
Heim >Technologie-Peripheriegeräte >KI >Alibaba Cloud AnalyticDB (ADB) + LLM: Aufbau eines unternehmensspezifischen Chatbots im AIGC-Zeitalter
Alibaba Cloud AnalyticDB (ADB) + LLM: Aufbau eines unternehmensspezifischen Chatbots im AIGC-Zeitalter

- 王林nach vorne
- 2023-05-23 12:23:471424Durchsuche
Einführung
Wie erstellt man einen unternehmensspezifischen Chatbot, der Sie basierend auf Vektordatenbank + LLM (Large Language Model) besser versteht?
1. Warum benötigt Chatbot ein großes Sprachmodell + Vektordatenbank?
Das schockierendste Technologieprodukt in diesem Frühjahr ist das Aufkommen von ChatGPT. Durch das große Sprachmodell (LLM) können Menschen erkennen, dass generative KI Sprachausdrucksfähigkeiten erreichen kann, die der menschlichen Sprache sehr ähnlich sind Unzählige Praktiker beeilen sich, sich der nächsten Gelegenheit zu widmen, die Ära zu verändern In nur vier Monaten haben die Vereinigten Staaten mehr als 4.000 Finanzierungen für die generative KI-Industrie abgeschlossen. In der nächsten Technologiegeneration ist generative KI zu einem nicht zu vernachlässigenden Teil des Kapitals und der Unternehmen geworden, und zur Unterstützung ihrer Entwicklung ist zunehmend ein höheres Maß an Infrastrukturkapazitäten erforderlich.
Große Modelle können universellere Fragen beantworten, aber wenn sie vertikale Berufsfelder bedienen wollen, wird es Probleme mit unzureichender Wissenstiefe und Aktualität geben Chance? Chancen und vertikale Domain-Dienste aufbauen? Derzeit gibt es zwei Modelle, Fine Tune, ein vertikales Domänenmodell, das hohe umfassende Investitionskosten und eine geringe Aktualisierungshäufigkeit aufweist und nicht für alle Unternehmen geeignet ist Speichern Sie die eigenen Wissensbestände des Unternehmens in der Vektordatenbank und bauen Sie mithilfe großer Modelle und Vektordatenbanken umfassende Dienste in vertikalen Bereichen auf. Das Wesentliche besteht darin, die Datenbank für eine schnelle Entwicklung zu nutzen. Unternehmen können vertikale Kategorien von gesetzlichen Bestimmungen und Präzedenzfällen nutzen, um juristische Technologiedienste in bestimmten Bereichen wie der Rechtsbranche aufzubauen. Beispielsweise baut Harvey, ein Unternehmen für Rechtstechnologie, einen „Copilot für Anwälte“ auf, um die juristischen Redaktions- und Recherchedienste zu verbessern. Das Extrahieren von Wissensdatenbankdokumenten und Echtzeitinformationen des Unternehmens über Vektorfunktionen und deren anschließende Speicherung in einer Vektordatenbank in Kombination mit dem großen LLM-Sprachmodell kann die Antworten von Chatbots (Frage- und Antwortrobotern) professioneller und zeitnaher gestalten und ein Unternehmen aufbauen. spezifischer Chatbot.
WieBasierend auf einem großen SprachmodellLassen Sie Chatbot aktuelle Fragen besser beantworten ? Willkommen im Videokonto „Alibaba Cloud Yaochi Database“, um die DemoDemo anzusehen.
Als Nächstes konzentriert sich dieser Artikel auf die Prinzipien und Prozesse zum Aufbau eines unternehmensspezifischen Chatbots basierend auf einem großen Sprachmodell (LLM) + Vektordatenbank sowie auf die Kernfunktionen von ADB-PG zum Erstellen dieses Szenarios.
2. Was ist eine Vektordatenbank?
In der realen Welt liegen die meisten Daten in unstrukturierter Form vor, beispielsweise Bilder, Audio, Video und Text. Mit dem Aufkommen von Smart Cities, Kurzvideos, personalisierten Produktempfehlungen, visueller Produktsuche und anderen Anwendungen haben diese unstrukturierten Daten ein explosionsartiges Wachstum erfahren. Um diese unstrukturierten Daten verarbeiten zu können, verwenden wir normalerweise Technologie der künstlichen Intelligenz, um die Merkmale dieser unstrukturierten Daten zu extrahieren und in Merkmalsvektoren umzuwandeln. Anschließend analysieren und rufen wir diese Merkmalsvektoren ab, um den Zweck der Analyse der unstrukturierten Daten zu erreichen. Verarbeitung. Daher nennen wir eine Datenbank, die Merkmalsvektoren speichern, analysieren und abrufen kann, eine Vektordatenbank.
Zum schnellen Abrufen von Merkmalsvektoren verwenden Vektordatenbanken im Allgemeinen die technischen Mittel zum Erstellen von Vektorindizes. Die Vektorindizes, auf die wir uns normalerweise beziehen, gehören zu ANNS (Approximate Nearest Neighbors Search, Approximate Nearest Neighbors). Die Kernidee von Search) besteht darin, dass sie nicht mehr darauf beschränkt ist, nur die genauesten Ergebniselemente zurückzugeben, sondern nur nach Datenelementen sucht, die möglicherweise nahe Nachbarn sind, d verbesserte Abrufeffizienz. Dies ist auch der größte Unterschied zwischen Vektordatenbanken und herkömmlichen Datenbanken.
# 🎜 🎜#Derzeit verfügt die Branche in tatsächlichen Produktionsumgebungen über zwei Hauptpraktiken, um den ANNS-Vektorindex bequemer anzuwenden. Die eine besteht darin, den ANNS-Vektorindex separat zu bedienen, um Funktionen zum Erstellen und Abrufen von Vektorindizes bereitzustellen und so eine proprietäre Vektordatenbank zu bilden. Die andere besteht darin, den ANNS-Vektorindex in eine herkömmliche strukturierte Datenbank zu integrieren, um ein DBMS mit Vektorabruffunktionen zu bilden. In tatsächlichen Geschäftsszenarien müssen proprietäre Vektordatenbanken häufig in Verbindung mit anderen herkömmlichen Datenbanken verwendet werden, was zu einigen häufigen Problemen führt, z. B. Datenredundanz, übermäßiger Datenmigration, Datenkonsistenzproblemen usw. Im Vergleich zu einem echten DBMS ist ein proprietäres Die Vektordatenbank erfordert zusätzliche professionelle Wartung, zusätzliche Kosten und sehr begrenzte Abfragesprachenfunktionen, Programmierbarkeit, Skalierbarkeit und Toolintegration.
# 🎜 🎜#Das DBMS, das die Vektorabruffunktion integriert, ist zunächst einmal eine sehr vollständige moderne Datenbankplattform, die die Datenbankfunktionsanforderungen von Anwendungsentwicklern erfüllen kann der Datenbank sowie das Speichern und Abrufen von Vektoren erben die hervorragenden Funktionen von DBMS, wie z. B. Benutzerfreundlichkeit (direkte Verwendung von SQL zur Verarbeitung von Vektoren), Transaktionen, hohe Verfügbarkeit, hohe Skalierbarkeit usw.
3. LLM großes Sprachmodell + ADB-PG: Erstellen Sie einen unternehmensspezifischen Chatbot
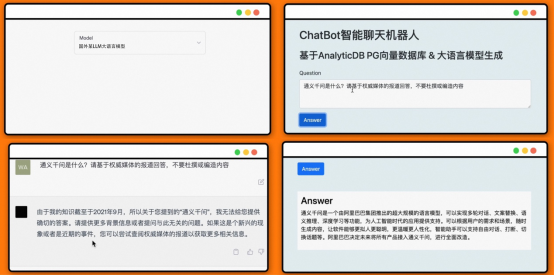
Fall- lokales Wissens-Frage- und Antwortsystem Lassen Sie LLM am Beispiel des vorherigen Demovideos, das das große Sprachmodell LLM und ADB-PG kombiniert, um aktuelle Nachrichten zu kommentieren, antworten „Was ist Tongyi Qianwen?“ Es ist ersichtlich, dass die erhaltene Antwort bedeutungslos ist, wenn wir LLM direkt um eine Antwort bitten, da der LLM-Trainingsdatensatz keinen relevanten Inhalt enthält. Und wenn wir die Vektordatenbank als lokalen Wissensspeicher verwenden und LLM automatisch relevantes Wissen extrahieren lassen, antwortet es richtig: „Was ist Tongyi Qianwen?“.
 # 🎜 🎜#
# 🎜 🎜#
Antwort auf „Was ist Tongyi Qianwen?“ #
- Kombinieren Sie die neuesten Fluginformationen und die neuesten Internet-Check-in-Standorte von Prominenten und andere Reiseführerressourcen, um einen Reiseassistenten zu erstellen. Beantworten Sie beispielsweise Fragen dazu, wohin Sie nächste Woche am besten reisen können und wie am günstigsten ist.
- Rezensionen zu Sportereignissen, Rezensionen zu aktuellen Nachrichten, Zusammenfassung . Wer ist heute der MVP des NBA-Spiels?
- Bildungsbranche, die neueste Interpretation von Bildungs-Hotspots, Sagen Sie mir zum Beispiel, was AIGC ist, was stabile Diffusion ist und wie man sie verwendet usw.
- Finanzbereich, analysieren Sie schnell Finanzberichte in verschiedenen Branchen , um einen Finanzberatungsassistenten zu gründen.
- Kundendienstroboter im professionellen Bereich... #🎜 🎜#
#🎜 🎜# #🎜 🎜#
Das lokale QA-System kombiniert hauptsächlich die Argumentationsfunktionen großer Sprachmodelle und die Speicher- und Abruffunktionen von Vektordatenbanken. Erhalten Sie die relevantesten semantischen Fragmente durch Vektorabruf und lassen Sie auf dieser Grundlage das große Sprachmodell in Kombination mit dem Kontext der relevanten Fragmente Schlussfolgerungen ziehen, um korrekte Schlussfolgerungen zu ziehen. Es gibt zwei Hauptprozesse in diesem Prozess:a Prozess
b. Front-End-Q&A-Prozess
#🎜 🎜# Gleichzeitig basiert die unterste Schicht hauptsächlich auf zwei Modulen:
#🎜 🎜## 🎜🎜#1. Inferenzmodul basierend auf großem Sprachmodell
#🎜🎜 ##🎜 🎜#2. Vektordatenverwaltungsmodul basierend auf Vektordatenbank
#🎜🎜 ##🎜. 🎜#
L#🎜🎜 # Lokales QA-System nach LLM- und VectorStore-Prinzip
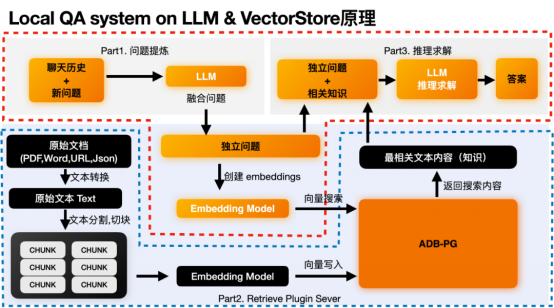
- Schritt 1: Konvertieren Sie zunächst den Textinhalt im Original Dokument Alles extrahieren. Anschließend wird es entsprechend der Semantik in mehrere Abschnitte zerschnitten, die als Textabsätze verstanden werden können, die eine Bedeutung vollständig ausdrücken können. In diesem Prozess können Sie auch einige zusätzliche Aktionen durchführen, wie z. B. die Metadatenextraktion und die Erkennung vertraulicher Informationen. #🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜##STEP2:# Wirf diese Chunks dem Einbettungsmodell zu, um die Einbettung dieser Chunks zu finden. #🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜##Schritt 3:#
- Einbettung und Originalblock zusammen in der Vektordatenbank speichern. Front-End-Q&A-Prozess# 🎜🎜 #Dieser Prozess ist hauptsächlich in drei Teile unterteilt:
- 1. Teil zur Verfeinerung der Frage; relevantes Wissen 3. Schlussfolgerungs- und Lösungsteil. Hier müssen wir uns auf den orangefarbenen Teil konzentrieren. Es mag etwas unklar sein, nur über das Prinzip zu sprechen, aber wir werden das obige Beispiel zur Veranschaulichung verwenden.
# 🎜 🎜#Llokales QA-System auf LLM und VectorStoreTeil1 Fragenverfeinerung# 🎜🎜#
Dieser Teil ist optional und existiert, weil einige Fragen vom Kontext abhängen müssen. Denn die neuen Fragen des Benutzers ermöglichen es LLM möglicherweise nicht, die Absichten des Benutzers zu verstehen.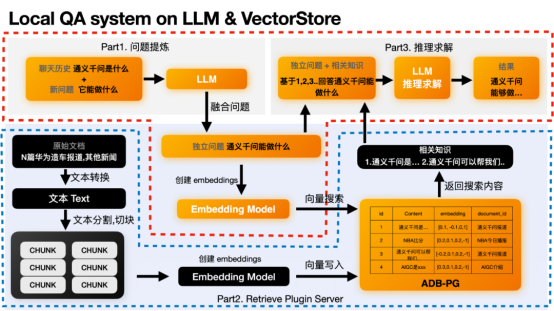
# 🎜 🎜#Zum Beispiel lautet die neue Frage des Benutzers „Was kann es?“ LLM weiß nicht, auf wen es sich bezieht, und muss den vorherigen Chatverlauf kombinieren, z. B. „Was ist Tongyi Qianwen“, um die unabhängige Frage abzuleiten, die der Benutzer beantworten muss: „Was kann Tongyi Qianwen tun?“ LLM kann die vage Frage „Was ist der Nutzen“ nicht richtig beantworten, aber die unabhängige Frage „Wozu dient Tongyi Qianwen?“ richtig beantworten. Wenn Ihr Problem in sich abgeschlossen ist, benötigen Sie diesen Abschnitt nicht.
# 🎜 🎜#Nachdem wir das unabhängige Problem erhalten haben, können wir die Einbettung dieses unabhängigen Problems basierend auf diesem unabhängigen Problem finden. Durchsuchen Sie dann die Vektordatenbank nach den ähnlichsten Vektoren, um die relevantesten Inhalte zu finden. Dieses Verhalten liegt in der Funktionalität des Part2 Retrieval Plugin.
# 🎜 🎜#Teil2 VektorabrufDie unabhängige Problemeinbettungsfunktion wird im text2vec-Modell ausgeführt. Nachdem Sie die Einbettung erhalten haben, können Sie diese Einbettung verwenden, um nach Daten zu suchen, die zuvor in der Vektordatenbank gespeichert wurden. Beispielsweise haben wir den folgenden Inhalt in ADB-PG gespeichert. Über den erhaltenen Vektor können wir den ähnlichsten Inhalt oder das ähnlichste Wissen erhalten, z. B. das erste und das dritte Element. Tongyi Qianwen ist..., Tongyi Qianwen kann uns helfen xxx.
# 🎜 🎜#Teil3 Schlussfolgerung und Lösung
Nachdem wir das relevanteste Wissen erhalten haben, können wir LLM eine Lösungsüberlegung basierend auf dem relevantesten Wissen und unabhängigen Fragen durchführen lassen, um die endgültige Antwort zu erhalten. Hier ist die Antwort auf die Frage „Was nützt Tongyi Qianwen?“ durch Kombination der effektivsten Informationen wie „Tongyi Qianwen ist ...“, „Tongyi Qianwen kann uns helfen xxx“ und so weiter. Letztendlich sieht die Inferenzlösung von GPT ungefähr so aus:
4. ADB-PG: One-Stop-Unternehmenswissensdatenbank mit integrierter Vektorsuche + Volltextsuche #🎜🎜 # #🎜🎜 #
#🎜🎜 #
# 🎜 🎜# Daher kann ADB-PG im AIGC-Szenario als Vektordatenbank verwendet werden, um seine Anforderungen an die Speicherung und den Abruf von Vektoren zu erfüllen, und kann auch die Speicherung und Abfrage anderer strukturierter Daten erfüllen. Es kann auch den Abruf von Volltexten ermöglichen Funktionen für Geschäftsanwendungen in AIGC-Szenarien bieten Lösungen aus einer Hand. Im Folgenden stellen wir die drei Funktionen von ADB-PG im Detail vor: Vektorabruf, Fusionsabruf und Volltextabruf.
# 🎜 🎜#ADB-PG-Vektorabruf- und Fusionsabruffunktionen wurden 2020 zum ersten Mal in der öffentlichen Cloud eingeführt und wurden im Bereich der Gesichtserkennung häufig eingesetzt. Die Vektordatenbank von ADB-PG wird von der Data-Warehouse-Plattform geerbt und bietet daher nahezu alle Vorteile von DBMS, wie ANSISQL, ACID-Transaktionen, hohe Verfügbarkeit, Fehlerbehebung, Wiederherstellung zu einem bestimmten Zeitpunkt, Programmierbarkeit, Skalierbarkeit usw. Gleichzeitig unterstützt es Vektor- und Vektorähnlichkeitssuchen für Skalarproduktdistanzen, Hamming-Distanzen und euklidische Distanzen. Diese Funktionen werden derzeit häufig in der Gesichtserkennung, Produkterkennung und textbasierten semantischen Suche eingesetzt. Da AIGC explodiert, bieten diese Funktionen eine solide Grundlage für textbasierte Chatbots. Darüber hinaus verwendet die ADB-PG-Vektorabruf-Engine auch Intel SIMD-Anweisungen, um einen Vektorähnlichkeitsabgleich äußerst effizient zu erreichen.
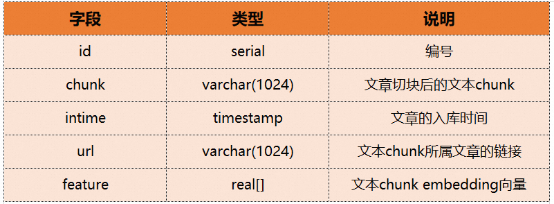
# 🎜 🎜# Im Folgenden veranschaulichen wir anhand eines konkreten Beispiels, wie der Vektorabruf und der Fusionsabruf von ADB-PG verwendet werden. Angenommen, es gibt eine Textwissensdatenbank, die einen Stapel von Artikeln in Blöcke unterteilt und diese in Einbettungsvektoren umwandelt, bevor sie in die Datenbank eingegeben werden. Die Chunks-Tabelle enthält die folgenden Felder: #🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## ## 🎜🎜 #Dann lautet die entsprechende Tabellenerstellungs-DDL wie folgt:
# 🎜🎜## 🎜🎜#Um den Vektorabruf zu beschleunigen, müssen wir auch einen Vektor erstellen Index:
# 🎜 🎜#Gleichzeitig müssen wir zur Beschleunigung vektorstrukturierter Fusionsabfragen auch Indizes für häufig verwendete strukturierte Spalten erstellen: Beim Einfügen von Daten können wir direkt die SQL-Einfügungssyntax verwenden: #🎜 🎜# # 🎜🎜# #🎜 🎜 Nachdem wir die obigen Beispiele gelesen haben, können wir deutlich feststellen, dass die Verwendung von Vektorabruf und Fusionsabruf in ADB-PG genauso bequem ist wie die Verwendung einer herkömmlichen Datenbank, ohne dass eine Lernschwelle besteht. Gleichzeitig haben wir auch viele gezielte Optimierungen für den Vektorabruf vorgenommen, wie z. B. Vektordatenkomprimierung, parallele Erstellung von Vektorindizes, parallelen Vektorabruf mit mehreren Partitionen usw., auf die hier nicht näher eingegangen wird.
# 🎜 🎜#Der Suchteil der Wissensdatenbank umfasst den traditionellen Schlüsselwort-Volltextabruf und den Vektor-Feature-Abruf, der zusätzlich zum wörtlichen Abgleich die Genauigkeit der Abfrage gewährleistet Wissen mit semantischem Matching, reduzieren die Nicht-Ergebnis-Rate, bieten einen umfassenderen Kontext für große Modelle und erleichtern die Zusammenfassung und Induktion großer Sprachmodelle. 5. ZusammenfassungKombiniert mit dem, was zuvor erwähnt wurde Inhalt dieses Artikels, wenn man den sachkundigen Chatbot 人#🎜 vergleicht 🎜# Class Derselbe Chatbot muss die Lern- und Argumentationsfunktionen großer Sprachmodelle mit einer zentralen Datenbank wie ADB-PG kombinieren, die Vektorabruf- und Volltextabruffunktionen enthält (in der die proprietären und neuesten Wissensdokumente der Unternehmensorganisation gespeichert sind). Vektorfunktionen) und bieten bei der Beantwortung von Fragen professionellere und zeitnahe Antworten auf der Grundlage des Wissensinhalts in der Datenbank. 


Ähnlich, wenn wir ein bestimmtes Datum innerhalb des letzten Monats finden müssen. Der Quellartikel von jeden Text. Dann können wir direkt über die Fusionssuche suchen: 
# 🎜 🎜#ADB-PG verfügt außerdem über umfangreiche Volltextsuchfunktionen, die komplexe Kombinationsbedingungen, Ergebnisranking und andere Suchfunktionen unterstützen. Darüber hinaus unterstützt ADB-PG für chinesische Datensätze auch chinesische Wortsegmentierungsfunktionen, mit denen chinesische Texte effizient verarbeitet werden können Und gleichzeitig unterstützt ADB-PG auch die Verwendung von Indizes, um die Volltextabfrage und -analyse zu beschleunigen. Diese Funktionen können auch in AIGC-Geschäftsszenarien vollständig genutzt werden. Beispielsweise kann das Unternehmen einen bidirektionalen Abruf von Wissensdatenbankdokumenten in Kombination mit den oben genannten Funktionen zur Vektorabfrage und Volltextabfrage durchführen.
mit
Das obige ist der detaillierte Inhalt vonAlibaba Cloud AnalyticDB (ADB) + LLM: Aufbau eines unternehmensspezifischen Chatbots im AIGC-Zeitalter. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr