
Heim >Technologie-Peripheriegeräte >KI >Die neue Arbeit von Professor Ma Yi: White-Box-ViT erreicht erfolgreich „partitioniertes Auftauchen'. Geht die Ära des empirischen Deep Learning zu Ende?
Die neue Arbeit von Professor Ma Yi: White-Box-ViT erreicht erfolgreich „partitioniertes Auftauchen'. Geht die Ära des empirischen Deep Learning zu Ende?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-09-14 14:45:081511Durchsuche
Das auf Transformer basierende visuelle Grundmodell hat bei verschiedenen nachgelagerten Aufgaben wie Segmentierung und Erkennung eine sehr leistungsstarke Leistung gezeigt, und nach selbstüberwachtem Training sind Modelle wie DINO mit semantischen Segmentierungsattributen entstanden.
Es ist seltsam, dass das visuelle Transformer-Modell keine ähnlichen Emergenzfähigkeiten zeigt, nachdem es für die überwachte Klassifizierung trainiert wurde.
Kürzlich untersuchte das Team von Professor Ma Yi ein Modell, das auf der Transformer-Architektur basiert, um Emergenz zu untersuchen. Ist die Segmentierungsfähigkeit einfach das Ergebnis eines komplexen selbstüberwachten Lernmechanismus, oder ob die gleiche Emergenz unter allgemeineren Bedingungen durch entsprechende Gestaltung der Modellarchitektur erreicht werden kann

Code-Link: https://github.com/Ma-Lab -Berkeley/CRATE
Bitte klicken Sie auf den folgenden Link, um das Papier anzuzeigen: https://arxiv.org/abs/2308.16271
Nach umfangreichen Experimenten demonstrierten die Forscher CRATE mithilfe des White-Box-Transformer-Modells. Sein Design modelliert und verfolgt explizit niedrigdimensionale Strukturen in der Datenverteilung. Segmentierungseigenschaften auf Gesamt- und Teilebene entstehen mit minimal überwachten Trainingsformulierungen die Entwurfsmathematischen Fähigkeiten von White-Box-Netzwerken. Basierend auf diesem Ergebnis haben wir eine Methode zum Entwurf eines White-Box-Basismodells vorgeschlagen, das nicht nur leistungsstark, sondern auch vollständig mathematisch interpretierbar ist. Professor Ma Yi sagte auch, dass sich die Forschung zum Deep Learning schrittweise weiterentwickeln wird Das empirische Design wendet sich der theoretischen Anleitung zu.
Die auftauchenden Eigenschaften von White-Box-CRATE
DINOs aufstrebende Fähigkeit zur Segmentierung bezieht sich auf die Fähigkeit des DINO-Modells, die Eingabesätze bei der Verarbeitung von Sprachaufgaben in kleinere Fragmente zu segmentieren und für jedes Fragment eine unabhängige Verarbeitung durchzuführen . Diese Fähigkeit ermöglicht es dem DINO-Modell, komplexe Satzstrukturen und semantische Informationen besser zu verstehen und dadurch seine Leistung im Bereich der Verarbeitung natürlicher Sprache zu verbessern

Das Training von Deep-Learning-Modellen verfolgt in der Regel einen datengesteuerten Ansatz, bei dem umfangreiche Daten eingegeben und selbstüberwacht gelernt werden.
Unter den grundlegenden visuellen Modellen zeigt das DINO-Modell überraschende Ergebnisse Durch die neue Fähigkeit können ViTs explizite semantische Segmentierungsinformationen auch ohne überwachtes Segmentierungstraining erkennen. Das DINO-Modell der selbstüberwachten Transformer-Architektur hat in dieser Hinsicht gute Leistungen erbracht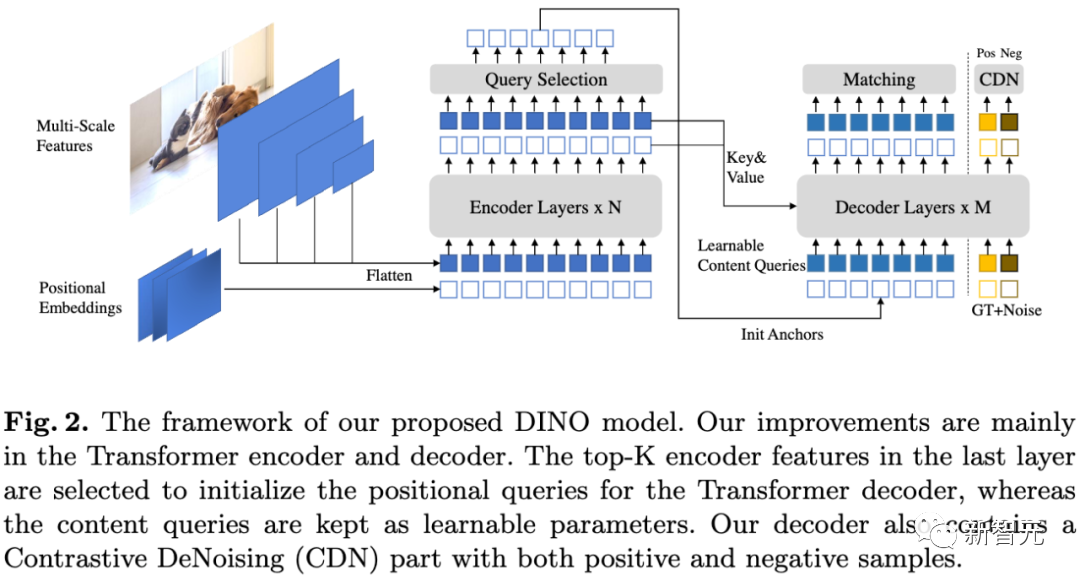
In der folgenden Arbeit wurde untersucht, wie diese Segmentierungsinformationen im DINO-Modell genutzt werden können, und bei nachgelagerten Aufgaben wie der Segmentierung eine Leistung auf dem neuesten Stand der Technik erzielt Es gibt auch Arbeiten, die belegen, dass die vorletzten Schichtmerkmale in mit DINO trainierten ViTs stark mit den hervorstechenden Informationen in der visuellen Eingabe zusammenhängen, wie z. B. der Unterscheidung von Vordergrund-, Hintergrund- und Objektgrenzen, wodurch die Leistung der Bildsegmentierung und anderes verbessert wird Aufgaben.
Um die Segmentierungsattribute hervorzuheben, muss DINO während des Trainingsprozesses selbstüberwachtes Lernen, Wissensdestillation und Gewichtsmittelungsmethoden geschickt kombinieren.
Es ist unklar, ob jede in DINO eingeführte Komponente für die Segmentierung nützlich ist. Obwohl DINO auch die ViT-Architektur als Rückgrat verwendet, wurde in gewöhnlichen überwachten ViT-Modellen, die auf Klassifizierungsaufgaben trainiert wurden, kein Segmentierungsentstehungsverhalten beobachtet.
Entstehung von CRATE
Basierend auf dem Erfolg von DINO wollten die Forscher untersuchen, ob komplexe selbstüberwachte Lernpipelines notwendig sind, um entstehende Eigenschaften in transformatorähnlichen visuellen Modellen zu erhalten.
Forscher glauben, dass ein vielversprechender Weg zur Förderung der Segmentierungseigenschaften in Transformer-Modellen darin besteht, die Architektur des Transformer-Modells unter Berücksichtigung der Eingabedatenstruktur zu entwerfen, die auch die Tiefe des Repräsentationslernens klassischer Methoden mit moderner datengesteuerter Integration des Lernens darstellt Rahmen.
Im Vergleich zum aktuellen Mainstream-Transformer-Modell kann diese Entwurfsmethode auch als White-Box-Transformer-Modell bezeichnet werden.
Basierend auf früheren Arbeiten der Gruppe von Professor Ma Yi führten Forscher umfangreiche Experimente zum CRATE-Modell der White-Box-Architektur durch und bewiesen, dass das White-Box-Design von CRATE der Grund für die Entstehung von Segmentierungsattributen in Selbstaufmerksamkeitsdiagrammen ist.
Was neu formuliert werden muss, ist: Qualitative Bewertung
Die Forscher verwendeten die [CLS]-Token-basierte Aufmerksamkeitskartenmethode, um das Modell zu erklären und zu visualisieren, und stellten fest, dass die Abfrage-Schlüssel-Wert-Matrix in CRATE Es ist dasselbe
Es kann beobachtet werden, dass die Selbstaufmerksamkeitskarte des CRATE-Modells der Semantik des Eingabebildes entsprechen kann. Das interne Netzwerk des Modells führt für jedes Bild eine klare semantische Segmentierung durch. Erzielte einen ähnlichen Effekt wie das DINO-Modell.
Gewöhnliches ViT weist keine ähnlichen Segmentierungseigenschaften auf, wenn es auf überwachte Klassifizierungsaufgaben trainiert wird.

Basierend auf früheren Untersuchungen zum visuellen Bildlernen von blockweisen Tiefenmerkmalen verglichen Forscher die tiefe Token-Darstellung von CRATE und ViT Das Modell wurde mithilfe der Hauptkomponentenanalyse (PCA) untersucht. Es wurde festgestellt, dass CRATE immer noch die Grenzen von Objekten in Bildern erfassen kann, ohne dass ein segmentierungsüberwachtes Training erforderlich ist.
 Darüber hinaus zeigen die Hauptkomponenten auch die Merkmalsausrichtung ähnlicher Teile zwischen Token und Objekten an, wie z. B. den roten Kanal, der den Beinen des Pferdes entspricht
Darüber hinaus zeigen die Hauptkomponenten auch die Merkmalsausrichtung ähnlicher Teile zwischen Token und Objekten an, wie z. B. den roten Kanal, der den Beinen des Pferdes entspricht
, während die PCA-Visualisierung des überwachten ViT-Modells recht schlecht strukturiert ist .
Quantitative Bewertung
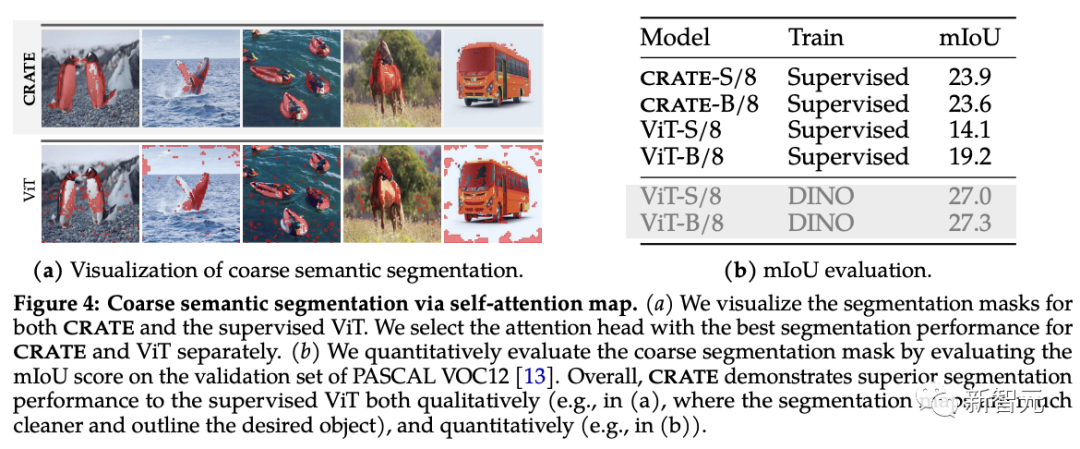
Die Forscher verwendeten vorhandene Segmentierungs- und Objekterkennungstechniken, um die neuen Segmentierungseigenschaften von CRATE zu bewerten. Wie aus dem Selbstaufmerksamkeitsdiagramm ersichtlich ist, verwendet CRATE klare Grenzen, um Objekte explizit zu erfassen. Um die Qualität der Segmentierung quantitativ zu messen, verwendeten die Forscher Selbstaufmerksamkeitskarten, um Segmentierungsmasken zu generieren, und verglichen sie mit dem Standard-mIoU (mittleres Schnittmengen-zu-Union-Verhältnis) zwischen ihnen und den realen Masken.
Aus den experimentellen Ergebnissen geht hervor, dass CRATE ViT in Bezug auf visuelle und mIOU-Scores deutlich übertrifft, was zeigt, dass die interne Darstellung von CRATE für die Aufgabe der Generierung von Segmentierungsmasken effektiver ist
Um die von CRATE erfassten umfangreichen semantischen Informationen weiter zu überprüfen und auszuwerten, verwendeten die Forscher MaskCut, eine effiziente Methode zur Objekterkennung und -segmentierung, um ein automatisiertes Bewertungsmodell ohne manuelle Anmerkungen zu erhalten Basierend auf den von CRATE Representations gelernten Token können feinkörnigere Segmentierungen aus Bildern extrahiert werden.
Wie aus den Segmentierungsergebnissen auf COCO val2017 hervorgeht, ist die interne Darstellung mit CRATE sowohl bei der Erkennung als auch bei den Segmentierungsindikatoren in einigen Fällen besser als bei überwachtem ViT Es ist sogar unmöglich, überhaupt eine geteilte Maske zu erzeugen. 
White-Box-Analyse der Segmentierungsfähigkeiten von CRATE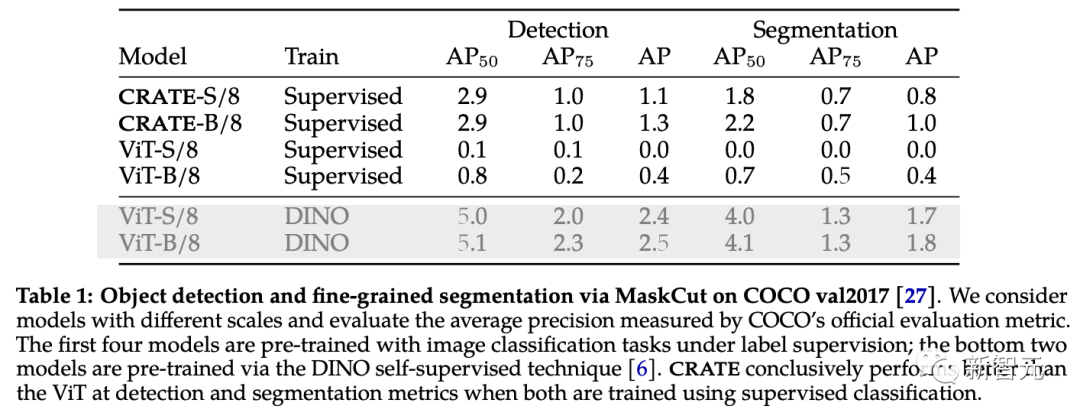
Die Rolle der Tiefe in CRATE
Das Design jeder Schicht von CRATE folgt dem gleichen konzeptionellen Zweck: die Reduzierung der Sparse-Rate zu optimieren und die zu konvertieren Token-Verteilung in kompakter und strukturierter Form. Nach dem Umschreiben: Das Design jeder Ebene von CRATE folgt dem gleichen Konzept: Optimierung der Sparse-Rate-Reduzierung und Umwandlung der Token-Verteilung in eine kompakte und strukturierte Form Unter der Annahme, dass die Entstehung semantischer Segmentierungsfunktionen in CRATE ähnlich ist „Darstellung von Clustern von Token, die zu ähnlichen semantischen Kategorien in Z gehören“, wird erwartet, dass sich die Segmentierungsleistung von CRATE mit zunehmender Tiefe verbessern kann.
Um dies zu testen, verwendeten die Forscher die MaskCut-Pipeline, um die Segmentierungsleistung über interne Darstellungen hinweg über verschiedene Ebenen hinweg quantitativ zu bewerten und gleichzeitig PCA-Visualisierung anzuwenden, um zu verstehen, wie Segmentierungen mit Tiefe entstehen.
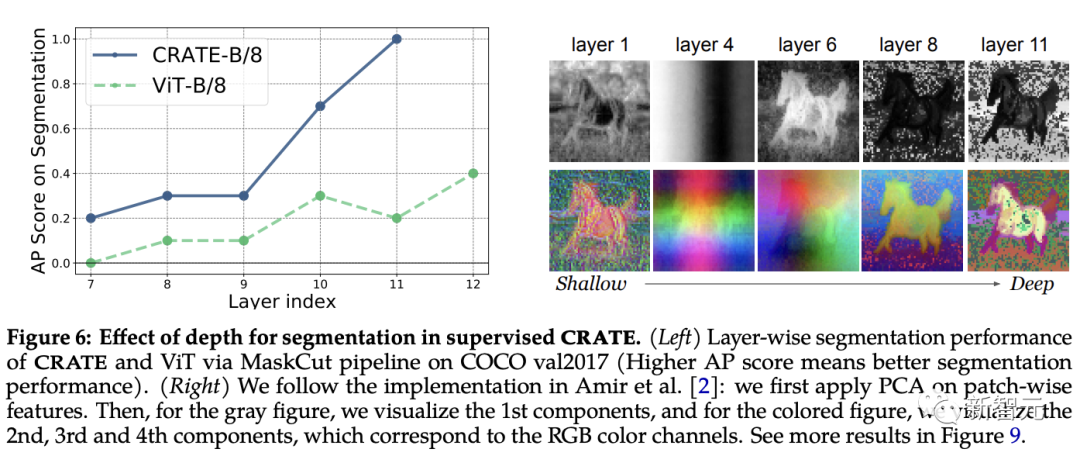
Aus den experimentellen Ergebnissen lässt sich beobachten, dass sich der Segmentierungsscore verbessert, wenn Darstellungen aus tieferen Schichten verwendet werden, was sehr gut mit dem inkrementellen Optimierungsdesign von CRATE übereinstimmt.
Obwohl sich die Leistung von ViT-B/8 in späteren Schichten leicht verbessert, sind seine Segmentierungswerte im Gegensatz dazu deutlich niedriger als bei CRATE, und PCA-Ergebnisse zeigen, dass Darstellungen, die aus tiefen Schichten von CRATE extrahiert wurden, den Vordergrundobjekten allmählich mehr Aufmerksamkeit schenken und ist in der Lage, Details auf Texturebene zu erfassen.
CRATEs Schmelzexperiment
Der Aufmerksamkeitsblock (MSSA) und der MLP-Block (ISTA) in CRATE unterscheiden sich vom Aufmerksamkeitsblock in ViT
Um jede Komponente auf ihre Wirkung hin zu untersuchen Aufgrund der neuen Segmentierungseigenschaften von CRATE wählten die Forscher drei CRATE-Varianten aus: CRATE, CRATE-MHSA und CRATE-MLP. Diese Varianten stellen den Aufmerksamkeitsblock (MHSA) bzw. den MLP-Block in ViT dar
Die Forscher wendeten dieselben Vortrainingseinstellungen auf den ImageNet-21k-Datensatz an und wendeten dann eine grobe Segmentierungsbewertung und eine maskierte Segmentierungsbewertung an, um die Leistung quantitativ zu vergleichen verschiedener Modelle.
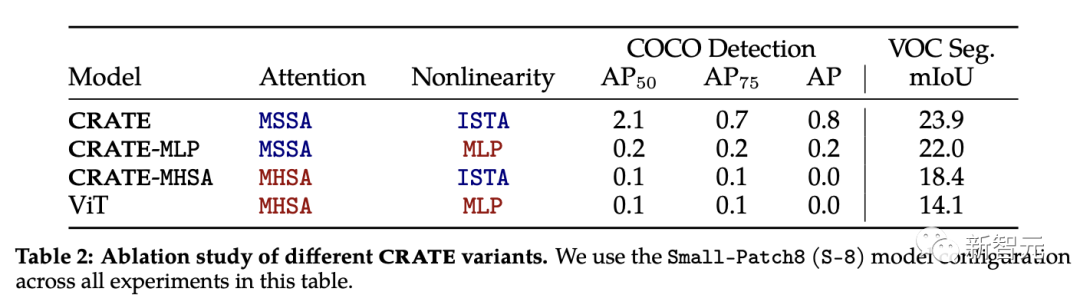
Experimentellen Ergebnissen zufolge übertrifft CRATE andere Modellarchitekturen in allen Aufgaben deutlich. Es ist erwähnenswert, dass der architektonische Unterschied zwischen MHSA und MSSA zwar gering ist, ein einfaches Ersetzen von MHSA in ViT durch MSSA in CRATE die Grobsegmentierungsleistung (d. h. VOC Seg) von ViT erheblich verbessern kann. Dies beweist weiter die Wirksamkeit des White-Box-Designs
Der Inhalt, der neu geschrieben werden muss, ist: die Identifizierung der semantischen Attribute des Aufmerksamkeitsheaders
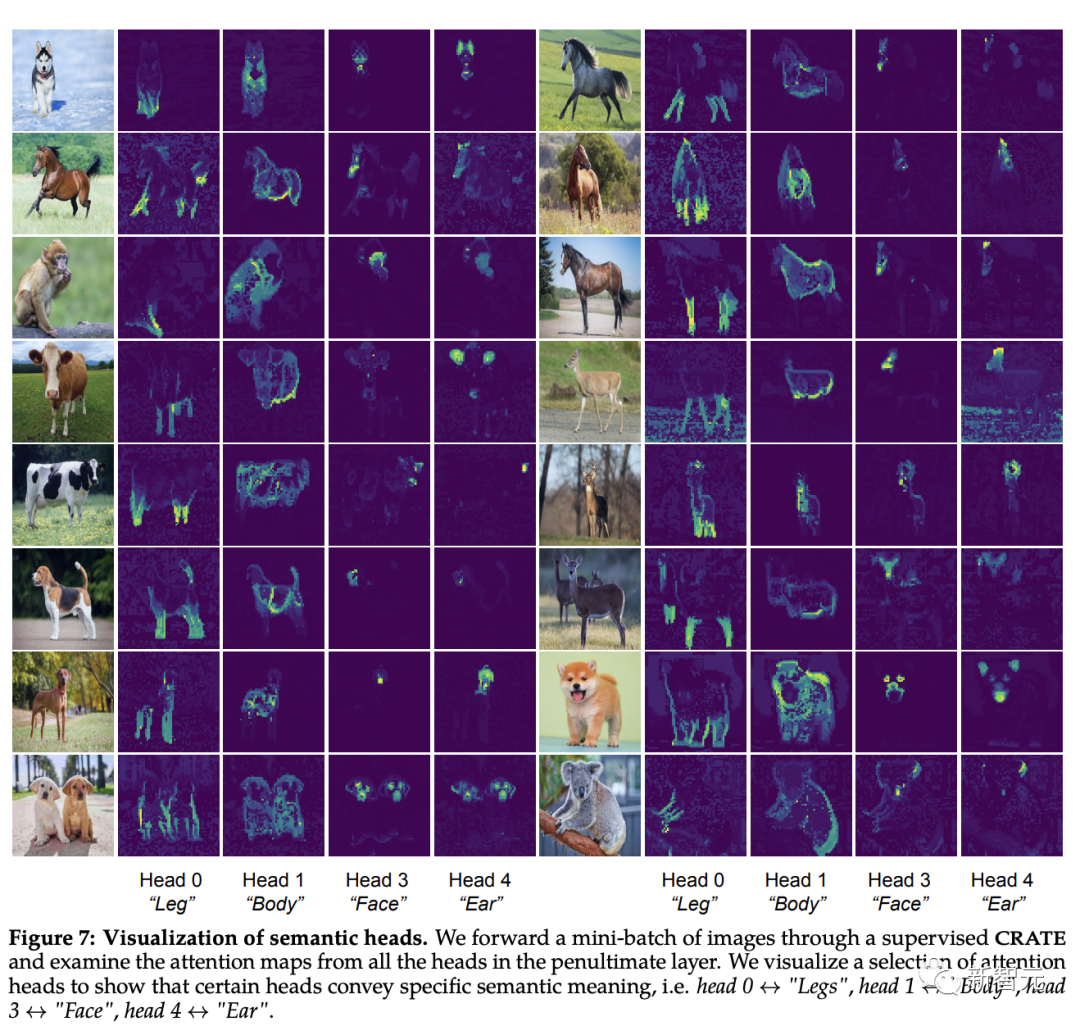
[CLS] Die Selbstaufmerksamkeitskarte zwischen Token und Bildblock-Token können gesehen werden. Um eine klare Segmentierungsmaske zu erhalten, sollte jeder Aufmerksamkeitskopf intuitiv in der Lage sein, einige Merkmale der Daten zu erfassen.
Die Forscher gaben zunächst Bilder in das CRATE-Modell ein und ließen dann Menschen vier Aufmerksamkeitsköpfe untersuchen und auswählen, die eine semantische Bedeutung zu haben schienen. Anschließend führten sie eine Selbstaufmerksamkeitskartenvisualisierung dieser Aufmerksamkeitsköpfe auf anderen Eingabebildern durch.
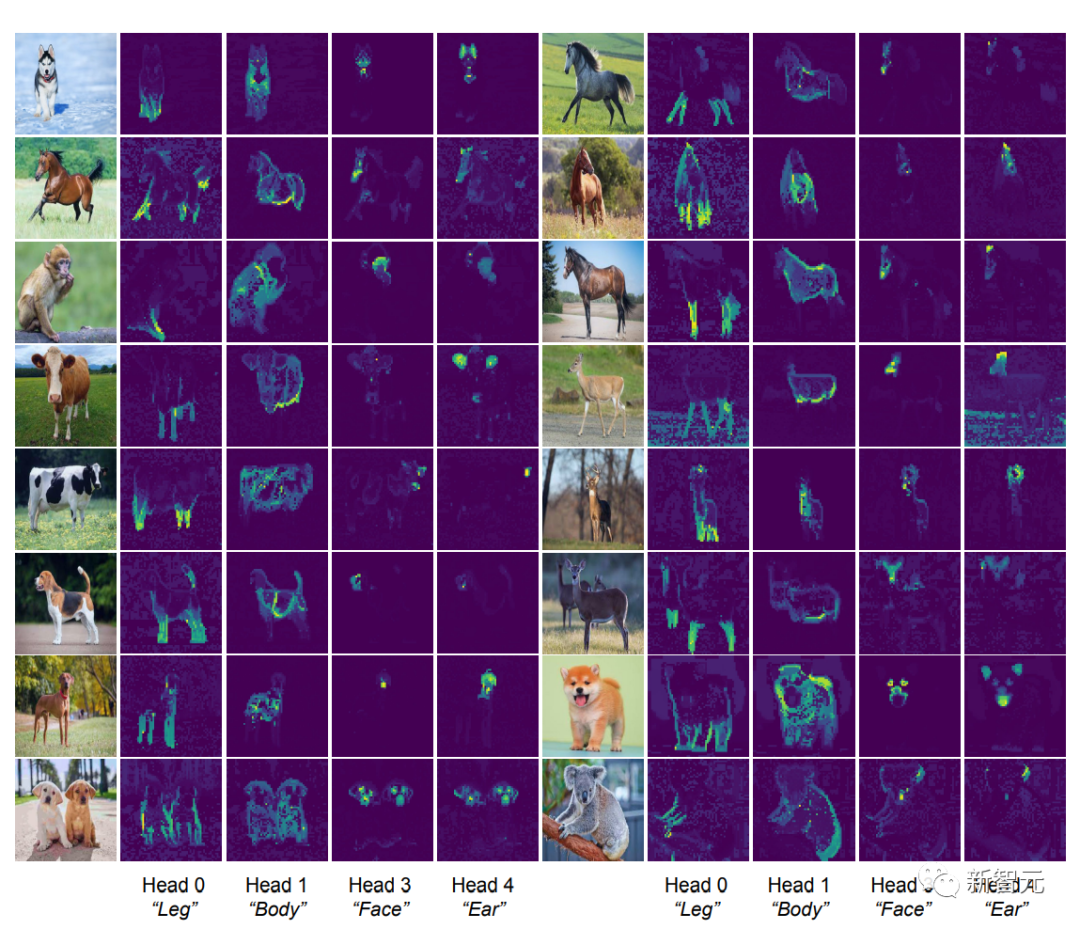
Beobachtung kann festgestellt werden, dass jeder Aufmerksamkeitskopf unterschiedliche Teile des Objekts und sogar unterschiedliche Semantiken erfassen kann. Beispielsweise kann der Aufmerksamkeitskopf in der ersten Spalte die Beine verschiedener Tiere erfassen, während der Aufmerksamkeitskopf in der letzten Spalte die Ohren und den Kopf erfassen kann Ganze Hierarchien sind seit der Veröffentlichung von Kapselnetzwerken ein Ziel von Erkennungsarchitekturen, und das White-Box-entworfene CRATE-Modell verfügt ebenfalls über diese Fähigkeit.
Das obige ist der detaillierte Inhalt vonDie neue Arbeit von Professor Ma Yi: White-Box-ViT erreicht erfolgreich „partitioniertes Auftauchen'. Geht die Ära des empirischen Deep Learning zu Ende?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist das relationale Datenmodell?
- So löschen Sie überflüssige Modelle in ZBrush
- Wie viele Arten von CSS-Box-Modellen gibt es?
- Neueste Fortschritte bei Sparse-Modellen! Ma Yi + LeCun bündeln ihre Kräfte: „White Box' unbeaufsichtigtes Lernen
- Warum ist Selbstüberwachung effektiv? Die 243-seitige Princeton-Doktorarbeit „Understanding Self-supervised Representation Learning' erläutert umfassend die drei Arten von Methoden: kontrastives Lernen, Sprachmodellierung und Selbstvorhersage.