
Heim >Technologie-Peripheriegeräte >KI >Kai-Fu Lee nahm an Zero One Wish teil, das ein erstklassiges multimodales Open-Source-Großmodell veröffentlichte.
Kai-Fu Lee nahm an Zero One Wish teil, das ein erstklassiges multimodales Open-Source-Großmodell veröffentlichte.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-25 11:09:051164Durchsuche
Kai-Fu Lee führte die beiden maßgeblichen Listen sowohl auf Chinesisch als auch auf Englisch an und überreichte das multimodale große ModellAntwortblatt!
Seit der Veröffentlichung der ersten großen Open-Source-Modelle Yi-34B und Yi-6B sind weniger als drei Monate vergangen.

Das Modell heißt Yi Vision Language (Yi-VL) und ist jetzt weltweit offiziell Open Source.
Beide gehören zur Yi-Serie und haben auch zwei Versionen:
Yi-VL-34B und Yi-VL-6B.
Schauen wir uns zunächst zwei Beispiele an, um die Leistung von Yi-VL in verschiedenen Szenarien wie grafischen Dialogen zu erleben:

Yi-VL hat eine detaillierte Analyse des gesamten Bildes durchgeführt und dabei nicht nur den Inhalt und sogar die Für die „Decke“ ist gesorgt.
Auf Chinesisch kann Yi-VL auch klar und genau ausdrücken:

Darüber hinaus wurden auch die offiziellen Testergebnisse angegeben.
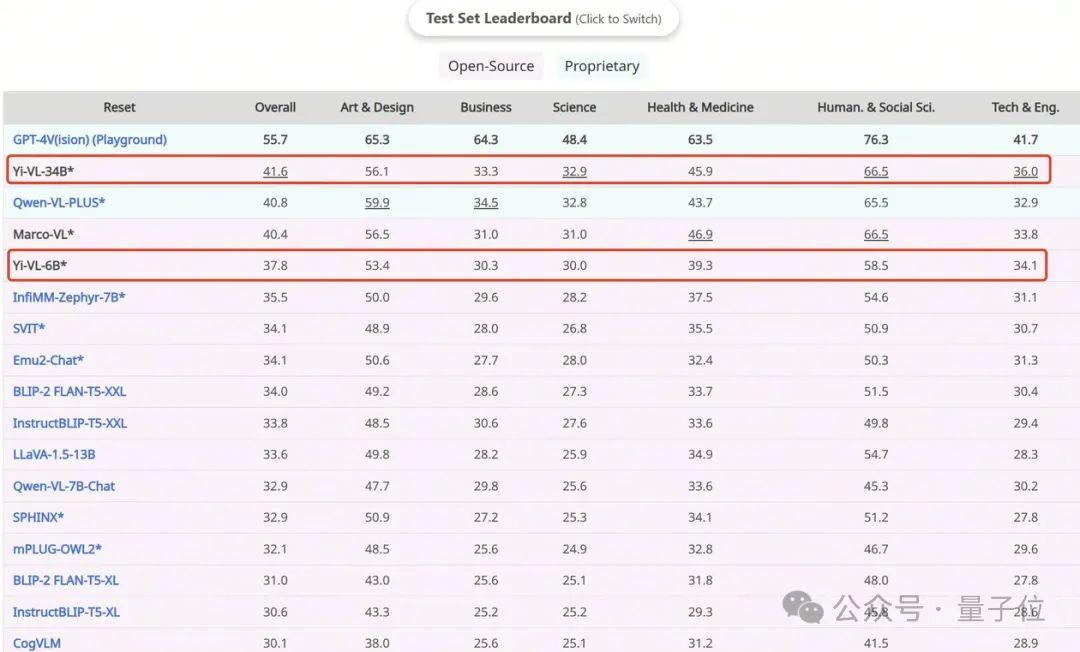
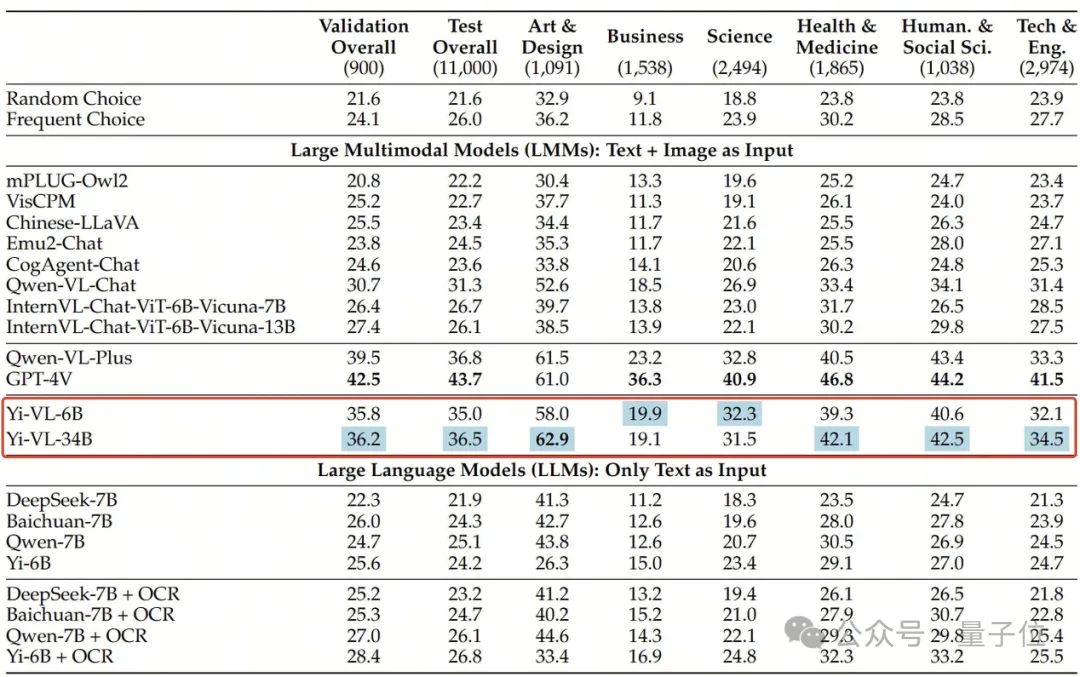
Yi-VL-34B hat eine Genauigkeit von 41,6 % im englischen Datensatz MMMU und liegt damit nach GPT-4V mit einer Genauigkeit von 55,7 % an zweiter Stelle und übertrifft damit eine Reihe multimodaler großer Modelle.
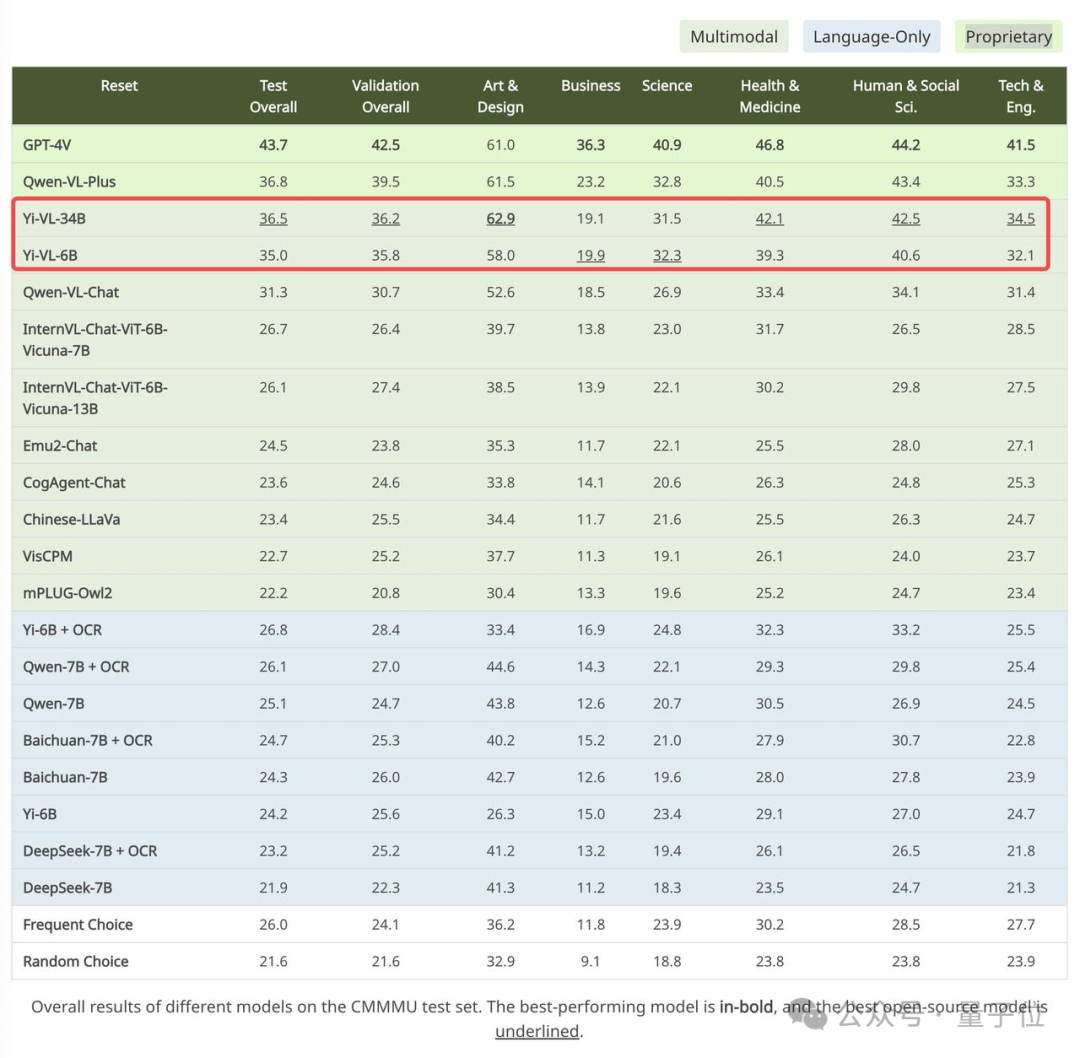
Auf dem chinesischen Datensatz CMMMU beträgt die Genauigkeit von Yi-VL-34B 36,5 %, was den aktuellen hochmodernen multimodalen Open-Source-Modellen voraus ist.
Wie sieht Yi-VL aus?
Yi-VL basiert auf dem Yi-Sprachmodell. Sie können die leistungsstarken Textverständnisfunktionen sehen, die auf dem Yi-Sprachmodell basieren. Sie müssen nur die Bilder ausrichten, um ein gutes multimodales visuelles Sprachmodell zu erhalten das Yi-VL-Modell. Eines der Kernhighlights.
Im Architekturdesign basiert das Yi-VL-Modell auf der Open-Source-LLaVA-Architektur und enthält drei Hauptmodule:
- Vision Transformer (als ViT bezeichnet) für die Bildkodierung unter Verwendung des Open-Source-OpenClip ViT -H/14-Modell Initialisieren Sie trainierbare Parameter und lernen Sie, Merkmale aus großen „Bild-Text“-Paaren zu extrahieren, wodurch das Modell in die Lage versetzt wird, Bilder zu verarbeiten und zu verstehen.
- Das Projektionsmodul bietet die Möglichkeit, Bildmerkmale und Textmerkmale räumlich am Modell auszurichten. Dieses Modul besteht aus einem mehrschichtigen Perzeptron (MLP) , das Schichtnormalisierungen enthält. Dieses Design ermöglicht es dem Modell, visuelle und Textinformationen effektiver zu verschmelzen und zu verarbeiten, wodurch die Genauigkeit des multimodalen Verständnisses und der multimodalen Generierung verbessert wird. Die Einführung der großen Sprachmodelle Yi-34B-Chat und Yi-6B-Chat bietet Yi-VL leistungsstarke Sprachverständnis- und Generierungsfunktionen. Dieser Teil des Modells nutzt fortschrittliche Technologie zur Verarbeitung natürlicher Sprache, um Yi-VL dabei zu helfen, komplexe Sprachstrukturen tiefgreifend zu verstehen und kohärente und relevante Textausgaben zu generieren.
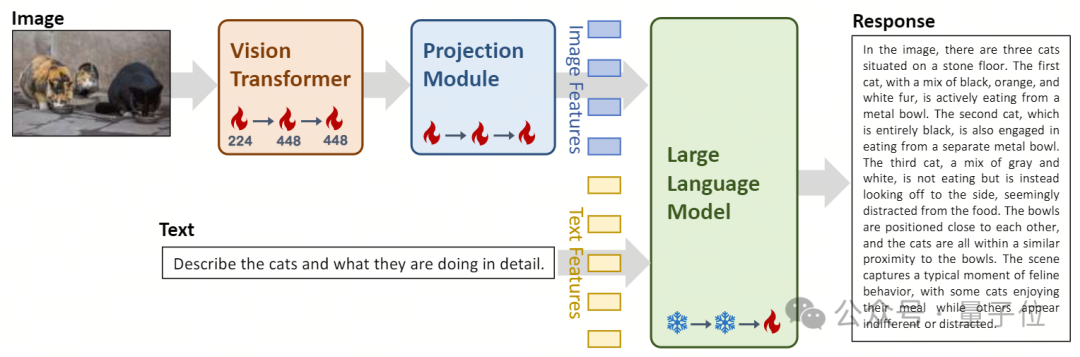
Trainingsmethode ist der Trainingsprozess des Yi-VL-Modells in drei Phasen unterteilt, mit dem Ziel, das Visuelle umfassend zu verbessern und visuelle Qualität des Modells Sprachverarbeitungsfähigkeit.
In der ersten Phase wird ein gepaarter Datensatz aus 100 Millionen „Bild-Text“ verwendet, um die Module ViT und Projection zu trainieren. Zu diesem Zeitpunkt ist die Bildauflösung auf 224 x 224 eingestellt, um die Wissenserwerbsfunktionen von ViT in bestimmten Architekturen zu verbessern und gleichzeitig eine effiziente Ausrichtung auf große Sprachmodelle zu erreichen. In der zweiten Stufe wird die Bildauflösung von ViT auf 448x448 erhöht, wodurch das Modell komplexe visuelle Details besser erkennen kann. In dieser Phase werden etwa 25 Millionen „Bild-Text“-Paare verwendet. In der dritten Stufe werden die Parameter des gesamten Modells für das Training geöffnet, mit dem Ziel, die Leistung des Modells in der multimodalen Chat-Interaktion zu verbessern. Die Trainingsdaten decken verschiedene Datenquellen mit insgesamt etwa 1 Million „Bild-Text“-Paaren ab und gewährleisten so die Breite und Ausgewogenheit der Daten. Das technische Team von Zero-One Everything hat außerdem bestätigt, dass es schnell effizientes Bildverständnis und flüssige Grafiken basierend auf den leistungsstarken Sprachverständnis- und Generierungsfähigkeiten des Yi-Sprachmodells unter Verwendung anderer multimodaler Trainingsmethoden wie BLIP, Flamingo EVA usw. Ein multimodales Grafik-Text-Modell für den Textdialog. Modelle der Yi-Serie können als Basissprachmodelle für multimodale Modelle verwendet werden und bieten so eine neue Option für die Open-Source-Community. Gleichzeitig erforscht das multimodale Zero-One-Things-Team das multimodale Vortraining von Grund auf, um GPT-4V schneller zu erreichen und zu übertreffen und das weltweit erste Echelon-Level zu erreichen.Derzeit ist das Yi-VL-Modell auf Plattformen wie Hugging Face und ModelScope für die Öffentlichkeit zugänglich. Benutzer können die Leistung dieses Modells in verschiedenen Szenarien wie Grafik- und Textdialogen persönlich erleben.
Über eine Reihe multimodaler Großmodelle hinaus
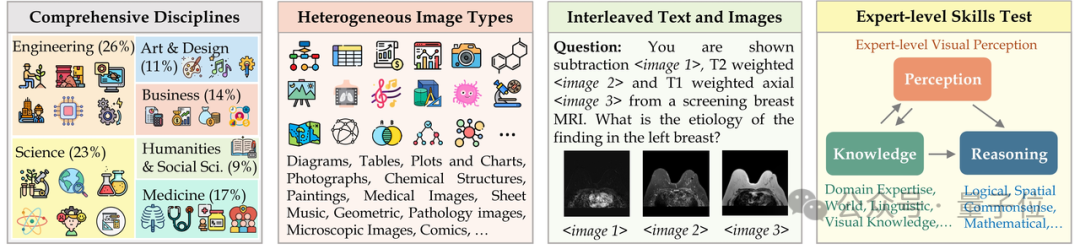
Im neuen multimodalen Benchmark MMMU schnitten beide Versionen Yi-VL-34B und Yi-VL-6B gut ab.
MMMU (Vollständiger Name: Massive Multi-discipline Multi-modal Understanding & Reasoning)Der Datensatz enthält 11.500 Fächer aus sechs Kerndisziplinen (Kunst und Design, Wirtschaft, Wissenschaft, Gesundheit und Medizin, Geistes- und Sozialwissenschaften usw.). Technologie und Ingenieurwesen) Probleme mit sehr heterogenen Bildtypen und miteinander verflochtenen Text-Bild-Informationen stellen extrem hohe Anforderungen an die fortgeschrittenen Wahrnehmungs- und Argumentationsfähigkeiten des Modells.
Und Yi-VL-34B hat eine Reihe multimodaler großer Modelle mit einer Genauigkeit von 41,6 % in diesem Testsatz erfolgreich übertroffen und liegt damit nach GPT-4V (55,7 %) an zweiter Stelle interdisziplinäres Wissen verstehen und anwenden.
 In ähnlicher Weise zeigt das Yi-VL-Modell im CMMMU-Datensatz, der für die chinesische Szene erstellt wurde, den einzigartigen Vorteil, „die Chinesen besser zu verstehen“.
In ähnlicher Weise zeigt das Yi-VL-Modell im CMMMU-Datensatz, der für die chinesische Szene erstellt wurde, den einzigartigen Vorteil, „die Chinesen besser zu verstehen“.
CMMMU enthält etwa 12.000 chinesische multimodale Fragen, die aus Universitätsprüfungen, Tests und Lehrbüchern stammen.
 Unter diesen hat GPT-4V eine Genauigkeit von 43,7 % in diesem Testsatz, gefolgt von Yi-VL-34B mit einer Genauigkeit von 36,5 %, was dem aktuellen hochmodernen Open-Source-Multimodal voraus ist Modelle.
Unter diesen hat GPT-4V eine Genauigkeit von 43,7 % in diesem Testsatz, gefolgt von Yi-VL-34B mit einer Genauigkeit von 36,5 %, was dem aktuellen hochmodernen Open-Source-Multimodal voraus ist Modelle.
[1]https://huggingface.co/01-ai
[2]https://www.modelscope.cn/organization/01ai
Das obige ist der detaillierte Inhalt vonKai-Fu Lee nahm an Zero One Wish teil, das ein erstklassiges multimodales Open-Source-Großmodell veröffentlichte.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was sind die Boxmodelleigenschaften von CSS? Einführung in die Eigenschaften von CSS-Boxmodellen
- Das Training von ViT und MAE reduziert den Rechenaufwand um die Hälfte! Sea und die Peking-Universität haben gemeinsam den effizienten Optimierer Adan vorgeschlagen, der für tiefe Modelle verwendet werden kann
- Volcano Engine unterstützt Shenzhen Technology bei der Veröffentlichung des branchenweit ersten molekularen 3D-Vortrainingsmodells Uni-Mol
- Verwendung großer Modelle zur Schaffung eines neuen Paradigmas für das Textzusammenfassungstraining
- Zoom sorgt für Transparenz bei der Datennutzung und stellt sicher, dass das KI-Training der Zustimmung des Benutzers unterliegt