworden, auf deren Schutz sich große Institutionen konzentrieren. Im Gegensatz zum herkömmlichen Schutz des geistigen Eigentums von Software gibt es jedoch zwei neue Probleme bei der Beurteilung des Diebstahls vorab trainierter Modellparameter:
1) Die Parameter vorab trainierter Modelle, insbesondere die von Hunderten Milliarden Modellen, sind normalerweise nicht offen Quelle.
Die Ausgabe und die Parameter des vorab trainierten Modells werden durch nachfolgende Verarbeitungsschritte (wie SFT, RLHF, Vortraining fortsetzen usw.) beeinflusst, was es schwierig macht, zu beurteilen, ob ein Modell auf der Grundlage eines anderen vorhandenen Modells feinabgestimmt ist Modell. Unabhängig davon, ob die Beurteilung auf der Grundlage der Modellausgabe oder der Modellparameter erfolgt, gibt es bestimmte Herausforderungen.
Daher ist der Schutz großer Modellparameter ein völlig neues Problem, für das es keine wirksamen Lösungen gibt.
Das Lumia-Forschungsteam von Professor Lin Zhouhan von der Shanghai Jiao Tong University hat eine innovative Technologie entwickelt, die Abstammungsbeziehungen zwischen großen Modellen identifizieren kann. Dieser Ansatz verwendet einen für Menschen lesbaren Fingerabdruck eines großen Modells, ohne Modellparameter offenzulegen. Die Erforschung und Entwicklung dieser Technologie ist für die Entwicklung und Anwendung großer Modelle von großer Bedeutung.
Diese Methode bietet zwei Identifizierungsmethoden: Eine ist eine quantitative Identifizierungsmethode, die durch Vergleich der Ähnlichkeit zwischen dem getesteten großen Modell und einer Reihe von Basismodellen bestimmt, ob das vorab trainierte Basismodell gestohlen wurde Methode: Entdecken Sie schnell Vererbungsbeziehungen zwischen Modellen, indem Sie für Menschen lesbare „Hundediagramme“ erstellen.

Fingerabdrücke von 6 verschiedenen Basismodellen (erste Reihe) und ihren entsprechenden Nachkommenmodellen (untere zwei Reihen).

Von Menschen lesbare Fingerabdrücke großer Modelle, erstellt auf 24 verschiedenen großen Modellen.
Motivation und Gesamtansatz
Die rasante Entwicklung von Großmodellen bringt vielfältige Anwendungsperspektiven mit sich, löst aber auch eine Reihe neuer Herausforderungen aus. Zwei der offenen Punkte sind:
Modelldiebstahlproblem: Ein cleverer „Dieb“, der nur geringfügige Änderungen am ursprünglichen Großmodell vornimmt und dann behauptet, ein brandneues Modell geschaffen zu haben, wobei er seinen eigenen Beitrag übertreibt. Wie erkennen wir, ob es sich um ein Raubkopienmodell handelt?
Modellmissbrauchsproblem: Wenn ein Krimineller das LLaMA-Modell in böswilliger Absicht modifiziert und es verwendet, um schädliche Informationen zu generieren, obwohl die Richtlinien von Meta dieses Verhalten eindeutig verbieten, wie können wir dann nachweisen, dass er das LLaMA-Modell verwendet?
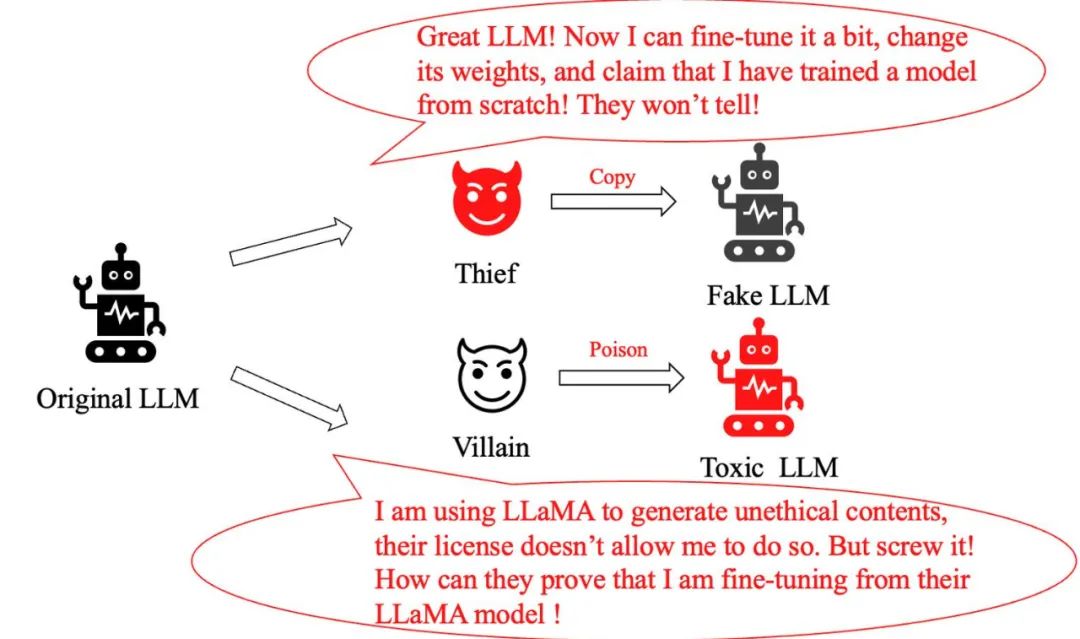
Zu den herkömmlichen Methoden zur Lösung dieser Art von Problemen gehörte bisher das Hinzufügen von Wasserzeichen während des Modelltrainings und der Inferenz oder das Klassifizieren von Text, der von großen Modellen generiert wurde. Diese Methoden beeinträchtigen jedoch entweder die Leistung großer Modelle oder können leicht durch einfache Feinabstimmung oder weiteres Vortraining umgangen werden.
Dies wirft eine Schlüsselfrage auf: Gibt es eine Methode, die die Ausgabeverteilung eines großen Modells nicht beeinträchtigt, robust gegenüber Feinabstimmung und weiterem Vortraining ist und gleichzeitig das Basismodell eines großen Modells genau und damit effektiv verfolgen kann? Das Ziel des Schutzes des Modellurheberrechts.
Ein Team der Shanghai Jiao Tong University ließ sich von den einzigartigen Eigenschaften menschlicher Fingerabdrücke inspirieren und entwickelte eine Methode zur Herstellung „für Menschen lesbarer Fingerabdrücke“ für große Modelle. Sie stellten unterschiedliche Basismodelle als unterschiedliche Hunderassen dar, wobei der gleiche „hundeförmige Fingerabdruck“ darauf hinweist, dass sie vom gleichen Basismodell abgeleitet waren.
Diese intuitive Methode ermöglicht es der Öffentlichkeit, die Verbindung zwischen verschiedenen großen Modellen leicht zu erkennen und das Basismodell des Modells anhand dieser Fingerabdrücke zu verfolgen, wodurch Modellpiraterie und -missbrauch wirksam verhindert werden. Es ist erwähnenswert, dass Hersteller großer Modelle nicht ihre Parameter veröffentlichen müssen, sondern nur die Invarianten, die zur Generierung von Fingerabdrücken verwendet werden.

Die „Fingerabdrücke“ von Alpaca und LLaMA sind sehr ähnlich. Dies liegt daran, dass das Alpaca-Modell durch Feinabstimmung von LLaMA erhalten wird, während die Fingerabdrücke mehrerer anderer Modelle offensichtliche Unterschiede aufweisen, was darauf hindeutet, dass sie von einer anderen Basis abgeleitet sind Modell.
Papier „HUREF: HUMAN-READABLE FINGERPRINT FOR LARGE LANGUAGE MODELS“:

Adresse zum Herunterladen des Papiers: https://arxiv.org/pdf/2312.04828.pdf
Beobachtete Invarianten aus Experimenten
Das Team der Jiaotong-Universität stellte fest, dass diese The Die Richtung des Parametervektors des Modells ändert sich geringfügig. Im Gegensatz dazu unterscheidet sich die Parameterrichtung eines großen, von Grund auf neu trainierten Modells völlig von der anderer Basismodelle.
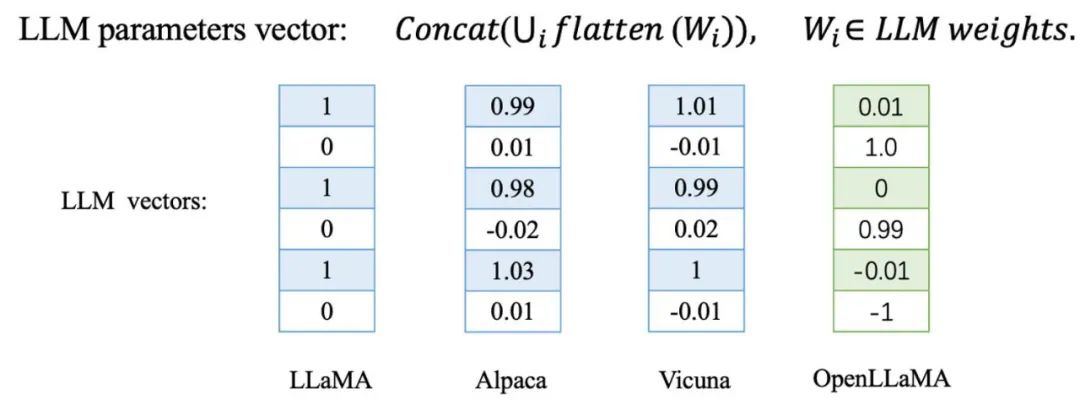
Sie wurden anhand einer Reihe abgeleiteter Modelle von LLaMA verifiziert, darunter Alpaca und Vicuna, die durch Feinabstimmung von LLaMA erhalten wurden, sowie Chinese LLaMA und Chinese Alpaca, die durch weiteres Vortraining von LLaMA erhalten wurden. Darüber hinaus testeten sie auch unabhängig trainierte Basismodelle wie Baichuan und Shusheng.

Das in der Tabelle blau markierte LLaMA-Ableitungsmodell und das LLaMA-7B-Basismodell weisen eine extrem hohe Kosinusähnlichkeit im Parametervektor auf, was bedeutet, dass diese Ableitungsmodelle in Richtung des sehr nahe am Basismodell liegen Parametervektor. Im Gegensatz dazu stellen die rot markierten unabhängig trainierten Basismodelle eine völlig andere Situation dar, da ihre Parametervektorrichtungen völlig unabhängig voneinander sind.
Auf der Grundlage dieser Beobachtungen überlegten sie, ob sie auf der Grundlage dieser empirischen Regel einen Fingerabdruck des Modells erstellen könnten. Es bleibt jedoch eine zentrale Frage: Ist dieser Ansatz robust genug gegen böswillige Angriffe?
Um dies zu überprüfen, fügte das Forschungsteam bei der Feinabstimmung von LLaMA die Parameterähnlichkeit zwischen Modellen als Strafverlust hinzu, sodass bei der Feinabstimmung des Modells die Parameterrichtung so weit wie möglich vom Basismodell abweicht. und testeten, ob das Modell die Leistung aufrechterhalten kann. Gleichzeitig wichen sie von der ursprünglichen Parameterrichtung ab:

Sie testeten das Originalmodell und das durch Hinzufügen von Strafverlust-Feinabstimmung erhaltene Modell an 8 Benchmarks wie BoolQ und MMLU . Wie Sie der folgenden Tabelle entnehmen können, nimmt die Leistung des Modells mit abnehmender Kosinusähnlichkeit rapide ab. Dies zeigt, dass es ziemlich schwierig ist, von der ursprünglichen Parameterrichtung abzuweichen, ohne die Fähigkeit des Basismodells zu beeinträchtigen!


Derzeit ist die Richtung des Parametervektors eines großen Modells ein äußerst effektiver und robuster Indikator zur Identifizierung seines Basismodells. Es scheint jedoch einige Probleme zu geben, die Parametervektorrichtung direkt als Identifikationsinstrument zu verwenden. Erstens erfordert dieser Ansatz die Offenlegung der Parameter des Modells, was für viele große Modelle möglicherweise nicht akzeptabel ist. Zweitens kann der Angreifer einfach die versteckten Einheiten ersetzen, um die Richtung des Parametervektors anzugreifen, ohne die Modellleistung zu beeinträchtigen.
Nehmen Sie als Beispiel das Feedforward Neural Network (FFN) in Transformer. Durch einfaches Ersetzen der versteckten Einheiten und entsprechendes Anpassen ihrer Gewichtungen können Sie die Gewichtsrichtung ändern, ohne die Netzwerkausgabe zu ändern.

Darüber hinaus führte das Team auch eine eingehende Analyse von linearen Mapping-Angriffen und Verschiebungsangriffen auf die Worteinbettung großer Modelle durch. Diese Ergebnisse werfen die Frage auf: Wie können wir effektiv reagieren und diese Probleme lösen, wenn wir mit solch unterschiedlichen Angriffsmethoden konfrontiert werden?
Sie leiteten drei Sätze von Invarianten ab, die robust gegenüber diesen Angriffen sind, indem sie die Angriffsmatrizen durch Multiplikation zwischen Parametermatrizen eliminierten.
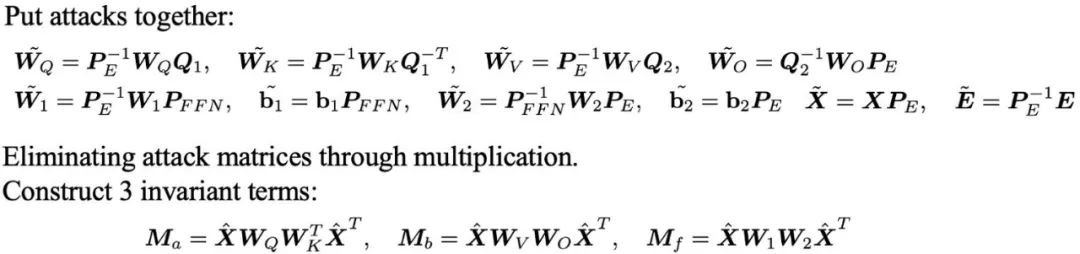
Von Invarianten zu menschenlesbaren Fingerabdrücken
Obwohl die oben abgeleiteten Invarianten als Identitätsmarker im großen Maßstab ausreichen, erscheinen sie normalerweise in Form riesiger Matrizen, die nicht nur nicht intuitiv sind, sondern auch zusätzliche Ähnlichkeiten aufweisen Berechnungen sind erforderlich, um die Beziehung zwischen verschiedenen großen Modellen zu bestimmen. Gibt es eine intuitivere und verständlichere Möglichkeit, diese Informationen darzustellen?
Um dieses Problem zu lösen, hat das Team der Shanghai Jiao Tong University eine Methode entwickelt, um aus Modellparametern für Menschen lesbare Fingerabdrücke zu generieren – HUREF.
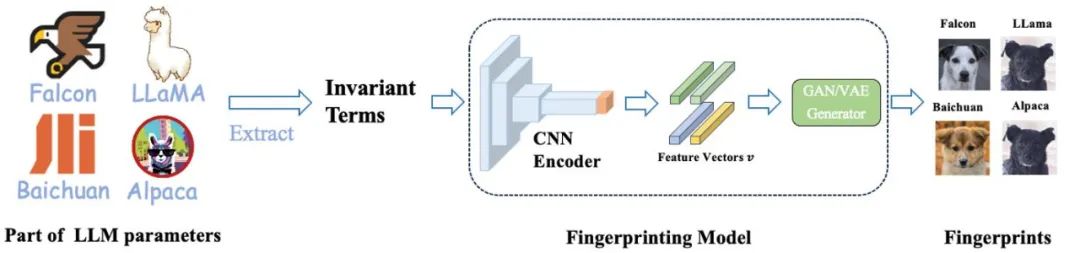
Sie extrahierten zunächst Invarianten aus einigen Parametern des großen Modells, codierten dann mit CNN Encoder die invariante Matrix in einen Merkmalsvektor, der der Gaußschen Verteilung unter Beibehaltung der Lokalität gehorchte, und verwendeten schließlich ein glattes GAN oder VAE als Bildgenerator Dekodieren Sie diese Merkmalsvektoren in visuelle Bilder (d. h. Bilder von Hunden). Diese Bilder sind nicht nur für Menschen lesbar, sondern zeigen auch visuell die Ähnlichkeiten zwischen verschiedenen Modellen und dienen so effektiv als „visueller Fingerabdruck“ für große Modelle. Im Folgenden finden Sie den detaillierten Trainings- und Inferenzprozess.

In diesem Rahmen ist der CNN-Encoder der einzige Teil, der trainiert werden muss. Sie verwenden kontrastives Lernen, um die lokale Erhaltung des Encoders sicherzustellen, und verwenden gleichzeitig generatives kontradiktorisches Lernen, um sicherzustellen, dass der Merkmalsvektor einer Gaußschen Verteilung folgt, die mit dem Eingaberaum des GAN- oder VAE-Generators übereinstimmt.
Wichtig ist, dass während des Trainingsprozesses keine echten Modellparameter verwendet werden müssen, alle Daten werden durch Normalverteilungsstichproben ermittelt. In praktischen Anwendungen werden der trainierte CNN-Encoder und der handelsübliche StyleGAN2-Generator, der auf dem AFHQ-Hundedatensatz trainiert wurde, direkt zur Inferenz verwendet.
Fingerabdrücke für verschiedene große Modelle generieren
Um die Wirksamkeit dieser Methode zu überprüfen, führte das Team Experimente an verschiedenen weit verbreiteten großen Modellen durch. Sie wählten mehrere bekannte Open-Source-Großmodelle wie Falcon, MPT, LLaMA2, Qwen, Baichuan und InternLM sowie deren abgeleitete Modelle aus, berechneten die Invarianten dieser Modelle und generierten das Fingerabdruckbild, wie in der folgenden Abbildung dargestellt . .

Die Fingerabdrücke der abgeleiteten Modelle sind ihren Originalmodellen sehr ähnlich und wir können anhand der Bilder intuitiv erkennen, auf welchem Prototypmodell sie basieren. Darüber hinaus weisen diese abgeleiteten Modelle hinsichtlich der Invarianten auch eine hohe Kosinusähnlichkeit mit dem ursprünglichen Modell auf.
Anschließend führten sie umfangreiche Tests mit den Modellen der LLaMA-Familie durch, darunter Alpaca und Vicuna, die durch SFT erhalten wurden, Modelle mit erweitertem chinesischen Vokabular, chinesische LLaMA und BiLLa, die durch weiteres Pretrain erhalten wurden, Beaver, die durch RLHF erhalten wurden, und das Multi-Mode-State-Modell Minigpt4 usw .

Die Tabelle zeigt die Kosinusähnlichkeit der Invarianten zwischen den Modellen der LLaMA-Familie. Gleichzeitig zeigt das Bild die für diese 14 Modelle generierten Fingerabdruckbilder. Anhand der Fingerabdruckbilder können wir beurteilen, dass sie aus demselben Modell stammen. Es ist erwähnenswert, dass diese Modelle eine Vielzahl verschiedener Trainingsmethoden wie SFT, weitere Vorschulung, RLHF und Multimodalität abdecken, was die von der vorgeschlagene Methode weiter validiert Team. Robustheit großer Modelle in nachfolgenden verschiedenen Trainingsparadigmen.
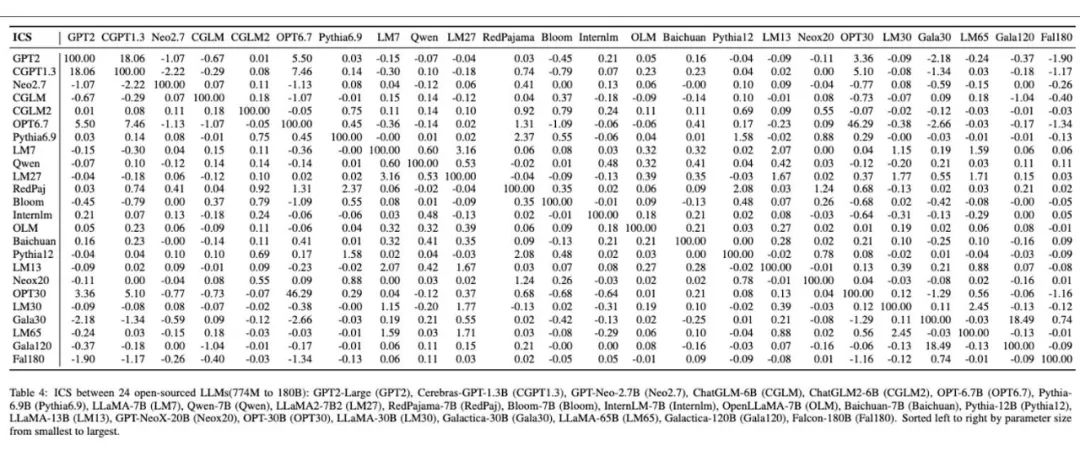
Darüber hinaus zeigt die folgende Abbildung die experimentellen Ergebnisse, die sie an 24 unabhängig trainierten Open-Source-Basismodellen durchgeführt haben. Durch ihre Methode erhält jedes unabhängige Basismodell ein einzigartiges Fingerabdruckbild, das die Vielfalt und Unterschiede der Fingerabdrücke zwischen verschiedenen großen Modellen anschaulich demonstriert. In der Tabelle stimmen die Ergebnisse der Ähnlichkeitsberechnung zwischen diesen Modellen mit den in ihren Fingerabdruckbildern dargestellten Unterschieden überein.

Abschließend überprüfte das Team die Einzigartigkeit und Stabilität der Parameterrichtung des Sprachmodells, das unabhängig in kleinem Maßstab trainiert wurde. Sie trainierten vier GPT-NeoX-350M-Modelle von Grund auf mit einem Zehntel des Pile-Datensatzes vor.
Diese Modelle sind im Aufbau identisch, der einzige Unterschied besteht in der Verwendung unterschiedlicher Zufallszahlen-Seeds. Aus der folgenden Tabelle geht hervor, dass nur der Unterschied in den Zufallszahlen-Seeds zu deutlich unterschiedlichen Modellparameterrichtungen und Fingerabdrücken führt, was die Einzigartigkeit der unabhängig trainierten Sprachmodellparameterrichtungen vollständig veranschaulicht.

Durch den Vergleich der Ähnlichkeit benachbarter Kontrollpunkte stellten sie schließlich fest, dass die Parameter des Modells während des Vortrainingsprozesses allmählich dazu neigten, stabil zu sein. Sie glauben, dass dieser Trend bei längeren Trainingsschritten und größeren Modellen deutlicher wird, was teilweise auch die Wirksamkeit ihrer Methode erklärt.

Das obige ist der detaillierte Inhalt vonGibt es auch Diebe in großen Modellen? Um Ihre Parameter zu schützen, übermitteln Sie das große Modell, um einen „für Menschen lesbaren Fingerabdruck' zu erstellen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist ein Full-Stack-Ingenieur?
- Was ist ein Web-Frontend-Ingenieur? Was macht ein Web-Frontend-Ingenieur?
- Lern-Roadmap für PHP-Full-Stack-Entwicklungsingenieure (Veranschaulichung der Beziehung und Lernsequenz jeder Programmiersprache)
- Acht klassische PHP-Interviewfragen für leitende Ingenieure (mit Antworten)
- Welche Erweiterungen haben Formulardateien und Projektdateien?