
Heim >Technologie-Peripheriegeräte >KI >Offenes Verständnis von 3D-Punktwolken, Klassifizierung, Abruf, Untertiteln und Bildgenerierung
Offenes Verständnis von 3D-Punktwolken, Klassifizierung, Abruf, Untertiteln und Bildgenerierung

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-04 15:04:041551Durchsuche
Geben Sie die dreidimensionale Form eines Schaukelstuhls und eines Pferdes ein. Was können Sie bekommen?


Holzkarren plus Pferd? Eine Kutsche und ein Elektropferd besorgen; eine Banane und ein Segelboot? Ein Bananensegelboot kaufen; Eier plus Liegestühle? Holen Sie sich den Eierstuhl.
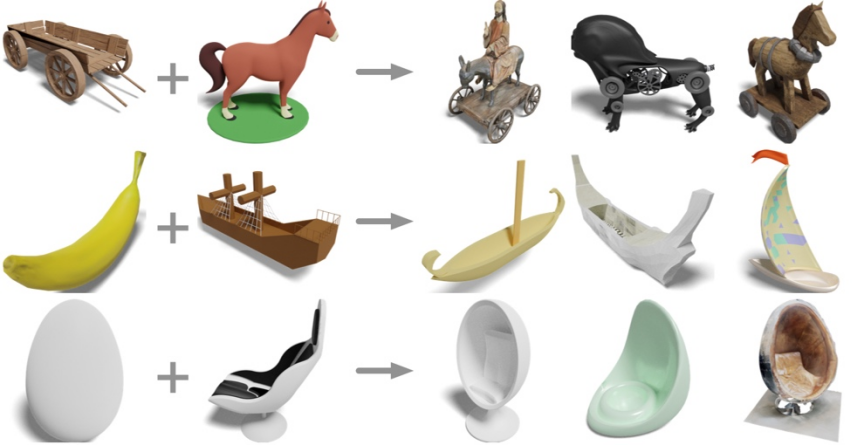
Forscher der UCSD, der Shanghai Jiao Tong University und Qualcomm-Teams schlugen das neueste dreidimensionale Darstellungsmodell OpenShape vor Dadurch können dreidimensionale Formen dargestellt werden. Das Verständnis einer offenen Welt wird möglich.
- Papieradresse: https://arxiv.org /pdf/2305.10764.pdf
- Projekthomepage: https ://colin97.github.io/OpenShape/
- Interaktive Demo: https://huggingface.co/spaces/OpenShape/openshape-demo
- Codeadresse: https://github.com/Colin97/OpenShape_code
By in more OpenShape ist ein nativer Encoder, der 3D-Punktwolken anhand modaler Daten (Punktwolke – Text – Bild) lernt. Er erstellt einen 3D-Formdarstellungsraum und richtet ihn an den Text- und Bildräumen von CLIP aus. Dank umfangreicher und vielfältiger 3D-Vorschulung erreicht OpenShape erstmals ein offenes Verständnis von 3D-Formen und unterstützt die Zero-Shot-3D-Formklassifizierung, den multimodalen 3D-Formabruf (Text-/Bild-/Punktwolkeneingabe) und und Untertitel von 3D-Punktwolken. Cross-modale Aufgaben wie Bildgenerierung und 3D-Punktwolken-basierte Bildgenerierung.
Dreidimensionale Form-Zero-Shot-Klassifizierung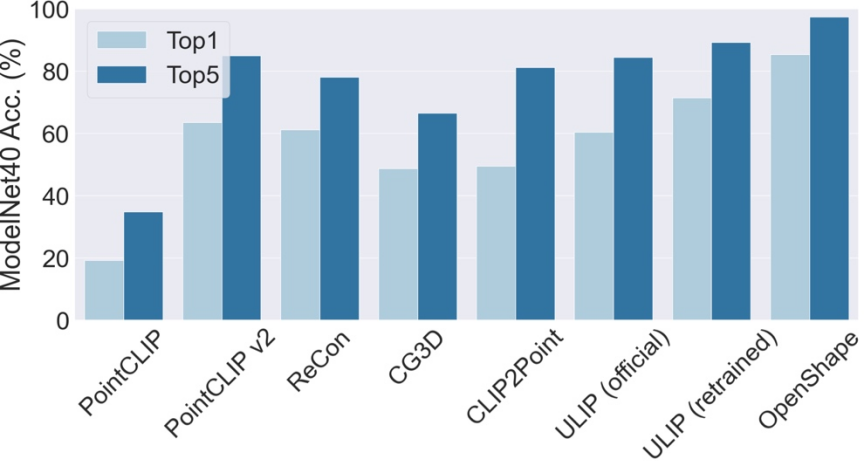
Die Top3- und Top5-Genauigkeit von OpenShape auf ModelNet40 erreichte 96,5 % bzw. 98,0 %. Im Gegensatz zu bestehenden Methoden, die hauptsächlich auf einige gängige Objektkategorien beschränkt sind, ist OpenShape in der Lage, eine breite Palette von Open-World-Kategorien zu kategorisieren. Beim Objaverse-LVIS-Benchmark (der 1156 Objektkategorien umfasst) erreicht OpenShape eine Top1-Genauigkeit von 46,8 % und übertrifft damit die höchste Genauigkeit von nur 6,2 % der bestehenden Zero-Shot-Methoden bei weitem. Diese Ergebnisse zeigen, dass OpenShape in der Lage ist, 3D-Formen in der offenen Welt effektiv zu erkennen.
Multimodaler 3D-Formabruf
Mit der multimodalen Darstellung von OpenShape können Benutzer den 3D-Abruf von Bild-, Text- oder Punktwolkeneingaben durchführen. Formabruf. Untersuchen Sie den Abruf von 3D-Formen aus integrierten Datensätzen, indem Sie die Kosinusähnlichkeit zwischen der Eingabedarstellung und der 3D-Formdarstellung berechnen und kNN ermitteln. #🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜##Bildeingabe Dreidimensionale Formsuche 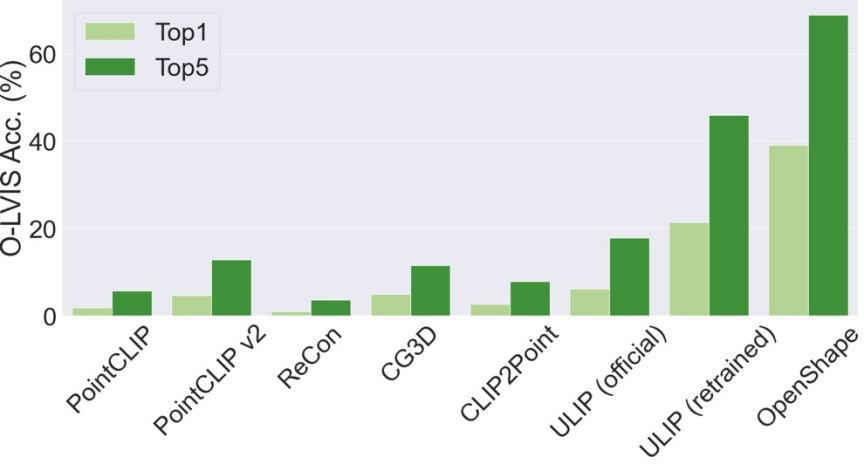
Das obige Bild zeigt das Eingabebild und zwei abgerufene 3D-Formen.

Dreidimensionaler Formabruf für die Texteingabe
Die obige Abbildung zeigt den Eingabetext und die abgerufene dreidimensionale Form. OpenShape lernt eine breite Palette visueller und semantischer Konzepte und ermöglicht so eine feinkörnige Unterkategorie- (erste zwei Zeilen) und Attributsteuerung (letzte zwei Zeilen, wie z. B. Farbe, Form, Stil und deren Kombinationen).

3D-Formabruf aus der 3D-Punktwolkeneingabe
Die obige Abbildung zeigt die eingegebene 3D-Punktwolke und zwei abgerufene 3D-Formen.

3D-Formabruf mit zwei Eingaben
Das obige Bild verwendet zwei 3D-Formen als Eingabe und verwendet deren OpenShape-Darstellung, um die drei gleichzeitig abzurufen, die beiden Eingaben am nächsten kommen - dimensionale Form. Die abgerufene Form kombiniert geschickt semantische und geometrische Elemente aus beiden Eingabeformen.
Text- und Bildgenerierung basierend auf 3D-Formen
Da die 3D-Formdarstellung von OpenShape auf den Bild- und Textdarstellungsraum von CLIP ausgerichtet ist, können sie mit vielen CLIP-basierten abgeleiteten Modellen kombiniert werden, um eine Vielzahl von modalübergreifenden Anwendungen zu unterstützen.

Untertitelgenerierung für 3D-Punktwolken
Durch die Kombination mit dem vorgefertigten Bilduntertitelmodell (ClipCap) implementiert OpenShape die Untertitelgenerierung für 3D-Punktwolken.

Bildgenerierung basierend auf 3D-Punktwolken
Durch die Kombination mit dem vorgefertigten Text-zu-Bild-Diffusionsmodell (Stable unCLIP) implementiert OpenShape die Bildgenerierung basierend auf 3D-Punktwolken (unterstützte optionale Textaufforderung).
... 3D Ein nativer Encoder, der dauert eine 3D-Punktwolke als Eingabe, um eine Darstellung der 3D-Form zu extrahieren. Im Anschluss an frühere Arbeiten nutzen wir multimodales kontrastives Lernen, um uns an den Bild- und Textdarstellungsräumen von CLIP auszurichten. Im Gegensatz zu früheren Arbeiten zielt OpenShape darauf ab, einen allgemeineren und skalierbareren gemeinsamen Darstellungsraum zu erlernen. Der Schwerpunkt der Forschung liegt hauptsächlich darauf, den Umfang des 3D-Darstellungslernens zu erweitern und die entsprechenden Herausforderungen anzugehen, um das 3D-Formverständnis in der offenen Welt wirklich zu verwirklichen.

Integration mehrerer 3D-Formdatensätze: Da der Umfang und die Vielfalt der Trainingsdaten eine entscheidende Rolle beim Erlernen großräumiger 3D-Formdarstellungen spielen, wurde die Forschung durch die Integration von vier der derzeit größten öffentlichen 3D-Formdatensätze durchgeführt. Wie in der folgenden Abbildung dargestellt, enthalten die untersuchten Trainingsdaten 876.000 Trainingsformen. Unter den vier Datensätzen enthalten ShapeNetCore, 3D-FUTURE und ABO hochwertige, vom Menschen verifizierte 3D-Formen, decken jedoch nur eine begrenzte Anzahl von Formen und Dutzende Kategorien ab. Der Objaverse-Datensatz ist ein kürzlich veröffentlichter 3D-Datensatz, der deutlich mehr 3D-Formen enthält und eine vielfältigere Objektklasse abdeckt. Allerdings werden die Formen in Objaverse hauptsächlich von Online-Benutzern hochgeladen und nicht manuell überprüft. Daher ist die Qualität ungleichmäßig und die Verteilung äußerst unausgewogen, was eine weitere Verarbeitung erfordert.

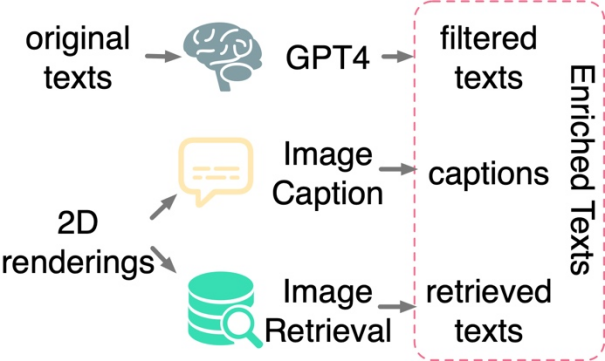
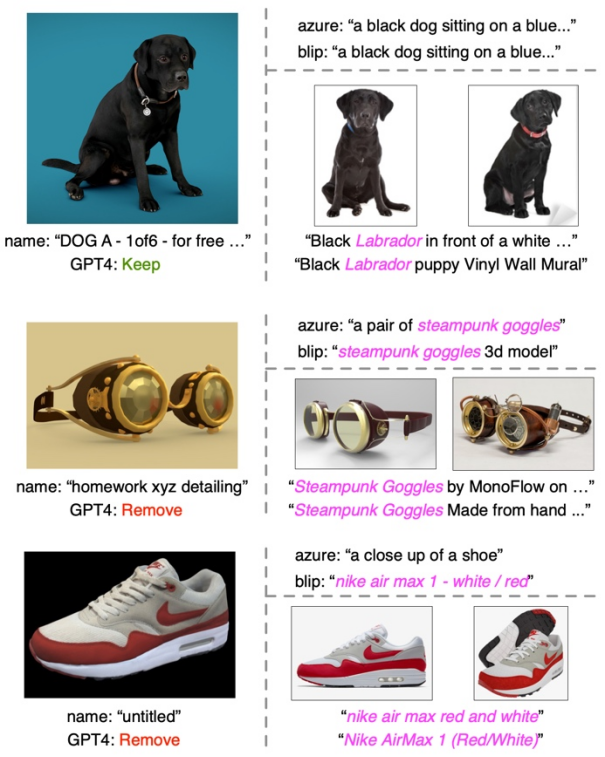
Textfilterung und -anreicherung: Studie ergab, dass die Anwendung von kontrastivem Lernen nur zwischen 3D-Formen und 2D-Bildern nicht ausreicht, um die Ausrichtung von 3D-Formen und Texträumen voranzutreiben, selbst wenn dies an großen Datensätzen durchgeführt wird Das Gleiche gilt für das Training. Untersuchungen gehen davon aus, dass dies auf die inhärente Domänenlücke in den Sprach- und Bilddarstellungsräumen von CLIP zurückzuführen ist. Daher muss die Forschung 3D-Formen explizit am Text ausrichten. Bei Textanmerkungen aus Original-3D-Datensätzen treten jedoch häufig Probleme wie fehlende, falsche oder grobe und einzelne Inhalte auf. Zu diesem Zweck schlägt dieses Papier drei Strategien zum Filtern und Anreichern von Text vor, um die Qualität von Textanmerkungen zu verbessern: Textfilterung mit GPT-4, Untertitelgenerierung und Bildabruf von 2D-Renderings von 3D-Modellen. Die Studie schlägt drei Strategien vor, um verrauschten Text in Originaldatensätzen automatisch zu filtern und anzureichern. ?? Im oberen rechten Teil werden die Bildunterschriften der beiden Untertitelungsmodelle angezeigt, während im unteren rechten Teil die abgerufenen Bilder und der entsprechende Text angezeigt werden.
Da frühere Arbeiten zum Lernen von 3D-Punktwolken hauptsächlich auf kleine 3D-Datensätze wie ShapeNet abzielten, sind diese Backbone-Netzwerke möglicherweise nicht direkt auf unser groß angelegtes 3D-Training anwendbar und der Umfang des Backbone-Netzwerks muss entsprechend erweitert werden. Die Studie ergab, dass verschiedene 3D-Backbone-Netzwerke unterschiedliche Verhaltensweisen und Skalierbarkeit aufweisen, wenn sie mit Datensätzen unterschiedlicher Größe trainiert werden. Unter diesen weisen PointBERT basierend auf Transformer und SparseConv basierend auf dreidimensionaler Faltung eine leistungsfähigere Leistung und Skalierbarkeit auf und wurden daher als dreidimensionales Backbone-Netzwerk ausgewählt.
Vergleich der Leistung und Skalierbarkeit verschiedener Backbone-Netzwerke beim Skalieren der Größe des 3D-Backbone-Modells auf dem integrierten Datensatz.
Hartes Negativbeispiel-Mining: Der Ensemble-Datensatz dieser Studie weist ein hohes Maß an Klassenungleichgewicht auf. Einige gängige Kategorien wie Architektur können Zehntausende Formen umfassen, während viele andere Kategorien wie Walrosse und Geldbörsen mit nur ein paar Dutzend oder sogar weniger Formen unterrepräsentiert sind. Wenn für kontrastives Lernen Stapel zufällig erstellt werden, ist es daher unwahrscheinlich, dass Formen aus zwei leicht zu verwechselnden Kategorien (z. B. Äpfel und Kirschen) im selben Stapel erscheinen, um kontrastiert zu werden. Zu diesem Zweck schlägt dieses Papier eine Offline-Strategie zum Mining schwieriger Negativbeispiele vor, um die Trainingseffizienz und -leistung zu verbessern. Willkommen, die interaktive Demo auf HuggingFace auszuprobieren.
Das obige ist der detaillierte Inhalt vonOffenes Verständnis von 3D-Punktwolken, Klassifizierung, Abruf, Untertiteln und Bildgenerierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr