
Heim >Technologie-Peripheriegeräte >KI >Neuer Titel: Aufdecken, warum große Modelle langsamer werden: Neue Wege für Algorithmen des menschlichen Geistes
Neuer Titel: Aufdecken, warum große Modelle langsamer werden: Neue Wege für Algorithmen des menschlichen Geistes

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-09-14 14:53:091219Durchsuche
KI-Forscher ignorieren oft die menschliche Intuition, aber tatsächlich verstehen wir selbst ihre Subtilität nicht vollständig. Kürzlich hat ein Forschungsteam von Virginia Tech und Microsoft einen Algorithm of Thinking (AoT) vorgeschlagen, der intuitive Fähigkeiten mit algorithmischen Methoden kombiniert, um nicht nur die LLM-Leistung zu gewährleisten, sondern auch erheblich Kosten zu sparen.
Großes Sprachmodell Die jüngste Entwicklung verlief sehr schnell , und es hat bemerkenswerte außergewöhnliche Fähigkeiten bei der Lösung allgemeiner Probleme, der Generierung von Code und der Befolgung von Anweisungen bewiesen
Während frühe Modelle auf Strategien mit direkter Antwort beruhten, hat sich die aktuelle Forschung dem linearen Denkpfad zugewandt, der durch die Zerlegung des Problems in Unteraufgaben erfolgt Entdecken Sie Lösungen oder verwenden Sie externe Mechanismen, um die Token-Generierung durch Ändern des Kontexts zu ändern.
Ähnlich wie die menschliche Kognition schienen frühe LLM-Strategien das unmittelbare System 1 (schnelle Reaktionen) nachzuahmen, das durch impulsive Entscheidungsfindung gekennzeichnet ist. Im Gegensatz dazu spiegeln neuere Methoden wie Chain of Thoughts (CoT) und L2M (Least-to-Moest Prompting) die introspektive Natur von System 2 (langsames Denken) wider. Es ist erwähnenswert, dass die Fähigkeit zum arithmetischen Denken im LLM durch die Integration von Zwischenschritten zum Denken verbessert werden kann.
Wenn die Aufgabe jedoch eine tiefere Planung und eine umfassendere mentale Erkundung erfordert, werden die Grenzen dieser Methoden deutlich. Obwohl CoT mit integrierter Selbstkonsistenz (CoT-SC) mehrere LLM-Ausgaben verwenden kann, um Konsensergebnisse zu erzielen, kann das Fehlen einer detaillierten Bewertung das Modell in die falsche Richtung führen. Der im Jahr 2023 entstehende Tree of Thinking (ToT) ist eine bemerkenswerte Lösung. Ein LLM dient der Generierung von Ideen und ein weiterer LLM dient der Bewertung der Vorzüge dieser Ideen, gefolgt von einem „Pause-Bewertung-Weiter“-Zyklus. Dieser auf der Baumsuche basierende iterative Prozess ist eindeutig effektiv, insbesondere bei Aufgaben mit langen Fortsetzungen. Die Forscher glauben, dass es sich bei dieser Entwicklung um den Einsatz externer Tools zur Verbesserung des LLM handelt, ähnlich wie Menschen Tools verwenden, um die Einschränkungen ihres eigenen Arbeitsgedächtnisses zu umgehen.
Andererseits weist die erweiterte LLM-Methode auch einige Mängel auf. Ein offensichtliches Problem besteht darin, dass die Anzahl der Abfragen und der Rechenaufwand erheblich zunehmen werden. Jede Abfrage an eine Online-LLM-API wie GPT-4 verursacht erheblichen Overhead und führt zu einer erhöhten Latenz, was besonders wichtig für Echtzeitanwendungen ist. Die kumulierte Latenz dieser Abfragen kann die Gesamteffizienz des Szenarios verringern. Auf der Infrastrukturseite belastet die ständige Interaktion das System, wodurch möglicherweise die Bandbreite eingeschränkt und die Modellverfügbarkeit verringert wird. Darüber hinaus sind die Auswirkungen auf die Umwelt nicht zu vernachlässigen. Häufige Abfragen werden den Energieverbrauch des ohnehin schon energieintensiven Rechenzentrums erhöhen und den CO2-Fußabdruck weiter erhöhen. Das Optimierungsziel der Forscher ist es, die aktuelle Zahl deutlich zu reduzieren der von der Multi-Query-Inferenzmethode verwendeten Abfragen. Eine solche Optimierung kann es Modellen ermöglichen, Aufgaben zu bewältigen, die eine kompetente Anwendung von Weltwissen erfordern, und Menschen dazu anleiten, KI-Ressourcen verantwortungsvoller und kompetenter zu nutzen
Wenn wir über die Entwicklung von LLM von System 1 zu System 2 nachdenken, können wir einen Schlüssel erkennen Der Faktor entstand: Algorithmen. Algorithmen sind methodisch und bieten Menschen die Möglichkeit, Problembereiche zu erkunden, Strategien zu formulieren und Lösungen zu entwickeln. Obwohl viele Mainstream-Literatur Algorithmen als externe Werkzeuge von LLM betrachtet, können wir angesichts der inhärenten generativen Wiederholungsfähigkeit von LLM diese iterative Logik leiten und den Algorithmus in LLM verinnerlichen?
Ein Forschungsteam von Virginia Tech und Microsoft hat die Raffinesse des menschlichen Denkens und die methodische Präzision algorithmischer Methoden zusammengebracht, mit dem Ziel, die Denkfähigkeiten innerhalb des LLM durch die Verschmelzung der beiden Aspekte zu verbessern
Nach bestehenden Forschungsergebnissen Menschen greifen bei der Lösung komplexer Probleme instinktiv auf frühere Erfahrungen zurück, um sicherzustellen, dass sie ganzheitlich denken und sich nicht nur auf ein einzelnes Detail konzentrieren. Der Generierungsbereich von LLM ist nur durch sein Token-Limit begrenzt und scheint dazu bestimmt zu sein, die Hindernisse des menschlichen Arbeitsgedächtnisses zu durchbrechen Durch Rückgriff auf vorherige Zwischenschritte, um undurchführbare Optionen auszuschließen – alles im Rahmen des LLM-Generierungszyklus. Menschen sind gut in der Intuition, während Algorithmen gut darin sind, organisierte und systematische Erkundungen durchzuführen. Aktuelle Technologien wie CoT neigen dazu, dieses Synergiepotenzial zu meiden und sich zu sehr auf die Vor-Ort-Genauigkeit von LLM zu konzentrieren. Durch die Nutzung der rekursiven Fähigkeiten von LLM entwickelten die Forscher einen Hybridansatz aus Mensch und Algorithmus. Dieser Ansatz wird durch die Verwendung algorithmischer Beispiele erreicht, die das Wesentliche der Exploration erfassen – von ersten Kandidaten bis hin zu bewährten Lösungen
Basierend auf diesen Beobachtungen schlugen Forscher den Algorithm of Thoughts (AoT) vor.

Der Inhalt, der neu geschrieben werden muss, ist: Papier: https://arxiv.org/pdf/2308.10379.pdf
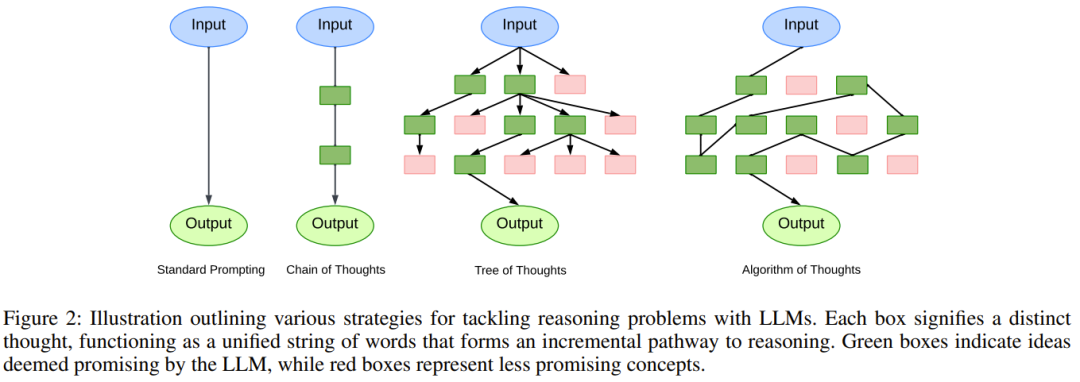
Aus einem breiteren Blickwinkel ist diese neue Methode It wird voraussichtlich ein neues Paradigma des kontextuellen Lernens hervorbringen. Anstatt das traditionelle überwachte Lernmodell [Frage, Antwort] oder [Frage, nachfolgende Schritte zum Erhalt der Antwort] zu verwenden, verwendet dieser neue Ansatz ein neues Modell [Frage, Suchprozess, Antwort]. Wenn ein LLM angewiesen wird, einen Algorithmus zu verwenden, erwarten wir natürlich normalerweise, dass der LLM einfach das iterative Denken dieses Algorithmus nachahmt. Interessant ist jedoch, dass LLM die Fähigkeit besitzt, seine eigene „Intuition“ einzubringen, wodurch seine Suche sogar effizienter wird als der Algorithmus selbst.
Denkalgorithmen
Die Forscher sagen, dass der Kern ihrer Forschungsstrategie darin besteht, die größten Mängel des aktuellen kontextuellen Lernparadigmas zu erkennen. Obwohl CoT die Konsistenz mentaler Verbindungen verbessern kann, treten gelegentlich Probleme auf, die zu falschen Zwischenschritten führen
Um dieses Phänomen zu veranschaulichen, haben Forscher ein Experiment entworfen. Bei der Abfrage von text-davinci-003 mit einer Rechenaufgabe (z. B. 11 − 2 =) stellten die Forscher mehrere Kontextgleichungen voran, die die gleiche Ausgabe liefern würden (z. B. 15 − 5 = 10, 8 + 2 = 10).
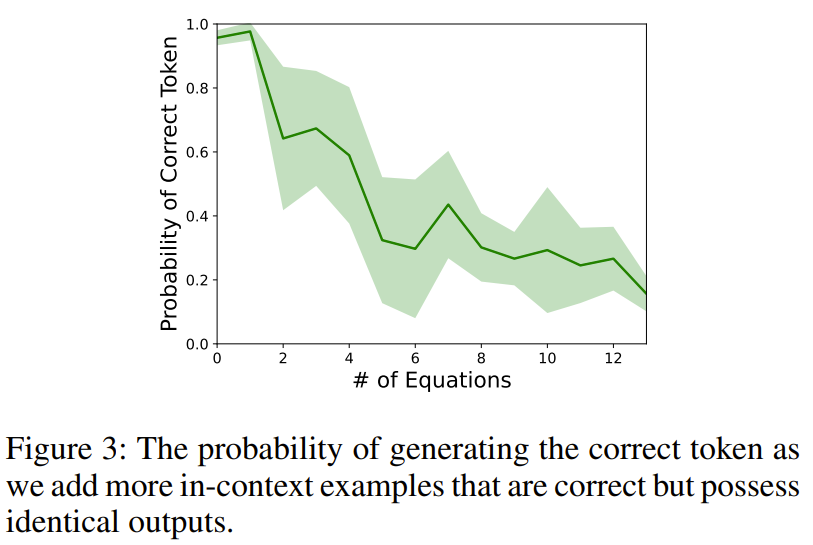
Nach einer Untersuchung wurde festgestellt, dass die Ergebnisgenauigkeit stark abnahm, was darauf hindeutet, dass die bloße Angabe korrekter Argumente im Kontext unbeabsichtigt die zugrunde liegenden Rechenfähigkeiten von LLM beeinträchtigen kann.
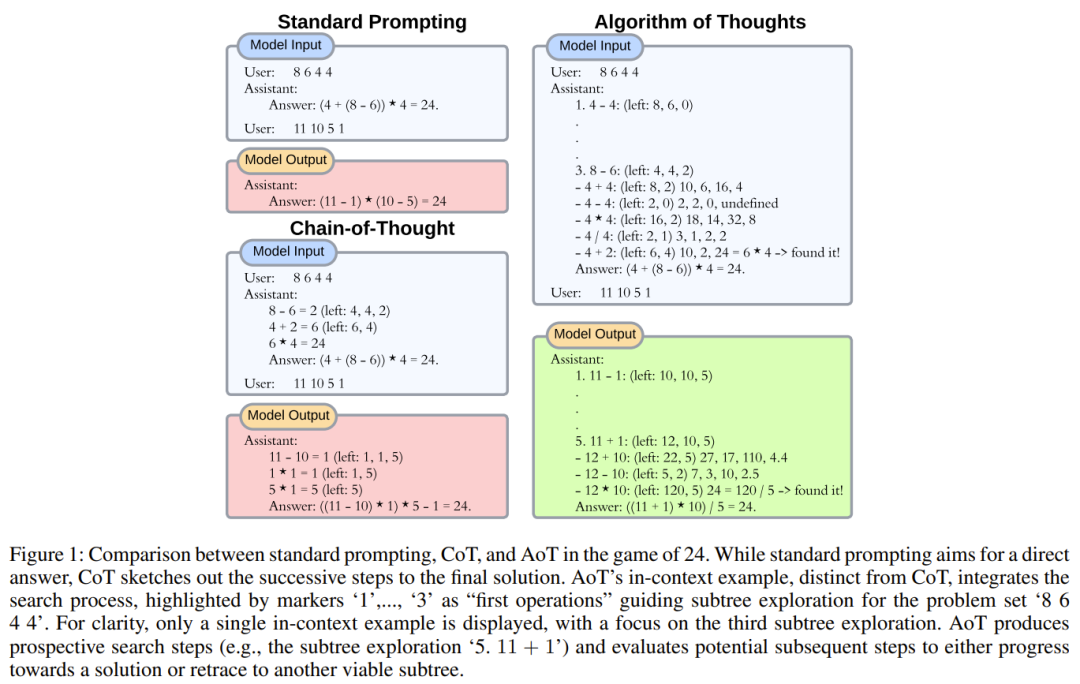
Um diese Verzerrung zu verringern, sollten die Beispiele vielfältiger sein könnte eine praktikable Lösung sein, aber dies könnte die Verteilung der Ausgabe leicht verändern. Das einfache Hinzufügen einiger erfolgloser Versuche (z. B. einer zufälligen Suche) kann das Modell versehentlich dazu verleiten, es erneut zu versuchen, ohne das Problem tatsächlich zu lösen. Um die wahre Natur des algorithmischen Verhaltens zu verstehen (wobei fehlgeschlagene Suchvorgänge und anschließende Wiederherstellungen wichtig sind, sowie das Lernen aus diesen Versuchen), integrieren Forscher kontextbezogene Beispiele, indem sie dem Muster von Suchalgorithmen folgen, insbesondere der Tiefensuche (DFS) und Breitensuche (BFS). Abbildung 1 zeigt ein Beispiel.
Der Schwerpunkt dieser Arbeit liegt auf einer Klasse von Aufgaben, die Baumsuchproblemen ähneln.
Bei dieser Art von Aufgaben ist es notwendig, das Hauptproblem aufzuschlüsseln und für jeden Teil eine praktikable Lösung zu entwickeln. Wir müssen dann entscheiden, ob wir bestimmte Wege einschlagen oder aufgeben und uns möglicherweise dafür entscheiden, diejenigen mit größerem Potenzial neu zu bewerten. Der Ansatz der Forscher besteht darin, die iterativen Fähigkeiten von LLM zu nutzen, um in einem einheitlichen generativen Scan Abfragefragen zu lösen jede Teilmenge. Durch die Beschränkung auf nur eine oder zwei LLM-Interaktionen kann der Ansatz auf natürliche Weise Erkenntnisse früherer Kontextkandidaten integrieren und komplexe Probleme lösen, die eine eingehende Untersuchung des Lösungsbereichs erfordern. Die Forscher geben auch Einblicke in die Geistesgröße und darüber, welche Art von Kontextbeispielen LLM zur Verbesserung der Token-Effizienz bereitstellen sollten. Nachfolgend werden die Schlüsselkomponenten des Baumsuchalgorithmus und ihre Darstellung im neuen Framework vorgestellt
1.
Angesichts eines Problems ist die Erstellung eines Suchbaums, der mögliche Argumentationspfade beschreibt, bereits eine schwierige Aufgabe, auch ohne die eigentlichen Problemlösungsaspekte zu berücksichtigen. Bei jeder Zerlegung müssen nicht nur die Wechselbeziehungen zwischen Teilaufgaben, sondern auch die Leichtigkeit der Lösung jedes Problems berücksichtigt werden. Nehmen Sie als Beispiel die einfache Addition mehrerer Ziffern: Obwohl es für Computer effizient ist, numerische Werte in Binärzahlen umzuwandeln, empfinden Menschen Dezimalzahlen oft intuitiver. Darüber hinaus können die Ausführungsmethoden unterschiedlich sein, selbst wenn die Teilprobleme gleich sind. Intuition kann Abkürzungen zwischen Schritten zu einer Lösung finden, und ohne Intuition sind möglicherweise detailliertere Schritte erforderlich.
Um die richtige Eingabeaufforderung (d. h. ein Beispiel für einen kontextbezogenen Algorithmus) zu erstellen, sind diese Feinheiten sehr wichtig und bestimmen die Mindestanzahl an Token, die LLM benötigt, um eine zuverlässige Leistung zu erzielen. Dies erfüllt nicht nur die Kontextbeschränkungen von LLM, sondern ist auch wichtig für die Fähigkeit von LLM, Probleme, die mit seinem Kontext in Zusammenhang stehen, mit einer ähnlichen Menge an Token zu lösen.
2. Schlagen Sie eine Lösung für die Unterfrage vor. Eine der aktuellen Mainstream-Methoden besteht darin, die LLM-Token-Ausgabewahrscheinlichkeit direkt abzutasten. Obwohl diese Methode für einmalige Antworten (mit gewissen Einschränkungen) effektiv ist, ist sie auch für einige Szenarien nicht geeignet, beispielsweise wenn die Probensequenz in eine nachfolgende Eingabeaufforderung integriert oder in einer nachfolgenden Eingabeaufforderung ausgewertet werden muss. Um Modellabfragen zu minimieren, verwendeten die Forscher einen ununterbrochenen Prozess zur Lösungserstellung. Das heißt, direkt und kontinuierlich Lösungen für die Hauptteilprobleme ohne Generierungspausen generieren.
Umgeschriebener Inhalt: Diese Methode hat viele Vorteile. Erstens befinden sich alle generierten Antworten im selben gemeinsamen Kontext, wodurch die Notwendigkeit entfällt, für jede Antwort zur Auswertung separate Modellabfragen zu generieren. Zweitens: Obwohl es auf den ersten Blick kontraintuitiv erscheinen mag, führen isolierte Marker- oder Markergruppen-Wahrscheinlichkeiten möglicherweise nicht immer zu sinnvollen Auswahlen. Abbildung 4 zeigt ein einfaches Schema

3 Messung der Aussichten von Teilproblemen. Wie oben erwähnt, stützen sich bestehende Techniken auf zusätzliche Hinweise, um das Potenzial von Baumknoten zu identifizieren und Entscheidungen über Explorationsrichtungen zu treffen. Unsere Beobachtungen deuten darauf hin, dass LLM von Natur aus dazu neigt, vielversprechende Kandidaten zu priorisieren, wenn sie in kontextbezogenen Beispielen zusammengefasst werden können. Dies reduziert den Bedarf an komplexem Prompt-Engineering und ermöglicht die Integration anspruchsvoller Heuristiken, unabhängig davon, ob diese intuitiv oder wissensgesteuert sind. Ebenso enthält die neue Methode keine unzusammenhängenden Eingabeaufforderungen, was eine sofortige Bewertung der Machbarkeit eines Kandidaten innerhalb desselben generierten Ergebnisses ermöglicht.
4. Zurück zu einem besseren Knoten. Die Entscheidung, welcher Knoten als nächstes untersucht werden soll (einschließlich Zurückverfolgen zu vorherigen Knoten), hängt im Wesentlichen vom gewählten Baumsuchalgorithmus ab. Obwohl in früheren Untersuchungen externe Methoden wie Codierungsmechanismen für den Suchprozess eingesetzt wurden, würde dies seine breitere Attraktivität einschränken und zusätzliche Anpassungen erfordern. Das in diesem Artikel vorgeschlagene neue Design übernimmt hauptsächlich die DFS-Methode, ergänzt durch Beschneiden. Das Ziel besteht darin, die Nähe zwischen untergeordneten Knoten mit demselben übergeordneten Knoten aufrechtzuerhalten und dadurch LLM zu ermutigen, lokalen Funktionen gegenüber entfernten Funktionen Vorrang einzuräumen. Darüber hinaus schlugen die Forscher auch Leistungsindikatoren der BFS-basierten AoT-Methode vor. Die Forscher sagen, dass die Notwendigkeit zusätzlicher Anpassungsmechanismen eliminiert werden kann, indem die inhärente Fähigkeit des Modells genutzt wird, Erkenntnisse aus kontextbezogenen Beispielen zu gewinnen.
Experiment
Die Forscher führten ein Experiment mit 24-Punkte- und 5x5-Miniwortspielen durch. Die Ergebnisse zeigen, dass die AoT-Methode Single-Prompt-Methoden (wie Standardmethoden, CoT, CoT-SC) in der Leistung übertrifft und auch mit Methoden vergleichbar ist, die externe Mechanismen verwenden (wie ToT)
Das ist deutlich zu erkennen Aus Tabelle 1 wurde festgestellt, dass die Baumsuchmethode mit LLM deutlich besser ist als die standardmäßige Prompt-Design-Methode, die CoT/CoT-SC kombiniert
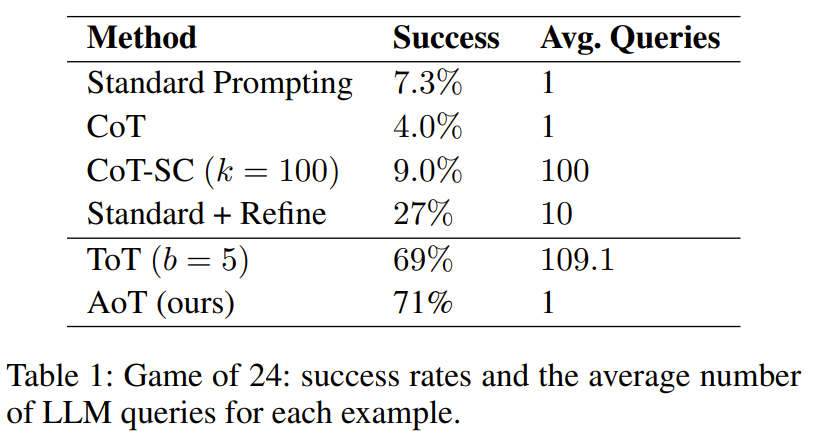
In der Mini-Wortfüllaufgabe zeigt Tabelle 3 die Wirksamkeit von AoT und Die Erfolgsquote beim Ausfüllen von Wörtern übertrifft frühere Methoden mit verschiedenen Aufforderungstechniken.

Allerdings ist es schlechter als ToT. Eine wichtige Beobachtung ist, dass das von ToT verwendete Abfragevolumen enorm ist und das von AoT um mehr als das Hundertfache übersteigt. Ein weiterer Faktor, der AoT gegenüber ToT unterlegen macht, besteht darin, dass die den algorithmischen Beispielen innewohnenden Backtracking-Fähigkeiten nicht vollständig aktiviert sind. Wenn diese Fähigkeit vollständig freigeschaltet werden könnte, würde dies zu einer deutlich längeren Generationsphase führen. Im Gegensatz dazu hat ToT den Vorteil, dass für das Backtracking externer Speicher verwendet wird.
Diskutieren
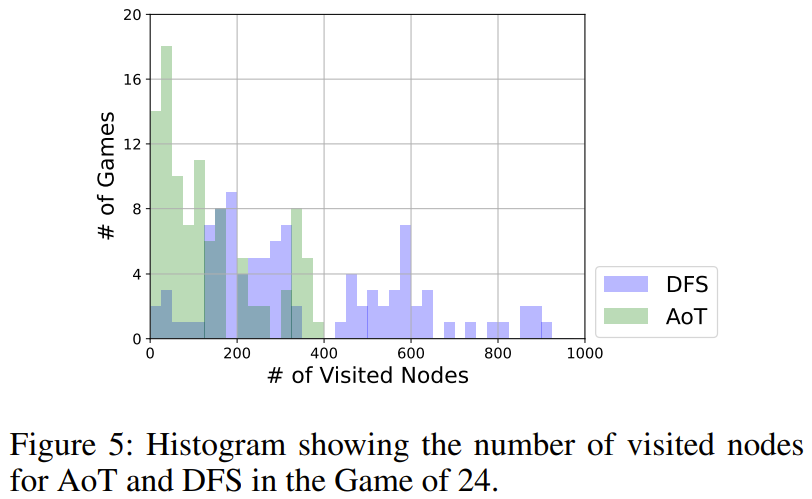
Kann AoT durch die Nachahmung von DFS einen Durchbruch erzielen?
Wie in Abbildung 5 dargestellt, verwendet AoT insgesamt weniger Knoten als die DFS-Version. DFS verfolgt eine einheitliche Strategie bei der Auswahl der zu untersuchenden Teilbäume, während das LLM von AoT seine inhärenten Heuristiken integriert. Diese Erweiterung des Grundalgorithmus spiegelt die Vorteile der rekursiven Argumentationsfähigkeiten von LLM wider
Wie wirkt sich die Wahl des Algorithmus auf die Leistung von AoT aus?
Die im Experiment gefundene Tabelle 5 zeigt, dass alle drei AoT-Varianten dem CoT für eine einzelne Abfrage überlegen sind
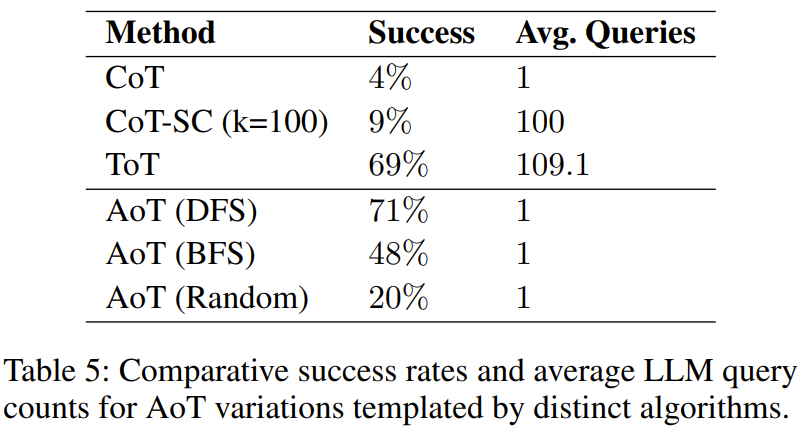
Dieses Ergebnis ist wie erwartet, da unabhängig vom Algorithmus gesucht wird und potenzielle Fehler erneut berücksichtigt werden – entweder durch zufällige Versuche in der Zufallssuchvariante oder durch Backtracking in einer Konfiguration mit Tiefensuche (DFS) oder Breitensuche (BFS). Es ist erwähnenswert, dass die Effizienz der strukturierten Suche, der DFS-Version von AoT und der BFS-Version von AoT, beide besser ist als die der Zufallsversion von AoT, was die Vorteile algorithmischer Erkenntnisse bei der Lösungsfindung hervorhebt. Allerdings hinkt die BFS-Version von AoT der DFS-Version von AoT hinterher. Durch die weitere Analyse der Fehler der BFS-Version von AoT stellten die Forscher fest, dass die BFS-Version von AoT im Vergleich zur DFS-Version von AoT schwieriger zu identifizieren ist Achten Sie auf die Algorithmusbeispiele. Die Anzahl der Suchschritte
ist in Abbildung 6 dargestellt. Die Auswirkung der Gesamtzahl der Suchschritte ist in Abbildung 6 dargestellt. Unter diesen stellen AoT (lang) und AoT (kurz) jeweils längere bzw. kürzere Versionen im Vergleich zu den ursprünglich von AoT generierten Ergebnissen dar. Forschungsergebnisse zeigen, dass der Suchschritt eine implizite Verzerrung der Suchgeschwindigkeit von LLM hervorruft . Es ist wichtig zu beachten, dass es auch bei falschen Schritten immer noch wichtig ist, den Schwerpunkt auf die Erkundung von Richtungen mit Potenzial zu legen
Das obige ist der detaillierte Inhalt vonNeuer Titel: Aufdecken, warum große Modelle langsamer werden: Neue Wege für Algorithmen des menschlichen Geistes. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierter Code für Schulungsfragen zur Grundanweisung der MySQL-Datenbank
- Was sind die grundlegenden Datentypen von Java?
- Was bedeutet mobile Daten ohne Service?
- Schockiert! Nach 70.000 Trainingsstunden lernte das Modell von OpenAI, Holz in „Minecraft' zu planen
- Das Training von ViT und MAE reduziert den Rechenaufwand um die Hälfte! Sea und die Peking-Universität haben gemeinsam den effizienten Optimierer Adan vorgeschlagen, der für tiefe Modelle verwendet werden kann