
Heim >Technologie-Peripheriegeräte >KI >FlashOcc: Neue Ideen für die Belegungsvorhersage, neue SOTA in Bezug auf Genauigkeit, Effizienz und Speichernutzung!
FlashOcc: Neue Ideen für die Belegungsvorhersage, neue SOTA in Bezug auf Genauigkeit, Effizienz und Speichernutzung!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-11-28 11:21:501073Durchsuche
Originaltitel: FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin
Papierlink: https://arxiv.org/pdf/2311.12058.pdf
Autorenzugehörigkeit: Dalian University of Technology Houmo AI Ade Rider University

Idee für die Abschlussarbeit:
Die Belegungsvorhersage ist aufgrund ihrer Fähigkeit, Long-Tail-Defekte und komplexe Formlöschungen, die bei der 3D-Objekterkennung vorherrschen, zu einer Schlüsselkomponente autonomer Fahrsysteme geworden. Allerdings führt die Verarbeitung dreidimensionaler Darstellungen auf Voxelebene unweigerlich zu einem erheblichen Speicher- und Rechenaufwand, der den Einsatz bisheriger Methoden zur Belegungsvorhersage behindert. Entgegen dem Trend, Modelle größer und komplexer zu machen, argumentiert dieser Artikel, dass ein ideales Framework über verschiedene Chips hinweg einsetzbar sein und gleichzeitig eine hohe Genauigkeit beibehalten sollte. Zu diesem Zweck schlägt dieses Papier ein Plug-and-Play-Paradigma, FlashOCC, vor, um eine schnelle und speichereffiziente Belegungsvorhersage zu konsolidieren und gleichzeitig eine hohe Genauigkeit beizubehalten. Insbesondere führt unser FlashOCC zwei Verbesserungen durch, die auf modernen Methoden zur Vorhersage der Belegung auf Voxelebene basieren. Erstens bleiben Merkmale in BEV erhalten, was die Verwendung effizienter 2D-Faltungsschichten zur Merkmalsextraktion ermöglicht. Zweitens wird die Kanal-zu-Höhe-Transformation eingeführt, um die Ausgabeprotokolle von BEV in den 3D-Raum zu übertragen. In diesem Artikel wird FlashOCC auf verschiedene Basislinien zur Belegungsvorhersage des anspruchsvollen Occ3D-nuScenes-Benchmarks angewendet und umfangreiche Experimente durchgeführt, um seine Wirksamkeit zu überprüfen. Die Ergebnisse bestätigen, dass unser Plug-and-Play-Paradigma frühere Methoden auf dem neuesten Stand der Technik in Bezug auf Genauigkeit, Laufzeiteffizienz und Speicherkosten übertrifft und sein Einsatzpotenzial unter Beweis stellt. Der Code steht zur Nutzung zur Verfügung.
Netzwerkdesign:
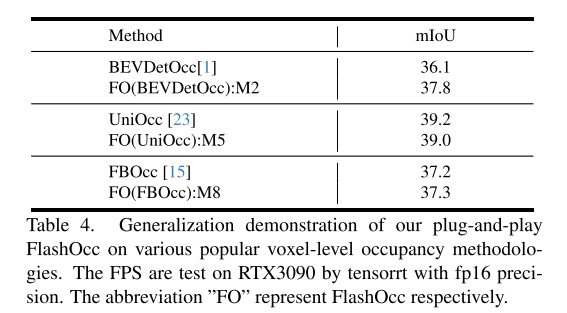
Inspiriert von der Subpixel-Faltungstechnologie [26] ersetzen wir Bild-Upsampling durch Kanalneuanordnung, um eine Kanal-zu-Raum-Feature-Konvertierung zu erreichen. In dieser Studie zielen wir darauf ab, eine effiziente Konvertierung von Kanal-zu-Höhe-Funktionen zu erreichen. In Anbetracht der Entwicklung von BEV-Wahrnehmungsaufgaben, bei denen jedes Pixel in der BEV-Darstellung Informationen über das entsprechende Säulenobjekt in der Höhendimension enthält, nutzen wir intuitiv die Kanal-zu-Höhe-Transformation, um die BEV-Merkmale in 3D-Belegungsprotokolle auf Voxelebene umzuformen . Daher konzentriert sich unsere Forschung auf die generische und Plug-and-Play-Verbesserung vorhandener Modelle und nicht auf die Entwicklung neuartiger Modellarchitekturen, wie in Abbildung 1(a) dargestellt. Insbesondere verwenden wir in modernen Methoden direkt 2D-Faltungen anstelle von 3D-Faltungen und ersetzen die aus den 3D-Faltungsausgaben abgeleiteten Belegungsprotokolle durch Kanal-zu-Höhe-Transformationen von BEV-Level-Merkmalen, die durch 2D-Faltungen erhalten wurden. Diese Modelle erzielen nicht nur den besten Kompromiss zwischen Genauigkeit und Zeitverbrauch, sondern weisen auch eine hervorragende Einsatzkompatibilität auf.
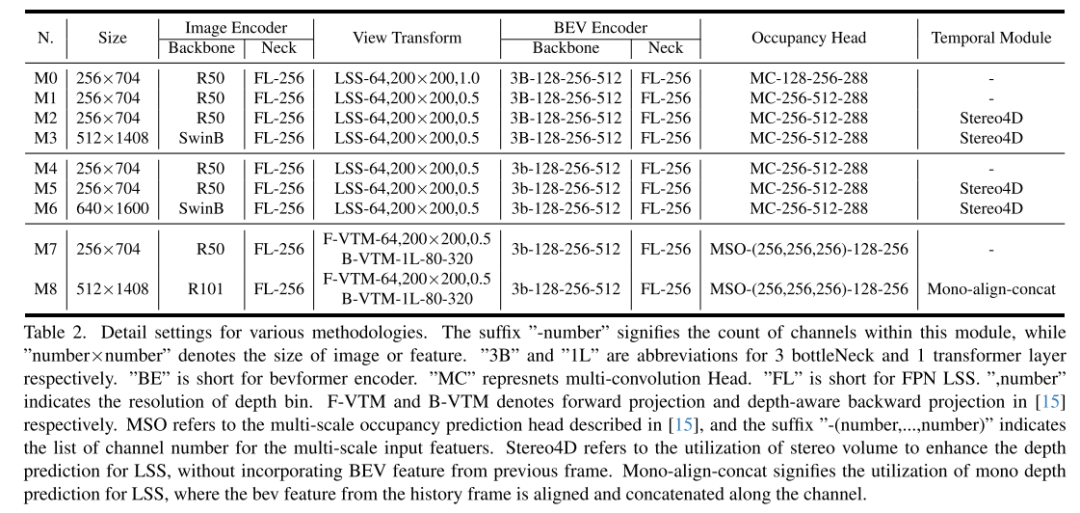
FlashOcc hat die 3D-Belegungsvorhersage in Echtzeit mit extrem hoher Genauigkeit erfolgreich abgeschlossen und stellt damit die besten bahnbrechenden Beiträge auf diesem Gebiet dar. Darüber hinaus zeigt es eine verbesserte Vielseitigkeit für den Einsatz auf verschiedenen Fahrzeugplattformen, da keine teure Merkmalsverarbeitung auf Voxelebene erforderlich ist und Ansichtstransformatoren oder 3D-Faltungsoperatoren (verformbar) vermieden werden. Wie in Abbildung 2 dargestellt, bestehen die Eingabedaten von FlashOcc aus Surround-Bildern, während die Ausgabe aus Ergebnissen zur Vorhersage dichter Belegung besteht. Obwohl sich FlashOcc in diesem Artikel auf die vielseitige Plug-and-Play-Verbesserung vorhandener Modelle konzentriert, kann es dennoch in fünf Grundmodule unterteilt werden: (1) 2D-Bildcodierer, der für das Extrahieren von Bildmerkmalen aus Bildern mit mehreren Kameras verantwortlich ist. (2) Ein Ansichtstransformationsmodul, das dabei hilft, Bildmerkmale der 2D-Wahrnehmungsansicht auf 3D-BEV-Darstellungen abzubilden. (3) BEV-Encoder, verantwortlich für die Verarbeitung der BEV-Funktionsinformationen. (4) Besetzen Sie das Vorhersagemodul, um die Segmentierungsbezeichnung jedes Voxels vorherzusagen. (5) Ein optionales zeitliches Fusionsmodul zur Integration historischer Informationen zur Verbesserung der Leistung.
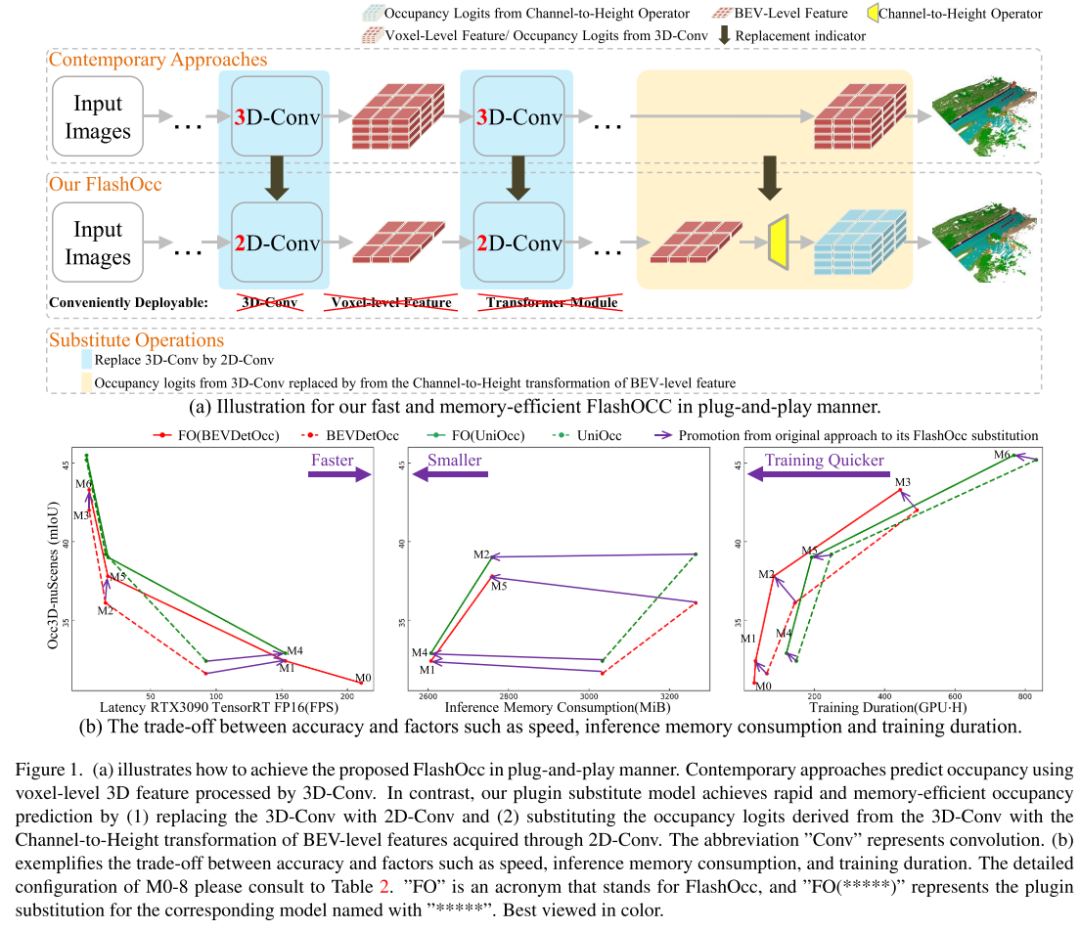
Abbildung 1.(a) zeigt, wie das vorgeschlagene FlashOcc per Plug-and-Play implementiert werden kann. Moderne Methoden nutzen 3D-Merkmale auf Voxelebene, die von 3D-Conv verarbeitet werden, um die Belegung vorherzusagen. Im Gegensatz dazu wird unser Plug-in-Ersatzmodell implementiert, indem (1) 3D-Conv durch 2D-Conv ersetzt wird und (2) die von 3D-Conv abgeleiteten Belegungsprotokolle durch eine schnelle und speichereffiziente Belegung von Kanal zu Höhe ersetzt werden Vorhersage von BEV-Level-Features, die über 2D-Conv erhalten wurden. Die Abkürzung „Conv“ steht für Convolution. (b) veranschaulicht den Kompromiss zwischen Genauigkeit und Faktoren wie Geschwindigkeit, Inferenzspeicherverbrauch und Trainingsdauer.
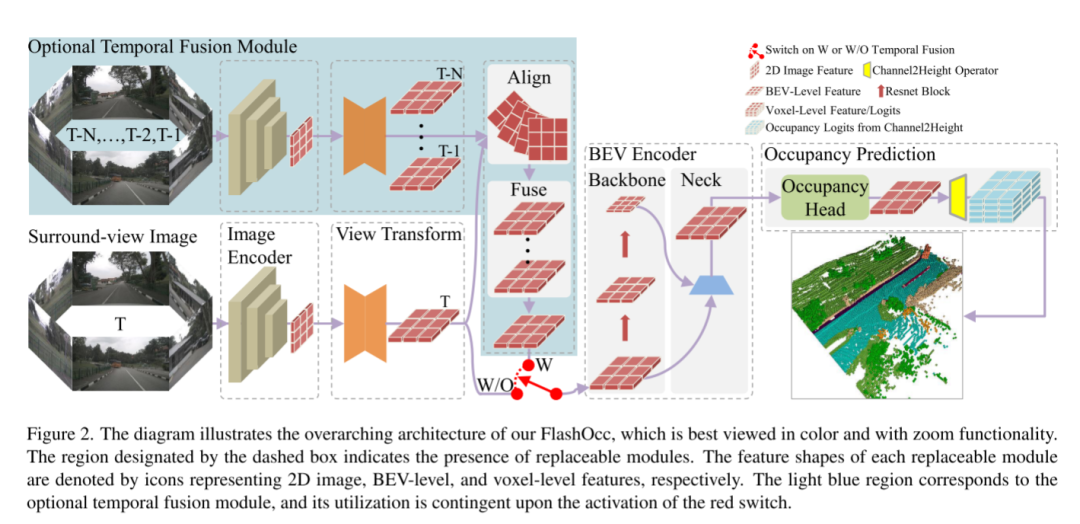
Abbildung 2. Diese Abbildung veranschaulicht die Gesamtarchitektur von FlashOcc und lässt sich am besten in Farbe mit Zoomfunktionen betrachten. Der durch das gestrichelte Kästchen gekennzeichnete Bereich zeigt das Vorhandensein austauschbarer Module an. Die Merkmalsform jedes austauschbaren Moduls wird durch Symbole dargestellt, die jeweils 2D-Bild-, BEV-Level- und Voxel-Level-Features darstellen. Der hellblaue Bereich entspricht dem optionalen Temporalfusionsmodul, dessen Nutzung von der Aktivierung des roten Schalters abhängt.
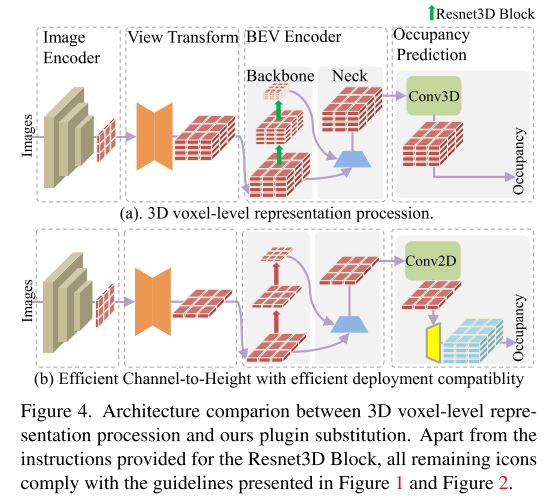
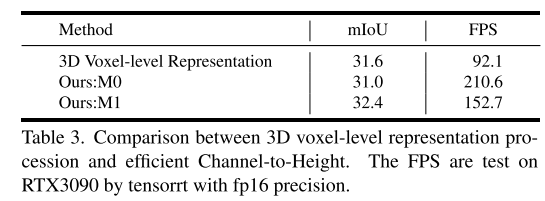
Abbildung 4 zeigt den Architekturvergleich zwischen der 3D-Darstellungsverarbeitung auf Voxelebene und dem in diesem Artikel vorgeschlagenen Plug-in-Ersatz
 Zusammenfassung:
Zusammenfassung: 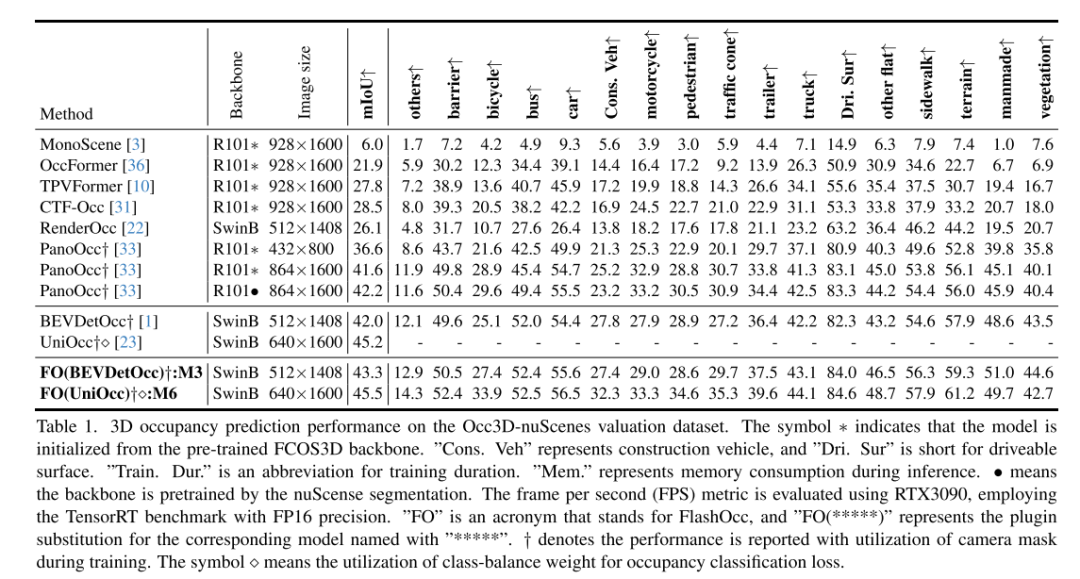
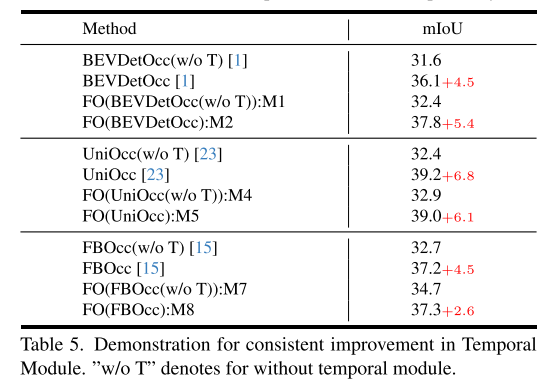
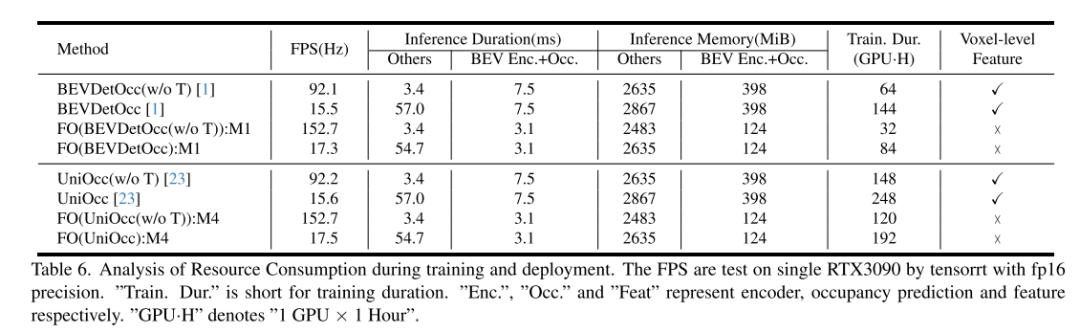 Originallink: https://mp.weixin.qq.com/s/JDPlWj8FnZffJZc9PIsvXQ
Originallink: https://mp.weixin.qq.com/s/JDPlWj8FnZffJZc9PIsvXQ
Das obige ist der detaillierte Inhalt vonFlashOcc: Neue Ideen für die Belegungsvorhersage, neue SOTA in Bezug auf Genauigkeit, Effizienz und Speichernutzung!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Three.js implementiert die gemeinsame Nutzung von 3D-Karteninstanzen
- So verlassen Sie den PS3D-Modus
- Welche Sprache wird zur Entwicklung von Unity3D verwendet?
- Physischer Abbau der Tesla Autopilot-Hardware 4.0: Hinzufügen von Radar und Bereitstellung weiterer Kameras
- Wie lange wird es dauern, bis autonomes Fahren realisierbar ist?