
Heim >Technologie-Peripheriegeräte >KI >Dieser „Fehler' ist nicht wirklich ein Fehler: Beginnen Sie mit vier klassischen Aufsätzen, um zu verstehen, was am Transformer-Architekturdiagramm „falsch' ist
Dieser „Fehler' ist nicht wirklich ein Fehler: Beginnen Sie mit vier klassischen Aufsätzen, um zu verstehen, was am Transformer-Architekturdiagramm „falsch' ist

- 王林nach vorne
- 2023-06-14 13:43:171661Durchsuche
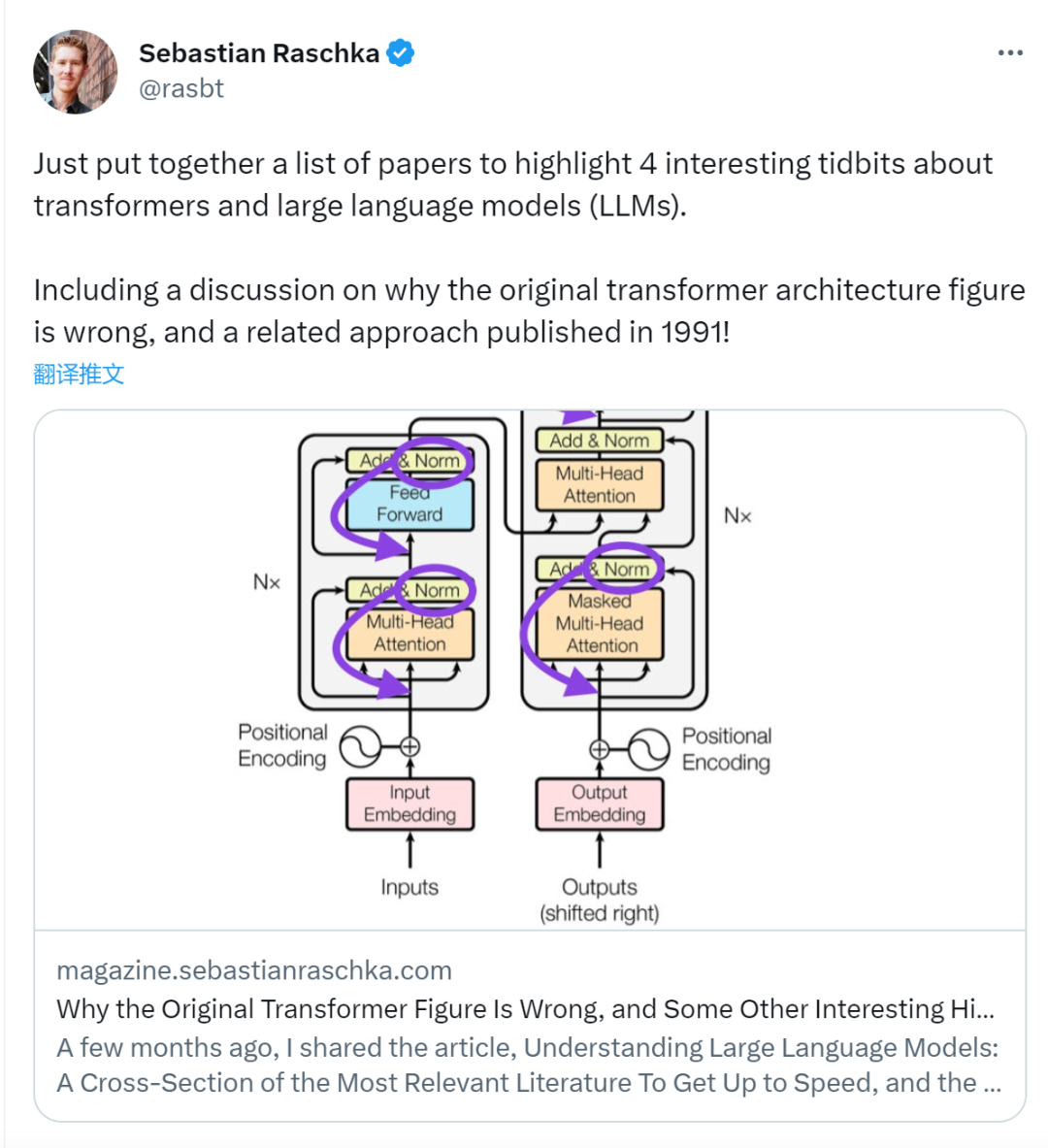
Vor einiger Zeit löste ein Tweet, der auf die Inkonsistenz zwischen dem Transformer-Architekturdiagramm und dem Code im Artikel „Attention Is All You Need“ des Google Brain-Teams hinwies, viele Diskussionen aus.
Manche Leute denken, dass Sebastians Entdeckung ein ehrlicher Fehler war, aber es ist gleichzeitig auch seltsam. Angesichts der Popularität des Transformer-Papiers hätte diese Inkonsistenz schließlich tausendmal erwähnt werden müssen.
Sebastian Raschka antwortete auf Kommentare von Internetnutzern, dass der „originellste“ Code zwar mit dem Architekturdiagramm übereinstimme, die 2017 eingereichte Codeversion jedoch geändert, das Architekturdiagramm jedoch nicht gleichzeitig aktualisiert worden sei. Dies ist auch die Ursache für „inkonsistente“ Diskussionen.
Anschließend veröffentlichte Sebastian einen Artikel über Ahead of AI, in dem er insbesondere beschrieb, warum das ursprüngliche Transformer-Architekturdiagramm nicht mit dem Code übereinstimmte, und zitierte mehrere Artikel, um die Entwicklung und Änderungen von Transformer kurz zu erläutern.
Das Folgende ist der Originaltext des Artikels. Schauen wir uns an, worum es in dem Artikel geht:
Vor ein paar Monaten habe ich „Große Sprachmodelle verstehen: Ein Kreuz“ geteilt -Abschnitt der „relevantesten Literatur, um sich auf den neuesten Stand zu bringen“ – das positive Feedback ist sehr ermutigend! Deshalb habe ich ein paar Artikel hinzugefügt, um die Liste aktuell und relevant zu halten.
Gleichzeitig ist es wichtig, die Liste prägnant und prägnant zu halten, damit sich alle in angemessener Zeit einarbeiten können. Es gibt auch einige Papiere, die viele Informationen enthalten und unbedingt beigefügt werden sollten.
Ich möchte vier nützliche Artikel vorstellen, um Transformer aus historischer Perspektive zu verstehen. Während ich sie nur direkt zum Artikel „Grundlegende große Sprachmodelle“ hinzufüge, teile ich sie in diesem Artikel auch separat, damit sie von denjenigen, die bereits zuvor „Grundlegende große Sprachmodelle“ gelesen haben, leichter gefunden werden können.
On Layer Normalization in the Transformer Architecture (2020)
Obwohl das ursprüngliche Transformer-Bild (links) unten (https://arxiv.org/abs/1706.03762) die ursprüngliche Encoder-Dekodierung A nützlich ist Zusammenfassung der Serverarchitektur, es gibt jedoch einen kleinen Unterschied im Diagramm. Es führt beispielsweise eine Ebenennormalisierung zwischen Restblöcken durch, die nicht mit der offiziellen (aktualisierten) Codeimplementierung übereinstimmt, die im ursprünglichen Transformer-Papier enthalten ist. Die unten (Mitte) gezeigte Variante wird als Post-LN-Transformator bezeichnet. Die Ebenennormalisierung im
Transformer-Architekturpapier zeigt, dass Pre-LN besser funktioniert und das Gradientenproblem wie unten gezeigt lösen kann. Viele Architekturen übernehmen diesen Ansatz in der Praxis, er kann jedoch zu einem Zusammenbruch der Darstellung führen.
Während es immer noch Diskussionen über die Verwendung von Post-LN oder Pre-LN gibt, gibt es auch ein neues Papier, das die gemeinsame Anwendung beider vorschlägt: „ResiDual: Transformer with Dual Residual Connections“ (https://arxiv .org /abs/2304.14802), aber es bleibt abzuwarten, ob es in der Praxis nützlich sein wird.
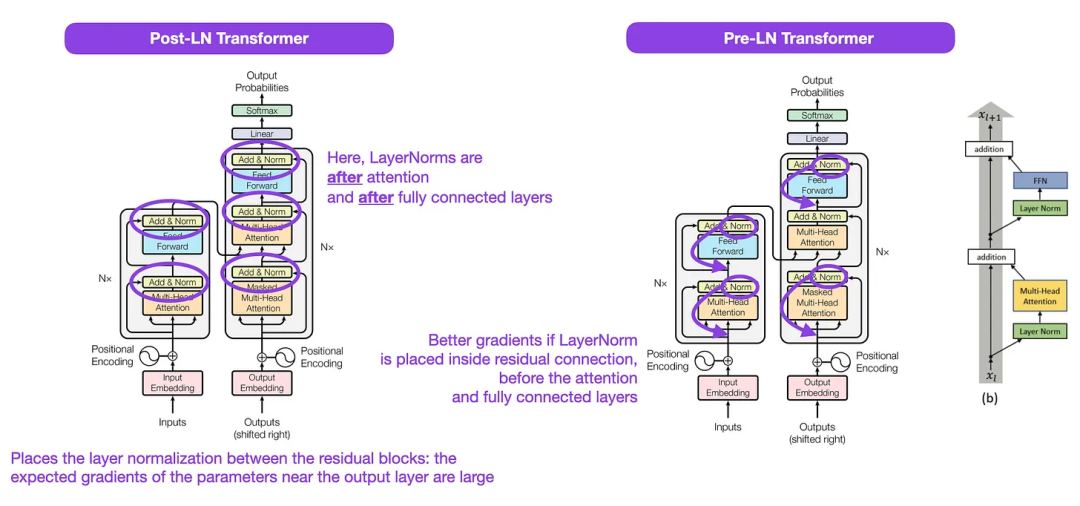
Bildquelle: https://arxiv.org/abs/1706.03762 (links & Mitte) und https://arxiv.org/abs/2002.04745 (rechts)
Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Neural Networks (1991)
Dieser Artikel wird allen empfohlen, die sich für historische Leckerbissen und frühe Methoden interessieren, die im Grunde dem modernen Transformer ähneln.
Zum Beispiel schlug Jürgen Schmidhuber 1991, 25 Jahre vor dem Transformer-Artikel, eine Alternative zu rekurrenten neuronalen Netzen vor (https://www.semanticscholar.org/paper/Learning-to-Control-Fast-Weight-Memories%3A -An-to-Schmidhuber/bc22e87a26d020215afe91c751e5bdaddd8e4922), genannt Fast Weight Programmers (FWP). Ein weiteres neuronales Netzwerk, das schnelle Gewichtsänderungen erreicht, ist das an der FWP-Methode beteiligte Feedforward-Neuronale Netzwerk, das mithilfe des Gradientenabstiegsalgorithmus langsam lernt.
Dieser Blog (https://people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html#sec2) vergleicht es mit dem modernen Transformer wie folgt:
Im heutigen Transformer In der Terminologie werden FROM und TO als Schlüssel bzw. Wert bezeichnet. Die Eingabe, auf die das schnelle Netzwerk angewendet wird, wird als Abfrage bezeichnet. Im Wesentlichen werden Abfragen von einer schnellen Gewichtungsmatrix verarbeitet, die die Summe der äußeren Produkte von Schlüsseln und Werten ist (ohne Berücksichtigung von Normalisierung und Projektion). Wir können additive äußere Produkte oder Tensorprodukte zweiter Ordnung verwenden, um eine durchgängig differenzierbare aktive Steuerung schneller Gewichtsänderungen zu erreichen, da alle Operationen beider Netzwerke die Differenzierung unterstützen. Während der Sequenzverarbeitung kann der Gradientenabstieg verwendet werden, um schnelle Netzwerke schnell anzupassen, um die Probleme langsamer Netzwerke zu bewältigen. Dies ist mathematisch äquivalent (mit Ausnahme der Normalisierung) zu dem, was heute als Transformer mit linearisierter Selbstaufmerksamkeit (oder linearer Transformer) bekannt ist.
Wie im obigen Auszug erwähnt, ist dieser Ansatz heute als linearer Transformer oder Transformer mit linearisierter Selbstaufmerksamkeit bekannt. Sie stammen aus den Artikeln „Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention“ (https://arxiv.org/abs/2006.16236) und „Rethinking Attention with Performers“ (https://arxiv. org/abs/2009.14794). .
Im Jahr 2021 zeigt der Artikel „Linear Transformers Are Secretly Fast Weight Programmers“ (https://arxiv.org/abs/2102.11174) deutlich den Unterschied zwischen linearisierter Selbstaufmerksamkeit und den Fast-Weight-Programmierern der 1990er-Äquivalenz.
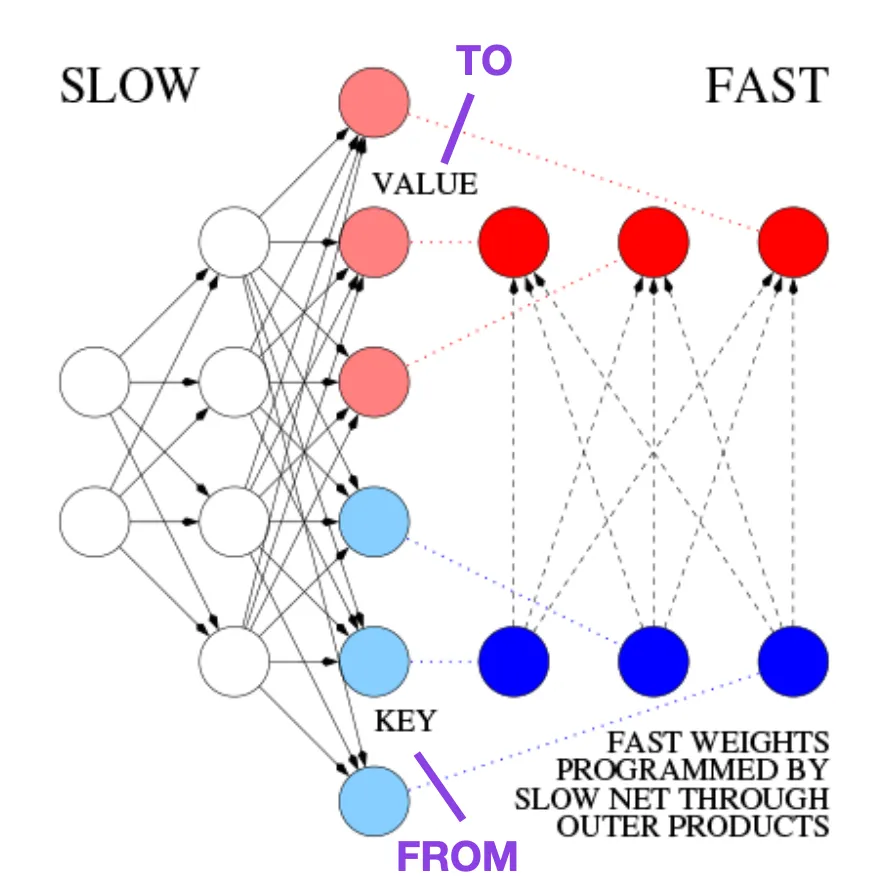
Bildquelle: https://people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html#sec2
Universal Feinabstimmung des Sprachmodells für die Textklassifizierung (2018)
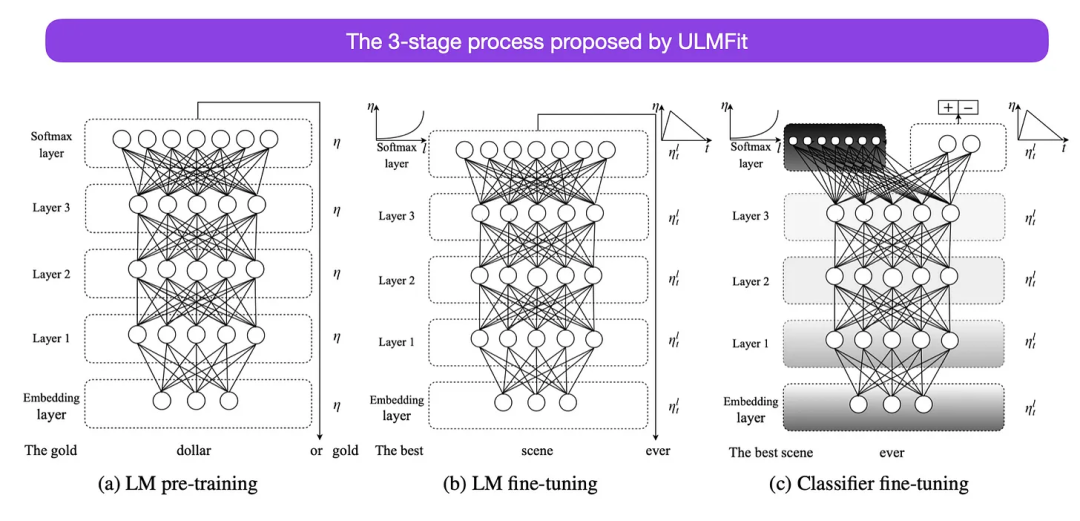
Dies ist ein weiterer sehr interessanter Artikel aus historischer Sicht. Es wurde ein Jahr nach der Veröffentlichung des Originals „Attention Is All You Need“ geschrieben und beinhaltet keine Transformatoren, sondern konzentriert sich stattdessen auf wiederkehrende neuronale Netze, ist aber trotzdem sehenswert. Weil es effektiv vorab trainierte Sprachmodelle und nachgelagerte Aufgaben des Transferlernens vorschlägt. Obwohl Transferlernen in der Computer Vision gut etabliert ist, hat es sich im Bereich der Verarbeitung natürlicher Sprache (NLP) noch nicht durchgesetzt. ULMFit (https://arxiv.org/abs/1801.06146) war einer der ersten Artikel, der zeigte, dass vorab trainierte Sprachmodelle bei vielen NLP-Aufgaben SOTA-Ergebnisse liefern können, wenn sie auf eine bestimmte Aufgabe abgestimmt werden.
Der von ULMFit vorgeschlagene Feinabstimmungsprozess für das Sprachmodell ist in drei Phasen unterteilt:
- 1. Trainieren des Sprachmodells anhand eines großen Textkorpus;
- 2 -spezifische Daten Das Modell ist so abgestimmt, dass es sich an den spezifischen Stil und das Vokabular des Textes anpassen kann
- 3 Passen Sie den Klassifikator an aufgabenspezifische Daten an, um katastrophales Vergessen zu vermeiden, indem Sie die Ebenen schrittweise auftauen.
Diese Methode zum Trainieren eines Sprachmodells auf einem großen Korpus und zur anschließenden Feinabstimmung auf nachgelagerte Aufgaben basiert auf Transformer-Modellen und Basismodellen (wie BERT, GPT-2/3/4, RoBERTa usw.). ) verwendete Kernmethoden.
Als wichtiger Bestandteil von ULMFiT wird das progressive Auftauen jedoch in der Praxis normalerweise nicht durchgeführt, da die Transformer-Architektur normalerweise alle Ebenen gleichzeitig feinabstimmt.
Gopher ist ein besonders gutes Papier (https://arxiv.org/abs/2112.11446), das umfangreiche Analysen zum Verständnis der LLM-Ausbildung enthält. Die Forscher trainierten ein 80-schichtiges Modell mit 280 Milliarden Parametern auf 300 Milliarden Token. Dazu gehören einige interessante Architekturmodifikationen, wie z. B. die Verwendung von RMSNorm (Root Mean Square Normalization) anstelle von LayerNorm (Layer Normalization). Sowohl LayerNorm als auch RMSNorm sind besser als BatchNorm, da sie nicht auf die Stapelgröße beschränkt sind und keine Synchronisierung erfordern, was in verteilten Einstellungen mit kleineren Stapelgrößen von Vorteil ist. RMSNorm gilt allgemein als stabilisierendes Training in tieferen Architekturen.
Neben den oben genannten interessanten Details liegt der Schwerpunkt dieses Artikels auf der Analyse der Aufgabenleistungsanalyse auf verschiedenen Ebenen. Eine Auswertung von 152 verschiedenen Aufgaben zeigt, dass eine Vergrößerung der Modellgröße für Aufgaben wie Verständnis, Faktenprüfung und Identifizierung toxischer Sprache am vorteilhaftesten ist, während die Erweiterung der Architektur für Aufgaben im Zusammenhang mit logischem und mathematischem Denken weniger vorteilhaft ist.
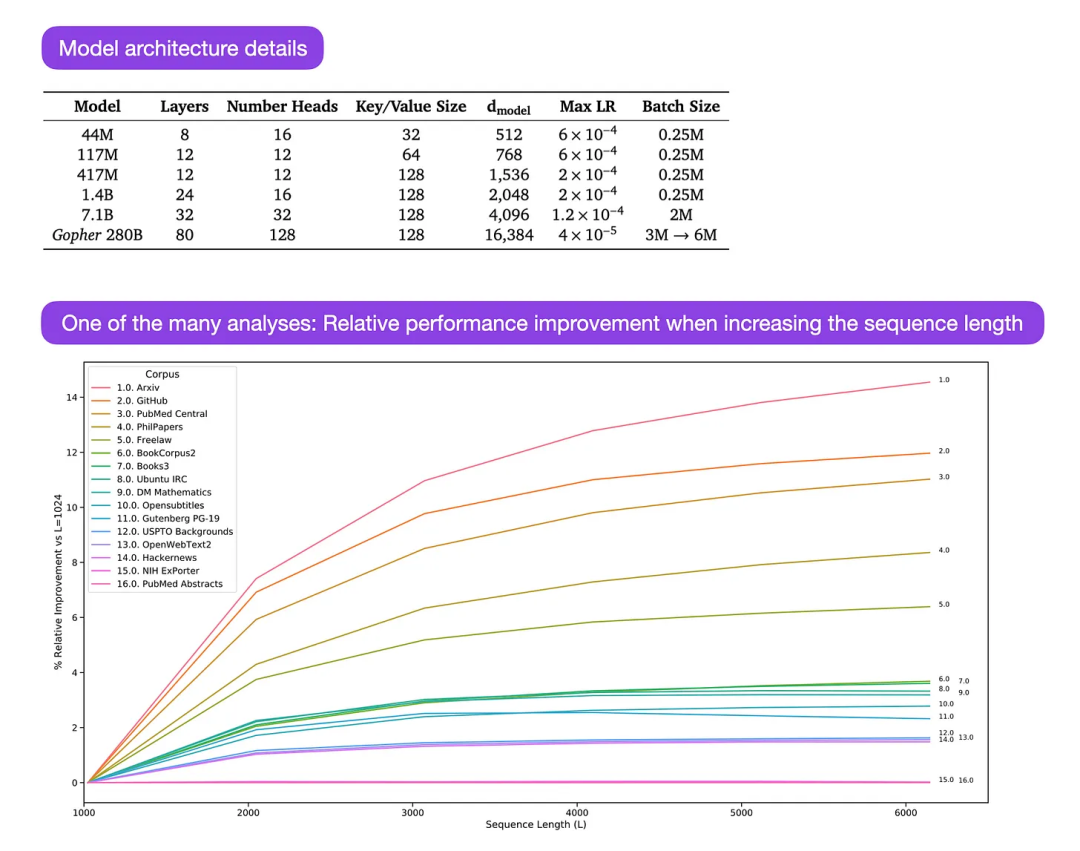
Bildunterschrift: Quelle https://arxiv.org/abs/2112.11446
Das obige ist der detaillierte Inhalt vonDieser „Fehler' ist nicht wirklich ein Fehler: Beginnen Sie mit vier klassischen Aufsätzen, um zu verstehen, was am Transformer-Architekturdiagramm „falsch' ist. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr