
Heim >Technologie-Peripheriegeräte >KI >Wie kann unüberwachtes maschinelles Lernen der industriellen Automatisierung zugute kommen?
Wie kann unüberwachtes maschinelles Lernen der industriellen Automatisierung zugute kommen?

- PHPznach vorne
- 2023-04-08 17:21:011754Durchsuche
Moderne Industrieumgebungen sind voll von Sensoren und intelligenten Komponenten, und alle diese Geräte zusammen erzeugen eine Fülle von Daten. Diese Daten, die heute in den meisten Fabriken ungenutzt bleiben, ermöglichen eine Vielzahl spannender neuer Anwendungen. Tatsächlich generiert eine durchschnittliche Fabrik laut IBM täglich 1 TB Produktionsdaten. Allerdings werden nur etwa 1 % der Daten in umsetzbare Erkenntnisse umgewandelt.

Maschinelles Lernen (ML) ist eine grundlegende Technologie, die entwickelt wurde, um diese Daten zu nutzen und enorme Werte zu erschließen. Mithilfe von Trainingsdaten können maschinelle Lernsysteme mathematische Modelle erstellen, die einem System beibringen, bestimmte Aufgaben ohne explizite Anweisungen auszuführen.
ML verwendet Algorithmen, die auf Daten reagieren, um Entscheidungen weitgehend ohne menschliches Eingreifen zu treffen. Die häufigste Form des maschinellen Lernens in der industriellen Automatisierung ist das überwachte maschinelle Lernen, bei dem große Mengen historischer, von Menschen gekennzeichneter Daten zum Trainieren von Modellen verwendet werden (d. h. das Training von vom Menschen überwachten Algorithmen).
Dies ist nützlich bei bekannten Problemen wie Lagerdefekten, Schmierungsausfällen oder Produktfehlern. Überwachtes maschinelles Lernen greift dann zu kurz, wenn nicht genügend historische Daten verfügbar sind, die Kennzeichnung zu zeitaufwändig oder zu teuer ist oder Benutzer nicht genau wissen, wonach sie in den Daten suchen. Hier kommt unüberwachtes maschinelles Lernen ins Spiel.
Unüberwachtes maschinelles Lernen zielt darauf ab, unbeschriftete Daten mithilfe von Algorithmen zu bearbeiten, die gut darin sind, Muster zu erkennen und Anomalien in den Daten zu lokalisieren. Richtig angewandtes unbeaufsichtigtes maschinelles Lernen bedient eine Vielzahl von Anwendungsfällen in der industriellen Automatisierung, von Zustandsüberwachung und Leistungstests bis hin zu Cybersicherheit und Anlagenverwaltung.
Überwachtes Lernen vs. unüberwachtes Lernen
Überwachtes maschinelles Lernen ist einfacher durchzuführen als unüberwachtes maschinelles Lernen. Mit einem richtig trainierten Modell kann es sehr konsistente und zuverlässige Ergebnisse liefern. Für überwachtes maschinelles Lernen sind möglicherweise große Mengen historischer Daten erforderlich, da diese alle relevanten Fälle umfassen müssen. Das heißt, um Produktfehler zu erkennen, müssen die Daten eine ausreichende Anzahl von Fällen fehlerhafter Produkte enthalten. Die Kennzeichnung dieser riesigen Datensätze kann zeitaufwändig und teuer sein. Darüber hinaus ist das Trainieren von Modellen eine Kunst. Um gute Ergebnisse zu erzielen, sind große Datenmengen erforderlich, die ordnungsgemäß organisiert sind.
Heutzutage wurde der Prozess des Benchmarkings verschiedener ML-Algorithmen mithilfe von Tools wie AutoML erheblich vereinfacht. Gleichzeitig kann eine übermäßige Einschränkung des Trainingsprozesses zu einem Modell führen, das auf dem Trainingssatz gut abschneidet, auf realen Daten jedoch eine schlechte Leistung erbringt. Ein weiterer wesentlicher Nachteil besteht darin, dass überwachtes maschinelles Lernen nicht sehr effektiv ist, um unerwartete Trends in Daten zu erkennen oder neue Phänomene zu entdecken. Bei solchen Anwendungen kann unüberwachtes maschinelles Lernen bessere Ergebnisse liefern.
Gängige Techniken des unbeaufsichtigten maschinellen Lernens
Im Vergleich zum überwachten maschinellen Lernen funktioniert unüberwachtes maschinelles Lernen nur bei unbeschrifteten Eingaben. Es bietet leistungsstarke Tools für die Datenexploration, um unbekannte Muster und Zusammenhänge ohne menschliche Hilfe zu entdecken. Die Möglichkeit, unbeschriftete Daten zu bearbeiten, spart Zeit und Geld und ermöglicht unbeaufsichtigtes maschinelles Lernen, die Daten zu bearbeiten, sobald die Eingabe generiert wird.
Der Nachteil ist, dass unüberwachtes maschinelles Lernen komplexer ist als überwachtes maschinelles Lernen. Es ist teurer, erfordert ein höheres Maß an Fachwissen und erfordert oft mehr Daten. Seine Ausgabe ist tendenziell weniger zuverlässig als überwachtes maschinelles Lernen und erfordert letztlich menschliche Aufsicht, um optimale Ergebnisse zu erzielen.
Drei wichtige Formen unbeaufsichtigter maschineller Lerntechniken sind Clustering, Anomalieerkennung und Reduzierung der Datendimensionalität.
Clustering
Wie der Name schon sagt, beinhaltet Clustering die Analyse eines Datensatzes, um gemeinsame Merkmale zwischen Daten zu identifizieren und ähnliche Instanzen zu gruppieren. Da Clustering eine unbeaufsichtigte ML-Technik ist, bestimmt der Algorithmus (und nicht ein Mensch) die Rankingkriterien. Daher kann Clustering zu überraschenden Entdeckungen führen und ist ein hervorragendes Werkzeug zur Datenexploration.
Um ein einfaches Beispiel zu nennen: Stellen Sie sich drei Personen vor, die in einer Produktionsabteilung Früchte sortieren sollen. Einer könnte nach Fruchttyp sortieren – Zitrusfrüchte, Steinobst, tropische Früchte usw.; ein anderer könnte nach Farbe sortieren und ein dritter könnte nach Form sortieren; Jede Methode hebt einen anderen Satz von Merkmalen hervor.
Clustering kann in viele Arten unterteilt werden. Die häufigsten sind:
Exklusives Clustering: Eine Dateninstanz ist exklusiv einem Cluster zugeordnet.
Fuzzy- oder überlappendes Clustering (Fuzzy-Clustering): Eine Dateninstanz kann mehreren Clustern zugewiesen werden. Orangen sind beispielsweise sowohl Zitrusfrüchte als auch tropische Früchte. Bei unbeaufsichtigten ML-Algorithmen, die mit unbeschrifteten Daten arbeiten, ist es möglich, eine Wahrscheinlichkeit dafür zuzuweisen, dass ein Datenblock korrekt zu Gruppe A gegenüber Gruppe B gehört.
Hierarchisches Clustering: Diese Technik beinhaltet den Aufbau einer hierarchischen Struktur geclusterter Daten anstelle einer Reihe von Clustern. Orangen gehören zu den Zitrusfrüchten, gehören aber auch zur Gruppe der größeren Kugelfrüchte und können von allen Fruchtgruppen weiter aufgenommen werden.
Sehen wir uns eine Reihe der beliebtesten Clustering-Algorithmen an:
- K-Means
K-Means-Algorithmus klassifiziert Daten in K-Cluster, wobei der Wert von K vom Benutzer festgelegt wird. Zu Beginn des Prozesses weist der Algorithmus zufällig K Datenpunkte als Schwerpunkte für K Cluster zu. Als nächstes berechnet es den Mittelwert zwischen jedem Datenpunkt und dem Schwerpunkt seines Clusters. Dies führt dazu, dass die Daten dem Cluster neu zugewiesen werden. An diesem Punkt berechnet der Algorithmus den Schwerpunkt neu und wiederholt die Mittelwertberechnung. Der Vorgang der Berechnung der Schwerpunkte und der Neuordnung der Cluster wird wiederholt, bis eine konstante Lösung erreicht ist (siehe Abbildung 1).

Abbildung 1: Der K-Means-Algorithmus unterteilt den Datensatz in K Cluster, indem er zunächst K Datenpunkte zufällig als Schwerpunkte auswählt und dann die verbleibenden Instanzen zufällig den Clustern zuordnet.
K-Means-Algorithmus ist einfach und effizient. Es ist sehr nützlich für die Mustererkennung und das Data Mining. Der Nachteil besteht darin, dass zur Optimierung des Setups einige fortgeschrittene Kenntnisse des Datensatzes erforderlich sind. Es ist auch überproportional von Ausreißern betroffen.
- K-Median
Der K-Median-Algorithmus ist ein enger Verwandter von K-Means. Es verwendet im Wesentlichen den gleichen Prozess, außer dass anstelle des Mittelwerts jedes Datenpunkts der Median berechnet wird. Daher ist der Algorithmus weniger empfindlich gegenüber Ausreißern.
Hier sind einige häufige Anwendungsfälle der Clusteranalyse:
- Clustering ist sehr effektiv für Anwendungsfälle wie die Segmentierung. Dies wird häufig mit Kundenanalysen in Verbindung gebracht. Es kann auch auf Anlageklassen angewendet werden, nicht nur zur Analyse der Produktqualität und -leistung, sondern auch zur Identifizierung von Nutzungsmustern, die sich auf die Produktleistung und -lebensdauer auswirken können. Dies ist hilfreich für OEM-Unternehmen, die „Flotten“ von Vermögenswerten verwalten, beispielsweise automatisierte mobile Roboter in intelligenten Lagerhäusern oder Drohnen zur Inspektion und Datenerfassung.
- Es kann zur Bildsegmentierung im Rahmen von Bildverarbeitungsvorgängen verwendet werden.
- Die Clusteranalyse kann auch als Vorverarbeitungsschritt verwendet werden, um bei der Vorbereitung von Daten für überwachte ML-Anwendungen zu helfen.
Anomalieerkennung
Die Anomalieerkennung ist für eine Vielzahl von Anwendungsfällen von entscheidender Bedeutung, von der Fehlererkennung über die Zustandsüberwachung bis hin zur Cybersicherheit. Dies ist eine Schlüsselaufgabe beim unbeaufsichtigten maschinellen Lernen. Es gibt mehrere Anomalieerkennungsalgorithmen, die beim unbeaufsichtigten maschinellen Lernen verwendet werden. Schauen wir uns zwei der beliebtesten an:
- Isolation Forest-Algorithmus
Der Standardansatz zur Anomalieerkennung besteht darin, eine Reihe von Normalwerten festzulegen Werte und analysieren Sie dann jedes Datenelement, um festzustellen, ob und wie stark es vom Normalwert abweicht. Bei der Arbeit mit riesigen Datensätzen, wie sie in ML verwendet werden, ist dies ein sehr zeitaufwändiger Prozess. Der Isolation Forest-Algorithmus verfolgt den umgekehrten Ansatz. Es definiert Ausreißer als weder häufig noch sehr unterschiedlich zu anderen Instanzen im Datensatz. Daher lassen sie sich in anderen Instanzen leichter vom Rest des Datensatzes isolieren.
Der Isolationswaldalgorithmus hat den geringsten Speicherbedarf und die benötigte Zeit hängt linear von der Größe des Datensatzes ab. Sie können hochdimensionale Daten verarbeiten, auch wenn diese irrelevante Attribute beinhalten.
- Lokaler Ausreißerfaktor (LOF)
Eine der Herausforderungen bei der Identifizierung von Ausreißern nur anhand ihrer Entfernung vom Schwerpunkt besteht darin, dass Datenpunkte, die nur kurze Entfernungen von kleinen Clustern entfernt sind, wahrscheinlich Ausreißer sind, wohingegen Datenpunkte Punkte, die nicht weit von großen Clustern entfernt sind, sind wahrscheinlich Ausreißer. Punkte, die weit entfernt zu sein scheinen, sind es möglicherweise nicht. Der LOF-Algorithmus soll diese Unterscheidung treffen.
LOF definiert einen Ausreißer als einen Datenpunkt, dessen lokale Dichteabweichung viel größer ist als die seiner benachbarten Datenpunkte (siehe Abbildung 2). Obwohl es wie K-Means einige vorherige Benutzereinstellungen erfordert, kann es sehr effektiv sein. Es kann auch auf die Neuheitserkennung angewendet werden, wenn es als halbüberwachter Algorithmus verwendet und nur auf normalen Daten trainiert wird.
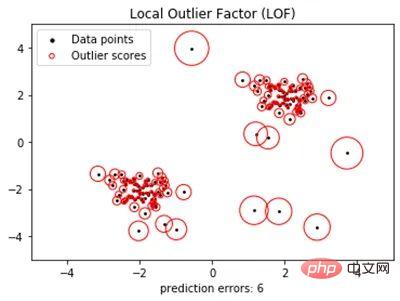
Abbildung 2: Local Outlier Factor (LOF) verwendet die lokale Dichteabweichung jedes Datenpunkts, um einen Anomaliewert zu berechnen, der normale Datenpunkte von Ausreißern unterscheidet.
Hier sind einige Anwendungsfälle für die Anomalieerkennung:
- Vorausschauende Wartung: Die meisten Industrieanlagen sind auf Langlebigkeit und minimale Ausfallzeiten ausgelegt. Daher sind die verfügbaren historischen Daten oft begrenzt. Da unbeaufsichtigtes ML selbst in begrenzten Datensätzen anomales Verhalten erkennen kann, kann es in diesen Fällen möglicherweise Entwicklungsdefizite identifizieren. Auch hier kann es für das Flottenmanagement eingesetzt werden, um frühzeitig vor Mängeln zu warnen und gleichzeitig die Menge der zu überprüfenden Daten zu minimieren.
- Qualitätssicherung/Inspektion: Unsachgemäß betriebene Maschinen können minderwertige Produkte produzieren. Unüberwachtes maschinelles Lernen kann zur Überwachung von Funktionen und Prozessen eingesetzt werden, um etwaige Anomalien zu erkennen. Im Gegensatz zu Standard-QS-Prozessen ist dies ohne Kennzeichnung und Schulung möglich.
- Erkennung von Bildanomalien: Dies ist besonders nützlich in der medizinischen Bildgebung, um gefährliche Pathologien zu identifizieren.
- Cybersicherheit: Eine der größten Herausforderungen in der Cybersicherheit besteht darin, dass sich Bedrohungen ständig ändern. In diesem Fall kann die Anomalieerkennung durch unbeaufsichtigtes ML sehr effektiv sein. Eine Standard-Sicherheitstechnik ist die Überwachung des Datenflusses. Wenn eine SPS, die normalerweise Befehle an andere Komponenten sendet, plötzlich einen stetigen Strom von Befehlen von atypischen Geräten oder IP-Adressen empfängt, könnte dies auf einen Einbruch hinweisen. Was aber, wenn der Schadcode von einer vertrauenswürdigen Quelle stammt (oder ein Angreifer eine vertrauenswürdige Quelle fälscht)? Unüberwachtes Lernen kann böswillige Akteure erkennen, indem es nach atypischem Verhalten in Geräten sucht, die Befehle empfangen.
- Testdatenanalyse: Tests spielen sowohl im Design als auch in der Produktion eine entscheidende Rolle. Die beiden größten Herausforderungen sind das schiere Datenvolumen und die Fähigkeit, die Daten ohne inhärente Verzerrungen zu analysieren. Unüberwachtes maschinelles Lernen kann beide Herausforderungen lösen. Dies kann während des Entwicklungsprozesses oder der Fehlerbehebung in der Produktion von besonderem Vorteil sein, wenn das Testteam nicht einmal sicher ist, wonach es sucht.
Dimensionalitätsreduktion
Maschinelles Lernen basiert auf großen Datenmengen, oft sehr großen Mengen. Es ist eine Sache, einen Datensatz mit zehn bis Dutzenden Funktionen zu filtern. Datensätze mit Tausenden von Funktionen (und es gibt sie sicherlich) können überwältigend sein. Daher kann der erste Schritt bei ML die Reduzierung der Dimensionalität sein, um die Daten auf die aussagekräftigsten Merkmale zu reduzieren.
Ein gängiger Algorithmus zur Dimensionsreduzierung, Mustererkennung und Datenexploration ist die Hauptkomponentenanalyse (PCA). Eine detaillierte Diskussion dieses Algorithmus würde den Rahmen dieses Artikels sprengen. Es kann wohl dabei helfen, zueinander orthogonale Datenteilmengen zu identifizieren, d. h. sie können aus dem Datensatz entfernt werden, ohne die Hauptanalyse zu beeinträchtigen. PCA hat mehrere interessante Anwendungsfälle:
- Datenvorverarbeitung: Wenn es um maschinelles Lernen geht, lautet die oft geäußerte Philosophie, dass mehr besser ist. Allerdings ist manchmal mehr mehr, insbesondere bei irrelevanten/redundanten Daten. In diesen Fällen kann unbeaufsichtigtes maschinelles Lernen eingesetzt werden, um unnötige Merkmale (Datendimensionen) zu entfernen, die Verarbeitungszeit zu beschleunigen und die Ergebnisse zu verbessern. Bei visuellen Systemen kann unüberwachtes maschinelles Lernen zur Rauschreduzierung eingesetzt werden.
- Bildkomprimierung: PCA ist sehr gut darin, die Dimensionalität eines Datensatzes zu reduzieren und gleichzeitig aussagekräftige Informationen beizubehalten. Dadurch eignet sich der Algorithmus sehr gut für die Bildkomprimierung.
- Mustererkennung: Dieselben oben besprochenen Funktionen machen PCA für Aufgaben wie Gesichtserkennung und andere komplexe Bilderkennung nützlich.
Unüberwachtes maschinelles Lernen ist nicht besser oder schlechter als überwachtes maschinelles Lernen. Für das richtige Projekt kann es sehr effektiv sein. Die beste Faustregel ist jedoch, es einfach zu halten, sodass unbeaufsichtigtes maschinelles Lernen im Allgemeinen nur bei Problemen eingesetzt wird, die durch überwachtes maschinelles Lernen nicht gelöst werden können.
Denken Sie über die folgenden Fragen nach, um herauszufinden, welcher maschinelle Lernansatz für Ihr Projekt am besten geeignet ist:
- Was ist das Problem?
- Was ist ein Business Case? Was ist das Ziel der Quantifizierung? Wie schnell wird sich das Projekt amortisieren? Wie ist dies im Vergleich zu überwachtem Lernen oder anderen traditionelleren Lösungen?
- Welche Arten von Eingabedaten sind verfügbar? Wie viele hast du? Ist es relevant für die Frage, die Sie beantworten möchten? Gibt es einen Prozess, der bereits gekennzeichnete Daten erzeugt, gibt es beispielsweise einen QS-Prozess, der fehlerhafte Produkte identifiziert? Gibt es eine Wartungsdatenbank, die Geräteausfälle aufzeichnet?
- Ist es für unbeaufsichtigtes maschinelles Lernen geeignet?
Abschließend noch ein paar Tipps für den Erfolg:
- Machen Sie Ihre Hausaufgaben und entwickeln Sie eine Strategie, bevor Sie ein Projekt starten.
- Fangen Sie klein an und beheben Sie Fehler in kleinerem Maßstab.
- Stellen Sie sicher, dass die Lösung skalierbar ist, Sie möchten nicht im Fegefeuer des Pilotprojekts landen.
- Erwägen Sie die Zusammenarbeit mit einem Partner. Alle Arten des maschinellen Lernens erfordern Fachwissen. Finden Sie die richtigen Tools und Partner für die Automatisierung. Erfinden Sie das Rad nicht neu. Sie können dafür bezahlen, dass Sie die erforderlichen Fähigkeiten intern aufbauen, oder Sie können Ihre Ressourcen auf die Bereitstellung der Produkte und Dienstleistungen konzentrieren, die Sie am besten können, während Sie Ihren Partnern und Ihrem Ökosystem die schwere Arbeit überlassen.
In industriellen Umgebungen gesammelte Daten können eine wertvolle Ressource sein, aber nur, wenn sie angemessen genutzt werden. Unüberwachtes maschinelles Lernen kann ein leistungsstarkes Werkzeug zur Analyse von Datensätzen sein, um umsetzbare Erkenntnisse zu gewinnen. Die Einführung dieser Technologie kann eine Herausforderung sein, aber sie kann in einer anspruchsvollen Welt einen erheblichen Wettbewerbsvorteil verschaffen.
Das obige ist der detaillierte Inhalt vonWie kann unüberwachtes maschinelles Lernen der industriellen Automatisierung zugute kommen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr