
Heim >Technologie-Peripheriegeräte >KI >Transformer überarbeitet: Inversion ist effektiver, es entsteht ein neuer SOTA für die Vorhersage in der realen Welt
Transformer überarbeitet: Inversion ist effektiver, es entsteht ein neuer SOTA für die Vorhersage in der realen Welt

- 王林nach vorne
- 2023-11-05 17:13:15708Durchsuche
Bei der Zeitreihenvorhersage hat Transformer seine leistungsstarke Fähigkeit unter Beweis gestellt, Abhängigkeiten zu beschreiben und mehrstufige Darstellungen zu extrahieren. Einige Forscher haben jedoch die Wirksamkeit transformatorbasierter Prädiktoren in Frage gestellt. Solche Prädiktoren betten typischerweise mehrere Variablen desselben Zeitstempels in nicht unterscheidbare Kanäle ein und konzentrieren sich auf diese Zeitstempel, um zeitliche Abhängigkeiten zu erfassen. Die Forscher fanden heraus, dass einfache lineare Schichten, die numerische Beziehungen statt semantischer Beziehungen berücksichtigen, komplexe Transformer sowohl in der Leistung als auch in der Effizienz übertrafen. Gleichzeitig hat die Bedeutung der Gewährleistung der Unabhängigkeit von Variablen und der Nutzung gegenseitiger Informationen in der neueren Forschung zunehmend Beachtung gefunden. Diese Studien modellieren explizit multivariate Korrelationen, um genaue Vorhersagen zu erzielen. Es ist jedoch immer noch schwierig, dieses Ziel zu erreichen, ohne die übliche Transformer-Architektur zu untergraben.
Angesichts der Kontroverse, die durch Transformer-basierte Prädiktoren verursacht wird, denken Forscher darüber nach, warum Transformer bei der Zeitreihenvorhersage nicht einmal so gut ist Als lineare Modelle in vielen anderen Bereichen, aber es dominiert in vielen anderen Bereichen
Kürzlich schlägt ein neuer Artikel der Tsinghua-Universität eine andere Perspektive vor – die Leistung von Transformer ist nicht inhärent, sondern wird durch die unsachgemäße Anwendung des Schemas verursacht zu Zeitreihendaten.

Der Link zum Artikel lautet: https://arxiv.org/pdf/2310.06625.pdf
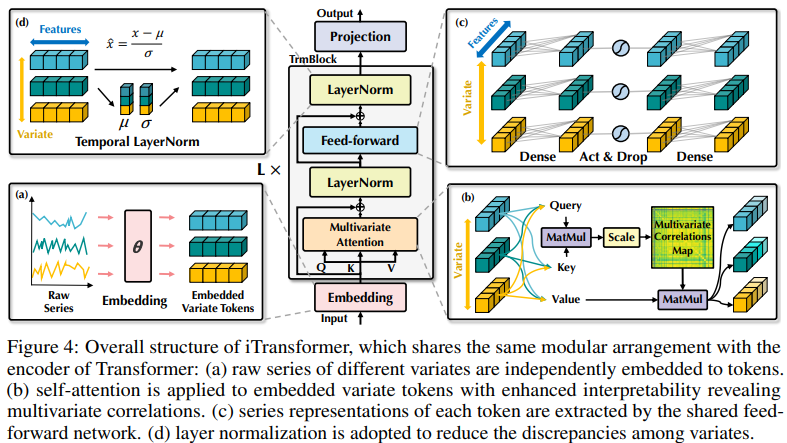
Die bestehende Struktur transformatorbasierter Prädiktoren ist möglicherweise nicht für multivariate Zeitreihenvorhersagen geeignet. Die linke Seite von Abbildung 2 zeigt, dass Punkte im gleichen Zeitschritt unterschiedliche physikalische Bedeutungen darstellen, die Messergebnisse jedoch inkonsistent sind. Diese Punkte sind in ein Token eingebettet und multivariate Korrelationen werden ignoriert. Darüber hinaus werden in der realen Welt einzelne Zeitschritte aufgrund der Fehlausrichtung lokaler Empfangsfelder und Zeitstempel zu multivariaten Zeitpunkten selten mit nützlichen Informationen gekennzeichnet. Obwohl die Sequenzvariation erheblich von der Sequenzreihenfolge beeinflusst wird, wurde der unterschiedliche Aufmerksamkeitsmechanismus in der zeitlichen Dimension nicht vollständig übernommen. Daher ist die Fähigkeit des Transformers, grundlegende Sequenzdarstellungen zu erfassen und multivariate Korrelationen zu beschreiben, geschwächt, was seine Fähigkeit und Generalisierungsfähigkeit auf verschiedene Zeitreihendaten einschränkt Bei einem (Zeit-)Token gehen Forscher von der umgekehrten Perspektive der Zeitreihen aus und betten die gesamte Zeitreihe jeder Variablen unabhängig in ein (Variablen-)Token ein. Dies ist ein Extremfall des Patchens, um das lokale Empfangsfeld zu erweitern. Durch Inversion aggregiert das eingebettete Token die globale Darstellung der Sequenz, die variablenzentrierter sein und den Aufmerksamkeitsmechanismus für die Assoziation mehrerer Variablen besser nutzen kann. Gleichzeitig können Feedforward-Netzwerke gekonnt verallgemeinerte Darstellungen verschiedener Variablen, die von einer beliebigen Lookback-Sequenz codiert werden, lernen und sie dekodieren, um zukünftige Sequenzen vorherzusagen.
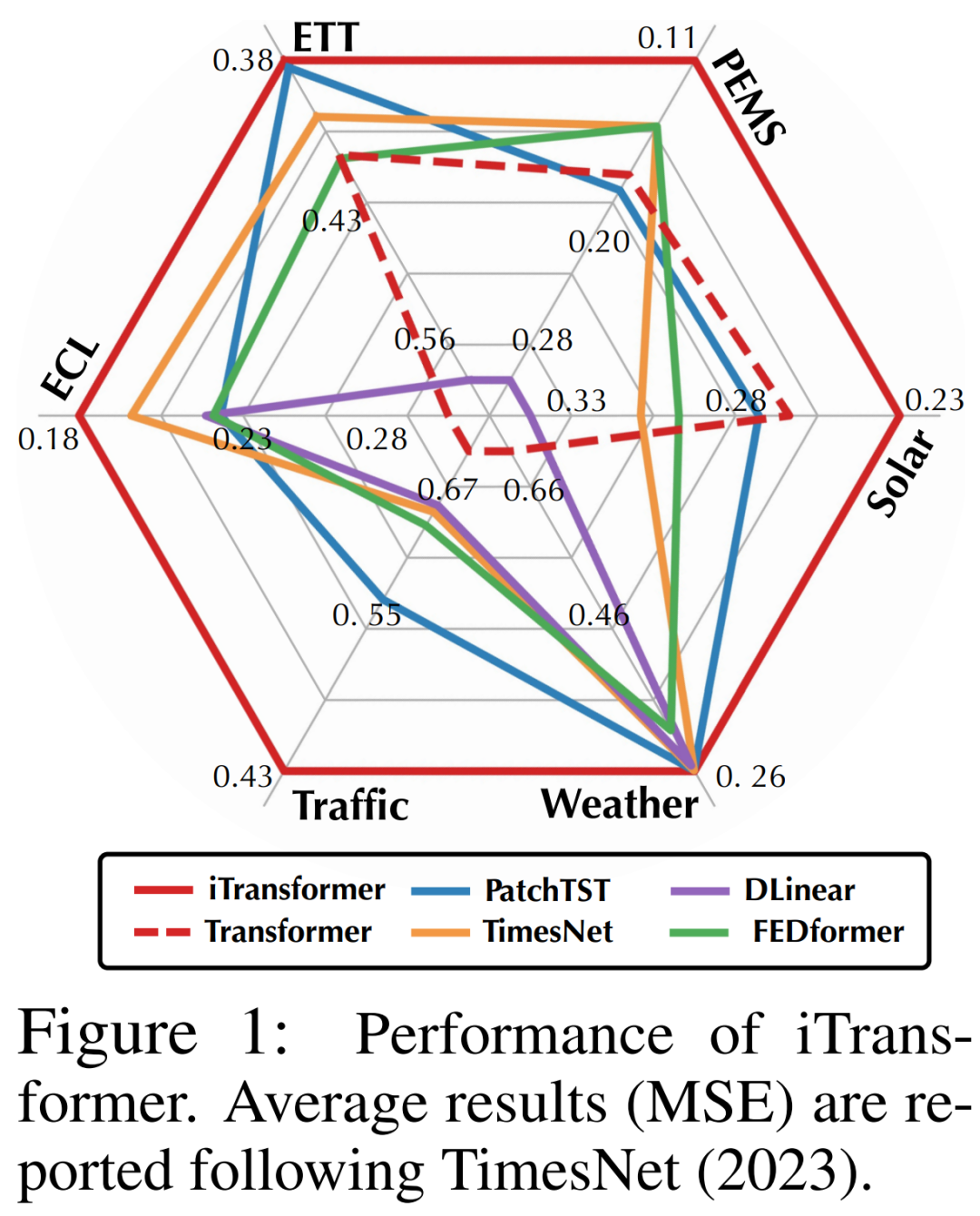
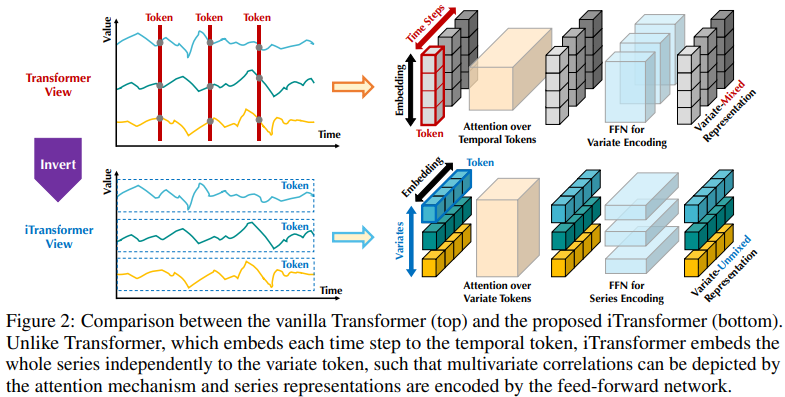 Forscher wiesen darauf hin, dass Transformer für die Vorhersage von Zeitreihen zwar nicht ungültig, seine Verwendung jedoch unangemessen ist. In diesem Artikel untersuchten die Forscher die Struktur von Transformer erneut und empfahlen iTransformer als Grundpfeiler der Zeitreihenvorhersage. Sie betten jede Zeitreihe als variables Token ein, übernehmen einen Korrelationsaufmerksamkeitsmechanismus mit mehreren Variablen und verwenden ein Feed-Forward-Netzwerk, um die Sequenz zu kodieren. Experimentelle Ergebnisse zeigen, dass der vorgeschlagene iTransformer im tatsächlichen Vorhersage-Benchmark (Abbildung 1) das neueste Niveau erreicht und unerwartet die Probleme löst, mit denen Transformer-basierte Prädiktoren konfrontiert sind.
Forscher wiesen darauf hin, dass Transformer für die Vorhersage von Zeitreihen zwar nicht ungültig, seine Verwendung jedoch unangemessen ist. In diesem Artikel untersuchten die Forscher die Struktur von Transformer erneut und empfahlen iTransformer als Grundpfeiler der Zeitreihenvorhersage. Sie betten jede Zeitreihe als variables Token ein, übernehmen einen Korrelationsaufmerksamkeitsmechanismus mit mehreren Variablen und verwenden ein Feed-Forward-Netzwerk, um die Sequenz zu kodieren. Experimentelle Ergebnisse zeigen, dass der vorgeschlagene iTransformer im tatsächlichen Vorhersage-Benchmark (Abbildung 1) das neueste Niveau erreicht und unerwartet die Probleme löst, mit denen Transformer-basierte Prädiktoren konfrontiert sind.
Die Beiträge lauten wie folgt:
Der in diesem Artikel vorgeschlagene iTransformer behandelt unabhängige Zeitreihen als Token, erfasst multivariable Korrelationen durch Selbstaufmerksamkeit und verwendet Schichtnormalisierungs- und Feed-Forward-Netzwerkmodule, um bessere globale Sequenzdarstellungen für die Vorhersage von Zeitreihen zu lernen.
- Durch Experimente erreicht iTransformer SOTA bei realen Vorhersage-Benchmarks. Die Forscher analysierten das Inversionsmodul und die Architekturoptionen und zeigten die Richtung für zukünftige Verbesserungen transformatorbasierter Prädiktoren auf.
- iTransformer
- Bei der multivariaten Zeitreihenvorhersage, gegebene historische Beobachtungen:
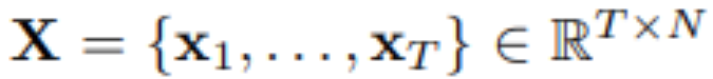
Unter Verwendung von T Zeitschritten und N Variablen sagt der Forscher S Zeitschritte in der Zukunft voraus: 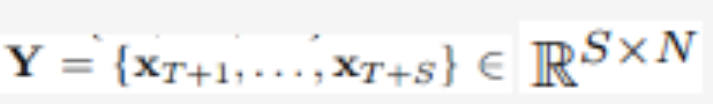 . Der Einfachheit halber bezeichnen wir als
. Der Einfachheit halber bezeichnen wir als 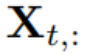 die multivariaten Variablen, die gleichzeitig zum Zeitpunkt t aufgezeichnet wurden, und
die multivariaten Variablen, die gleichzeitig zum Zeitpunkt t aufgezeichnet wurden, und 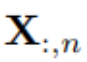 als die gesamte Zeitreihe, wobei jede Variable durch n indiziert ist. Es ist erwähnenswert, dass
als die gesamte Zeitreihe, wobei jede Variable durch n indiziert ist. Es ist erwähnenswert, dass 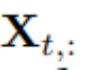 in der realen Welt aufgrund der Systemlatenz von Monitoren und lose organisierten Datensätzen möglicherweise keine Zeitpunkte mit im Wesentlichen demselben Zeitstempel enthält. Elemente von
in der realen Welt aufgrund der Systemlatenz von Monitoren und lose organisierten Datensätzen möglicherweise keine Zeitpunkte mit im Wesentlichen demselben Zeitstempel enthält. Elemente von
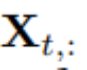 können sich in physikalischen Messungen und statistischen Verteilungen voneinander unterscheiden, und Variablen
können sich in physikalischen Messungen und statistischen Verteilungen voneinander unterscheiden, und Variablen 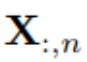 teilen diese Daten häufig.
teilen diese Daten häufig.
Die mit der in diesem Artikel vorgeschlagenen Architektur ausgestattete Transformer-Variante namens iTransformer stellt grundsätzlich keine spezifischeren Anforderungen an die Transformer-Variante, außer dass der Aufmerksamkeitsmechanismus für die multivariate Korrelationsmodellierung geeignet sein sollte. Daher kann ein effektiver Satz von Aufmerksamkeitsmechanismen als Plug-in dienen, um die Komplexität von Assoziationen zu verringern, wenn die Anzahl der Variablen zunimmt.
iTransformer ist im vierten Bild dargestellt und verwendet eine einfachere Transformer-Encoder-Architektur, die Einbettungs-, Projektions- und Transformer-Blöcke umfasst.
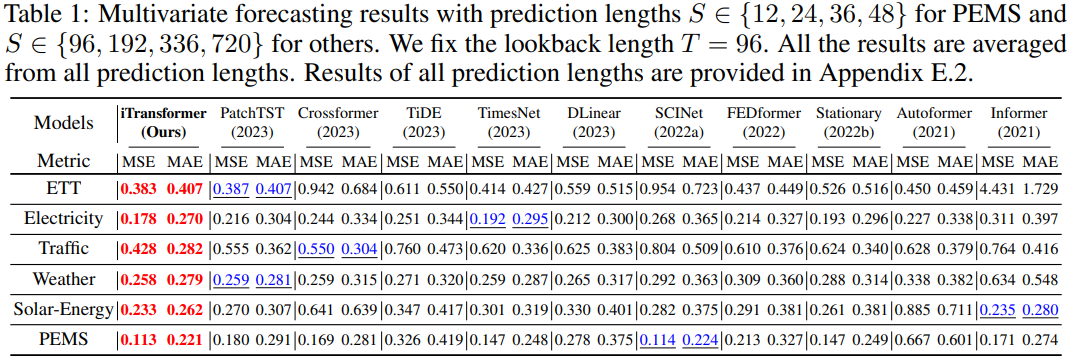
Experimente und Ergebnisse wurde in verschiedenen Zeitreihen-Prognoseanwendungen durchgeführt, um die Vielseitigkeit des Frameworks zu bestätigen und den Effekt der Umkehrung der Verantwortlichkeiten der Transformer-Komponente für bestimmte Zeitreihendimensionen weiter zu untersuchen. Die Forscher haben 6 reale Daten umfassend in das Experiment einbezogen Weltdatensätze, einschließlich ETT-, Wetter-, Strom-, Verkehrsdatensätze, Solarenergie-Datensätze und PEMS-Datensätze. Ausführliche Informationen zum Datensatz finden Sie im Originaltext
Der umgeschriebene Inhalt lautet: Die Vorhersageergebnisse
sind in Tabelle 1 dargestellt, wobei Rot das Optimum und Unterstrich das Optimum angibt. Je niedriger der MSE/MAE-Wert ist, desto genauer sind die Vorhersageergebnisse. Der in diesem Artikel vorgeschlagene iTransformer erreicht SOTA-Leistung. Die native Transformer-Komponente ist zur Zeitmodellierung und multivariaten Korrelation fähig, und die vorgeschlagene invertierte Architektur kann reale Zeitreihenvorhersageszenarien effektiv lösen.
Was neu geschrieben werden muss, ist: Universalität von iTransformer
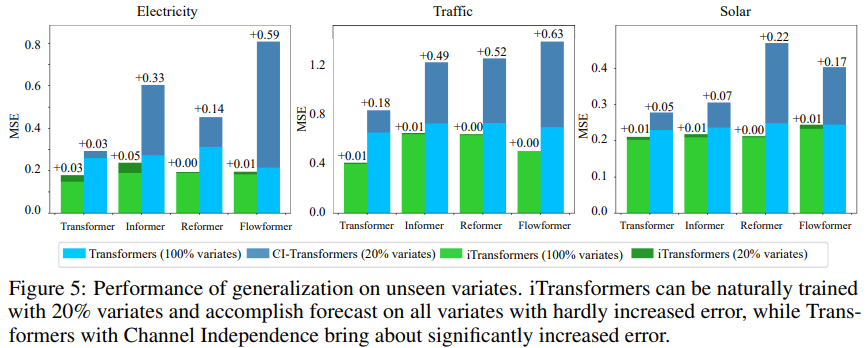
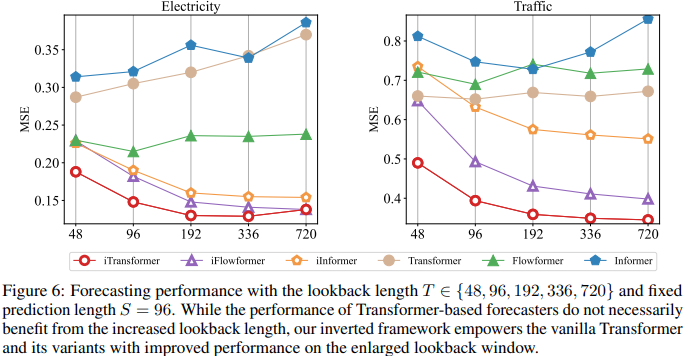
Ein weiterer Faktor ist, dass iTransformer häufig in transformatorbasierten Prädiktoren verwendet werden kann, da es die umgekehrte Struktur des Aufmerksamkeitsmechanismus in der Variablendimension übernimmt, effiziente Aufmerksamkeit mit linearer Komplexität einführt und Effizienzprobleme aufgrund von 6 Variablen grundsätzlich löst. Dieses Problem tritt häufig in realen Anwendungen auf, kann jedoch für Channel Independent ressourcenintensiv sein. Um die Hypothese zu testen, verglichen die Forscher iTransformer mit einer anderen Generalisierungsstrategie: Channel Independent Force Muster für alle Varianten. Wie in Abbildung 5 dargestellt, kann der Generalisierungsfehler von Channel Independent (CI-Transformers) erheblich zunehmen, während der Anstieg des iTransformer-Vorhersagefehlers viel geringer ist. Da die Verantwortlichkeiten von Aufmerksamkeits- und Feedforward-Netzwerken umgekehrt sind, wird die Leistung von Transformers und iTransformer mit zunehmender Lookback-Länge in Abbildung 6 bewertet. Es bestätigt die Rationalität der Nutzung von MLP in der zeitlichen Dimension, d. h. Transformatoren können von erweiterten Rückblickfenstern profitieren, was zu genaueren Vorhersagen führt. Modellanalyse Um die Rationalität der Transformer-Komponente zu überprüfen, führten die Forscher detaillierte Ablationsexperimente durch, einschließlich Experimenten zum Komponentenaustausch (Replace) und Komponentenentfernung (w/o). Tabelle 3 listet die experimentellen Ergebnisse auf. Weitere Einzelheiten finden Sie im Originalartikel. 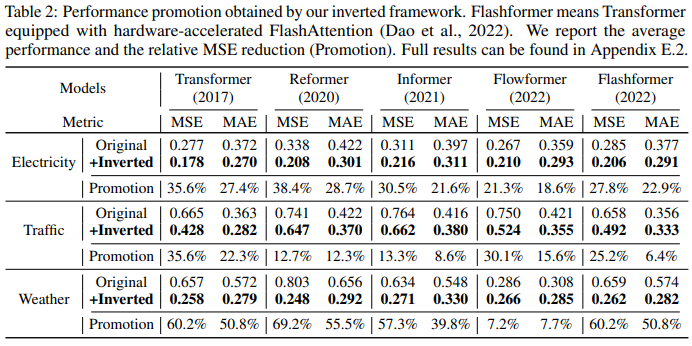
Das obige ist der detaillierte Inhalt vonTransformer überarbeitet: Inversion ist effektiver, es entsteht ein neuer SOTA für die Vorhersage in der realen Welt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Die C-Sprache kann beim Aufrufen der Funktion in main keinen Bezeichner finden
- Ein College-Student, der GPT-3 zum Schreiben einer Arbeit verwendete, wurde hart bestraft und weigerte sich, dies zuzugeben! Universitätspapiere sind „tot', ChatGPT könnte ein großes Erdbeben im akademischen Kreis auslösen
- Die Blackbox von AlphaZero ist geöffnet! DeepMind-Artikel in PNAS veröffentlicht
- Wirklich wichtige Forschung! 32 Artikel nehmen die KI-Hotspots im Jahr 2022 unter die Lupe
- Dieser „Fehler' ist nicht wirklich ein Fehler: Beginnen Sie mit vier klassischen Aufsätzen, um zu verstehen, was am Transformer-Architekturdiagramm „falsch' ist