
Heim >Technologie-Peripheriegeräte >KI >Damit die Rechenleistung nicht länger zum Engpass wird, nutzt Xiaohongshu die Methode zur Optimierung heterogener Hardware-Inferenzen für maschinelles Lernen
Damit die Rechenleistung nicht länger zum Engpass wird, nutzt Xiaohongshu die Methode zur Optimierung heterogener Hardware-Inferenzen für maschinelles Lernen

- PHPznach vorne
- 2023-09-08 12:33:061609Durchsuche

Viele Unternehmen kombinieren die Entwicklung der GPU-Rechenleistung, um Lösungen für maschinelle Lernprobleme zu finden, die für sie geeignet sind. Beispielsweise wird Xiaohongshu im Jahr 2021 mit der GPU-basierten Transformation des Promotion-Suchmodells beginnen, um die Inferenzleistung und -effizienz zu verbessern. Während des Migrationsprozesses standen wir auch vor einigen Schwierigkeiten, z. B. wie wir reibungslos auf heterogene Hardware migrieren, wie wir unsere eigenen Lösungen basierend auf den Geschäftsszenarien und der Online-Architektur von Xiaohongshu entwickeln usw. Im Rahmen des globalen Trends der Kostensenkung und Effizienzsteigerung hat sich heterogenes Computing zu einer vielversprechenden Richtung entwickelt, die durch die Kombination verschiedener Prozessortypen (wie CPU, GPU, FPGA usw.) die Rechenleistung verbessern kann, um eine bessere Effizienz und niedrigere Kosten zu erzielen.
1. Hintergrund
Die Modelldienste für Empfehlung, Werbung, Suche und andere Hauptszenarien werden einheitlich von der Middle-End-Inferenzarchitektur getragen. Mit der kontinuierlichen Weiterentwicklung des Geschäfts von Xiaohongshu nimmt auch der Umfang der Modelle für Szenarien wie die Werbesuche zu. Am Beispiel des Hauptmodells verfeinerter Empfehlungsszenarien hat der Algorithmus seit Anfang 2020 die Full-Interest-Modellierung gestartet und die durchschnittliche Länge der historischen Benutzerverhaltensaufzeichnungen hat sich um etwa das Hundertfache erhöht. Die Modellstruktur hat seit der anfänglichen Muti-Aufgabe auch mehrere Iterationsrunden durchlaufen, und die Komplexität der Modellstruktur hat ebenfalls weiter zugenommen. Diese Änderungen haben zu einer 30-fachen Erhöhung der Anzahl der Gleitkommaoperationen geführt Modellinferenz und eine etwa fünffache Steigerung des Modellspeicherzugriffs.
 Bilder
Bilder
2. Übersicht über die Modelldienstarchitektur
Modellmerkmale:Nehmen Sie als Beispiel das empfohlene Hauptmodell von Xiaohongshu Ein Teil der Struktur besteht aus kontinuierlichen Wertmerkmalen und Matrixoperationen, und es gibt auch großräumige spärliche Parameter wie Die spärlichen Merkmale eines einzelnen Modells sind jedoch bis zu 1 TB groß Der dichte Teil wird innerhalb von 10 GB gesteuert und kann im Videospeicher abgelegt werden. Jedes Mal, wenn der Benutzer über Xiaohongshu wischt, erreichen die gesamten berechneten FLOPs 40 B, und die Zeitüberschreitung wird auf 300 ms begrenzt (ohne Funktionsverarbeitung, mit Suche).
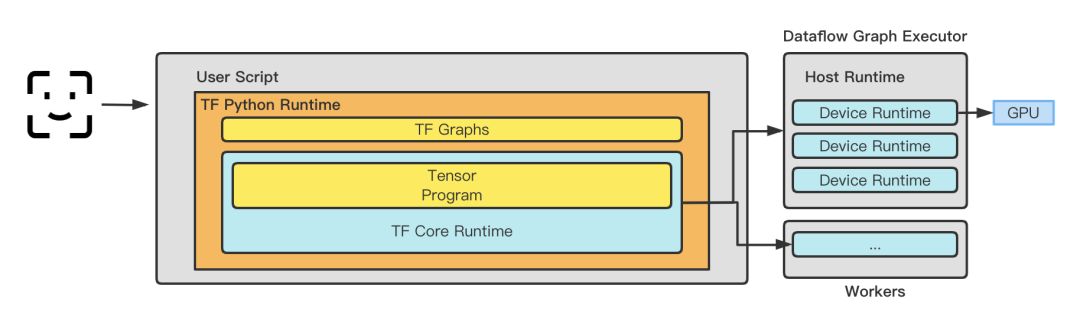
Inferenz-Framework: Vor 2020 übernahm Xiaohongshu das TensorFlow Serving-Framework als Online-Service-Framework. Nach 2020 wurde es schrittweise in den selbst entwickelten Lambda-Service auf Basis von TensorFlowCore iteriert. TensorFlow Serving führt vor dem Eintritt in das Diagramm eine Speicherkopie von TensorProto -> CTensor durch, um die Richtigkeit und Zuverlässigkeit der Modellinferenz sicherzustellen. Mit zunehmender Unternehmensgröße wirken sich Speicherkopiervorgänge jedoch auf die Modellleistung aus. Das von Xiaohongshu selbst entwickelte Framework eliminiert unnötiges Kopieren durch Optimierung, behält jedoch die steckbaren Funktionen der Laufzeit, der Diagrammplanungsfunktionen und der Optimierungsfunktionen bei und legt den Grundstein für die spätere Verwendung verschiedener Optimierungsframeworks wie TRT, BLADE und TVM. Nun scheint es eine kluge Entscheidung zu sein, sich zum richtigen Zeitpunkt für die Selbstforschung zu entscheiden. Gleichzeitig übernimmt das Inferenz-Framework auch einen Teil der Implementierung der Merkmalsextraktion und -transformation Hier wird geschätzt, dass auf der nahen Seite des Dienstes ein selbst entwickelter Edge-Speicher bereitgestellt wird, der das Kostenproblem beim Abrufen von Daten von der entfernten Seite löst.
Modellmerkmale: Xiaohongshu baut keinen eigenen Computerraum. Alle Maschinen werden von Cloud-Anbietern gekauft. Daher hängt die Entscheidung für die Auswahl verschiedener Modelle weitgehend davon ab, welche Art von Maschinen gekauft werden können. Bei der Berechnung der Modellinferenz handelt es sich nicht um eine reine GPU-Berechnung. Um ein angemessenes Hardware-Verhältnis zu finden, sind neben der Berücksichtigung der GPUCPU auch Probleme wie Bandbreite, Speicherbandbreite und nummerübergreifende Kommunikationsverzögerung erforderlich.
 Bilder
Bilder
GPU-Funktionen
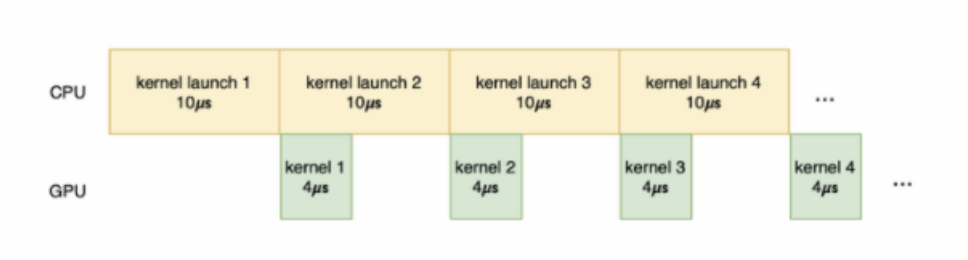
GPU-Funktionen:Hier sind die Probleme, auf die Xiaohongshu und andere Unternehmen stoßen, die gleichen. Die Ausführung des GPU-Kernels kann in die folgenden Phasen unterteilt werden: Datenübertragung, Kernel Startup, Kernelberechnung und Ergebnisübertragung. Unter anderem dient die Datenübertragung dazu, Daten vom Host-Speicher an den GPU-Speicher zu übertragen; der Kernel-Start dient dazu, den Kernel-Code von der Host-Seite zur GPU-Seite zu übertragen, und das Starten der Kernel-Berechnung auf der GPU Das Ergebnis der Kernel-Code-Berechnung erfolgt an die Rechenergebnisse, die vom GPU-Speicher zurück an den Host-Speicher übertragen werden. Wenn viel Zeit für die Datenübertragung und den Kernel-Start aufgewendet wird, die an den Kernel zur Berechnung gelieferte Arbeit nicht schwer ist und die tatsächliche Berechnungszeit sehr kurz ist, wird die GPU-Auslastung nicht verbessert, und sogar der Leerlauf verbessert sich geschehen.
 Bilder
Bilder
Geschätzter Servicerahmen
3.GPU-Optimierungspraxis
3.1 Systemoptimierung
3.1.1 Physische Maschine
In Bezug auf die physische Maschinenoptimierung können einige herkömmliche Optimierungsideen übernommen werden. Der Hauptzweck besteht darin, die Kosten anderer Systeme zu senken andere Gemeinkosten als die GPU, wodurch die Zwischenhändler der Virtualisierung reduziert werden, um Gewinne zu erzielen. Im Allgemeinen kann eine Reihe von Systemoptimierungen die Leistung um 1–2 % verbessern. Aus unserer Praxis muss die Optimierung mit den tatsächlichen Fähigkeiten der Cloud-Anbieter kombiniert werden.
● Interrupt-Isolation: Isolieren Sie GPU-Interrupts, um zu vermeiden, dass Interrupts von anderen Geräten die GPU-Rechenleistung beeinträchtigen.
● Kernel-Versions-Upgrade: Verbessern Sie die Systemstabilität und -sicherheit, verbessern Sie die Kompatibilität und Leistung des GPU-Treibers.
● Transparente Anweisungsübertragung: Übertragen Sie GPU-Anweisungen transparent direkt an das physische Gerät, um die Rechengeschwindigkeit der GPU zu beschleunigen.
3.1.2 Virtualisierung und Container
Binden Sie in Situationen mit mehreren Karten einen einzelnen Pod an einen bestimmten NUMA-Knoten und erhöhen Sie so die Geschwindigkeit der Datenübertragung zwischen CPU und GPU.
● CPU-NUMA-Affinität, Affinität bezieht sich darauf, welche Speicherzugriffe aus CPU-Sicht schneller sind und eine geringere Latenz haben. Wie bereits erwähnt, ist lokaler Speicher, der direkt mit der CPU verbunden ist, schneller. Daher kann das Betriebssystem lokalen Speicher entsprechend der CPU zuweisen, auf der sich die Aufgabe befindet, um die Zugriffsgeschwindigkeit und Leistung zu verbessern. Dies basiert auf Überlegungen zur CPU-NUMA-Affinität und versucht, die Aufgabe im lokalen NUMA-Knoten auszuführen. Im Xiaohongshu-Szenario ist der Speicherzugriffsaufwand auf der CPU nicht gering. Wenn Sie der CPU erlauben, sich direkt mit dem lokalen Speicher zu verbinden, können Sie viel Zeit für die Kernel-Ausführung auf der CPU sparen und so genügend Platz für die GPU schaffen.
● Durch die Steuerung der CPU-Auslastung auf 70 % kann die Verzögerung von 200 ms -> 150 ms reduziert werden.
3.1.3 Spiegel
Kompilierungsoptimierung. Unterschiedliche CPUs verfügen über unterschiedliche Unterstützungsfunktionen für die Unterrichtsstufen, und auch die von verschiedenen Cloud-Anbietern gekauften Modelle sind unterschiedlich. Eine relativ einfache Idee besteht darin, das Image mit unterschiedlichen Befehlssätzen in unterschiedlichen Hardwareszenarien zu kompilieren. Bei der Implementierung von Operatoren verfügen viele Operatoren bereits über Anweisungen wie AVX512. Am Beispiel des Modells Intel(R) Mit der Befehlsoptimierung wird der CPU-Durchsatz bei diesem Modell um 10 % erhöht.
# Intel(R) Xeon(R) Platinum 8163 for ali intelbuild:intel --copt=-march=skylake-avx512 --copt=-mmmx --copt=-mno-3dnow --copt=-mssebuild:intel --copt=-msse2 --copt=-msse3 --copt=-mssse3 --copt=-mno-sse4a --copt=-mcx16build:intel --copt=-msahf --copt=-mmovbe --copt=-maes --copt=-mno-sha --copt=-mpclmulbuild:intel --copt=-mpopcnt --copt=-mabm --copt=-mno-lwp --copt=-mfma --copt=-mno-fma4build:intel --copt=-mno-xop --copt=-mbmi --copt=-mno-sgx --copt=-mbmi2 --copt=-mno-pconfigbuild:intel --copt=-mno-wbnoinvd --copt=-mno-tbm --copt=-mavx --copt=-mavx2 --copt=-msse4.2build:intel --copt=-msse4.1 --copt=-mlzcnt --copt=-mrtm --copt=-mhle --copt=-mrdrnd --copt=-mf16cbuild:intel --copt=-mfsgsbase --copt=-mrdseed --copt=-mprfchw --copt=-madx --copt=-mfxsrbuild:intel --copt=-mxsave --copt=-mxsaveopt --copt=-mavx512f --copt=-mno-avx512erbuild:intel --copt=-mavx512cd --copt=-mno-avx512pf --copt=-mno-prefetchwt1build:intel --copt=-mno-clflushopt --copt=-mxsavec --copt=-mxsavesbuild:intel --copt=-mavx512dq --copt=-mavx512bw --copt=-mavx512vl --copt=-mno-avx512ifmabuild:intel --copt=-mno-avx512vbmi --copt=-mno-avx5124fmaps --copt=-mno-avx5124vnniwbuild:intel --copt=-mno-clwb --copt=-mno-mwaitx --copt=-mno-clzero --copt=-mno-pkubuild:intel --copt=-mno-rdpid --copt=-mno-gfni --copt=-mno-shstk --copt=-mno-avx512vbmi2build:intel --copt=-mavx512vnni --copt=-mno-vaes --copt=-mno-vpclmulqdq --copt=-mno-avx512bitalgbuild:intel --copt=-mno-movdiri --copt=-mno-movdir64b --copt=-mtune=skylake-avx512
3.2 Computeroptimierung
3.2.1 Nutzen Sie die Rechenleistung voll aus
● Computeroptimierung: Sie müssen zunächst die Hardwareleistung vollständig verstehen und gründlich verstehen. Im Xiaohongshu-Szenario sind, wie in der folgenden Abbildung dargestellt, zwei Kernprobleme aufgetreten:
1 Es gibt viele Speicherzugriffe auf die CPU und die Häufigkeit von Speicherseitenfehlern ist hoch, was zu einer Verschwendung von CPU-Ressourcen führt Anforderungslatenz.
2. Bei Online-Inferenzdiensten weisen Berechnungen normalerweise zwei Merkmale auf: Die Stapelgröße einer einzelnen Anforderung ist klein und der Parallelitätsumfang eines einzelnen Dienstes ist groß. Eine kleine Batchgröße führt dazu, dass der Kernel die Rechenleistung der GPU nicht vollständig nutzen kann. Die GPU-Kernel-Ausführungszeit ist im Allgemeinen kürzer und kann den Overhead des Kernel-Starts nicht vollständig abdecken. Die Kernel-Startzeit kann sogar länger sein als die Kernel-Ausführungszeit. In TensorFlow wird ein einzelner Cuda Stream-Startkernel zu einem Engpass, was in Inferenzszenarien zu einer GPU-Auslastung von nur 50 % führt. Darüber hinaus ist es für kleine Modellszenarien (einfache dichte Netzwerke) nicht kosteneffektiv, die CPU durch eine GPU zu ersetzen, was die Komplexität des Modells begrenzt.
 Bilder
Bilder
● Um die beiden oben genannten Probleme zu lösen, haben wir die folgenden Maßnahmen ergriffen:
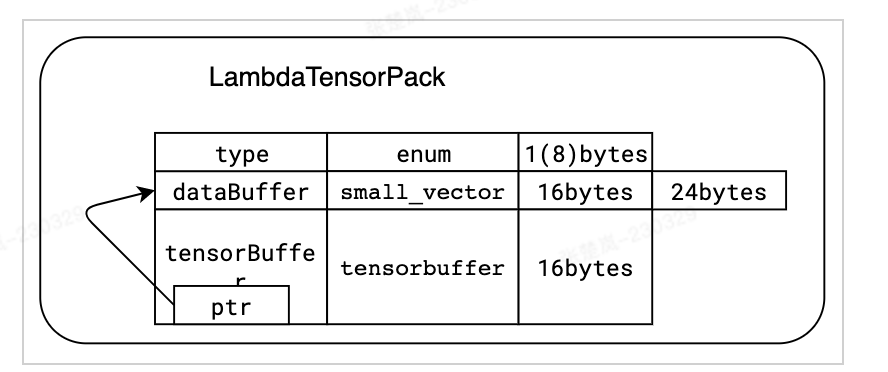
1. Um das Problem der hohen Häufigkeit von Speicherseitenfehlern anzugehen, verwenden wir die Jemalloc-Bibliothek, um das Speicherrecycling zu optimieren Mechanismus und aktivieren Sie die transparente Hugepages-Funktion des Betriebssystems. Darüber hinaus entwerfen wir für die besonderen Speicherzugriffseigenschaften von Lambda spezielle Datenstrukturen und optimieren Speicherzuweisungsstrategien, um eine Speicherfragmentierung so weit wie möglich zu vermeiden. Gleichzeitig haben wir die Schnittstelle tf_serving direkt umgangen und TensorFlow direkt aufgerufen, wodurch die Serialisierung und Deserialisierung von Daten reduziert wurde. Diese Optimierungen haben den Durchsatz in Homepage- und In-Stream-Feinabstimmungsszenarien um mehr als 10 % verbessert und die Latenz in den meisten Werbeszenarien um 50 % reduziert.
 Bilder
Bilder
sind mit dem Tensorflow::Tensor-Format kompatibel und werden nullkopiert, bevor Funktionen an tensorflow::SessionRun übergeben werden
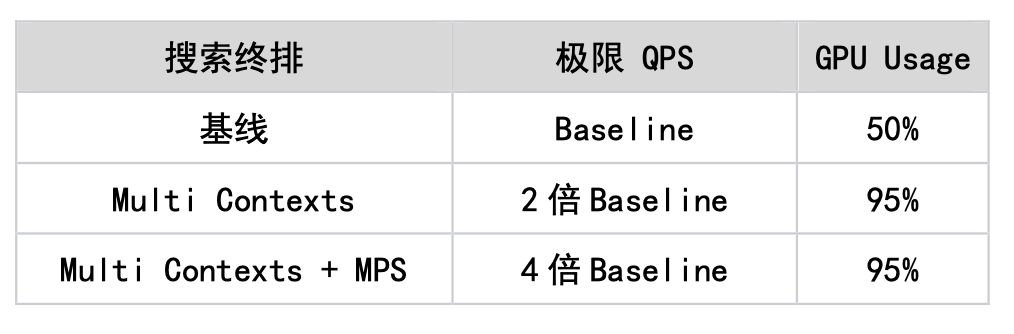
2. Als Reaktion auf das Problem des einzelnen Cuda-Streams von TensorFlow unterstützen wir die Funktionen von Multi Streams und Multi Contexts, vermeiden den durch Mutex-Sperren verursachten Leistungsengpass und erhöhen erfolgreich die GPU-Auslastung auf 90+ %. Gleichzeitig nutzen wir die von Nvidia bereitgestellte Cuda MPS-Funktion, um räumliches Multiplexen der GPU zu realisieren (unterstützt mehrere Kernel-Ausführungen gleichzeitig) und so die Auslastung der GPU weiter zu verbessern. Auf dieser Grundlage wurde das Ranking-Modell von Search erfolgreich auf der GPU implementiert. Darüber hinaus haben wir es auch in anderen Geschäftsbereichen erfolgreich implementiert, darunter Homepage-Layout, Werbung usw. Die folgende Tabelle zeigt eine Optimierungssituation im Suchranking-Szenario.
 Bilder
Bilder
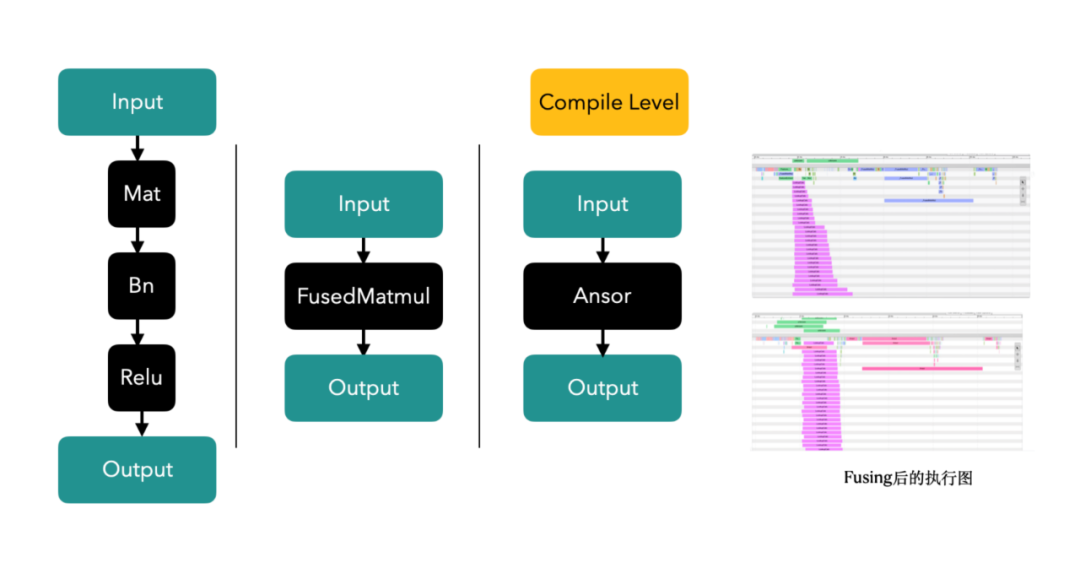
3. Op/Kernel-Fusionstechnologie: Generieren Sie leistungsstärkere Tensorflow-Operatoren durch Handschrift- oder Diagrammkompilierungs- und Optimierungstools und nutzen Sie dabei den Cache der CPU und den Shared Memory der GPU vollständig aus, um den Systemdurchsatz zu verbessern.
 Bilder
Bilder
Im Inflow-Szenario sind die Operatoren fusioniert, und Sie können sehen, dass ein einzelner Anruf 12 ms -> 5 ms dauert
3.2.2 Vermeidung von Rechenleistungsverschwendung
1. Systemlink Es gibt Raum für Optimierung
a. Vorläufige Berechnung: Bei der Verarbeitung benutzerseitiger Berechnungen muss eine große Anzahl von Notizen berechnet werden. Am Beispiel des Abflusses müssen etwa 5.000 Notizen berechnet werden. und Lambda hat Slicing-Verarbeitung für sie. Um wiederholte Berechnungen zu vermeiden, werden die benutzerseitigen Berechnungen der Anfangszeile parallel zur Rückrufphase verschoben, sodass die Berechnung des Benutzervektors von mehreren Wiederholungen auf nur einmal reduziert wird und 40 % der Maschinen optimiert werden im Rough-Row-Szenario.
2. In-Graph-Training für den Inferenzprozess:
a Berechnungsvorverarbeitung: Ein Teil der Berechnung kann im Voraus durch das Einfrieren des Diagramms verarbeitet werden. Bei der Argumentation ist es nicht erforderlich, Berechnungen zu wiederholen.
b. Optimierung des Einfrierens des Ausgabemodells: Bei der Ausgabe des Modells werden alle Parameter zusammen mit dem Diagramm selbst generiert, um ein eingefrorenes Diagramm (eingefrorenes Diagramm) zu erstellen und Vorverarbeitungsberechnungen durchzuführen. Viele vorberechnete Variablenoperatoren können in Const-Operatoren (GPU) umgewandelt werden Die Nutzung ist um 12 % gesunken
c. Zusammengeführte Berechnungen in Inferenzszenarien: Jeder Stapel enthält nur einen Benutzer, d. Aufteilung des GPU-Operators: Verschieben Sie alle Operatoren nach der Suche auf die GPU, um das Kopieren von Daten zwischen CPU und GPU zu vermeiden. Kopieren Sie Daten von GPU zu CPU: Packen Sie die Daten und kopieren Sie sie einmal.
f. Beschleunigen Sie Berechnungen durch die GPU, um die Leistung zu verbessern. GPU-basierte Teiloperatoren: CPU-Kopie auslassen Anzahl der Eingaben in die GPU (N -> 1), Erhöhung der Berechnungsmenge für eine Berechnung (Wiederverwendung der Parallelitätsfähigkeit des kleinen GPU-Kerns)
Bilder
3.2.3 Dynamische Rechenleistung den ganzen Tag über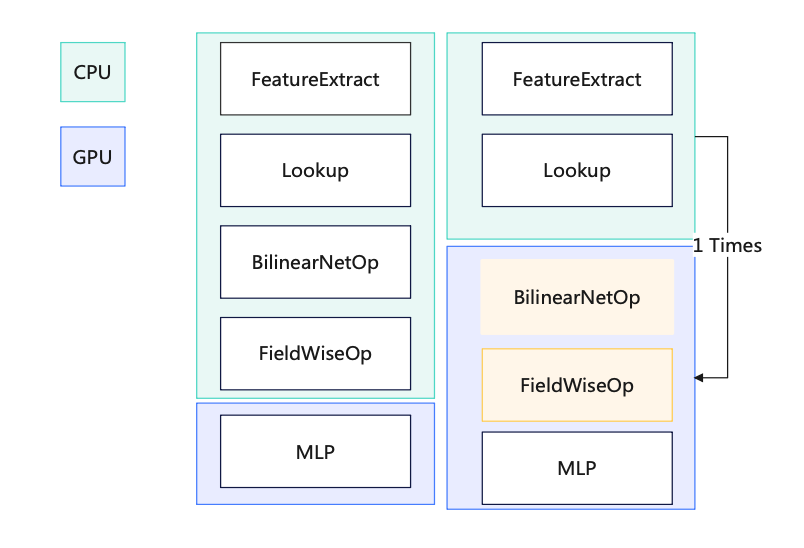 ● Das dynamische Computing-Downgrade verbessert die Effizienz der Ressourcennutzung im Laufe des Tages und passt die Lambda-Last automatisch mit negativem Feedback auf der zweiten Ebene an, um einen Einzelzonen-Stresstest zu erreichen. Es ist nicht erforderlich, sich vorher manuell auf das Downgrade vorzubereiten.
● Das dynamische Computing-Downgrade verbessert die Effizienz der Ressourcennutzung im Laufe des Tages und passt die Lambda-Last automatisch mit negativem Feedback auf der zweiten Ebene an, um einen Einzelzonen-Stresstest zu erreichen. Es ist nicht erforderlich, sich vorher manuell auf das Downgrade vorzubereiten.
● Wichtige Geschäftsszenarien wie das verfeinerte Outbound-Ranking, die vorläufige Ausgangssortierung, die verfeinerte Eingangssortierung, die vorläufige interne Eingangssortierung und die Suche wurden alle gestartet. ● Das Kapazitätsproblem in mehreren Geschäftsbereichen wurde gelöst, der durch das Geschäftswachstum verursachte lineare Ressourcenanstieg wirksam abgemildert und die Robustheit des Systems erheblich verbessert. In den Geschäftsbereichen gab es nach Einführung der Funktion keine Unfälle mit P3 oder höher, die auf einen starken Rückgang der sofortigen Erfolgsquote zurückzuführen waren. ● Verbessern Sie die Effizienz der Ressourcennutzung im Laufe des Tages erheblich. Nehmen Sie als Beispiel die Instream-Feinabstimmung (wie in der Abbildung unten gezeigt), die Anzahl der CPU-Kerne, die während des dreitägigen Maifeiertags von 10:00 bis 17:00 Uhr verwendet werden 24:00 behält eine flache Linie von 50 Kernen bei (Dithering entspricht der Release-Version)
Bilder
3.2.4 Wechsel zu besserer Hardware ● Die Leistung der A10-GPU beträgt das 1,5-fache der der T4-GPU. Gleichzeitig ist das A10-Modell mit einer CPU (Icelake, 10 nm) ausgestattet, einer neueren Generation als das T4-Modell (Skylake, 14 nm), und der Preis beträgt nur das 1,2-fache des T4-Modells . Wir werden darüber nachdenken, Modelle wie den A30 in Zukunft auch online zu nutzen.
● Die Leistung der A10-GPU beträgt das 1,5-fache der der T4-GPU. Gleichzeitig ist das A10-Modell mit einer CPU (Icelake, 10 nm) ausgestattet, einer neueren Generation als das T4-Modell (Skylake, 14 nm), und der Preis beträgt nur das 1,2-fache des T4-Modells . Wir werden darüber nachdenken, Modelle wie den A30 in Zukunft auch online zu nutzen.
3.3 Bildoptimierung
Bilder
3.3.1 Automatische Kompilierungsoptimierung des DL-Stacks
● BladeDISC ist Alibabas neuester Open-Source-Compiler für dynamisches Formen-Deep-Learning, der auf MLIR basiert. Xiaohongshus Teil zur automatischen Diagrammoptimierung stammt aus diesem Framework (die Blade-Inferenzbeschleunigungsbibliothek ist Apache 2.0 Open Source, kann in jeder Cloud verwendet werden und hat keine Rechte an geistigem Eigentum Risiko). Dieses Framework bietet eine TF-Graph-Kompilierungsoptimierung (einschließlich Dynamic Shape Compiler, Sparse-Subgraph-Optimierung) und kann auch unsere eigene benutzerdefinierte Operatoroptimierung überlagern, die sich besser an unsere Geschäftsszenarien anpassen lässt. Bei der Stresstest-Einzelmaschineninferenz kann der QPS um 20 % erhöht werden. ● Schlüsseltechnologien dieses Frameworks (1) MLIR-Infrastruktur MLIR, Multi-Level Intermediate Representation (Multi-Level Intermediate Representation), ist ein von Google initiiertes Open-Source-Projekt. Sein Zweck besteht darin, eine flexible, erweiterbare mehrschichtige IR-Infrastruktur und Compiler-Dienstprogrammbibliothek bereitzustellen und ein einheitliches Framework für Entwickler von Compilern und Sprachtools bereitzustellen. Das Design von MLIR wird von LLVM beeinflusst, aber im Gegensatz zu LLVM konzentriert sich MLIR hauptsächlich auf das Design und die Erweiterung der Zwischendarstellung (IR). MLIR bietet ein mehrstufiges IR-Design, das den Kompilierungsprozess von Hochsprachen bis hin zu Low-Level-Hardware unterstützen kann, und bietet umfassende Infrastrukturunterstützung und modulare Designarchitektur, sodass Entwickler die Funktionen von MLIR problemlos erweitern können. Darüber hinaus verfügt MLIR auch über starke Glue-Fähigkeiten und kann in verschiedene Programmiersprachen und Tools integriert werden. MLIR ist eine leistungsstarke Compiler-Infrastruktur und Tool-Bibliothek, die Entwicklern von Compilern und Sprachtools eine einheitliche und flexible Zwischendarstellungssprache bietet, die die Kompilierungsoptimierung und Codegenerierung erleichtern kann. (2) Dynamische Formkompilierung Die Einschränkungen der statischen Form bedeuten, dass die Form jeder Ein- und Ausgabe beim Schreiben eines Deep-Learning-Modells im Voraus bestimmt werden muss und zur Laufzeit nicht geändert werden kann. Dies schränkt die Flexibilität und Skalierbarkeit von Deep-Learning-Modellen ein und erfordert daher einen Deep-Learning-Compiler, der dynamische Formen unterstützt. 3.3.2 Genauigkeitsanpassung ● Eine Möglichkeit zur Quantisierung ist die Verwendung von FP16 FP16-Berechnungsoptimierung: Das Ersetzen von FP32-Berechnungen durch FP16 in der MLP-Ebene kann die GPU-Nutzung erheblich reduzieren (relativ 13). % Abnahme ) Bei der Anpassung von FP16 bedeutet die Wahl der White-Box-Methode zur Präzisionsoptimierung, dass wir genauer steuern können, welche Ebenen Berechnungen mit geringer Genauigkeit verwenden, und basierend auf Erfahrung kontinuierlich anpassen und optimieren können. Diese Methode erfordert ein relativ tiefgreifendes Verständnis und eine Analyse der Modellstruktur. Je nach den Merkmalen und Berechnungsanforderungen des Modells können gezielte Anpassungen vorgenommen werden, um eine höhere Kostenleistung zu erzielen. Im Gegensatz dazu ist die Black-Box-Methode relativ einfach. Sie erfordert kein Verständnis der internen Struktur des Modells. Sie muss lediglich einen bestimmten Toleranzschwellenwert festlegen, um die Genauigkeit zu optimieren. Der Vorteil dieser Methode besteht darin, dass sie einfach zu bedienen ist und relativ geringe Anforderungen an Modellschüler stellt, sie kann jedoch zu Einbußen bei Leistung und Genauigkeit führen. Daher muss je nach Situation entschieden werden, ob zur Genauigkeitsoptimierung die White-Box- oder die Black-Box-Methode gewählt werden soll. Wenn Sie eine höhere Leistung und Genauigkeit anstreben und über ausreichende Erfahrung und technische Fähigkeiten verfügen, ist der White-Box-Ansatz möglicherweise besser geeignet. Wenn eine einfache Bedienung und eine schnelle Iteration wichtiger sind, ist der Black-Box-Ansatz möglicherweise praktischer. Von 2021 bis Ende 2022 hat sich die Inferenzrechenleistung von Xiaohongshu um das 30-fache erhöht, die wichtigsten Benutzerindikatoren sind um mehr als 10 % gestiegen und gleichzeitig sind die Clusterressourcen gestiegen wurden insgesamt um mehr als 50 % eingespart. Unserer Meinung nach sollte sich Xiaohongshus Entwicklungspfad in der KI-Technologie an den Geschäftsanforderungen orientieren und die Entwicklung von Technologie und Geschäft in Einklang bringen: Bei der Erzielung technologischer Innovationen müssen auch Kosten, Effizienz und Nachhaltigkeit berücksichtigt werden. Im Folgenden finden Sie einige Gedanken während des Optimierungsprozesses: Optimieren Sie den Algorithmus und verbessern Sie die Systemleistung. Dies ist die Kernaufgabe des Xiaohongshu-Teams für maschinelles Lernen. Durch die Optimierung von Algorithmen und die Verbesserung der Systematisierung können Geschäftsanforderungen besser unterstützt und die Benutzererfahrung verbessert werden. Wenn jedoch die Ressourcen begrenzt sind, muss das Team den Schwerpunkt der Optimierung klären und eine Überoptimierung vermeiden. Bauen Sie eine Infrastruktur auf und verbessern Sie die Datenverarbeitungsfunktionen. Infrastruktur ist für die Unterstützung von KI-Anwendungen von entscheidender Bedeutung. Xiaohongshu kann weitere Investitionen in den Infrastrukturbau in Betracht ziehen, einschließlich Rechen- und Speicherkapazitäten, Rechenzentren und Netzwerkarchitektur. Darüber hinaus ist es auch sehr wichtig, die Datenverarbeitungsfähigkeiten zu verbessern, um maschinelles Lernen und datenwissenschaftliche Anwendungen besser zu unterstützen. Verbessern Sie die Talentdichte und die Organisationsstruktur Ihres Teams. Ein exzellentes Team für maschinelles Lernen benötigt Talente mit unterschiedlichen Fähigkeiten und Hintergründen, darunter Datenwissenschaftler, Algorithmeningenieure, Softwareentwickler usw.; die Optimierung der Organisationsstruktur kann auch dazu beitragen, die Teameffizienz und Innovationsfähigkeiten zu verbessern. Win-Win-Kooperation und offene Innovation. Xiaohongshu arbeitet weiterhin mit anderen Unternehmen, akademischen Institutionen und Open-Source-Communities zusammen, um gemeinsam die Entwicklung der KI-Technologie voranzutreiben, was Xiaohongshu dabei hilft, mehr Ressourcen und Wissen zu erhalten und eine offenere und innovativere Organisation zu werden. Diese Lösung bringt die Architektur für maschinelles Lernen von Xiaohongshu auf das höchste Niveau der Branche. In Zukunft werden wir weiterhin Motor-Upgrades fördern, Kosten senken und die Effizienz steigern, neue Technologien einführen, um die Produktivität des maschinellen Lernens von Xiaohongshu zu verbessern, und die tatsächlichen Geschäftsszenarien von Xiaohongshu weiter integrieren, indem wir von der Einzelmoduloptimierung auf die Gesamtsystemoptimierung umsteigen. und darüber hinaus die personalisierten differenziellen Merkmale des geschäftlichen Datenverkehrs einzuführen, um die ultimative Kostensenkung und Effizienzsteigerung zu erreichen. Wir freuen uns auf Menschen mit hohen Idealen, die sich uns anschließen! Zhang Chulan (Du Zeyu): Abteilung für Geschäftstechnologie Absolvent der East China Normal University, Leiter des Kommerzialisierungs-Engine-Teams, hauptsächlich verantwortlich für den Aufbau kommerzialisierter Online-Dienste. Lu Guang (Peng Peng): Abteilung für intelligente Verteilung Absolvent der Shanghai Jiao Tong University, Maschineningenieur für maschinelles Lernen, hauptsächlich verantwortlich für die Lambda-GPU-Optimierung. Ian (Chen Jianxin): Abteilung für intelligente Verteilung Absolvent der Universität für Post und Telekommunikation in Peking, Maschineningenieur für maschinelles Lernen, hauptsächlich verantwortlich für Lambda-Parameterserver und GPU-Optimierung. Aka Yu (Liu Zhaoyu): Abteilung für intelligente Verteilung Absolvent der Tsinghua-Universität und ist Ingenieur für maschinelles Lernen. Er ist hauptsächlich für die damit verbundene Forschung und Erforschung in Richtung Feature-Engines verantwortlich. Besonderer Dank geht an: Alle Studierenden der Abteilung Intelligente Verteilung
4. Zusammenfassung
5. Team
Das obige ist der detaillierte Inhalt vonDamit die Rechenleistung nicht länger zum Engpass wird, nutzt Xiaohongshu die Methode zur Optimierung heterogener Hardware-Inferenzen für maschinelles Lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Schauen Sie sich den Sklearn-Algorithmus für maschinelles Lernen von Python an
- Wie kann unüberwachtes maschinelles Lernen der industriellen Automatisierung zugute kommen?
- So nutzen Sie maschinelles Lernen zur Stimmungsanalyse
- Maschinelles Lernen: Unterschätzen Sie nicht die Leistungsfähigkeit von Baummodellen
- Konfigurationsmethode für die Verwendung von RStudio für die Modellentwicklung für maschinelles Lernen auf Linux-Systemen