
Heim >Backend-Entwicklung >Python-Tutorial >Verwendung von Pytorch zur Implementierung des kontrastiven Lernens von SimCLR für selbstüberwachtes Vortraining
Verwendung von Pytorch zur Implementierung des kontrastiven Lernens von SimCLR für selbstüberwachtes Vortraining

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-10 14:11:032122Durchsuche
SimCLR (Simple Framework for Contrastive Learning of Representations) ist eine selbstüberwachte Technologie zum Lernen von Bilddarstellungen. Im Gegensatz zu herkömmlichen Methoden des überwachten Lernens verlässt sich SimCLR nicht auf gekennzeichnete Daten, um nützliche Darstellungen zu lernen. Es nutzt ein kontrastives Lernframework, um eine Reihe nützlicher Funktionen zu erlernen, mit denen semantische Informationen auf hoher Ebene aus unbeschrifteten Bildern erfasst werden können.
SimCLR übertrifft nachweislich modernste unbeaufsichtigte Lernmethoden bei verschiedenen Bildklassifizierungs-Benchmarks. Und die erlernten Darstellungen können problemlos auf nachgelagerte Aufgaben wie Objekterkennung, semantische Segmentierung und Lernen mit wenigen Schüssen übertragen werden, und zwar mit minimaler Feinabstimmung bei kleineren beschrifteten Datensätzen.

SimCLR Die Hauptidee besteht darin, eine gute Darstellung des Bildes zu lernen, indem es mit anderen verbesserten Versionen desselben Bildes über das Erweiterungsmodul T verglichen wird. Dies geschieht, indem das Bild durch ein Encodernetzwerk f(.) abgebildet und dann projiziert wird. head g(.) ordnet die gelernten Merkmale einem niedrigdimensionalen Raum zu. Anschließend wird ein Kontrastverlust zwischen Darstellungen zweier verbesserter Versionen desselben Bildes berechnet, um ähnliche Darstellungen desselben Bildes und unterschiedliche Darstellungen verschiedener Bilder zu fördern.
In diesem Artikel tauchen wir tief in das SimCLR-Framework ein und untersuchen die Schlüsselkomponenten des Algorithmus, einschließlich Datenerweiterung, Kontrastverlustfunktionen und Kopfarchitektur für Encoder und Projektionen.
Hier verwenden wir den Müllklassifizierungsdatensatz von Kaggle, um Experimente durchzuführen
Erweiterungsmodul
Das Wichtigste in SimCLR ist das Erweiterungsmodul zum Konvertieren von Bildern. Die Autoren des SimCLR-Papiers schlagen vor, dass eine leistungsstarke Datenerweiterung für unbeaufsichtigtes Lernen nützlich ist. Daher werden wir dem im Papier empfohlenen Ansatz folgen.
- Zufälliger Zuschnitt zur Größenänderung
- Zufällige horizontale Drehung mit 50 % Wahrscheinlichkeit
- Zufällige Farbverzerrung (80 % Wahrscheinlichkeit von Farbzittern, 20 % Wahrscheinlichkeit von Farbabfall)
- 50 % Wahrscheinlichkeit von zufälliger Gaußscher Unschärfe
def get_complete_transform(output_shape, kernel_size, s=1.0): """ Color distortion transform Args: s: Strength parameter Returns: A color distortion transform """ rnd_crop = RandomResizedCrop(output_shape) rnd_flip = RandomHorizontalFlip(p=0.5) color_jitter = ColorJitter(0.8*s, 0.8*s, 0.8*s, 0.2*s) rnd_color_jitter = RandomApply([color_jitter], p=0.8) rnd_gray = RandomGrayscale(p=0.2) gaussian_blur = GaussianBlur(kernel_size=kernel_size) rnd_gaussian_blur = RandomApply([gaussian_blur], p=0.5) to_tensor = ToTensor() image_transform = Compose([ to_tensor, rnd_crop, rnd_flip, rnd_color_jitter, rnd_gray, rnd_gaussian_blur, ]) return image_transform class ContrastiveLearningViewGenerator(object): """ Take 2 random crops of 1 image as the query and key. """ def __init__(self, base_transform, n_views=2): self.base_transform = base_transform self.n_views = n_views def __call__(self, x): views = [self.base_transform(x) for i in range(self.n_views)] return views
Der nächste Schritt besteht darin, einen PyTorch-Datensatz zu definieren.
class CustomDataset(Dataset): def __init__(self, list_images, transform=None): """ Args: list_images (list): List of all the images transform (callable, optional): Optional transform to be applied on a sample. """ self.list_images = list_images self.transform = transform def __len__(self): return len(self.list_images) def __getitem__(self, idx): if torch.is_tensor(idx): idx = idx.tolist() img_name = self.list_images[idx] image = io.imread(img_name) if self.transform: image = self.transform(image) return image
Als Beispiel verwenden wir das kleinere Modell ResNet18 als Backbone, daher ist seine Eingabe ein 224x224-Bild. Wir stellen einige Parameter nach Bedarf ein und generieren den Datenlader
out_shape = [224, 224]
kernel_size = [21, 21] # 10% of out_shape
# Custom transform
base_transforms = get_complete_transform(output_shape=out_shape, kernel_size=kernel_size, s=1.0)
custom_transform = ContrastiveLearningViewGenerator(base_transform=base_transforms)
garbage_ds = CustomDataset(
list_images=glob.glob("/kaggle/input/garbage-classification/garbage_classification/*/*.jpg"),
transform=custom_transform
)
BATCH_SZ = 128
# Build DataLoader
train_dl = torch.utils.data.DataLoader(
garbage_ds,
batch_size=BATCH_SZ,
shuffle=True,
drop_last=True,
pin_memory=True)
SimCLR
Wir haben die Daten vorbereitet , beginnen Sie mit der Reproduktion des Modells. Das obige Erweiterungsmodul stellt zwei erweiterte Ansichten des Bildes bereit, die durch den Encoder weitergeleitet werden, um die entsprechende Darstellung zu erhalten. Das Ziel von SimCLR besteht darin, die Ähnlichkeit zwischen diesen verschiedenen erlernten Darstellungen zu maximieren, indem das Modell dazu ermutigt wird, eine allgemeine Darstellung eines Objekts aus zwei verschiedenen erweiterten Ansichten zu lernen.
Die Auswahl des Encoder-Netzwerks ist nicht beschränkt und kann eine beliebige Architektur haben. Wie oben erwähnt, verwenden wir zur einfachen Demonstration ResNet18. Die vom Encodermodell gelernten Darstellungen bestimmen die Ähnlichkeitskoeffizienten. Um die Qualität dieser Darstellungen zu verbessern, verwendet SimCLR einen Projektionskopf, um die Codierungsvektoren in einen umfassenderen latenten Raum zu projizieren. Hier projizieren wir die 512-dimensionalen Merkmale von ResNet18 in einen 256-dimensionalen Raum. Es sieht sehr kompliziert aus, aber in Wirklichkeit ist es nur das Hinzufügen eines mlp mit relu.
class Identity(nn.Module): def __init__(self): super(Identity, self).__init__() def forward(self, x): return x class SimCLR(nn.Module): def __init__(self, linear_eval=False): super().__init__() self.linear_eval = linear_eval resnet18 = models.resnet18(pretrained=False) resnet18.fc = Identity() self.encoder = resnet18 self.projection = nn.Sequential( nn.Linear(512, 512), nn.ReLU(), nn.Linear(512, 256) ) def forward(self, x): if not self.linear_eval: x = torch.cat(x, dim=0) encoding = self.encoder(x) projection = self.projection(encoding) return projection
Kontrastverlust
Die Kontrastverlustfunktion, auch bekannt als Normalized Temperature Scaled Cross-Entropy Loss (NT-Xent), ist eine Schlüsselkomponente von SimCLR, die das Modell dazu ermutigt, ähnliche und unterschiedliche Darstellungen desselben Bildes zu lernen Verschiedene Darstellungen von Bildern.
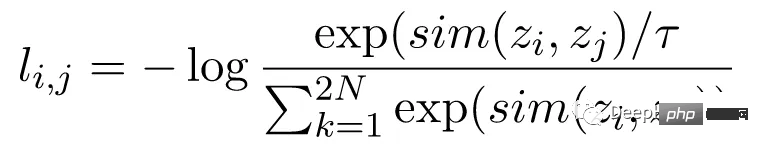
Der NT-Xent-Verlust wird mithilfe eines Paares erweiterter Ansichten des Bildes berechnet, das durch das Encodernetzwerk geleitet wird, um die entsprechenden Darstellungen zu erhalten. Das Ziel des Kontrastverlusts besteht darin, die Darstellungen zweier erweiterter Ansichten desselben Bildes ähnlich zu gestalten und gleichzeitig die Darstellungen unterschiedlicher Bilder dazu zu zwingen, unterschiedlich zu sein.
NT-Xent wendet eine Softmax-Funktion an, um die paarweise Ähnlichkeit von Ansichtsdarstellungen zu verbessern. Die Softmax-Funktion wird auf alle Darstellungspaare innerhalb des Minibatches angewendet, um eine Ähnlichkeitswahrscheinlichkeitsverteilung für jedes Bild zu erhalten. Der Temperaturparameter wird verwendet, um die paarweisen Ähnlichkeiten vor der Anwendung der Softmax-Funktion zu skalieren, was dabei hilft, bessere Gradienten während der Optimierung zu erhalten.
Nach Erhalt der Wahrscheinlichkeitsverteilung der Ähnlichkeit wird der NT-Xent-Verlust berechnet, indem die logarithmische Wahrscheinlichkeit übereinstimmender Darstellungen desselben Bildes maximiert und die logarithmische Wahrscheinlichkeit nicht übereinstimmender Darstellungen verschiedener Bilder minimiert wird.
LABELS = torch.cat([torch.arange(BATCH_SZ) for i in range(2)], dim=0) LABELS = (LABELS.unsqueeze(0) == LABELS.unsqueeze(1)).float() #one-hot representations LABELS = LABELS.to(DEVICE) def ntxent_loss(features, temp): """ NT-Xent Loss. Args: z1: The learned representations from first branch of projection head z2: The learned representations from second branch of projection head Returns: Loss """ similarity_matrix = torch.matmul(features, features.T) mask = torch.eye(LABELS.shape[0], dtype=torch.bool).to(DEVICE) labels = LABELS[~mask].view(LABELS.shape[0], -1) similarity_matrix = similarity_matrix[~mask].view(similarity_matrix.shape[0], -1) positives = similarity_matrix[labels.bool()].view(labels.shape[0], -1) negatives = similarity_matrix[~labels.bool()].view(similarity_matrix.shape[0], -1) logits = torch.cat([positives, negatives], dim=1) labels = torch.zeros(logits.shape[0], dtype=torch.long).to(DEVICE) logits = logits / temp return logits, labels
Alle Vorbereitungen sind abgeschlossen, lasst uns SimCLR trainieren und die Wirkung sehen!
simclr_model = SimCLR().to(DEVICE)
criterion = nn.CrossEntropyLoss().to(DEVICE)
optimizer = torch.optim.Adam(simclr_model.parameters())
epochs = 10
with tqdm(total=epochs) as pbar:
for epoch in range(epochs):
t0 = time.time()
running_loss = 0.0
for i, views in enumerate(train_dl):
projections = simclr_model([view.to(DEVICE) for view in views])
logits, labels = ntxent_loss(projections, temp=2)
loss = criterion(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# print stats
running_loss += loss.item()
if i%10 == 9: # print every 10 mini-batches
print(f"Epoch: {epoch+1} Batch: {i+1} Loss: {(running_loss/100):.4f}")
running_loss = 0.0
pbar.update(1)
print(f"Time taken: {((time.time()-t0)/60):.3f} mins")
Der obige Code wird für 10 Runden trainiert. Unter der Annahme, dass wir den Vortrainingsprozess abgeschlossen haben, können wir den vorab trainierten Encoder für die gewünschten Downstream-Aufgaben verwenden. Dies kann mit dem folgenden Code erfolgen.
from torchvision.transforms import Resize, CenterCrop
resize = Resize(255)
ccrop = CenterCrop(224)
ttensor = ToTensor()
custom_transform = Compose([
resize,
ccrop,
ttensor,
])
garbage_ds = ImageFolder(
root="/kaggle/input/garbage-classification/garbage_classification/",
transform=custom_transform
)
classes = len(garbage_ds.classes)
BATCH_SZ = 128
train_dl = torch.utils.data.DataLoader(
garbage_ds,
batch_size=BATCH_SZ,
shuffle=True,
drop_last=True,
pin_memory=True,
)
class Identity(nn.Module):
def __init__(self):
super(Identity, self).__init__()
def forward(self, x):
return x
class LinearEvaluation(nn.Module):
def __init__(self, model, classes):
super().__init__()
simclr = model
simclr.linear_eval=True
simclr.projection = Identity()
self.simclr = simclr
for param in self.simclr.parameters():
param.requires_grad = False
self.linear = nn.Linear(512, classes)
def forward(self, x):
encoding = self.simclr(x)
pred = self.linear(encoding)
return pred
eval_model = LinearEvaluation(simclr_model, classes).to(DEVICE)
criterion = nn.CrossEntropyLoss().to(DEVICE)
optimizer = torch.optim.Adam(eval_model.parameters())
preds, labels = [], []
correct, total = 0, 0
with torch.no_grad():
t0 = time.time()
for img, gt in tqdm(train_dl):
image = img.to(DEVICE)
label = gt.to(DEVICE)
pred = eval_model(image)
_, pred = torch.max(pred.data, 1)
total += label.size(0)
correct += (pred == label).float().sum().item()
print(f"Time taken: {((time.time()-t0)/60):.3f} mins")
print(
"Accuracy of the network on the {} Train images: {} %".format(
total, 100 * correct / total
)
)
Der Hauptteil des obigen Codes besteht darin, das gerade trainierte Simclr-Modell zu lesen, dann alle Gewichte einzufrieren und dann einen selbstlinearen Klassifizierungskopf zu erstellen, um nachgelagerte Klassifizierungsaufgaben auszuführen
Zusammenfassung
Dieser Artikel stellt das SimCLR-Framework vor und verwendet es, um ResNet18 mit zufällig initialisierten Gewichten vorab zu trainieren. Pretraining ist eine leistungsstarke Technik, die beim Deep Learning verwendet wird, um Modelle anhand großer Datenmengen zu trainieren und nützliche Funktionen zu erlernen, die auf andere Aufgaben übertragen werden können. Das SimCLR-Papier geht davon aus, dass die Leistung umso besser ist, je größer die Chargengröße ist. Unsere Implementierung verwendet nur eine Stapelgröße von 128 und trainiert nur für 10 Epochen. Dies ist also nicht die beste Leistung des Modells. Wenn ein Leistungsvergleich erforderlich ist, ist weiteres Training erforderlich.
Das folgende Bild ist das Leistungsfazit des Autors der Arbeit:

Das obige ist der detaillierte Inhalt vonVerwendung von Pytorch zur Implementierung des kontrastiven Lernens von SimCLR für selbstüberwachtes Vortraining. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!