
Heim >Technologie-Peripheriegeräte >KI >LLaVA-1.6, das mit Gemini Pro gleichzieht und die Argumentations- und OCR-Fähigkeiten verbessert, ist zu leistungsstark
LLaVA-1.6, das mit Gemini Pro gleichzieht und die Argumentations- und OCR-Fähigkeiten verbessert, ist zu leistungsstark

- PHPznach vorne
- 2024-02-01 16:51:29685Durchsuche
Im April letzten Jahres veröffentlichten Forscher der University of Wisconsin-Madison, Microsoft Research und der Columbia University gemeinsam LLaVA (Large Language and Vision Assistant). Obwohl LLaVA nur mit einem kleinen multimodalen Befehlsdatensatz trainiert wird, zeigt es bei einigen Proben sehr ähnliche Inferenzergebnisse wie GPT-4. Im Oktober brachten sie dann LLaVA-1.5 auf den Markt, das den SOTA in 11 Benchmarks mit einfachen Modifikationen am ursprünglichen LLaVA aktualisierte. Die Ergebnisse dieses Upgrades sind sehr aufregend und bringen neue Durchbrüche auf dem Gebiet der multimodalen KI-Assistenten.
Das Forschungsteam kündigte die Einführung der LLaVA-1.6-Version an, die zu erheblichen Leistungsverbesserungen in den Bereichen Argumentation, OCR und Weltwissen geführt hat. Diese Version von LLaVA-1.6 übertrifft in mehreren Benchmarks sogar den Gemini Pro.
- Demo-Adresse: https://llava.hliu.cc/
- Projektadresse: https://github.com/haotian-liu/LLaVA
Im Vergleich zu LLaVA-1.5 weist LLaVA-1.6 die folgenden Verbesserungen auf:
- Erhöht die Auflösung des Eingabebilds um das Vierfache, unterstützt drei Seitenverhältnisse, bis zu 672x672, 336x1344, 1344x336 Auflösung. Dadurch kann LLaVA-1.6 mehr visuelle Details erfassen.
- LLaVA-1.6 erhält bessere visuelle Argumentation und OCR-Fähigkeiten durch verbesserte visuelle Anweisungen zur Anpassung der Datenmischung.
- Bessere visuelle Dialoge, mehr Szenen, die verschiedene Anwendungen abdecken. LLaVA-1.6 beherrscht mehr Weltwissen und verfügt über bessere logische Denkfähigkeiten.
- Verwenden Sie SGLang für eine effiziente Bereitstellung und Inferenz.

Bildquelle: https://twitter.com/imhaotian/status/1752621754273472927
LLaVA-1.6 ist auf Basis von LLaVA-1.5 verfeinert und optimiert. Es behält das einfache Design und die effizienten Datenverarbeitungsfunktionen von LLaVA-1.5 bei und verwendet weiterhin weniger als 1 Million visuelle Befehlsoptimierungsbeispiele. Durch den Einsatz von 32 A100-Grafikkarten wurde das größte 34B-Modell in etwa einem Tag trainiert. Darüber hinaus nutzt LLaVA-1.6 1,3 Millionen Datenproben und die Kosten für Rechen-/Trainingsdaten betragen nur das 100- bis 1000-fache der Kosten anderer Methoden. Diese Verbesserungen machen LLaVA-1.6 zu einer effizienteren und kostengünstigeren Version.
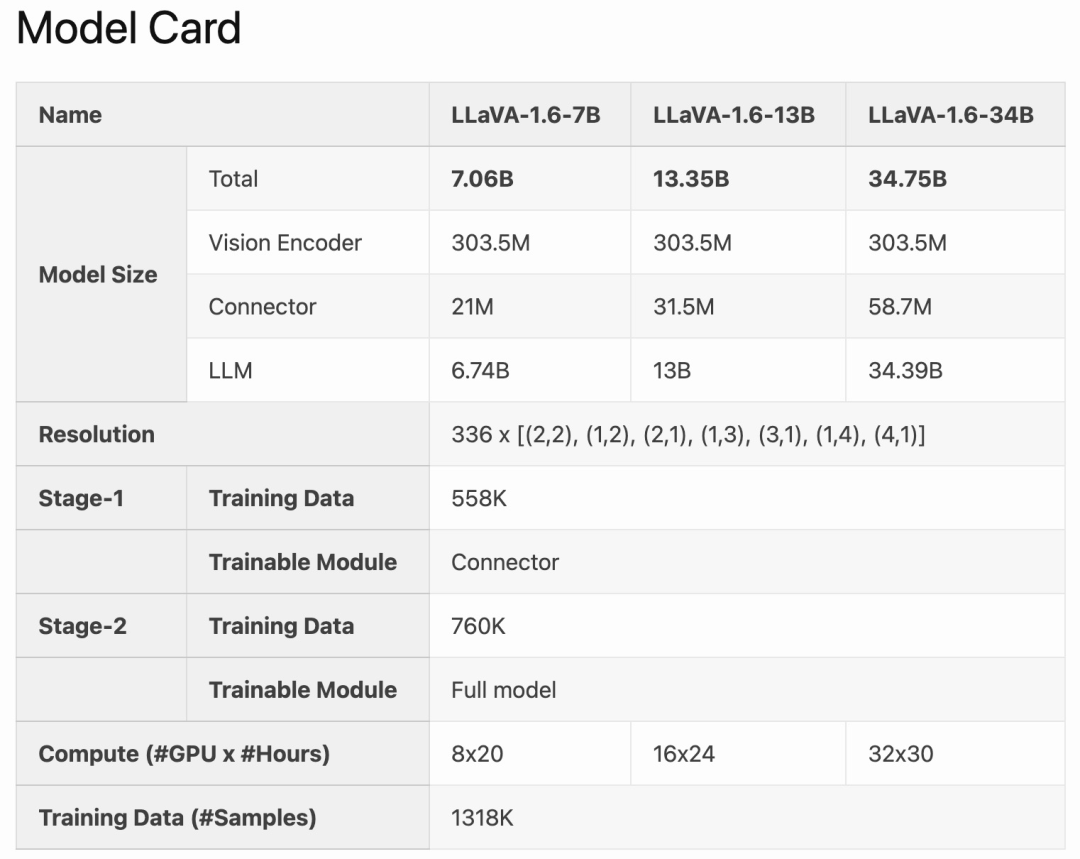
Im Vergleich zu Open-Source-LMMs wie CogVLM oder Yi-VL erreicht LLaVA-1.6 SOTA-Leistung. Im Vergleich zu kommerziellen Produkten ist LLaVA-1.6 mit Gemini Pro vergleichbar und in ausgewählten Benchmarks besser als Qwen-VL-Plus.
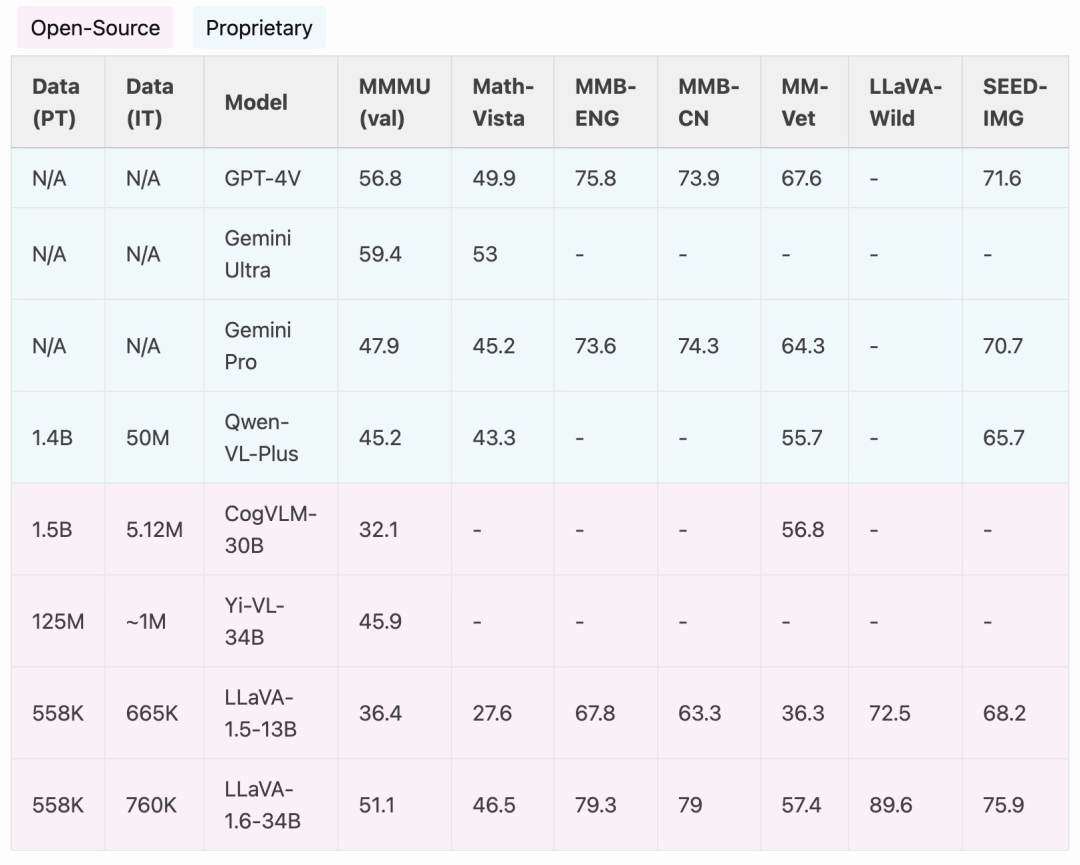
Es ist erwähnenswert, dass LLaVA-1.6 starke chinesische Zero-Shot-Fähigkeiten aufweist und SOTA-Leistung beim multimodalen Benchmark MMBench-CN erreicht.
Methodenverbesserungen
Dynamische hohe Auflösung
Das Forschungsteam hat das LLaVA-1.6-Modell mit hoher Auflösung entworfen, um seine Dateneffizienz aufrechtzuerhalten. Durch die Bereitstellung hochauflösender Bilder und detailgetreuer Darstellungen verbessert sich die Fähigkeit des Modells, komplexe Details in Bildern wahrzunehmen, deutlich. Es reduziert die Halluzination des Modells, wenn es mit Bildern mit niedriger Auflösung konfrontiert wird, d. h. das Erraten des imaginären visuellen Inhalts.
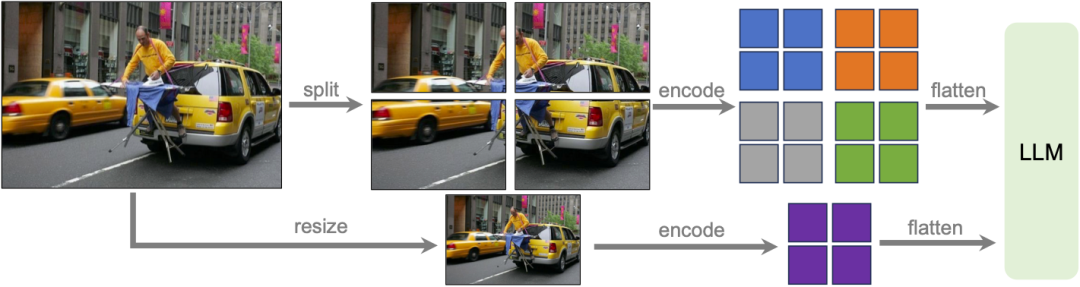
Datenmischung
Hochwertige Benutzeranweisungsdaten. Die in der Studie definierte Definition qualitativ hochwertiger visueller Anweisungen zur Befolgung von Daten hängt von zwei Hauptkriterien ab: erstens von der Vielfalt der Aufgabenanweisungen, die eine angemessene Darstellung des breiten Spektrums an Benutzerabsichten gewährleisten, die in realen Szenarien, insbesondere während, auftreten können die Modellbereitstellungsphase. Zweitens ist die Priorisierung der Antworten von entscheidender Bedeutung, um positives Benutzerfeedback einzuholen.
Daher wurden in der Studie zwei Datenquellen berücksichtigt:
Vorhandene GPT-V-Daten (LAION-GPT-V und ShareGPT-4V);
Um einen besseren visuellen Dialog in mehr Szenarien weiter zu fördern, sammelte das Forschungsteam einen kleinen 15K-Datensatz zur Optimierung visueller Anweisungen, der verschiedene Anwendungen abdeckte, sorgfältig gefilterte Proben, die möglicherweise Datenschutzprobleme haben oder schädlich sein könnten, und generierte mithilfe von GPT-4V eine Reaktion.
Multimodale Dokument-/Diagrammdaten. (1) Entfernen Sie TextCap aus den Trainingsdaten, da das Forschungsteam erkannt hat, dass TextCap denselben Trainingsbildsatz wie TextVQA verwendet. Dies ermöglichte es dem Forschungsteam, die Zero-Shot-OCR-Fähigkeiten des Modells bei der Bewertung von TextVQA besser zu verstehen. Um die OCR-Fähigkeiten des Modells aufrechtzuerhalten und weiter zu verbessern, wurde in dieser Studie TextCap durch DocVQA und SynDog-EN ersetzt. (2) Mit Qwen-VL-7B-Chat fügt diese Studie außerdem ChartQA, DVQA und AI2D hinzu, um Diagramme und Diagramme besser zu verstehen.
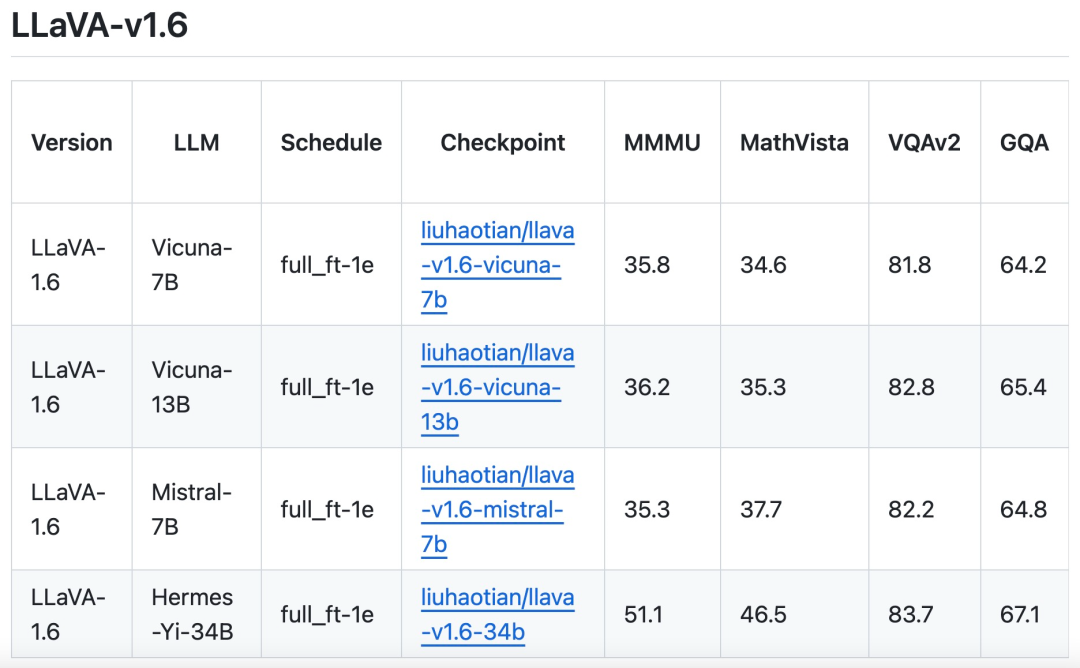
Das Forschungsteam gab außerdem an, dass es zusätzlich zu Vicuna-1.5 (7B und 13B) auch die Einführung weiterer LLM-Lösungen in Betracht zieht, darunter Mistral-7B und Nous-Hermes-2-Yi-34B, um LLaVA zu ermöglichen Unterstützen Sie ein breiteres Benutzerspektrum und mehr Szenen.
Das obige ist der detaillierte Inhalt vonLLaVA-1.6, das mit Gemini Pro gleichzieht und die Argumentations- und OCR-Fähigkeiten verbessert, ist zu leistungsstark. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Welches Farbmodell wird von Computermonitoren verwendet?
- Was sind in der Datenbanktechnologie die vier wichtigsten Datenmodelle?
- Anwendung und Erforschung der Branchensuche basierend auf einem vorab trainierten Sprachmodell
- Integrieren Sie effektiv Sprachmodelle, graphische neuronale Netze und das Textgraph-Trainings-Framework GLEM, um neue SOTA zu erreichen
- Die internen Tests von Kimi Chat beginnen, Volcano Engine bietet Beschleunigungslösungen und unterstützt das Training und die Inferenz des Moonshot AI-Großmodelldienstes