
Heim >Technologie-Peripheriegeräte >KI >Entdeckung des NVIDIA-Inferenz-Frameworks für große Modelle: TensorRT-LLM
Entdeckung des NVIDIA-Inferenz-Frameworks für große Modelle: TensorRT-LLM

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-01 17:24:231238Durchsuche
1. Produktpositionierung von TensorRT-LLM
TensorRT-LLM ist eine von NVIDIA entwickelte skalierbare Inferenzlösung für große Sprachmodelle (LLM). Es erstellt, kompiliert und führt Berechnungsdiagramme auf der Grundlage des TensorRT-Deep-Learning-Kompilierungsframeworks aus und stützt sich auf die effiziente Kernels-Implementierung in FastTransformer. Darüber hinaus nutzt es NCCL für die Kommunikation zwischen Geräten. Entwickler können Betreiber entsprechend der Technologieentwicklung und Nachfrageunterschieden an spezifische Anforderungen anpassen, beispielsweise durch die Entwicklung maßgeschneiderter GEMM auf Basis von Entermessern. TensorRT-LLM ist die offizielle Inferenzlösung von NVIDIA, die sich der Bereitstellung hoher Leistung und der kontinuierlichen Verbesserung ihrer Praktikabilität verschrieben hat.

TensorRT-LLM ist Open Source auf GitHub und ist in zwei Zweige unterteilt: Release-Zweig und Dev-Zweig. Der Release-Zweig wird einmal im Monat aktualisiert, während der Dev-Zweig häufiger Funktionen aus offiziellen oder Community-Quellen aktualisiert, um Entwicklern die Erfahrung und Bewertung der neuesten Funktionen zu erleichtern. Die folgende Abbildung zeigt die Framework-Struktur von TensorRT-LLM. Mit Ausnahme des grünen TensorRT-Kompilierungsteils und der Kernel mit Hardwareinformationen sind andere Teile Open Source.

TensorRT-LLM bietet außerdem eine Pytorch-ähnliche API, um die Lernkosten für Entwickler zu senken, und stellt viele vordefinierte Modelle zur Verwendung durch Benutzer bereit.

Aufgrund der Größe großer Sprachmodelle kann die Inferenz möglicherweise nicht auf einer einzelnen Grafikkarte abgeschlossen werden. Daher bietet TensorRT-LLM zwei parallele Mechanismen: Tensor-Parallelität und Pipeline-Parallelität, um die Argumentation mehrerer Karten oder mehrerer Maschinen zu unterstützen . Diese Mechanismen ermöglichen die Aufteilung des Modells in mehrere Teile und die Verteilung auf mehrere Grafikkarten oder Maschinen zur parallelen Berechnung, um die Inferenzleistung zu verbessern. Tensor-Parallelität ermöglicht paralleles Rechnen, indem Modellparameter auf verschiedene Geräte verteilt und die Ausgabe verschiedener Teile gleichzeitig berechnet wird. Pipeline-Parallelität unterteilt das Modell in mehrere Stufen, die parallel auf verschiedenen Geräten berechnet werden, und leitet die Ausgabe an die nächste Stufe weiter, wodurch das Gesamtergebnis erreicht wird von LLM
 TensorRT-LLM ist ein leistungsstarkes Tool mit umfassender Modellunterstützung und Inferenzfunktionen mit geringer Präzision.
Erstens unterstützt TensorRT-LLM gängige große Sprachmodelle, einschließlich Modellanpassungen, die von Entwicklern wie Qwen (Qianwen) durchgeführt wurden, und wurde in die offizielle Unterstützung aufgenommen. Dies bedeutet, dass Benutzer diese vordefinierten Modelle problemlos erweitern oder anpassen und sie schnell und einfach auf ihre eigenen Projekte anwenden können.
Zweitens verwendet TensorRT-LLM standardmäßig die FP16/BF16-Präzisionsinferenzmethode. Diese Argumentation mit geringer Genauigkeit kann nicht nur die Argumentationsleistung verbessern, sondern auch die Quantisierungsmethoden der Branche nutzen, um den Hardware-Durchsatz weiter zu optimieren. Durch die Reduzierung der Genauigkeit des Modells kann TensorRT-LLM die Geschwindigkeit und Effizienz der Inferenz erheblich verbessern, ohne zu große Einbußen bei der Genauigkeit hinnehmen zu müssen.
Zusammenfassend lässt sich sagen, dass TensorRT-LLM aufgrund seiner umfassenden Modellunterstützung und seiner Inferenzfunktionen mit geringer Präzision ein sehr praktisches Werkzeug ist. Ob für Entwickler oder Forscher, TensorRT-LLM kann effiziente Inferenzlösungen bereitstellen, die ihnen helfen, eine bessere Leistung in Deep-Learning-Anwendungen zu erzielen.
TensorRT-LLM ist ein leistungsstarkes Tool mit umfassender Modellunterstützung und Inferenzfunktionen mit geringer Präzision.
Erstens unterstützt TensorRT-LLM gängige große Sprachmodelle, einschließlich Modellanpassungen, die von Entwicklern wie Qwen (Qianwen) durchgeführt wurden, und wurde in die offizielle Unterstützung aufgenommen. Dies bedeutet, dass Benutzer diese vordefinierten Modelle problemlos erweitern oder anpassen und sie schnell und einfach auf ihre eigenen Projekte anwenden können.
Zweitens verwendet TensorRT-LLM standardmäßig die FP16/BF16-Präzisionsinferenzmethode. Diese Argumentation mit geringer Genauigkeit kann nicht nur die Argumentationsleistung verbessern, sondern auch die Quantisierungsmethoden der Branche nutzen, um den Hardware-Durchsatz weiter zu optimieren. Durch die Reduzierung der Genauigkeit des Modells kann TensorRT-LLM die Geschwindigkeit und Effizienz der Inferenz erheblich verbessern, ohne zu große Einbußen bei der Genauigkeit hinnehmen zu müssen.
Zusammenfassend lässt sich sagen, dass TensorRT-LLM aufgrund seiner umfassenden Modellunterstützung und seiner Inferenzfunktionen mit geringer Präzision ein sehr praktisches Werkzeug ist. Ob für Entwickler oder Forscher, TensorRT-LLM kann effiziente Inferenzlösungen bereitstellen, die ihnen helfen, eine bessere Leistung in Deep-Learning-Anwendungen zu erzielen.
Eine weitere Funktion ist die Implementierung des FMHA-Kernels (Fused Multi-Head Attention). Da der zeitaufwändigste Teil von Transformer die Berechnung der Selbstaufmerksamkeit ist, hat der Beamte FMHA entwickelt, um die Berechnung der Selbstaufmerksamkeit zu optimieren, und verschiedene Versionen mit Akkumulatoren von fp16 und fp32 bereitgestellt. Darüber hinaus wird neben der Geschwindigkeitsverbesserung auch die Speichernutzung stark reduziert. Wir bieten auch eine auf Flash-Aufmerksamkeit basierende Implementierung an, mit der die Sequenzlänge auf beliebige Längen erweitert werden kann.
Das Folgende sind die detaillierten Informationen von FMHA, wobei MQA für Multi Query Attention und GQA für Group Query Attention steht.

Ein weiterer Kernel ist MMHA (Masked Multi-Head Attention). FMHA wird hauptsächlich für Berechnungen in der Kontextphase verwendet, während MMHA hauptsächlich für eine Beschleunigung der Aufmerksamkeit in der Generierungsphase sorgt und Unterstützung für Volta und nachfolgende Architekturen bietet. Im Vergleich zur Implementierung von FastTransformer wird TensorRT-LLM weiter optimiert und die Leistung um bis zu 2x verbessert.

Ein weiteres wichtiges Merkmal ist die Quantisierungstechnologie, die eine Inferenzbeschleunigung mit geringerer Präzision erreicht. Häufig verwendete Quantisierungsmethoden werden hauptsächlich in PTQ (Post Training Quantization) und QAT (Quantization-aware Training) unterteilt. Für TensorRT-LLM ist die Argumentationslogik dieser beiden Quantisierungsmethoden dieselbe. Ein wichtiges Merkmal der LLM-Quantifizierungstechnologie ist die gemeinsame Gestaltung des Algorithmusdesigns und der technischen Implementierung, dh die Eigenschaften der Hardware müssen zu Beginn des Entwurfs der entsprechenden Quantifizierungsmethode berücksichtigt werden. Andernfalls wird die erwartete Verbesserung der Inferenzgeschwindigkeit möglicherweise nicht erreicht.

Die PTQ-Quantifizierungsschritte in TensorRT sind im Allgemeinen in die folgenden Schritte unterteilt: Zuerst wird das Modell quantifiziert und dann werden die Gewichte und das Modell in die TensorRT-LLM-Darstellung umgewandelt. Für einige benutzerdefinierte Vorgänge müssen Benutzer auch ihre eigenen Kernel schreiben. Zu den häufig verwendeten PTQ-Quantifizierungsmethoden gehören INT8 Weight-Only, SmoothQuant, GPTQ und AWQ, bei denen es sich um typische Co-Design-Methoden handelt.

INT8-Gewicht-nur quantisiert das Gewicht direkt auf INT8, der Aktivierungswert bleibt jedoch FP16. Der Vorteil dieser Methode besteht darin, dass der Modellspeicher um das Zweifache reduziert und die Speicherbandbreite zum Laden von Gewichten halbiert wird, wodurch der Zweck einer Verbesserung der Inferenzleistung erreicht wird. Diese Methode wird in der Branche als W8A16 bezeichnet, das heißt, das Gewicht ist INT8 und der Aktivierungswert ist FP16/BF16 – gespeichert mit INT8-Präzision und berechnet im FP16/BF16-Format. Diese Methode ist intuitiv, verändert die Gewichte nicht, ist einfach zu implementieren und weist eine gute Generalisierungsleistung auf.

Die zweite Quantifizierungsmethode ist SmoothQuant, die gemeinsam von NVIDIA und der Community entwickelt wurde. Es wird beobachtet, dass Gewichte normalerweise der Gaußschen Verteilung folgen und leicht zu quantisieren sind, es jedoch Ausreißer bei den Aktivierungswerten gibt und die Nutzung von Quantisierungsbits nicht hoch ist.

SmoothQuant komprimiert die entsprechende Verteilung, indem es zunächst den Aktivierungswert glättet, also durch eine Skala dividiert. Gleichzeitig müssen die Gewichte mit derselben Skala multipliziert werden, um die Äquivalenz sicherzustellen. Anschließend können sowohl Gewichte als auch Aktivierungen quantifiziert werden. Die entsprechende Speicher- und Berechnungsgenauigkeit kann INT8 oder FP8 sein, und INT8 oder FP8 TensorCore kann für die Berechnung verwendet werden. In Bezug auf Implementierungsdetails unterstützen Gewichte die Quantifizierung pro Tensor und pro Kanal, und Aktivierungswerte unterstützen die Quantifizierung pro Tensor und pro Token.
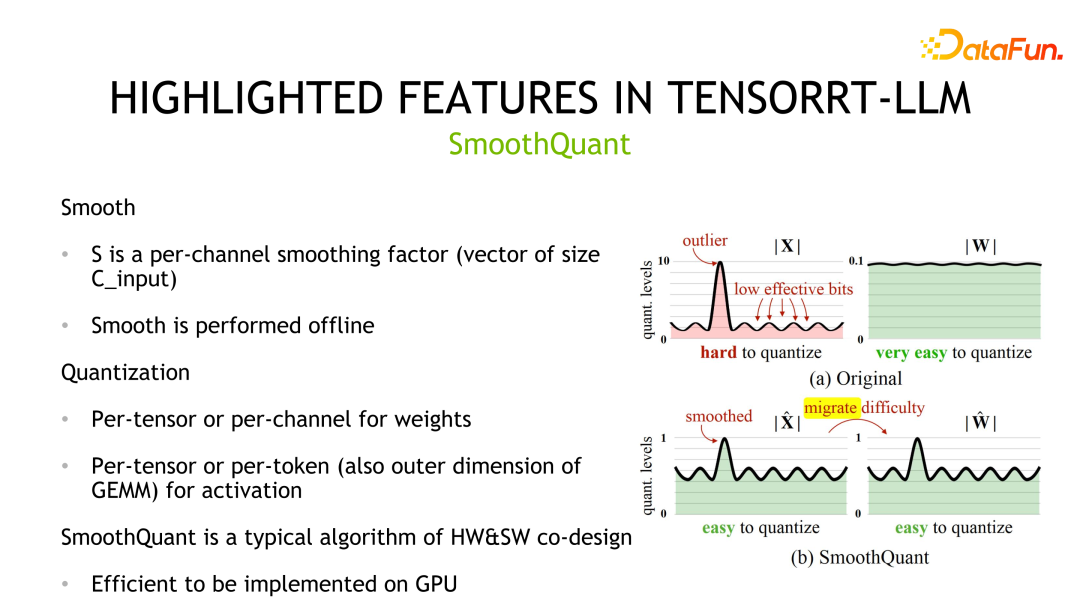
Die dritte Quantisierungsmethode ist GPTQ, eine schichtweise Quantisierungsmethode, die durch Minimierung des Rekonstruktionsverlusts implementiert wird. GPTQ ist eine reine Gewichtungsmethode und die Berechnung verwendet das FP16-Datenformat. Diese Methode wird bei der Quantisierung großer Modelle verwendet. Da die Quantisierung selbst relativ teuer ist, hat der Autor einige Tricks entwickelt, um die Kosten der Quantisierung selbst zu reduzieren, z. B. Lazy Batch-Updates und die Quantisierung der Gewichte aller Zeilen in derselben Reihenfolge. GPTQ kann auch in Verbindung mit anderen Methoden wie Gruppierungsstrategien verwendet werden. Darüber hinaus bietet TensorRT-LLM unterschiedliche Implementierungsoptimierungsleistungen für verschiedene Situationen. Insbesondere wenn die Stapelgröße klein ist, wird der Cuda-Kern zur Implementierung verwendet. Wenn die Stapelgröße hingegen groß ist, wird der Tensor-Kern zur Implementierung verwendet.

Die vierte Quantifizierungsmethode ist AWQ. Bei dieser Methode wird berücksichtigt, dass nicht alle Gewichte gleich wichtig sind, nur 0,1 % bis 1 % der Gewichte (hervorragende Gewichte) tragen mehr zur Modellgenauigkeit bei und diese Gewichte hängen eher von der Aktivierungswertverteilung als von der Gewichtsverteilung ab. Der Quantifizierungsprozess dieser Methode ähnelt SmoothQuant. Der Hauptunterschied besteht darin, dass die Skala auf der Grundlage der Aktivierungswertverteilung berechnet wird.


Neben der Quantifizierungsmethode besteht eine weitere Möglichkeit zur Verbesserung der Leistung von TensorRT-LLM in der Verwendung von Multi-Machine- und Multi-Card-Inferenz. In einigen Szenarien sind große Modelle zu groß, um für die Inferenz auf einer einzelnen GPU platziert zu werden, oder sie können abgelegt werden, aber die Recheneffizienz wird beeinträchtigt, sodass für die Inferenz mehrere Karten oder mehrere Maschinen erforderlich sind.

TensorRT-LLM bietet derzeit zwei parallele Strategien: Tensor-Parallelität und Pipeline-Parallelität. TP teilt das Modell vertikal auf und platziert jeden Teil auf verschiedenen Geräten. Dies führt zu einer häufigen Datenkommunikation zwischen Geräten und wird im Allgemeinen in Szenarien mit hoher Vernetzung zwischen Geräten verwendet, wie z. B. NVLINK. Eine andere Segmentierungsmethode ist die horizontale Segmentierung. Derzeit gibt es nur eine horizontale Front, und die entsprechende Kommunikationsmethode ist die Punkt-zu-Punkt-Kommunikation, die für Szenarien geeignet ist, in denen die Kommunikationsbandbreite des Geräts schwach ist.

Die letzte hervorzuhebende Funktion ist die Stapelverarbeitung während des Flugs. Batchverarbeitung ist eine gängige Praxis zur Verbesserung der Inferenzleistung, aber in LLM-Inferenzszenarien ist die Ausgabelänge jeder Probe/Anfrage in einem Batch unvorhersehbar. Wenn Sie der statischen Batch-Methode folgen, hängt die Verzögerung eines Batches von der längsten Ausgabe in Probe/Anfrage ab. Obwohl die Ausgabe der kürzeren Probe/Anfrage beendet ist, wurden daher die Rechenressourcen nicht freigegeben, und ihre Verzögerung ist dieselbe wie die Verzögerung der längsten ausgegebenen Probe/Anfrage. Die Methode der Stapelverarbeitung während des Flugs besteht darin, am Ende der Probe/Anfrage eine neue Probe/Anfrage einzufügen. Auf diese Weise wird nicht nur die Verzögerung einer einzelnen Probe/Anfrage reduziert und Ressourcenverschwendung vermieden, sondern auch der Durchsatz des gesamten Systems verbessert. 3. TensorRT-LLM-Nutzungsprozess: TensorRT-LLM ähnelt der Verwendung von TensorRT. Zuerst müssen Sie ein vorab trainiertes Modell erhalten und es dann verwenden TensorRT-LLM Die bereitgestellte API schreibt das Modellberechnungsdiagramm neu und rekonstruiert es, verwendet dann TensorRT zur Kompilierung und Optimierung und speichert es dann als serialisierte Engine für die Inferenzbereitstellung.

Am Beispiel von Llama installieren Sie zuerst TensorRT-LLM, laden dann das vorab trainierte Modell herunter, kompilieren das Modell dann mit TensorRT-LLM und führen schließlich eine Inferenz durch.
Für das Debuggen von Modellinferenzen stimmt die Debugging-Methode von TensorRT-LLM mit der von TensorRT überein. Eine der Optimierungen, die der Deep-Learning-Compiler TensorRT ermöglicht, ist die Layer-Fusion. Wenn Sie also die Ergebnisse einer bestimmten Ebene ausgeben möchten, müssen Sie die entsprechende Ebene als Ausgabeebene markieren, um zu verhindern, dass sie vom Compiler optimiert wird, und sie dann mit der Basislinie vergleichen und analysieren. Gleichzeitig muss jedes Mal, wenn eine neue Ausgabeschicht markiert wird, die TensorRT-Engine neu kompiliert werden.
 Für benutzerdefinierte Ebenen bietet TensorRT-LLM viele Pytorch-ähnliche Operatoren, um Benutzern bei der Implementierung von Funktionen zu helfen, ohne den Kernel selbst schreiben zu müssen. Wie im Beispiel gezeigt, wird die von TensorRT-LLM bereitgestellte API verwendet, um die Logik der RMS-Norm zu implementieren, und TensorRT generiert automatisch den entsprechenden Ausführungscode auf der GPU.
Für benutzerdefinierte Ebenen bietet TensorRT-LLM viele Pytorch-ähnliche Operatoren, um Benutzern bei der Implementierung von Funktionen zu helfen, ohne den Kernel selbst schreiben zu müssen. Wie im Beispiel gezeigt, wird die von TensorRT-LLM bereitgestellte API verwendet, um die Logik der RMS-Norm zu implementieren, und TensorRT generiert automatisch den entsprechenden Ausführungscode auf der GPU.
 Wenn der Benutzer höhere Leistungsanforderungen hat oder TensorRT-LLM keine Bausteine zur Implementierung der entsprechenden Funktionen bereitstellt, muss der Benutzer den Kernel anpassen und ihn als Plugin für die Verwendung durch TensorRT-LLM packen. Der Beispielcode ist ein Beispielcode, der das angepasste GEMM von SmoothQuant implementiert und in ein Plugin kapselt, das TensorRT-LLM aufrufen kann.
Wenn der Benutzer höhere Leistungsanforderungen hat oder TensorRT-LLM keine Bausteine zur Implementierung der entsprechenden Funktionen bereitstellt, muss der Benutzer den Kernel anpassen und ihn als Plugin für die Verwendung durch TensorRT-LLM packen. Der Beispielcode ist ein Beispielcode, der das angepasste GEMM von SmoothQuant implementiert und in ein Plugin kapselt, das TensorRT-LLM aufrufen kann.

4. Inferenzleistung von TensorRT-LLM
Details wie Leistung und Konfiguration sind auf der offiziellen Website einsehbar und werden hier nicht im Detail vorgestellt. Dieses Produkt arbeitet seit seiner Gründung mit vielen großen inländischen Herstellern zusammen. Aufgrund des Feedbacks ist TensorRT-LLM im Allgemeinen aus Leistungssicht derzeit die beste Lösung. Da viele Faktoren wie Technologieiteration, Optimierungsmethoden und Systemoptimierung die Leistung beeinflussen und sich sehr schnell ändern, werden die Leistungsdaten von TensorRT-LLM hier nicht im Detail vorgestellt. Wenn Sie interessiert sind, können Sie die Details auf der offiziellen Website erfahren.
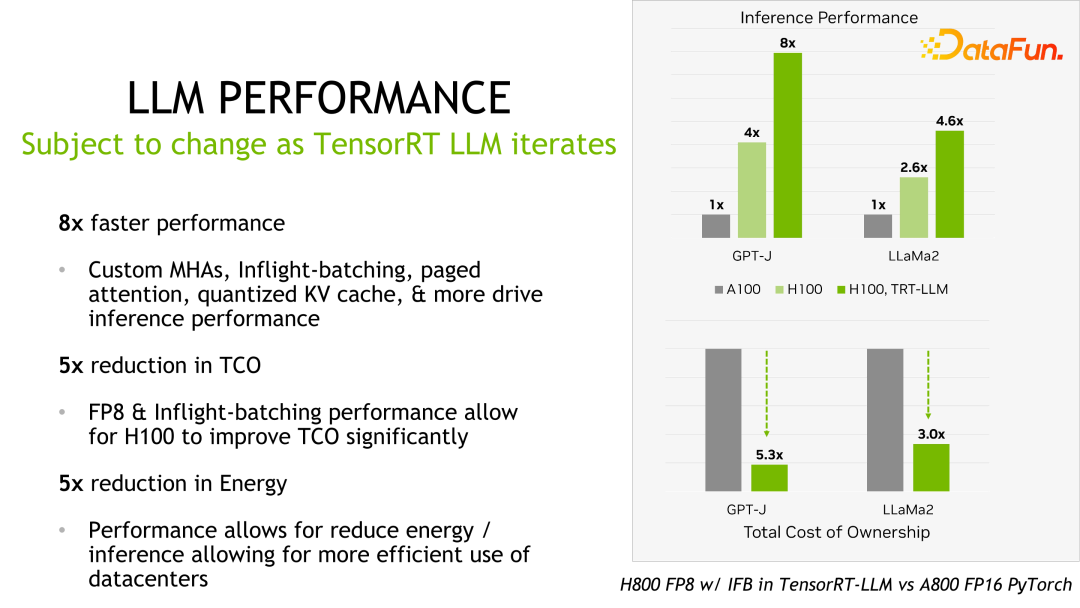
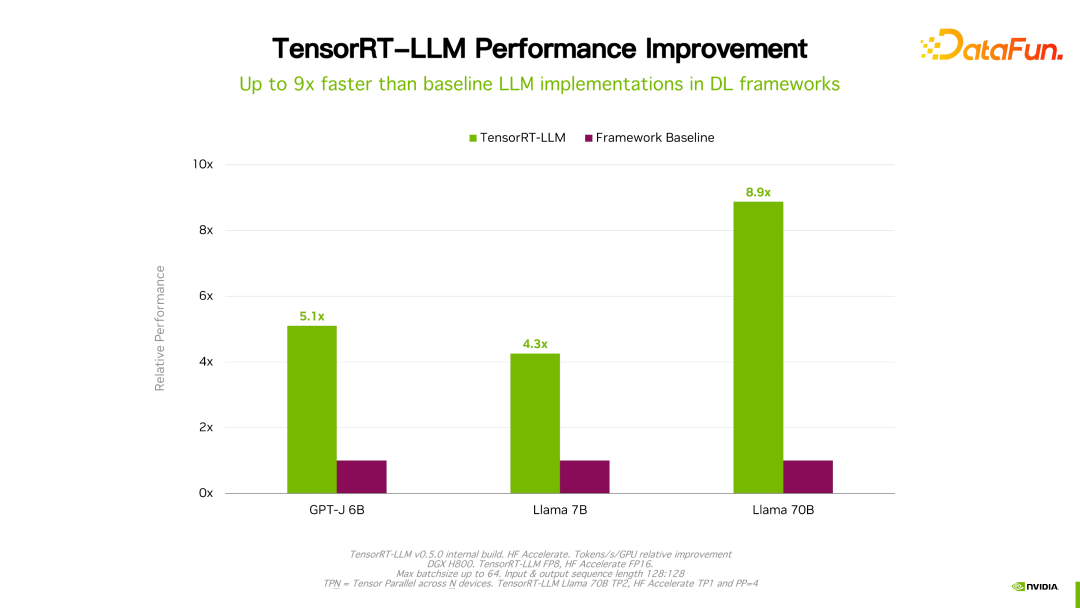
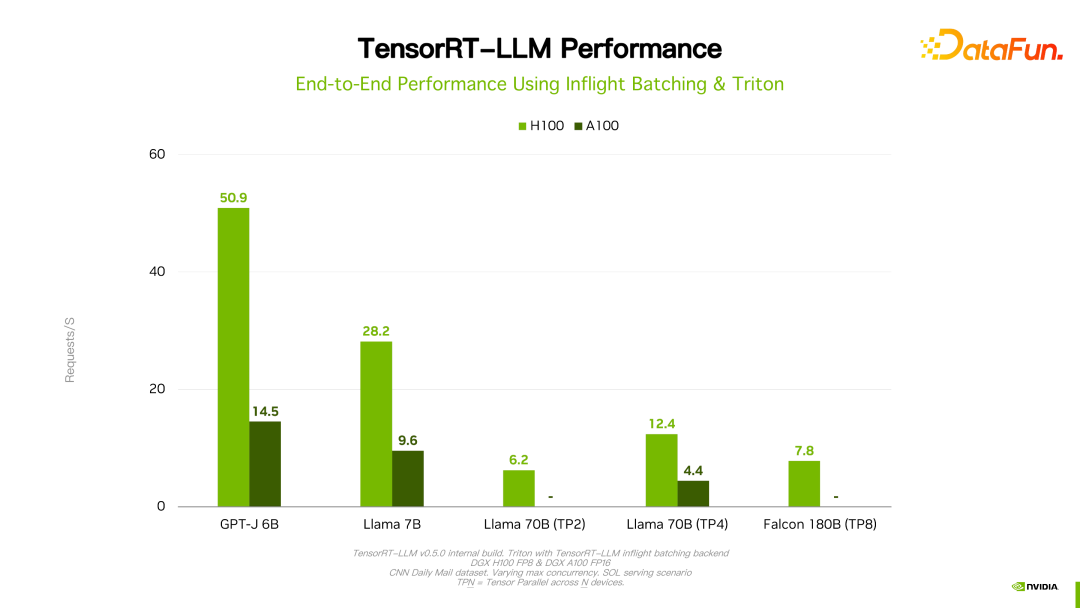
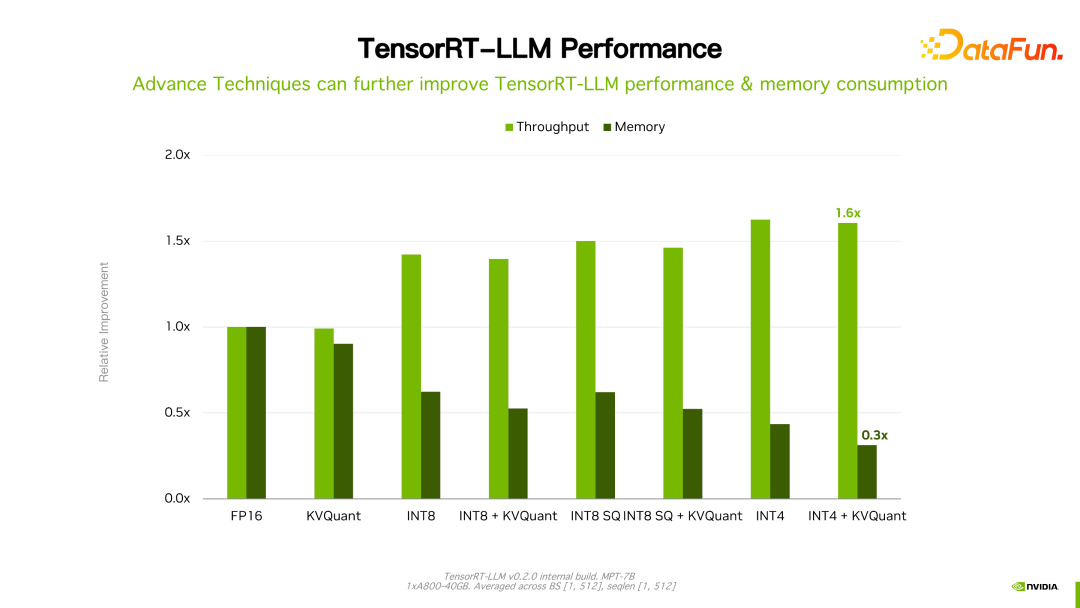
Es ist erwähnenswert, dass sich die Leistung von TensorRT-LLM im Vergleich zur Vorgängerversion weiter verbessert hat. Wie in der Abbildung oben gezeigt, wird basierend auf FP16 nach der Verwendung von KVQuant die Nutzung des Videospeichers bei gleichbleibender Geschwindigkeit reduziert. Mit INT8 lässt sich eine deutliche Verbesserung des Durchsatzes feststellen, gleichzeitig wird die Speichernutzung weiter reduziert. Es ist ersichtlich, dass sich die Leistung mit der kontinuierlichen Weiterentwicklung der TensorRT-LLM-Optimierungstechnologie weiter verbessern wird. Dieser Trend wird anhalten.
5. Die Zukunftsaussichten von TensorRT-LLM
LLM ist ein Szenario mit hohen Inferenzkosten und kostensensitiv. Wir glauben, dass zur Erzielung des nächsten hundertfachen Beschleunigungseffekts eine gemeinsame Iteration von Algorithmen und Hardware erforderlich ist, und dieses Ziel kann durch gemeinsames Design von Software und Hardware erreicht werden. Die Hardware bietet eine Quantisierung mit geringerer Präzision, während die Software-Perspektive Algorithmen wie optimierte Quantisierung und Netzwerkbereinigung verwendet, um die Leistung weiter zu verbessern.

TensorRT-LLM, NVIDIA wird auch in Zukunft daran arbeiten, die Leistung von TensorRT-LLM zu verbessern. Gleichzeitig sammeln wir durch Open Source Feedback und Meinungen, um die Benutzerfreundlichkeit zu verbessern. Darüber hinaus werden wir uns auf die Benutzerfreundlichkeit konzentrieren und weitere Anwendungstools wie Model Zone oder quantitative Tools entwickeln und als Open Source veröffentlichen, um die Kompatibilität mit gängigen Frameworks zu verbessern und End-to-End-Lösungen von der Schulung bis zur Inferenz und Bereitstellung bereitzustellen.

6. Frage- und Antwortsitzung
F1: Muss jede Berechnungsausgabe dequantisiert werden? Was soll ich tun, wenn während der Quantisierung ein Präzisionsüberlauf auftritt?
A1: Derzeit bietet TensorRT-LLM zwei Arten von Methoden, nämlich FP8 und die gerade erwähnte INT4/INT8-Quantisierungsmethode. Geringe Genauigkeit: Wenn INT8 als GEMM verwendet wird, verwendet der Akkumulator hochpräzise Datentypen wie fp16 oder sogar fp32, um einen Überlauf zu verhindern. Was die inverse Quantisierung betrifft, nehmen wir als Beispiel die fp8-Quantisierung: Wenn TensorRT-LLM den Berechnungsgraphen optimiert, verschiebt es möglicherweise automatisch den inversen Quantisierungsknoten und führt ihn mit anderen Vorgängen zusammen, um Optimierungszwecke zu erreichen. Allerdings werden die zuvor eingeführten GPTQ und QAT derzeit durch harte Codierung in den Kernel geschrieben, und es gibt keine einheitliche Verarbeitung von Quantisierungs- oder Dequantisierungsknoten.
F2: Führen Sie derzeit eine inverse Quantisierung speziell für bestimmte Modelle durch?
A2: Die aktuelle Quantifizierung ist tatsächlich so und unterstützt verschiedene Modelle. Wir planen, eine sauberere API zu erstellen oder die Modellquantifizierung durch Konfigurationselemente einheitlich zu unterstützen.
F3: Sollte TensorRT-LLM für Best Practices direkt verwendet oder mit Triton Inference Server kombiniert werden? Gibt es fehlende Funktionen, wenn sie zusammen verwendet werden?
A3: Da einige Funktionen nicht Open Source sind, müssen Sie Anpassungsarbeiten durchführen, wenn es sich um Triton handelt.
F4: Es gibt mehrere quantitative Methoden zur quantitativen Kalibrierung, und wie hoch ist das Beschleunigungsverhältnis? Wie viele Punkte gibt es in den Auswirkungen dieser Quantifizierungsschemata? Die Ausgabelänge jedes Beispiels in der In-Flight-Verzweigung ist unbekannt. Wie führt man eine dynamische Stapelverarbeitung durch?
A4: Über die quantitative Leistung können Sie privat sprechen. Wir haben nur eine grundlegende Überprüfung durchgeführt, um sicherzustellen, dass der implementierte Kernel in Ordnung ist. Wir können die Ergebnisse aller quantitativen Algorithmen im tatsächlichen Geschäft nicht garantieren Einige Dinge sind unkontrollierbar, beispielsweise der zur Quantifizierung verwendete Datensatz und seine Auswirkungen. Beim In-Flight-Batching geht es darum, zu erkennen und zu beurteilen, ob die Ausgabe einer bestimmten Probe/Anfrage während der Laufzeit beendet wurde. Wenn dies der Fall ist und dann andere eingehende Anforderungen eingefügt werden, wird und kann TensorRT-LLM die Länge der vorhergesagten Ausgabe nicht vorhersagen.
F5: Bleiben die C++-Schnittstelle und die Python-Schnittstelle der In-Flight-Verzweigung konsistent? Die Installationskosten von TensorRT-LLM sind hoch. Gibt es Verbesserungspläne für die Zukunft? Wird TensorRT-LLM eine andere Entwicklungsperspektive haben als VLLM?
A5: Wir werden unser Bestes geben, um eine konsistente Schnittstelle zwischen C++-Laufzeit und Python-Laufzeit bereitzustellen, was bereits in Planung ist. Zuvor konzentrierte sich das Team auf die Verbesserung der Leistung und der Funktionen und wird in Zukunft die Benutzerfreundlichkeit weiter verbessern. Ein direkter Vergleich mit vllm ist hier nicht einfach, aber NVIDIA wird die Investitionen in die TensorRT-LLM-Entwicklung, Community und Kundenunterstützung weiter erhöhen, um der Branche die beste LLM-Inferenzlösung bereitzustellen.
Das obige ist der detaillierte Inhalt vonEntdeckung des NVIDIA-Inferenz-Frameworks für große Modelle: TensorRT-LLM. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So lösen Sie das Problem, dass der NVIDIA-Treiber nicht mit Windows kompatibel ist
- Lernen Sie neue CSS-Funktionen kennen: Directional Clipping overflow:clip
- Neuer Durchbruch im HCP-Labor der Sun Yat-sen-Universität: Verwendung eines Kausalparadigmas zur Verbesserung multimodaler großer Modelle
- Li Ying, CIO von Baidu: Große Modelle sind eine wichtige Chance im Unternehmensbürobereich, und die native Rekonstruktion der KI wird die Art und Weise verändern, wie intelligente Arbeit geleistet wird.
- In diesem Artikel lernen Sie das von Tencent unabhängig entwickelte universelle große Sprachmodell kennen – das große Hunyuan-Modell.