
Heim >Technologie-Peripheriegeräte >KI >Die NVIDIA RTX-Grafikkarte beschleunigt die KI-Inferenz um das Fünffache! Der RTX-PC bewältigt große Modelle problemlos lokal
Die NVIDIA RTX-Grafikkarte beschleunigt die KI-Inferenz um das Fünffache! Der RTX-PC bewältigt große Modelle problemlos lokal

- 王林nach vorne
- 2023-11-17 23:05:431494Durchsuche
Auf der Microsoft Iginte Global Technology Conference veröffentlichte Microsoft eine Reihe neuer KI-bezogener Optimierungsmodelle und Ressourcen für Entwicklungstools, die Entwicklern dabei helfen sollen, die Hardwareleistung voll auszunutzen und KI-Anwendungsfelder zu erweitern.
Speziell für NVIDIA, das derzeit eine absolute Dominanz im KI-Bereich einnimmt, hat Microsoft dieses Mal ein großes Geschenkpaket verschickt, Ob es sich um die TensorRT-LLM-Paketschnittstelle für die OpenAI-Chat-API oder die Leistungsverbesserung des RTX-Treibers handelt DirectML für Llama 2 sowie andere beliebte Large Language Models (LLM) können eine bessere Beschleunigung und Anwendung auf NVIDIA-Hardware erreichen.
Unter diesen ist TensorRT-LLM eine Bibliothek zur Beschleunigung der LLM-Inferenz, die die KI-Inferenzleistung erheblich verbessern kann. Sie wird ständig aktualisiert, um immer mehr Sprachmodelle zu unterstützen, und ist außerdem Open Source.
NVIDIA hat im Oktober TensorRT-LLM für die Windows-Plattform veröffentlicht. Bei Desktops und Laptops, die mit GPU-Grafikkarten der RTX 30/40-Serie ausgestattet sind, können anspruchsvolle KI-Arbeitslasten einfacher erledigt werden, solange der Grafikspeicher 8 GB oder mehr erreicht
Jetzt kann Tensor RT-LLM für Windows über eine neue Paketschnittstelle mit der beliebten Chat-API von OpenAI kompatibel sein, sodass verschiedene verwandte Anwendungen direkt lokal ausgeführt werden können, ohne dass eine Verbindung zur Cloud erforderlich ist, was der Speicherung auf dem PC zuträglich ist Private und proprietäre Daten, um Datenschutzlecks zu verhindern.
Solange es sich um ein großes, von TensorRT-LLM optimiertes Sprachmodell handelt, kann es mit dieser Paketschnittstelle verwendet werden, einschließlich Llama 2, Mistral, NV LLM usw.Für Entwickler ist kein mühsames Umschreiben und Portieren des Codes erforderlich.
Ändern Sie einfach ein oder zwei Codezeilen. Die KI-Anwendung kann schnell lokal ausgeführt werden.
 ↑ ↑ ↑ Microsoft Visual Studio-Code-Plug-in basierend auf TensorRT-LLM – Continue.dev-Codierungsassistent
↑ ↑ ↑ Microsoft Visual Studio-Code-Plug-in basierend auf TensorRT-LLM – Continue.dev-Codierungsassistent
und die Unterstützung beliebterer LLMs, einschließlich des neuen Mistral mit 7 Milliarden Parametern, The 8 Milliarden Parameter Nemotron-3 ermöglicht es Desktops und Laptops, LLM jederzeit lokal, schnell und genau auszuführen. Laut tatsächlichen Messdaten,
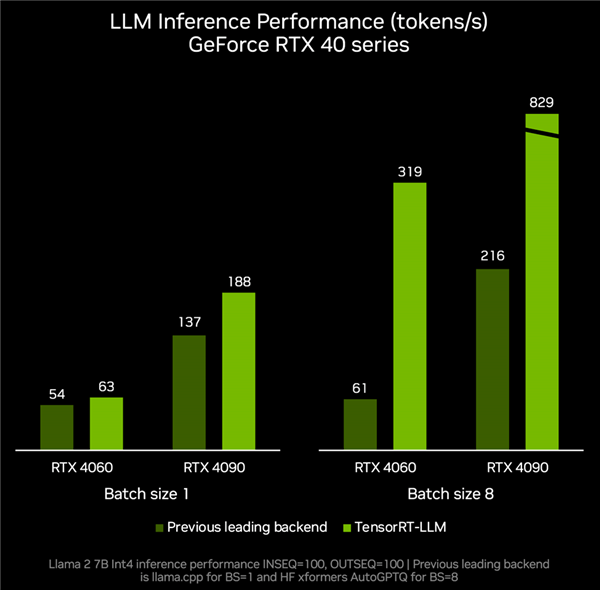
RTX 4060-Grafikkarte gepaart mit TenroRT-LLM, kann die Inferenzleistung 319 Token pro Sekunde erreichen, was ganze 4,2-mal schneller ist als die 61 Token pro Sekunde anderer Backends.RTX 4090 kann von Token pro Sekunde auf 829 Token pro Sekunde beschleunigen, was einer Steigerung um das 2,8-fache entspricht.
 Mit seiner leistungsstarken Hardwareleistung, seinem umfangreichen Entwicklungsökosystem und einer Vielzahl von Anwendungsszenarien wird NVIDIA RTX zu einem unverzichtbaren und leistungsstarken Assistenten für die lokale KI. Gleichzeitig beschleunigt sich mit der kontinuierlichen Anreicherung von Optimierungen, Modellen und Ressourcen auch die Beliebtheit von KI-Funktionen auf Hunderten Millionen RTX-PCs
Mit seiner leistungsstarken Hardwareleistung, seinem umfangreichen Entwicklungsökosystem und einer Vielzahl von Anwendungsszenarien wird NVIDIA RTX zu einem unverzichtbaren und leistungsstarken Assistenten für die lokale KI. Gleichzeitig beschleunigt sich mit der kontinuierlichen Anreicherung von Optimierungen, Modellen und Ressourcen auch die Beliebtheit von KI-Funktionen auf Hunderten Millionen RTX-PCs
Derzeit haben mehr als 400 Partner KI-Anwendungen und Spiele veröffentlicht, die die RTX-GPU-Beschleunigung unterstützen. Da sich die Benutzerfreundlichkeit der Modelle weiter verbessert, gehe ich davon aus, dass immer mehr AIGC-Funktionen auf der Windows-PC-Plattform erscheinen werden.
Das obige ist der detaillierte Inhalt vonDie NVIDIA RTX-Grafikkarte beschleunigt die KI-Inferenz um das Fünffache! Der RTX-PC bewältigt große Modelle problemlos lokal. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr