
Heim >Technologie-Peripheriegeräte >KI >Verwenden Sie beim Lernen mit wenigen Schüssen SetFit für die Textklassifizierung
Verwenden Sie beim Lernen mit wenigen Schüssen SetFit für die Textklassifizierung

- 王林nach vorne
- 2023-11-28 11:14:281782Durchsuche
Übersetzer |. Chen Jun
Rezensent |. Chonglou
In diesem Artikel werde ich Ihnen das „Few-Shot-Lernen“ vorstellen Konzepte , und konzentrieren Sie sich auf die SetFit-Methode, die bei der Textklassifizierung weit verbreitet ist.
Traditionelles maschinelles Lernen (ML) 
Beim überwachten (S
überwachten) maschinellen Lernen werden große Datensätze für das Modelltraining verwendet, um das Modell zu verfeinern, um die Fähigkeit zu entwickeln genau vorhersagen. Nach Abschluss des Trainingsprozesses können wir die Testdaten verwenden, um die Vorhersageergebnisse des Modells zu erhalten. Dieser traditionelle Ansatz des überwachten Lernens weist jedoch einen erheblichen Nachteil auf: Er erfordert einen großen, fehlerfreien Trainingsdatensatz. Doch nicht alle Felder sind in der Lage, solch fehlerfreie Datensätze zu liefern. Daher entstand das Konzept des „Few-Shot-Learning“.Bevor wir uns mit der Feinabstimmung des Satztransformators
(SetFit) befassen, müssen wir uns kurz mit der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) befassen Ein wichtiger Aspekt von ) ist: „Few-Shot-Learning“. Few-Shot-Lernen
Few-Shot-Lernen bedeutet: Verwenden eines begrenzten Trainingsdatensatzes zum Trainieren des Modells. Das Modell kann Wissen aus diesen kleinen Sammlungen, sogenannten Support-Sets, gewinnen. Diese Art des Lernens zielt darauf ab, einem Wenig-Schuss-Modell beizubringen, Ähnlichkeiten und Unterschiede in den Trainingsdaten zu erkennen. Anstatt das Modell beispielsweise anzuweisen, ein bestimmtes Bild als Katze oder Hund zu klassifizieren, weisen wir es an, die Gemeinsamkeiten und Unterschiede zwischen verschiedenen Tieren zu erfassen. Wie man sieht, konzentriert sich dieser Ansatz auf das Verständnis von Ähnlichkeiten und Unterschieden in den Eingabedaten. Daher wird es auch oft als Meta-Lernen (meta-learning
) oder Lernen-zu-Lernen (learning-to-learn) bezeichnet. Es ist erwähnenswert, dass der Unterstützungssatz des Wenig-Shot-Lernens auch k
to (k-way)n Sample (n-shot) Learning genannt wird. Darunter stellt „k“ die Anzahl der Kategorien im Support-Set dar. Beispielsweise ist in der binären Klassifizierung k gleich 2. Und „n“ stellt die Anzahl der verfügbaren Beispiele für jede Kategorie im Support-Set dar. Wenn beispielsweise die positive Klassifizierung 10 Datenpunkte aufweist und die negative Klassifizierung ebenfalls 10 Datenpunkte, dann ist n gleich 10. Zusammenfassend kann dieses Unterstützungsset als bidirektionales 10 Beispiellernen beschrieben werden. Da wir nun über ein grundlegendes Verständnis des Wenig-Schuss-Lernens verfügen, lernen wir schnell, indem wir SetFit
verwenden und in praktischen Anwendungen eine Textklassifizierung für E-Commerce-Datensätze durchführen.SetFitArchitecture
wurde gemeinsam vom Team von Hugging Face
und Intel Labs entwickelt Fotoklassifizierung mit wenigen Beispielen. Ausführliche Informationen zu SetFit finden Sie in der Projektbibliothek unter dem Link https://github.com/huggingface/setfit?ref=hackernoon.com.In Bezug auf die Ausgabe verwendet SetFit nur acht kommentierte Beispiele jeder Kategorie im Stimmungsanalysedatensatz „Kundenrezensionen“ (Kundenrezensionen, CR
). Das Ergebnis ist das gleiche wie das Ergebnis des abgestimmtenRoBERTa Large auf dem vollständigen Trainingssatz bestehend aus 3.000 Beispielen. Hervorzuheben ist, dass das leicht optimierte Modell RoBERTa vom Volumen her dreimal so groß ist wie das Modell SetFit. Das Bild unten zeigt die SetFit-Architektur: Bildquelle: https://www.php.cn/link/2456b9cd2668fa69e3c7ecd6f51866bf
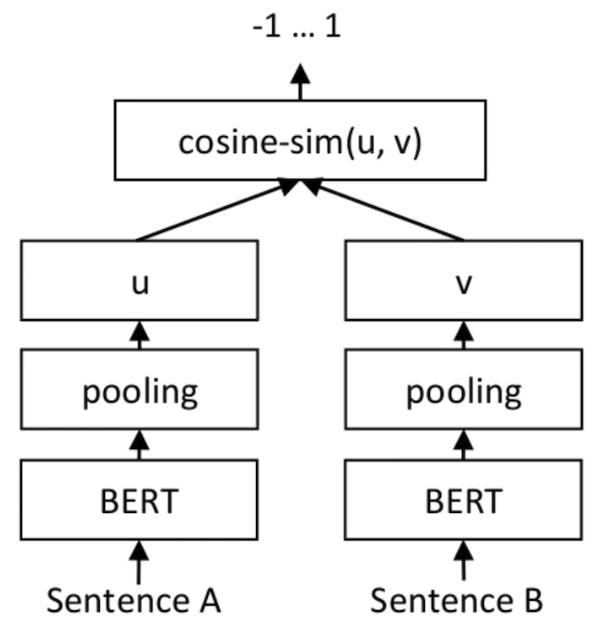
Erreicht mit SetFit Schnelles Lernen
SetFit Das Training ist sehr schnell und effizient. Seine Leistung ist im Vergleich zu großen Modellen wie GPT-3 und
T-FEW äußerst konkurrenzfähig. Siehe das Bild unten: Vergleich von Wie in der Abbildung unten gezeigt, schneidet SetFit beim Wenig-Schuss-Lernen besser ab als RoBERTa. Vergleich zwischen SetFit und RoBERT, Bildquelle: https://www.php.cn/link/3ff4cea152080fd7d692a8286a587a67. unten, Wir werden einen einzigartigen E-Commerce-Datensatz verwenden, der aus vier verschiedenen Kategorien besteht: Bücher, Kleidung und Accessoires, Elektronik und Einrichtungsgegenstände. Der Hauptzweck dieses Datensatzes besteht darin, Produktbeschreibungen von E-Commerce-Websites unter bestimmten Tags zu klassifizieren. Um die Verwendung der Trainingsmethode mit wenigen Stichproben zu erleichtern, werden wir acht Stichproben aus jeder der vier Kategorien auswählen, was insgesamt 32 Trainingsstichproben ergibt. Die restlichen Muster bleiben für Testzwecke reserviert. Kurz gesagt, der Support-Satz, den wir hier verwenden, ist 4 Lernen aus 8 Beispielen. Die folgende Abbildung zeigt ein Beispiel für einen benutzerdefinierten E-Commerce-Datensatz: Wir verwenden den Namen „all-mpnet-base-v2“ Sentence Transformers hat Modelle vorab trainiert, um Textdaten in verschiedene Vektoreinbettungen umzuwandeln. Dieses Modell kann Vektoreinbettungen der Dimension 768 für Eingabetext generieren. Wie im folgenden Befehl gezeigt, starten wir SetFit mit der Installation der erforderlichen Pakete in der Implementierung der conda-Umgebung (ein Open-Source-Paketverwaltungssystem und Umgebungsverwaltungssystem). Nach der Installation des Softwarepakets können wir den Datensatz über den folgenden Code laden. Sehen wir uns die Abbildung unten an, um die Anzahl der Trainings- und Testbeispiele zu sehen. Wir verwenden LabelEncoder aus dem Paket sklearn, um Textetiketten in codierte Etiketten umzuwandeln. Mit LabelEncoder kodieren wir die Trainings- und Testdatensätze und fügen die kodierten Beschriftungen zur Spalte „Label“ des Datensatzes hinzu. Siehe den Code unten: Nachfolgend initialisieren wir das SetFit-Modell und das Satztransformatormodell. Nach der Initialisierung der beiden Modelle können wir nun das Trainingsprogramm aufrufen. Nach Abschluss von 2 Trainingsrunden (Epochen) evaluieren wir das trainierte Modell auf eval_dataset. Nach dem Test erreichte unser Trainingsmodell die höchste Genauigkeit von 87,5 %. Obwohl die Genauigkeit von 87,5% nicht hoch ist, hat unser Modell schließlich nur 32 Proben für das Training verwendet. Mit anderen Worten: Angesichts der begrenzten Größe des Datensatzes ist das Erreichen einer Genauigkeit von 87,5 % beim Testdatensatz tatsächlich recht beeindruckend. Darüber hinaus kann SetFit das trainierte Modell auch im lokalen Speicher speichern, um es später für zukünftige Vorhersagen von der Festplatte zu laden. Der folgende Code zeigt die Vorhersageergebnisse basierend auf neuen Daten: Es ist ersichtlich, dass die Vorhersageausgabe 1 ist und der LabelEncoded-Wert des Etiketts „Kleidung und“ ist Zubehör" . Herkömmliche KI-Modelle erfordern eine große Menge an Trainingsressourcen (einschließlich Zeit und Daten), um ein stabiles Ausgabeniveau zu erzielen. Im Gegensatz dazu ist unser Modell sowohl genau als auch effizient. An diesem Punkt glaube ich, dass Sie das Konzept des „Few-Shot-Lernens“ im Grunde beherrschen und wissen, wie Sie SetFit für die Textklassifizierung und andere Anwendungen verwenden. Um ein tieferes Verständnis zu erlangen, empfehle ich Ihnen natürlich dringend, ein tatsächliches Szenario auszuwählen, einen Datensatz zu erstellen, den entsprechenden Code zu schreiben und den Prozess auf Zero-Shot-Lernen und Single-Shot-Lernen auszudehnen. Julian Chen ist der Herausgeber der 51CTO-Community. Er verfügt über mehr als zehn Jahre Erfahrung in der Umsetzung von IT-Projekten, ist gut im Management interner und externer Ressourcen und Risiken und ist fokussiert Verbreitung des Wissens und der Erfahrung im Bereich Netzwerk- und Informationssicherheit Originaltitel: Mastering Few-Shot Learning with SetFit for Text Classification, Autor: Shyam Ganesh (S) 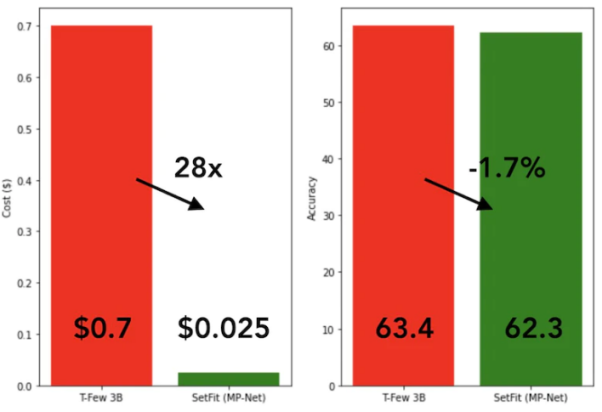 SetFit und dem T-Few 3B-Modell
SetFit und dem T-Few 3B-Modell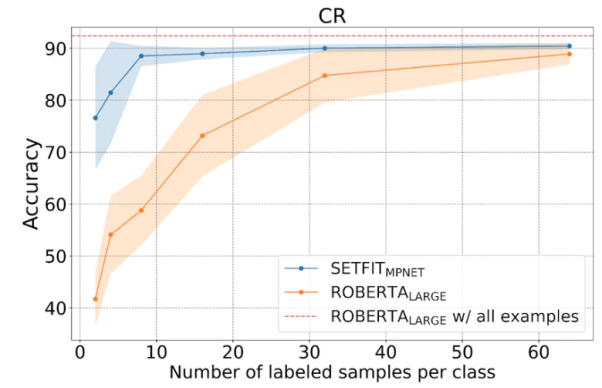
Datensatz
 Beispiel für einen benutzerdefinierten E-Commerce-Datensatz
Beispiel für einen benutzerdefinierten E-Commerce-Datensatz!pip3 install SetFit !pip3 install sklearn !pip3 install transformers !pip3 install sentence-transformers
from datasets import load_datasetdataset = load_dataset('csv', data_files={"train": 'E_Commerce_Dataset_Train.csv',"test": 'E_Commerce_Dataset_Test.csv'})
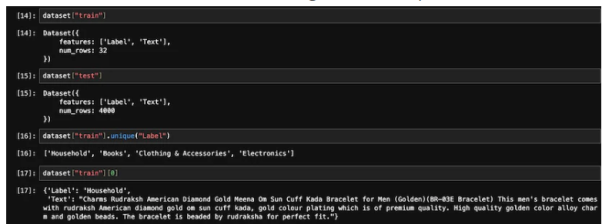 Trainings- und Testdaten
Trainings- und Testdaten from sklearn.preprocessing import LabelEncoder le = LabelEncoder()
Encoded_Product = le.fit_transform(dataset["train"]['Label']) dataset["train"] = dataset["train"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["train"].features)Encoded_Product = le.fit_transform(dataset["test"]['Label']) dataset["test"] = dataset["test"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["test"].features)
from setfit import SetFitModel, SetFitTrainer from sentence_transformers.losses import CosineSimilarityLossmodel_id = "sentence-transformers/all-mpnet-base-v2" model = SetFitModel.from_pretrained(model_id)trainer = SetFitTrainer( model=model, train_dataset=dataset["train"], eval_dataset=dataset["test"], loss_class=CosineSimilarityLoss, metric="accuracy", batch_size=64, num_iteratinotallow=20, num_epochs=2, column_mapping={"Text": "text", "Label": "label"})
trainer.train()
trainer.evaluate()
trainer.model._save_pretrained(save_directory="SetFit_ECommerce_Output/")model=SetFitModel.from_pretrained("SetFit_ECommerce_Output/", local_files_notallow=True)
input = ["Campus Sutra Men's Sports Jersey T-Shirt Cool-Gear: Our Proprietary Moisture Management technology. Helps to absorb and evaporate sweat quickly. Keeps you Cool & Dry. Ultra-Fresh: Fabrics treated with Ultra-Fresh Antimicrobial Technology. Ultra-Fresh is a trademark of (TRA) Inc, Ontario, Canada. Keeps you odour free."]output = model(input)
Übersetzer-Einführung
Das obige ist der detaillierte Inhalt vonVerwenden Sie beim Lernen mit wenigen Schüssen SetFit für die Textklassifizierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Drei Top-Bibliotheken für maschinelles Lernen für Python
- Python-Bibliothek für maschinelles Lernen NumPy
- Die zehn wichtigsten Konzepte und Technologien des maschinellen Lernens im Jahr 2023
- Welche Anwendungen gibt es für maschinelles Lernen?
- Konfigurationsmethode für die Verwendung von RStudio für die Modellentwicklung für maschinelles Lernen auf Linux-Systemen