
Heim >Technologie-Peripheriegeräte >KI >Der Apple Core führt auch große Modelle aus, ohne die Berechnungsgenauigkeit zu beeinträchtigen. GPT-4 wird ebenfalls verwendet.
Der Apple Core führt auch große Modelle aus, ohne die Berechnungsgenauigkeit zu beeinträchtigen. GPT-4 wird ebenfalls verwendet.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-09-08 11:25:08867Durchsuche
Sobald Code Llama herauskam, erwarteten alle, dass jemand das quantitative Abnehmen fortsetzt.
Wie erwartet war es Georgi Gerganov, der Autor von llama.cpp, der Maßnahmen ergriff, aber dieses Mal tat er es Befolgen Sie die Routine nicht:
Nicht weiter Quantisiert, der 34B-Code von Code LLama kann auf Apple-Computern sogar mit FP16-Präzision ausgeführt werden, und die Inferenzgeschwindigkeit übersteigt 20 Token pro Sekunde
 Bilder
Bilder
Verwenden Sie jetzt einfach eine Bandbreite von 800 GB/s M2 Ultra kann Aufgaben erledigen, für die ursprünglich 4 High-End-GPUs erforderlich waren, und die Geschwindigkeit beim Schreiben von Code ist ebenfalls sehr hoch. Der alte Mann hat dann das Geheimnis gelüftet. Die Antwort ist sehr einfach: spekulatives Sampling/Dekodierung Bilder
erregten die Aufmerksamkeit vieler Branchenriesen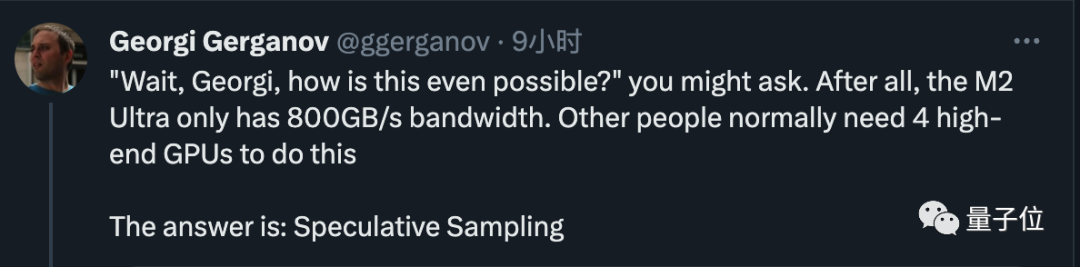 OpenAI-Gründungsmitglied Andrej Karpathy kommentierte, dass dies eine sehr hervorragende Inferenzzeitoptimierung sei und gab weitere technische Erklärungen. Fan Linxi, ein Nvidia-Wissenschaftler, glaubt auch, dass dies eine Technik ist, mit der jeder, der an großen Modellen arbeitet, vertraut sein sollte Es ist nicht auf diejenigen beschränkt, die große Modelle lokal ausführen, sondern auch Supergiganten wie Google und OpenAI nutzen diese Technologie leisten, so viel Geld zu verbrennen.
OpenAI-Gründungsmitglied Andrej Karpathy kommentierte, dass dies eine sehr hervorragende Inferenzzeitoptimierung sei und gab weitere technische Erklärungen. Fan Linxi, ein Nvidia-Wissenschaftler, glaubt auch, dass dies eine Technik ist, mit der jeder, der an großen Modellen arbeitet, vertraut sein sollte Es ist nicht auf diejenigen beschränkt, die große Modelle lokal ausführen, sondern auch Supergiganten wie Google und OpenAI nutzen diese Technologie leisten, so viel Geld zu verbrennen.
Bilder
Die neuesten Nachrichten deuten darauf hin, dass wahrscheinlich das von Google DeepMind gemeinsam entwickelte Großmodell Gemini der nächsten Generation zum Einsatz kommen wird.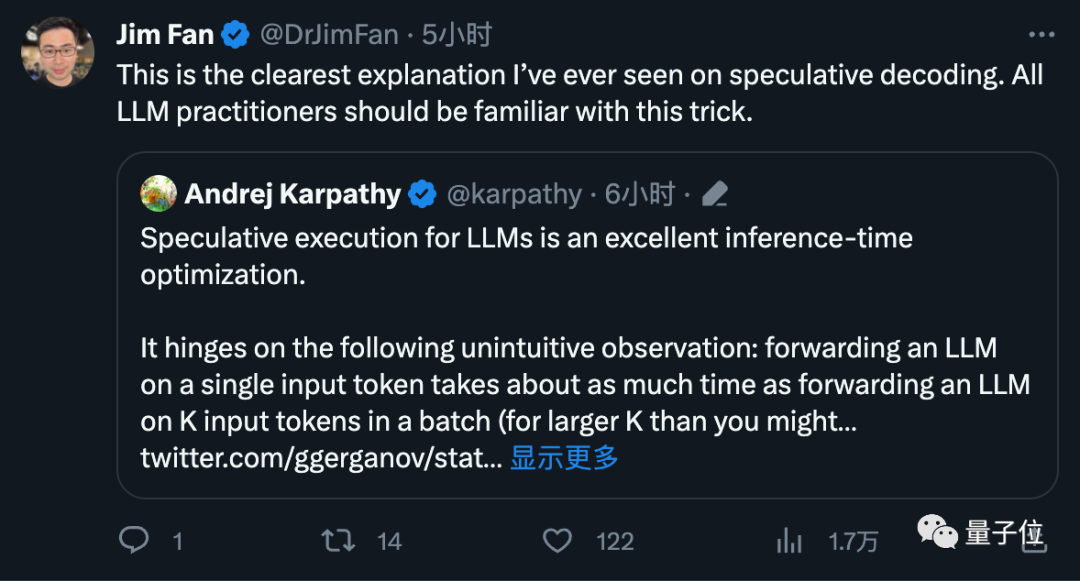 Obwohl die spezifische Methode von OpenAI vertraulich ist, hat das Google-Team ein entsprechendes Papier veröffentlicht und das Papier wurde für den mündlichen Bericht des ICML 2023 ausgewählt
Obwohl die spezifische Methode von OpenAI vertraulich ist, hat das Google-Team ein entsprechendes Papier veröffentlicht und das Papier wurde für den mündlichen Bericht des ICML 2023 ausgewählt
Bilder
Die Methode ist einfach: Trainieren Sie zunächst ein Modell dafür ist dem großen Modell ähnlich und billiger. Lassen Sie beim kleinen Modell zuerst das kleine Modell K-Token generieren und dann das große Modell die Beurteilung vornehmen. Das große Modell kann die akzeptierten Teile direkt verwenden und die nicht akzeptierten Teile durch das große Modell ändern. In der ursprünglichen Forschung wurde das T5-XXL-Modell zur Demonstration verwendet, und während die generierten Ergebnisse unverändert blieben, wurde das
In der ursprünglichen Forschung wurde das T5-XXL-Modell zur Demonstration verwendet, und während die generierten Ergebnisse unverändert blieben, wurde das
Bild
Andjrey Karpathy vergleicht diese Methode damit, „das kleine Modell zuerst entwerfen zu lassen“. Er erklärte, dass der Schlüssel zur Wirksamkeit dieser Methode darin besteht, dass bei der Eingabe eines großen Modells in einen Token und einen Stapel von Token die Zeit, die zur Vorhersage des nächsten Tokens erforderlich ist, nahezu gleich istJeder Token hängt vom vorherigen ab Token, daher ist es unter normalen Umständen unmöglich, mehrere Token gleichzeitig abzutasten.
Er erklärte, dass der Schlüssel zur Wirksamkeit dieser Methode darin besteht, dass bei der Eingabe eines großen Modells in einen Token und einen Stapel von Token die Zeit, die zur Vorhersage des nächsten Tokens erforderlich ist, nahezu gleich istJeder Token hängt vom vorherigen ab Token, daher ist es unter normalen Umständen unmöglich, mehrere Token gleichzeitig abzutasten.
Obwohl das kleine Modell über geringe Fähigkeiten verfügt, sind viele Teile bei der tatsächlichen Generierung eines Satzes sehr einfach, und das kleine Modell kann die Aufgabe auch erfüllen. Lassen Sie das große Modell nur bei schwierigen Stellen einfach einsteigen.
Das Originalpapier weist darauf hin, dass bestehende ausgereifte Modelle direkt beschleunigt werden können, ohne ihre Struktur zu ändern oder neu zu trainieren.
Ein mathematisches Argument dafür, dass die Genauigkeit nicht verringert wird, wird auch im Anhang des Papiers angegeben.
 Bilder
Bilder
Da wir nun das Prinzip verstanden haben, schauen wir uns dieses Mal die spezifischen Einstellungen von Georgi Gerganov an.
Er verwendet ein 4-Bit-quantisiertes 7B-Modell als „Entwurfs“-Modell, das etwa 80 Token pro Sekunde generieren kann.
Bei alleiniger Verwendung kann das 34B-Modell mit FP16-Präzision nur 10 Token pro Sekunde erzeugen
Nach Verwendung der spekulativen Abtastmethode haben wir einen 2-fachen Beschleunigungseffekt erhalten, der mit den Daten im Originalpapier übereinstimmt
Bild
Abschließend schlug er Meta auch vor, kleine Entwurfsmodelle direkt in die künftige Veröffentlichung von Modellen einzubeziehen, was von allen gut angenommen wurde. Georgi Gerganov ist der Autor. Er hat im März dieses Jahres die erste Generation von LlaMA auf C++ portiert. Sein Open-Source-Projekt llama.cpp hat fast 40.000 Sterne erhalten Er betrachtete dies zunächst nur als Nebenhobby, doch aufgrund der überwältigenden Resonanz kündigte er im Juni sein Startup neue Firma ggml an. ai widmet sich der Ausführung von KI auf Edge-Geräten. Das Flaggschiffprodukt des Unternehmens ist das Framework für maschinelles Lernen in C-Sprache hinter llama.cpp Investition Er war auch nach der Veröffentlichung von LlaMA2 sehr aktiv. Das Rücksichtsloseste war, ein großes Modell direkt in den Browser zu stopfen. Bitte schauen Sie sich Googles spekulatives Stichprobenpapier an: https://arxiv.org/abs/2211.17192 Referenzlink: [1] https://x.com/ggerganov/status/1697262700165013689 [2 ]https://x.com/karpathy/status/1697318534555336961 Er gab außerdem an, dass die Geschwindigkeit je nach generiertem Inhalt variieren kann, aber bei der Codegenerierung sehr effektiv ist und das Entwurfsmodell die meisten Token richtig erraten kann.
Er gab außerdem an, dass die Geschwindigkeit je nach generiertem Inhalt variieren kann, aber bei der Codegenerierung sehr effektiv ist und das Entwurfsmodell die meisten Token richtig erraten kann. 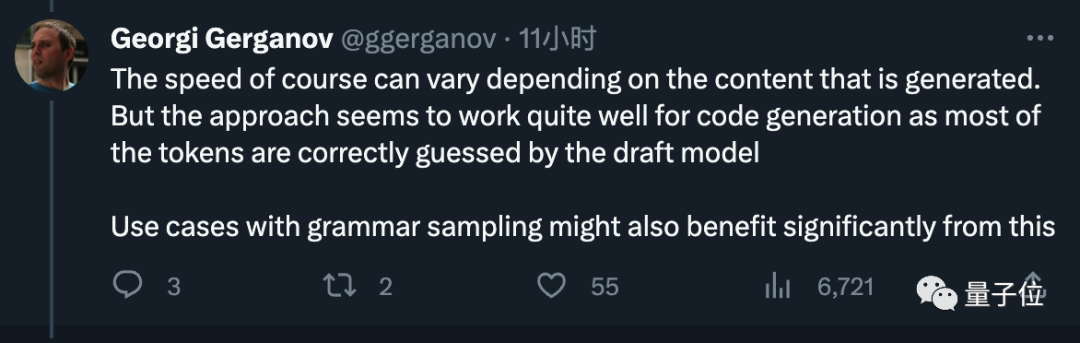 Bilder
Bilder Bilder
BilderDer Autor hat ein Unternehmen gegründet
 Bilder
Bilder
Das obige ist der detaillierte Inhalt vonDer Apple Core führt auch große Modelle aus, ohne die Berechnungsgenauigkeit zu beeinträchtigen. GPT-4 wird ebenfalls verwendet.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Switch-Fehlercode 2110-2003
- Wie groß ist die Akkukapazität des Apple X?
- Wie viele iPhones können mit einer ID genutzt werden?
- ChatGPT hat plötzlich die APP gestartet! iPhone ist verfügbar und schneller, GPT-4-Nutzungslimit soll vermutlich aufgehoben werden
- „Social Master' GPT-4! Wissen, wie man Ausdrücke interpretiert und über Psychologie spekuliert