Large Scale Visual Language Model (LVLM) kann die Leistung durch Skalieren des Modells verbessern. Allerdings erhöht die Vergrößerung der Parametergröße die Trainings- und Inferenzkosten, da die Berechnung jedes Tokens alle Modellparameter aktiviert.
Forscher der Peking-Universität, der Sun Yat-sen-Universität und anderen Institutionen schlugen gemeinsam eine neue Trainingsstrategie namens MoE-Tuning vor, um das Problem der Leistungsverschlechterung im Zusammenhang mit multimodalem Lernen und Modellsparsity zu lösen. MoE-Tuning ist in der Lage, spärliche Modelle mit überraschend vielen Parametern, aber konstantem Rechenaufwand zu erstellen. Darüber hinaus schlugen die Forscher auch eine neue, auf MoE basierende LVLM-Architektur mit geringer Dichte vor, das sogenannte MoE-LLaVA-Framework. In diesem Rahmen werden nur die Top-k-Experten durch den Routing-Algorithmus aktiviert und die verbleibenden Experten bleiben inaktiv. Auf diese Weise kann das MoE-LLaVA-Framework die Ressourcen des Expertennetzwerks während des Bereitstellungsprozesses effizienter nutzen. Diese Forschungsergebnisse liefern neue Lösungen zur Lösung der Herausforderungen des multimodalen Lernens und der Modellsparsität von LVLM-Modellen.

Papieradresse: https://arxiv.org/abs/2401.15947
Projektadresse: https://github.com/PKU-YuanGroup/MoE-LLaVA
Demoadresse: https://huggingface.co/spaces/LanguageBind/MoE-LLaVA
Papiertitel: MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
MoE-LLaVA hat nur 3B spärliche Aktivierungsparameter und Leistung Es entspricht jedoch LLaVA-1.5-7B in verschiedenen Datensätzen zum visuellen Verständnis und übertrifft sogar LLaVA-1.5-13B im Benchmark-Test zur Objektillusion. Durch MoE-LLaVA zielt diese Studie darauf ab, einen Maßstab für spärliche LVLMs zu etablieren und wertvolle Erkenntnisse für zukünftige Forschung zur Entwicklung effizienterer und effektiverer multimodaler Lernsysteme zu liefern. Das MoE-LLaVA-Team hat alle Daten, Codes und Modelle offengelegt.
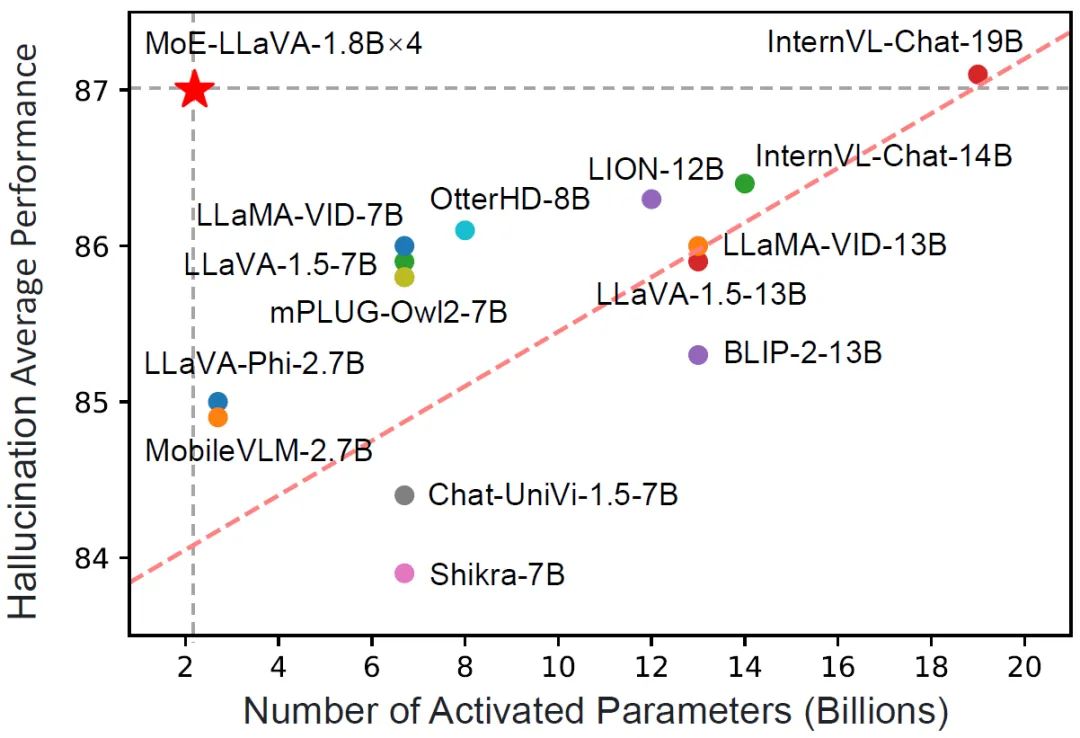
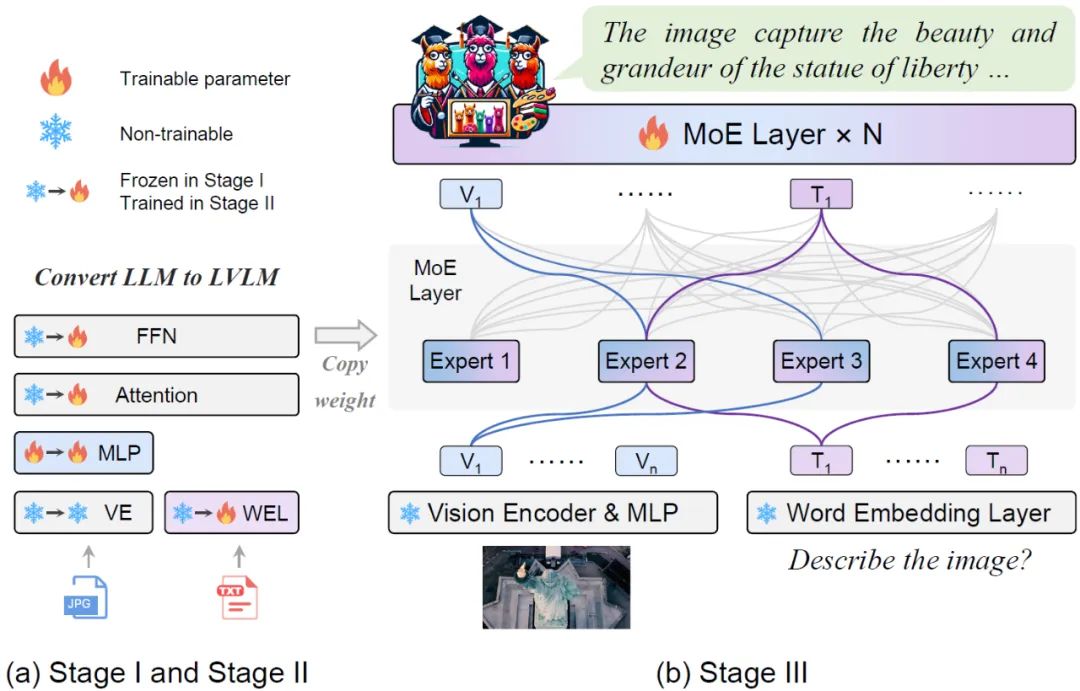
Abbildung 1 Vergleich von MoE-LLaVA und anderen LVLM bei der HalluzinationsleistungMoE-LLaVA übernimmt eine Bühnentrainingsstrategie. Wie in Abbildung 2 dargestellt, verarbeitet der Vision-Encoder das Eingabebild, um die visuelle Token-Sequenz zu erhalten. Eine Projektionsebene wird verwendet, um visuelle Token in für das LLM akzeptable Dimensionen abzubilden. In ähnlicher Weise wird der mit dem Bild gepaarte Text durch eine Worteinbettungsebene projiziert, um das Sequenztext-Token zu erhalten.
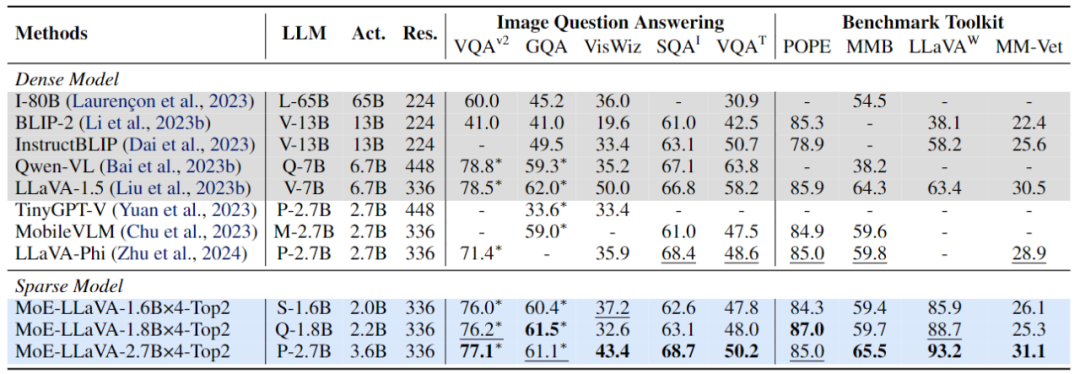
Phase 1: Wie in Abbildung 2 dargestellt, besteht das Ziel von Phase 1 darin, das visuelle Token an LLM anzupassen und LLM die Fähigkeit zu geben, die Entitäten im Bild zu verstehen. MoE-LLaVA verwendet ein MLP, um Bild-Tokens in die Eingabedomäne von LLM zu projizieren, was bedeutet, dass kleine Bild-Patches von LLM als Pseudotext-Tokens behandelt werden. In dieser Phase wird LLM darauf trainiert, Bilder zu beschreiben und die Bildsemantik auf höherer Ebene zu verstehen. Die MoE-Schicht wird zu diesem Zeitpunkt noch nicht auf LVLM angewendet. Abbildung 3 Spezifischerer Trainingsrahmen und TrainingsstrategiePhase 2: Die Verwendung multimodaler Befehlsdaten zur Feinabstimmung ist in dieser Phase eine Schlüsseltechnologie zur Verbesserung der Leistungsfähigkeit und Steuerbarkeit großer Modelle LLM LVLM optimiert für multimodales Verständnis. Zu diesem Zeitpunkt fügt die Forschung komplexere Anweisungen hinzu, einschließlich fortgeschrittener Aufgaben wie logisches Denken in Bildern und Texterkennung, die ein stärkeres multimodales Verständnis des Modells erfordern. Im Allgemeinen wird das LVLM des dichten Modells zu diesem Zeitpunkt trainiert. Das Forschungsteam stellte jedoch fest, dass es schwierig ist, das LLM in LVLM umzuwandeln und gleichzeitig das Modell zu schonen. Daher wird MoE-LLaVA die Gewichte der zweiten Stufe als Initialisierung der dritten Stufe verwenden, um die Schwierigkeit des Lernens mit spärlichem Modell zu verringern. Phase 3: MoE-LLaVA kopiert mehrere Kopien von FFN als Initialisierungsgewichte des Expertensatzes. Wenn visuelle Token und Text-Token in die MoE-Schicht eingespeist werden, berechnet der Router das passende Gewicht jedes Tokens und der Experten, und dann wird jedes Token zur Verarbeitung an die Top-K-Experten mit den meisten Übereinstimmungen gesendet und schließlich basierend auf dem Gewicht des Routers Die gewichtete Summe wird in der Ausgabe aggregiert. Wenn die Top-K-Experten aktiviert werden, bleiben die verbleibenden Experten inaktiv, und dieses Modell stellt MoE-LLaVA mit unendlich vielen möglichen spärlichen Pfaden dar. Da MoE-LLaVA das erste spärliche Modell auf LVLM-Basis ist, das mit einem Soft-Router ausgestattet ist, fasst diese Studie das Vorgängermodell als dichtes Modell zusammen. Das Forschungsteam überprüfte die Leistung von MoE-LLaVA anhand von 5 Bild-Frage- und Antwort-Benchmarks und berichtete über die Anzahl der aktivierten Parameter und die Bildauflösung. Im Vergleich zur SOTA-Methode LLaVA-1.5 weist MoE-LLaVA-2.7B×4 starke Bildverständnisfähigkeiten auf und seine Leistung kommt LLaVA-1.5 bei 5 Benchmarks sehr nahe. Unter diesen verwendet MoE-LLaVA 3,6B spärliche Aktivierungsparameter und übertrifft LLaVA-1,5-7B auf SQAI um 1,9 %. Es ist erwähnenswert, dass aufgrund der spärlichen Struktur von MoE-LLaVA nur 2,6B Aktivierungsparameter erforderlich sind, um IDEFICS-80B vollständig zu übertreffen. Abbildung 4 Leistung von MoE-LLaVA bei 9 Benchmarks × 4 übertrifft TinyGPT-V um 27,5 % bzw. 10 % in GQA und VisWiz unter vergleichbaren Aktivierungsparametern, was die starke Verständnisfähigkeit von MoE-LLaVA im natürlichen Sehen unterstreicht.
Um die multimodalen Verständnisfähigkeiten von MoE-LLaVA umfassender zu überprüfen, wurde in dieser Studie die Modellleistung anhand von 4 Benchmark-Toolkits bewertet. Das Benchmark-Toolkit ist ein Toolkit zur Überprüfung, ob das Modell Fragen in natürlicher Sprache beantworten kann. Normalerweise sind die Antworten offen und haben keine feste Vorlage. Wie in Abbildung 4 dargestellt, übertrifft MoE-LLaVA-1.8B×4 Qwen-VL, das eine größere Bildauflösung verwendet. Diese Ergebnisse zeigen, dass MoE-LLaVA, ein spärliches Modell, eine Leistung erzielen kann, die mit der von dichten Modellen mit weniger Aktivierungsparametern vergleichbar ist oder diese sogar übertrifft.
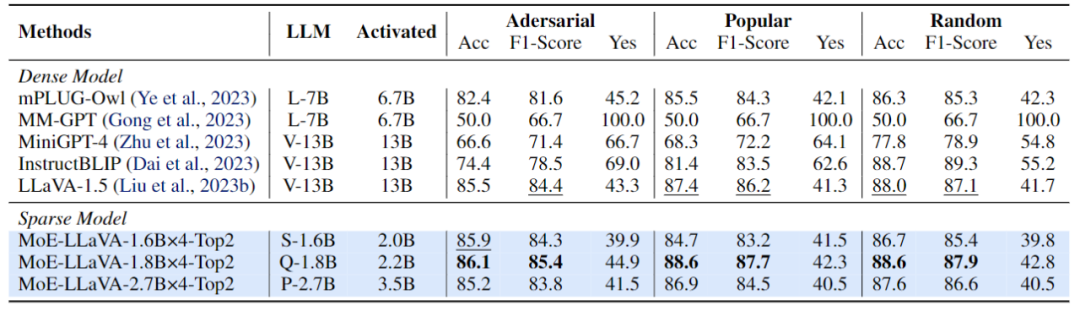
Abbildung 5 Leistungsbewertung von MoE-LLaVA zur Erkennung illusorischer ObjekteDiese Studie verwendet die POPE-Bewertungspipeline, um die Objektillusion von MoE-LLaVA zu überprüfen . MoE-LLaVA weist die beste Leistung auf, was bedeutet, dass MoE-LLaVA dazu neigt, Objekte zu generieren, die mit dem gegebenen Bild übereinstimmen. Insbesondere übertraf MoE-LLaVA-1.8B×4 LLaVA mit einem Aktivierungsparameter von 2.2B. Darüber hinaus stellte das Forschungsteam fest, dass das Ja-Verhältnis von MoE-LLaVA in einem relativ ausgeglichenen Zustand ist, was zeigt, dass das spärliche Modell MoE-LLaVA basierend auf dem Problem korrektes Feedback geben kann.
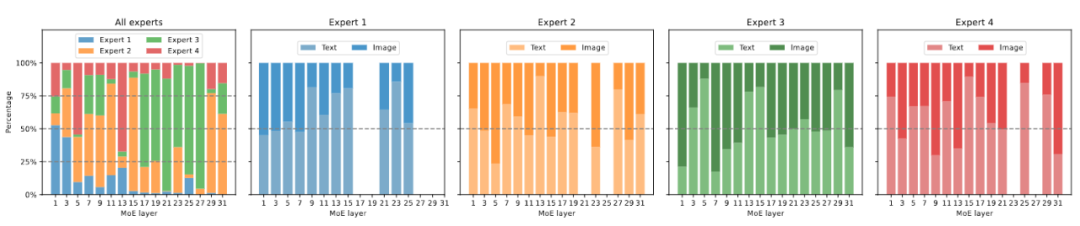
Abbildung 6 Visualisierung der Expertenlast Abbildung 6 zeigt die Expertenlast von MoE-LLaVA-2.7B×4-Top2 auf ScienceQA. Insgesamt ist die Belastung der Experten in allen MoE-Schichten während der Trainingsinitialisierung relativ ausgeglichen. Wenn das Modell jedoch allmählich spärlicher wird, steigt die Expertenlast auf den Schichten 17 bis 27 plötzlich an und deckt sogar fast alle Token ab. Für die flachen Schichten 5-11 arbeiten hauptsächlich die Experten 2, 3 und 4 zusammen. Es ist erwähnenswert, dass Experte 1 fast ausschließlich an den Schichten 1–3 arbeitet und mit zunehmender Tiefe des Modells nach und nach aus der Arbeit aussteigt. Daher haben MoE-LLaVA-Experten ein spezifisches Muster erlernt, das eine fachmännische Arbeitsteilung nach bestimmten Regeln ermöglicht.
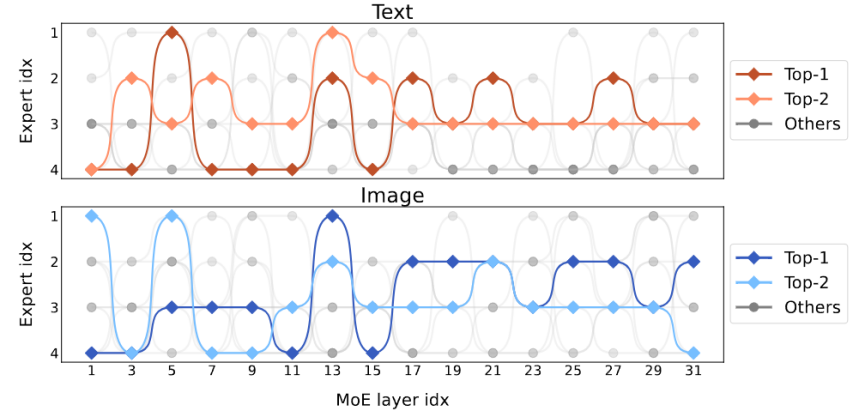
Abbildung 7 Modalverteilungsvisualisierung Abbildung 7 zeigt die Modalverteilung verschiedener Experten. Die Studie ergab, dass die Routing-Verteilung von Text und Bild sehr ähnlich ist. Wenn beispielsweise Experte 3 hart an den Ebenen 17 bis 27 arbeitet, ist der Anteil von Text und Bild, der von ihm verarbeitet wird, ähnlich. Dies zeigt, dass MoE-LLaVA keine offensichtliche Präferenz für die Modalität hat. Die Studie beobachtete auch das Verhalten von Experten auf Token-Ebene und verfolgte die Flugbahnen aller Token im spärlichen Netzwerk bei nachgelagerten Aufgaben. Für alle aktivierten Text- und Bildpfade verwendete diese Studie die PCA-Dimensionalitätsreduzierung, um die zehn Hauptpfade zu erhalten, wie in Abbildung 8 dargestellt. Das Forschungsteam stellte fest, dass MoE-LLaVA für ein unsichtbares Text- oder Bild-Token immer lieber die Experten 2 und 3 entsendet, um die Tiefe des Modells zu verwalten. Die Experten 1 und 4 beschäftigen sich in der Regel mit initialisierten Token. Diese Ergebnisse können uns helfen, das Verhalten spärlicher Modelle beim multimodalen Lernen besser zu verstehen und unbekannte Möglichkeiten zu erkunden.
Abbildung 8 Aktivierungspfad-VisualisierungDas obige ist der detaillierte Inhalt vonSpärliche große multimodale Modelle, und das 3B-Modell MoE-LLaVA ist mit LLaVA-1.5-7B vergleichbar. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!