
Heim >Technologie-Peripheriegeräte >KI >Je mehr Wörter das Dokument enthält, desto aufgeregter wird das Model sein! KOSMOS-2.5: Multimodales großes Sprachmodell zum Lesen von „textdichten Bildern'
Je mehr Wörter das Dokument enthält, desto aufgeregter wird das Model sein! KOSMOS-2.5: Multimodales großes Sprachmodell zum Lesen von „textdichten Bildern'

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-09-29 20:13:10786Durchsuche
Ein klarer Trend geht derzeit in Richtung der Erstellung größerer und komplexerer Modelle mit Dutzenden/Hunderten Milliarden von Parametern, die eine beeindruckende Sprachausgabe erzeugen können.
Bestehende große Sprachmodelle konzentrieren sich jedoch hauptsächlich auf Textinformationen und sind nicht in der Lage, visuelle Informationen zu verstehen.
Fortschritte auf dem Gebiet der multimodalen großen Sprachmodelle (MLLMs) zielen darauf ab, diese Einschränkung zu beseitigen. MLLMs verschmelzen visuelle und textliche Informationen in einem einzigen transformatorbasierten Modell, sodass sich das Modell an beide Lernmodalitäten anpassen und Inhalte generieren kann.
MLLMs zeigen Potenzial in verschiedenen praktischen Anwendungen, einschließlich des natürlichen Bildverständnisses und des Textbildverständnisses. Diese Modelle nutzen die Sprachmodellierung als gemeinsame Schnittstelle zur Behandlung multimodaler Probleme und ermöglichen es ihnen, Antworten basierend auf Text- und visuellen Eingaben zu verarbeiten und zu generieren
Derzeit liegt der Schwerpunkt jedoch auf MLLMs mit natürlichen Bildern mit niedrigerer Auflösung dicht für Text. Es gibt relativ wenig Forschung zu Bildern. Daher ist die umfassende Nutzung groß angelegter multimodaler Vorschulungen zur Verarbeitung von Textbildern zu einer wichtigen Richtung der MLLM-Forschung geworden kann neue Wege mit hochauflösenden neuen Möglichkeiten für multimodale Anwendungen von textdichten Bildern eröffnen.
Bilder
 Papieradresse: https://arxiv.org/abs/2309.11419
Papieradresse: https://arxiv.org/abs/2309.11419
KOSMOS-2.5 ist ein multimodales, groß angelegtes Sprachmodell, das auf Bildern mit hoher Textdichte basiert entwickelt in KOSMOS- Auf Basis von 2 entwickelt, hebt es die multimodalen Lese- und Verständnisfähigkeiten textintensiver Bilder hervor (Multimodal Literate Model).
Der Vorschlag dieses Modells unterstreicht seine hervorragende Leistung beim Verstehen textintensiver Bilder und schließt die Lücke zwischen Vision und Text.
Gleichzeitig markiert es auch die Entwicklung des Aufgabenparadigmas gegenüber der vorherigen Codierung Decoder-Decoder-Architektur zur reinen Decoder-Architektur
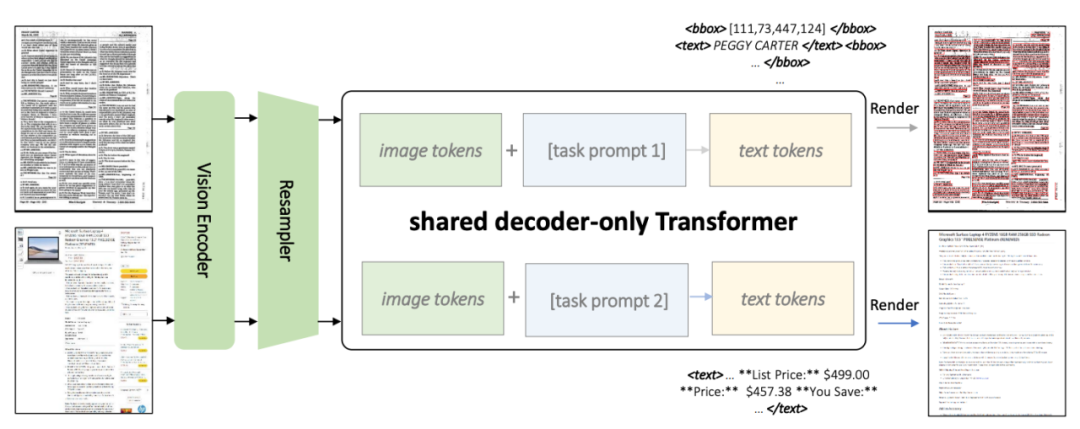
Das Ziel von KOSMOS-2.5 ist es, eine nahtlose visuelle und textuelle Datenverarbeitung in textreichen Bildern zu ermöglichen, um Bildinhalte zu verstehen und strukturierte Textbeschreibungen zu generieren. Abbildung 1: Übersicht über KOSMOS-2.5 Die erste Aufgabe besteht darin, einen raumbezogenen Textblock zu generieren, also gleichzeitig den Inhalt und den Koordinatenrahmen des Textblocks zu generieren. Was neu geschrieben werden muss, ist: Die erste Aufgabe besteht darin, einen räumlich bewussten Textblock zu generieren, d. h. den Inhalt des Textblocks und des Koordinatenfelds gleichzeitig zu generieren. Die zweite Aufgabe besteht darin, eine strukturierte Textausgabe im Markdown-Format zu generieren. und Erfassen verschiedener Stile und Strukturen
Abbildung 2: KOSMOS-2.5-Architekturdiagramm
 Wie in Abbildung 2 gezeigt, verwenden beide Aufgaben eine gemeinsame Transformer-Architektur und aufgabenspezifische Hinweise
Wie in Abbildung 2 gezeigt, verwenden beide Aufgaben eine gemeinsame Transformer-Architektur und aufgabenspezifische Hinweise
KOSMOS-2.5 kombiniert einen visuellen Encoder auf Basis von ViT (Vision Transformer) mit einem Decoder auf Basis der Transformer-Architektur, verbunden über ein Resampling-Modul. Abbildung 3: Datensatz vor dem Training
Abbildung 4: Beispiel eines Trainingsbeispiels für Textzeilen mit BegrenzungsrahmenAbbildung 5: Beispiel eines Trainingsbeispiels im Markdown-Format
 Dieser Datensatz enthält verschiedene Arten von Bildern mit hoher Textdichte, einschließlich Textzeilen mit Begrenzungsrahmen und einfachem Text im Markdown-Format. Die Abbildungen 4 und 5 sind Beispielvisualisierungen für das Training.
Dieser Datensatz enthält verschiedene Arten von Bildern mit hoher Textdichte, einschließlich Textzeilen mit Begrenzungsrahmen und einfachem Text im Markdown-Format. Die Abbildungen 4 und 5 sind Beispielvisualisierungen für das Training.
Diese Multitasking-Trainingsmethode verbessert die gesamten multimodalen Fähigkeiten von KOSMOS-2.5
 [Abbildung 6] End-to-End-Experiment zur Texterkennung auf Dokumentebene
[Abbildung 6] End-to-End-Experiment zur Texterkennung auf Dokumentebene
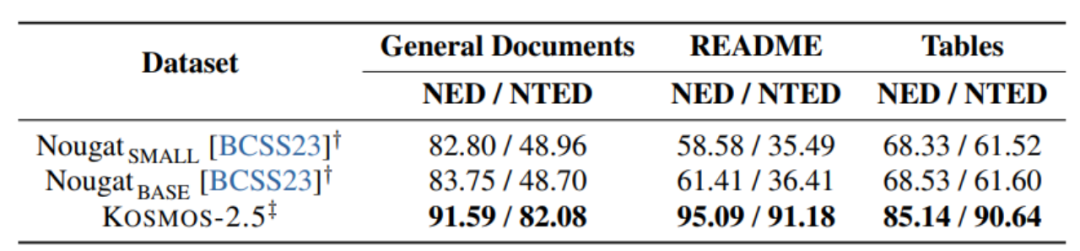 Abbildung 7: Experiment zur Generierung von Text im Markdown-Format aus Bildern
Abbildung 7: Experiment zur Generierung von Text im Markdown-Format aus Bildern
Wie in Abbildung 6 und Abbildung 7 gezeigt, KOSMOS- 2.5 Es wird anhand von zwei Aufgaben bewertet: End-to-End-Texterkennung auf Dokumentebene und Generierung von Markdown-formatiertem Text aus Bildern.
KOSMOS-2.5 schneidet bei der Verarbeitung textintensiver Bildaufgaben gut ab, und die experimentellen Ergebnisse zeigen dies
 Abbildung 8: Eingabe- und Ausgabebeispielanzeige von KOSMOS-2.5
Abbildung 8: Eingabe- und Ausgabebeispielanzeige von KOSMOS-2.5
KOSMOS- 2.5 demonstriert Vielversprechende Fähigkeiten sowohl in Wenig-Schuss-Lernszenarien als auch in Null-Schuss-Lernszenarien, was es zu einem vielseitigen Werkzeug für praktische Anwendungen bei der Verarbeitung textreicher Bilder macht. Es kann als vielseitiges Werkzeug angesehen werden, das textreiche Bilder effektiv verarbeiten kann und vielversprechende Fähigkeiten im Falle von Wenig-Schuss-Lernen und Null-Schuss-Lernen zeigt. Der Autor weist darauf hin, dass die Feinabstimmung von Anweisungen sehr vielversprechend ist Das Tool „Prospect“ kann eine breitere Anwendungsfähigkeit des Modells erreichen.
Im breiteren Forschungsfeld liegt eine wichtige Richtung in der Weiterentwicklung der Fähigkeit zur Erweiterung von Modellparametern.
Da Aufgaben immer umfangreicher und komplexer werden, ist die Skalierung von Modellen zur Verarbeitung größerer Datenmengen von entscheidender Bedeutung für die Entwicklung textintensiver multimodaler Modelle.
Das ultimative Ziel besteht darin, ein Modell zu entwickeln, das visuelle und textliche Daten effektiv interpretieren und erfolgreich auf textintensivere multimodale Aufgaben verallgemeinern kann.
Beim Umschreiben des Inhalts muss er ins Chinesische umgeschrieben werden und der Originalsatz muss nicht erscheinen
https://arxiv.org/abs/2309.11419
Das obige ist der detaillierte Inhalt vonJe mehr Wörter das Dokument enthält, desto aufgeregter wird das Model sein! KOSMOS-2.5: Multimodales großes Sprachmodell zum Lesen von „textdichten Bildern'. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!