
Heim >Technologie-Peripheriegeräte >KI >Die innovative „Meta-Tipp'-Strategie des Byte Fudan-Teams hat die Leistung des Diffusionsmodell-Bildverständnisses verbessert und ein beispielloses Niveau erreicht!
Die innovative „Meta-Tipp'-Strategie des Byte Fudan-Teams hat die Leistung des Diffusionsmodell-Bildverständnisses verbessert und ein beispielloses Niveau erreicht!

- 王林nach vorne
- 2024-01-17 12:48:13806Durchsuche
Das Text-to-Image (T2I)-Diffusionsmodell zeichnet sich durch die Generierung hochauflösender Bilder aus, da es vorab auf großformatige Bild-Text-Paare trainiert wird.
Dies führt zu einer natürlichen Frage: Können Diffusionsmodelle zur Lösung visueller Wahrnehmungsaufgaben verwendet werden?
Kürzlich haben Teams von ByteDance und der Fudan-Universität ein Diffusionsmodell zur Bewältigung visueller Aufgaben vorgeschlagen.

Papieradresse: https://arxiv.org/abs/2312.14733
Open-Source-Projekt: https://github.com/fudan-zvg/meta-prompts
Der Schlüssel Für das Team Insight ist die Einführung lernbarer Meta-Hinweise in vorab trainierte Diffusionsmodelle, um Merkmale zu extrahieren, die für bestimmte Wahrnehmungsaufgaben geeignet sind.
Technische Einführung
Das Team wendet das Text-zu-Bild-Diffusionsmodell als Merkmalsextrahierer auf visuelle Wahrnehmungsaufgaben an.
Zunächst wird das Eingabebild vom VQVAE-Encoder komprimiert, die Auflösung auf 1/8 der Originalgröße reduziert und eine Latentraum-Feature-Darstellung generiert. Es ist zu beachten, dass die Parameter des VQVAE-Encoders fest sind und nicht am nachfolgenden Training beteiligt sind.
Der nächste Schritt besteht darin, die Daten ohne zusätzliches Rauschen zur Merkmalsextraktion an UNet zu senden. Um sich besser an verschiedene Aufgaben anzupassen, empfängt UNet modulierte Zeitschritt-Einbettungen und mehrere Meta-Hinweise gleichzeitig, um formkonsistente Merkmale zu generieren.
Während des gesamten Prozesses führt diese Methode eine wiederholte Verfeinerung durch, um den Merkmalsausdruck zu verbessern. Dies ermöglicht eine bessere interaktive Fusion von Features aus verschiedenen Ebenen innerhalb von UNet. Im zweiten Zyklus werden die Parameter von UNet durch spezifische lernbare zeitliche Modulationsmerkmale angepasst.
Abschließend werden die von UNet generierten Multiskalenfunktionen in einen Decoder eingegeben, der speziell für die Zielsichtaufgabe entwickelt wurde.
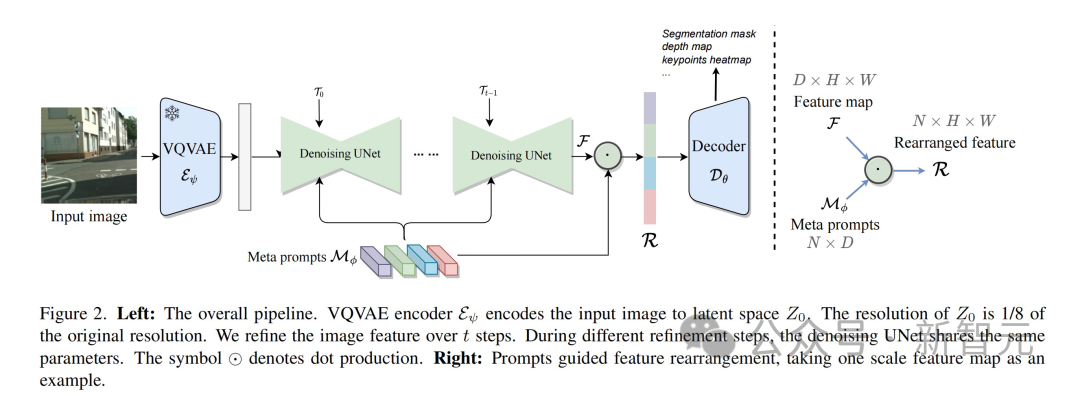
Erlernbares Meta-Prompt-Design
Das stabile Diffusionsmodell übernimmt die UNet-Architektur, um Textprompts durch Kreuzaufmerksamkeit in Bildfunktionen zu integrieren und so ein vincentisches Diagramm zu realisieren. Diese Integration stellt sicher, dass die Bildgenerierung kontextuell und semantisch korrekt ist.
Die Vielfalt der visuellen Wahrnehmungsaufgaben geht jedoch über diese Kategorie hinaus, da das Bildverständnis mit unterschiedlichen Herausforderungen konfrontiert ist und es oft an Textinformationen als Orientierungshilfe mangelt, was textgesteuerte Methoden manchmal unpraktisch macht.
Um dieser Herausforderung zu begegnen, verfolgt das technische Team eine vielfältigere Strategie: Anstatt sich auf externe Textaufforderungen zu verlassen, entwerfen wir interne lernbare Meta-Eingabeaufforderungen, sogenannte Meta-Eingabeaufforderungen, die zur Anpassung in Diffusionsmodelle integriert werden zu Wahrnehmungsaufgaben.
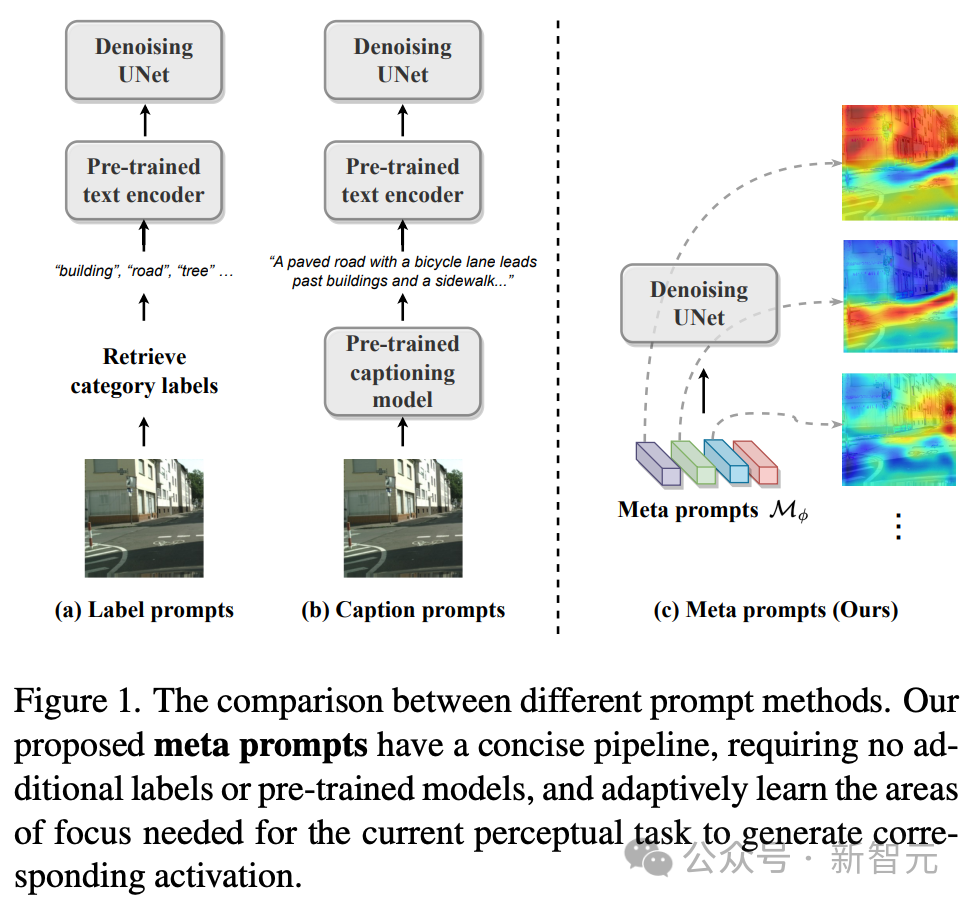
Meta-Eingabeaufforderungen werden in Form einer Matrix ausgedrückt, die die Anzahl der Meta-Eingabeaufforderungen und die Dimension darstellt. Wahrnehmungsdiffusionsmodelle mit Meta-Eingabeaufforderungen machen externe Texteingabeaufforderungen wie Datensatzkategoriebezeichnungen oder Bildtitel überflüssig und erfordern keinen vorab trainierten Textencoder, um die endgültigen Texteingabeaufforderungen zu generieren.
Meta-Eingabeaufforderungen können basierend auf Zielaufgaben und Datensätzen durchgängig trainiert werden, um speziell angepasste Anpassungsbedingungen für die Entrauschung von UNet festzulegen. Diese Meta-Eingabeaufforderungen enthalten umfangreiche semantische Informationen, die an bestimmte Aufgaben angepasst sind. Zum Beispiel:
- In der semantischen Segmentierungsaufgabe demonstrieren Meta-Eingabeaufforderungen effektiv die Fähigkeit, Kategorien zu identifizieren, und dieselben Meta-Eingabeaufforderungen neigen dazu, Funktionen derselben Kategorie zu aktivieren.

- In der Tiefenschätzungsaufgabe zeigen Meta-Eingabeaufforderungen die Fähigkeit, Tiefe wahrzunehmen, und der Aktivierungswert ändert sich mit der Tiefe, sodass Eingabeaufforderungen sich auf Objekte in der gleichen Entfernung konzentrieren können.

- Bei der Posenschätzung weisen Meta-Eingabeaufforderungen unterschiedliche Fähigkeiten auf, insbesondere die Wahrnehmung von Schlüsselpunkten, was bei der Erkennung menschlicher Posen hilfreich ist.
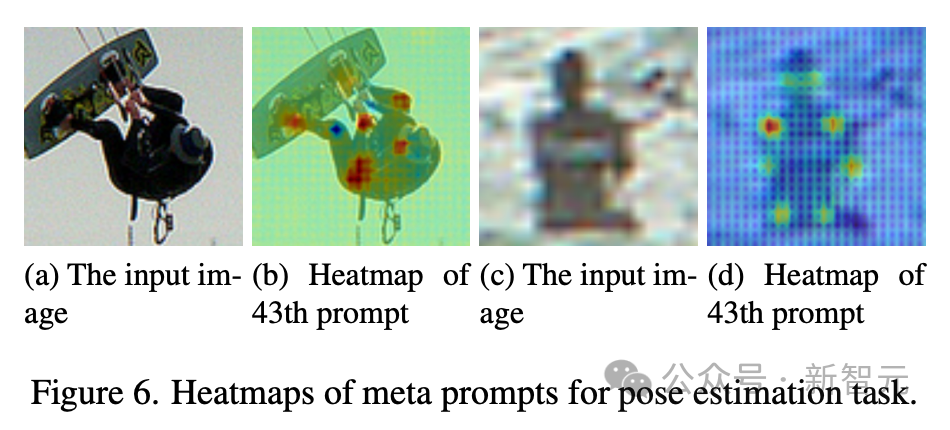
Zusammengenommen unterstreichen diese qualitativen Ergebnisse die Wirksamkeit der vom technischen Team vorgeschlagenen Meta-Eingabeaufforderungen bei der Aktivierung aufgabenbezogener Fähigkeiten in verschiedenen Aufgaben.
Als Alternative zu Text-Eingabeaufforderungen füllen Meta-Eingabeaufforderungen gut die Lücke zwischen Text-zu-Bild-Diffusionsmodellen und visuellen Wahrnehmungsaufgaben.
Meta-Cue-basierte Feature-Reorganisation
Diffusionsmodell generiert durch sein inhärentes Design Multiskalen-Features bei der Entrauschung von UNet, die sich auf feinere Detailinformationen auf niedriger Ebene konzentrieren, wenn sie sich der Ausgabeebene nähern.
Während diese Detailgenauigkeit auf niedriger Ebene für Aufgaben ausreicht, bei denen Textur und Feinkörnigkeit im Vordergrund stehen, erfordern visuelle Wahrnehmungsaufgaben häufig das Verständnis von Inhalten, die sowohl Details auf niedriger Ebene als auch semantische Interpretation auf hoher Ebene umfassen.
Daher müssen nicht nur umfangreiche Features generiert werden, es ist auch sehr wichtig zu bestimmen, welche Kombination dieser Multiskalen-Features die beste Darstellung für die aktuelle Aufgabe bieten kann.
Hier kommen Meta-Eingabeaufforderungen ins Spiel –
Diese Eingabeaufforderungen bewahren Kontextwissen, das für den während des Trainings verwendeten Datensatz spezifisch ist. Dieses Kontextwissen ermöglicht es Meta-Eingabeaufforderungen, als Filter für die Feature-Rekombination zu fungieren, den Feature-Auswahlprozess zu leiten und aus den vielen von UNet generierten Features die relevantesten Features für die Aufgabe herauszufiltern.
Das Team verwendet einen Punktproduktansatz, um den Reichtum der Multiskalenfunktionen von UNet mit der Aufgabenanpassungsfähigkeit von Meta-Eingabeaufforderungen zu kombinieren.
Berücksichtigen Sie Funktionen mit mehreren Maßstäben. und stellen die Höhe und Breite der Feature-Map dar. Meta-Eingabeaufforderungen. Die neu angeordneten Merkmale auf jeder Skala werden wie folgt berechnet:
Schließlich werden diese durch Meta-Eingabeaufforderungen gefilterten Merkmale dann in einen aufgabenspezifischen Decoder eingegeben.
Wiederkehrende Verfeinerung basierend auf lernbaren zeitlichen Modulationsmerkmalen
Im Diffusionsmodell bildet der iterative Prozess des Hinzufügens von Rauschen und der anschließenden mehrstufigen Rauschunterdrückung den Rahmen der Bilderzeugung.
Inspiriert von diesem Mechanismus entwarf das technische Team einen einfachen wiederkehrenden Verfeinerungsprozess für visuelle Wahrnehmungsaufgaben – anstatt Rauschen zu den Ausgabemerkmalen hinzuzufügen, werden die Ausgabemerkmale von UNet in einer Schleife direkt in UNet eingegeben.
Um gleichzeitig das inkonsistente Problem zu lösen, dass sich beim Durchlaufen des Modells durch die Schleife die Verteilung der Eingabemerkmale ändert, die Parameter von UNet jedoch unverändert bleiben, führte das technische Team für jedes einzelne erlernbare und einzigartige Zeitschritteinbettungen ein Schleife zum Modulieren von UNet-Parametern.
Dadurch wird sichergestellt, dass das Netzwerk anpassungsfähig bleibt und auf die Variabilität der Eingabemerkmale in verschiedenen Schritten reagiert, der Merkmalsextraktionsprozess optimiert und die Leistung des Modells bei visuellen Erkennungsaufgaben verbessert wird.
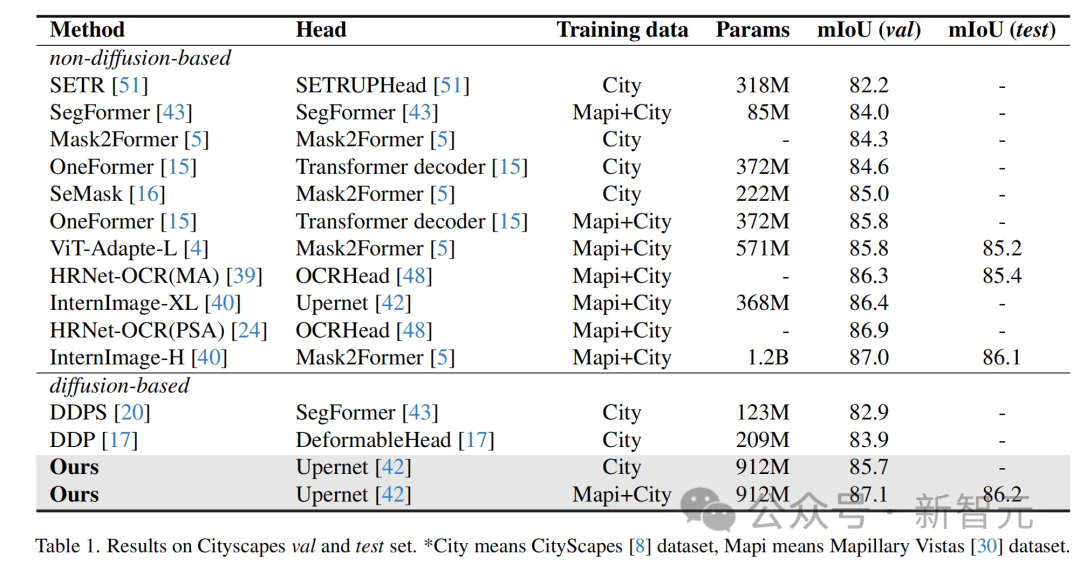
Die Ergebnisse zeigen, dass diese Methode bei mehreren Wahrnehmungsaufgabendatensätzen optimale Ergebnisse erzielt hat.
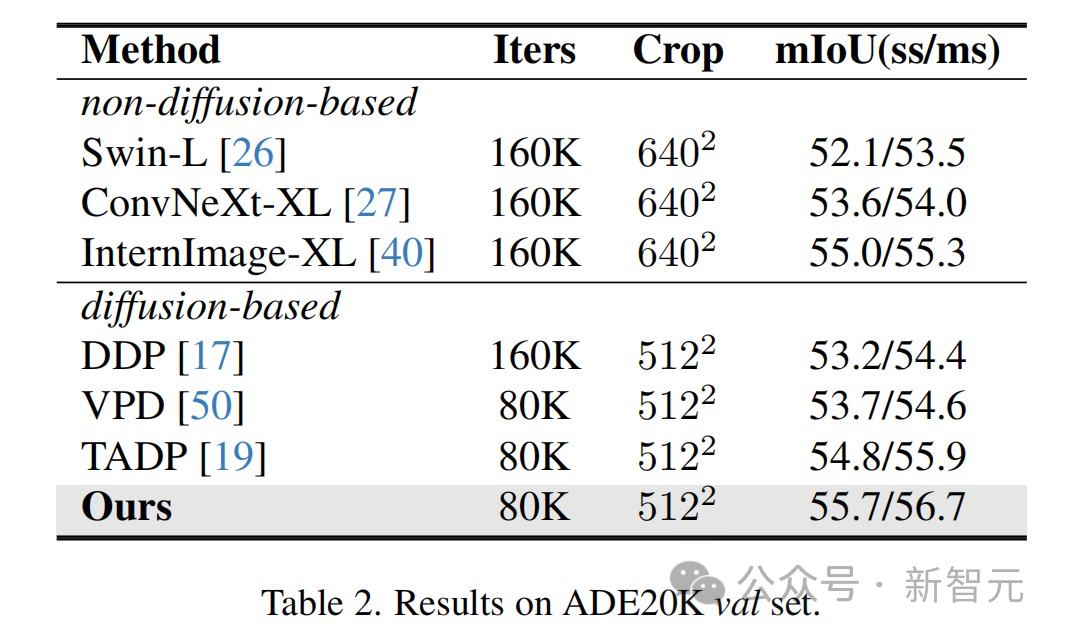
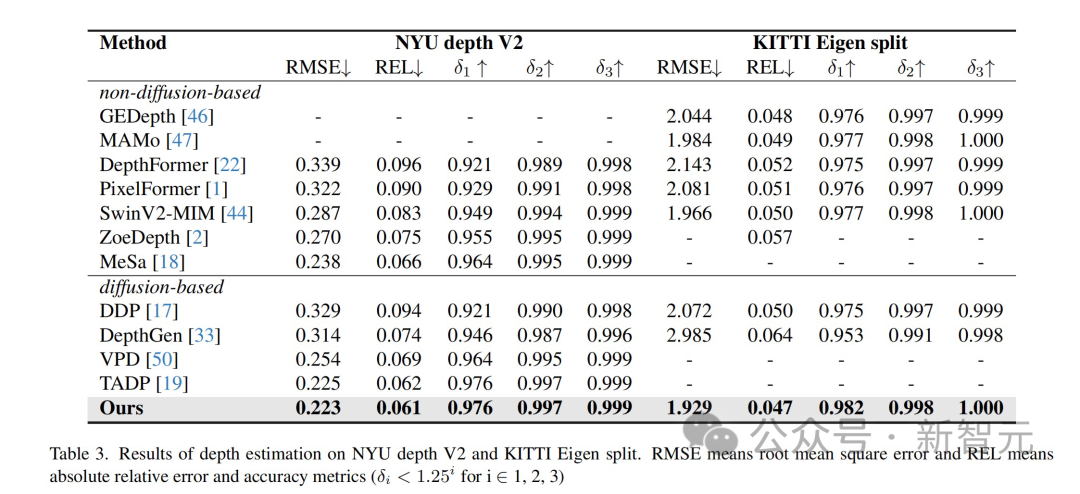
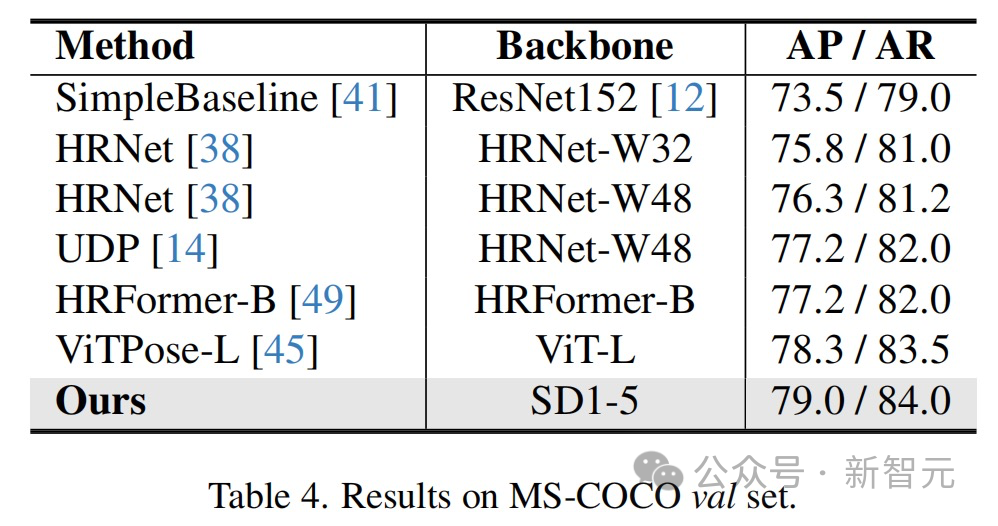
Anwendungsumsetzung und Perspektiven
Die in diesem Artikel vorgeschlagenen Methoden und Technologien haben breite Anwendungsaussichten und können die technologische Entwicklung und Innovation in mehreren Bereichen fördern:
- Verbesserungen bei visuellen Wahrnehmungsaufgaben: Diese Forschung kann die Leistung verschiedener visueller Wahrnehmungsaufgaben verbessern, wie z. B. Bildsegmentierung, Tiefenschätzung und Posenschätzung. Diese Verbesserungen können auf Bereiche wie autonomes Fahren, medizinische Bildanalyse und Roboter-Vision-Systeme angewendet werden.
- Verbesserte Computer-Vision-Modelle: Die vorgeschlagene Technologie kann Computer-Vision-Modelle genauer und effizienter bei der Handhabung komplexer Szenen machen, insbesondere wenn keine expliziten Textbeschreibungen vorhanden sind. Dies ist besonders wichtig für Anwendungen wie das Verstehen von Bildinhalten.
- Fachübergreifende Anwendungen: Die Methoden und Ergebnisse dieser Studie können bereichsübergreifende Forschung und Anwendungen inspirieren, beispielsweise im Kunstschaffen, in der virtuellen Realität und in der erweiterten Realität, um die Qualität und Interaktivität von Bildern und Videos zu verbessern .
- Langfristige Aussichten: Mit der Weiterentwicklung der Technologie können diese Methoden weiter verbessert werden, was zu einer fortschrittlicheren Bilderzeugungs- und Inhaltsverständnistechnologie führt.
Teamvorstellung
Das Team für intelligente Kreation ist das KI- und Multimedia-Technologiezentrum von ByteDance, das Computer Vision, Audio- und Videobearbeitung, Spezialeffektverarbeitung und andere technische Bereiche abdeckt und sich dabei auf die umfangreichen Geschäftsszenarien, Infrastrukturressourcen und Technik des Unternehmens stützt Zusammenarbeit Die Atmosphäre realisiert einen geschlossenen Kreislauf modernster Algorithmen-Engineering-Systeme-Produkte mit dem Ziel, den internen Unternehmen des Unternehmens modernstes Inhaltsverständnis, Inhaltserstellung, interaktive Erlebnis- und Konsumfunktionen sowie Branchenlösungen in verschiedenen Formen zu bieten.
Derzeit hat das intelligente Kreationsteam seine technischen Fähigkeiten und Dienste über Volcano Engine, eine Cloud-Service-Plattform von ByteDance, für Unternehmen geöffnet. Weitere Stellen im Zusammenhang mit großen Modellalgorithmen sind offen. Klicken Sie zum Anzeigen auf 「Originaltext lesen」.
Das obige ist der detaillierte Inhalt vonDie innovative „Meta-Tipp'-Strategie des Byte Fudan-Teams hat die Leistung des Diffusionsmodell-Bildverständnisses verbessert und ein beispielloses Niveau erreicht!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierter Code für Schulungsfragen zur Grundanweisung der MySQL-Datenbank
- So löschen Sie überflüssige Modelle in ZBrush
- Was sind die drei Elemente eines Datenmodells?
- Schockiert! Nach 70.000 Trainingsstunden lernte das Modell von OpenAI, Holz in „Minecraft' zu planen
- Verwendung von Pytorch zur Implementierung des kontrastiven Lernens von SimCLR für selbstüberwachtes Vortraining