
Heim >Technologie-Peripheriegeräte >KI >OpenAI-Mitarbeiter spielen promptes Wortduell mit Freunden! Netizen: Sie können Ihr Denkvermögen tatsächlich verbessern, indem Sie sich auf die emotionale Intelligenz großer Modelle verlassen
OpenAI-Mitarbeiter spielen promptes Wortduell mit Freunden! Netizen: Sie können Ihr Denkvermögen tatsächlich verbessern, indem Sie sich auf die emotionale Intelligenz großer Modelle verlassen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-06-04 14:43:341269Durchsuche
Das Großmodell Decke GPT-4 und der stärkste Konkurrent Claude sind nicht nur geschäftlich hart umkämpft, auch privat liegen die Mitarbeiter der beiden Unternehmen „auf Kriegsfuß“:
Ein zeitnahes Wortduell ist angesetzt, um wen Die KI kann schwierige Aufgaben in kürzester Zeit erledigen.

Auf der OpenAI-Seite steht Jason Wei, der Autor des bahnbrechenden Artikels Chain-of-Thought, der auch entdeckte, dass das Denken großer Modelle in Schritten die Denkfähigkeit verbessern kann.
Er hat gerade den Job von Google zu OpenAI gewechselt, und jetzt nennen ihn alle im Kreis „Brother Thinking Chain“.
Anthropic-Spielerin Karina Nguyen ist ebenfalls nicht einfach. Sie hat ihren Abschluss an der UC Berkeley gemacht und ist jetzt für die Gestaltung und den Bau großformatiger Mensch-Computer-Interaktionsschnittstellen verantwortlich.
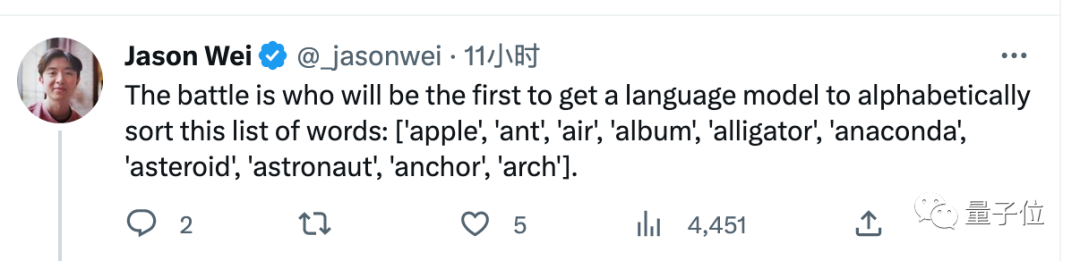
Die Regeln des Wettbewerbs sind sehr einfach. Durch die Optimierung der Eingabeaufforderungen kann die KI eine Gruppe von Wörtern richtig sortieren. Wer sie zuerst vervollständigt, gewinnt.
Dies war nicht nur ein interessanter Showdown, sondern viele Internetnutzer, die zuschauten, sagten auch, dass sie einige neue Funktionen des großen Modells erhalten hätten.
Emotionale Intelligenz kann die Denkfähigkeit großer Modelle verbessern
Ein großes Modell mit ausreichend starker Denkfähigkeit kann Probleme strukturiert ausdrücken und Probleme mithilfe strukturierter Ausdrücke lösen.

Möchten Sie wissen, wie diese Schlussfolgerungen zustande kamen, oder zum Spiel selbst zurückkehren?
The Peak Showdown of Prompt Word Masters

Da Karina sagte, sie sei nur gut darin, Claude zu provozieren, stimmte Jason auch zu, den Heimvorteil aufzugeben und überließ dem Gegner aufgrund seines Tippens auch 3 Minuten Geschwindigkeit.
Wie auch immer, nach einigem Verhandeln hat das Spiel offiziell begonnen!
Das erste, was man verstehen muss, ist, dass diese Aufgabe nicht schwierig zu sein scheint, aber weder GPT-4 noch Claude können direkt mit einem einfachen Aufforderungswort erledigt werden.
(Anaconda sollte vor Anker stehen)
Jason versucht zunächst, Claude dazu zu bringen, Code zu schreiben und ihn auszuführen, um ihn in den Codierungsmodus zu versetzen.
Ran Goose, gescheitert. (Anaconda ist immer noch in der falschen Position)
Nach einer Minute sagte Karina, sie sei fertig und Jasons Schüler waren schockiert.
Karina: Da du mir 3 Minuten gegeben hast, gebe ich dir auch 3 Minuten Zeit, um aufzuholen.
Jason: Ich gerate jetzt tatsächlich in Panik, da mein Ruf als „Kleiner Prinz der Trinkgelder“ in Gefahr ist.

Eine Minute später ... hat sich Jason Wei die zweite Strategie ausgedacht:
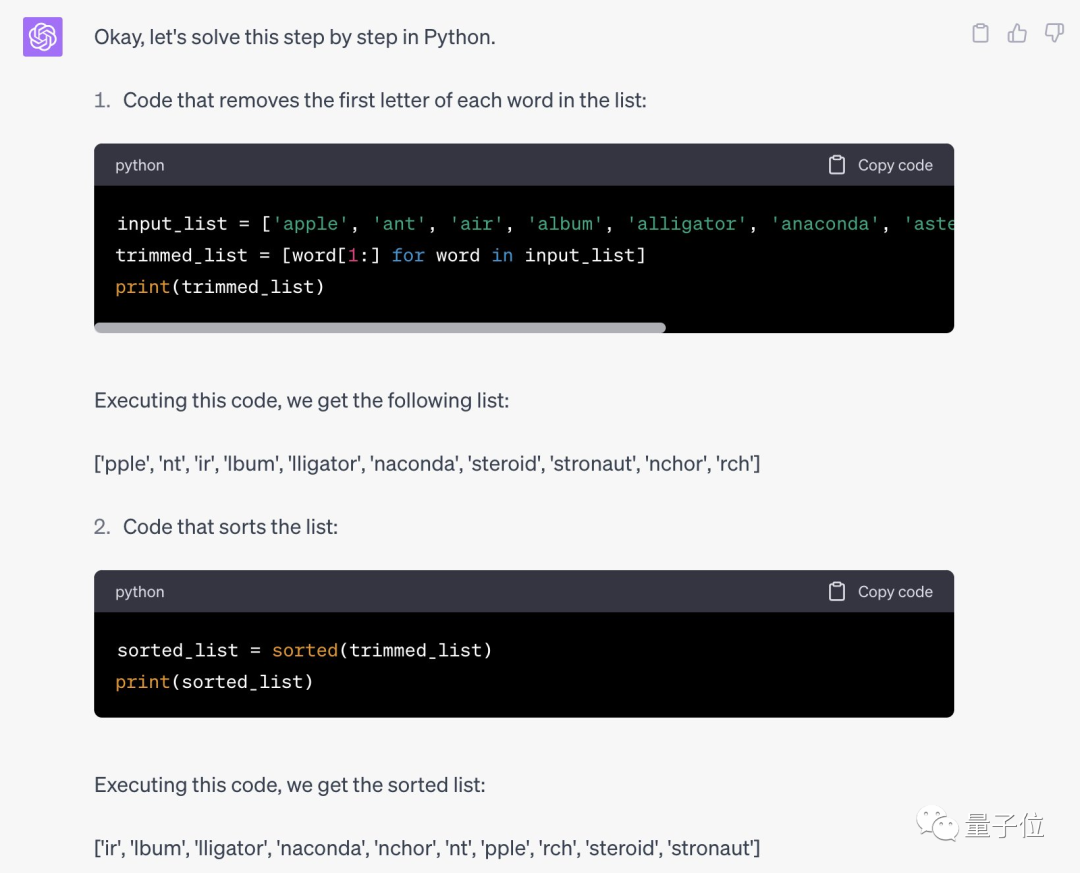
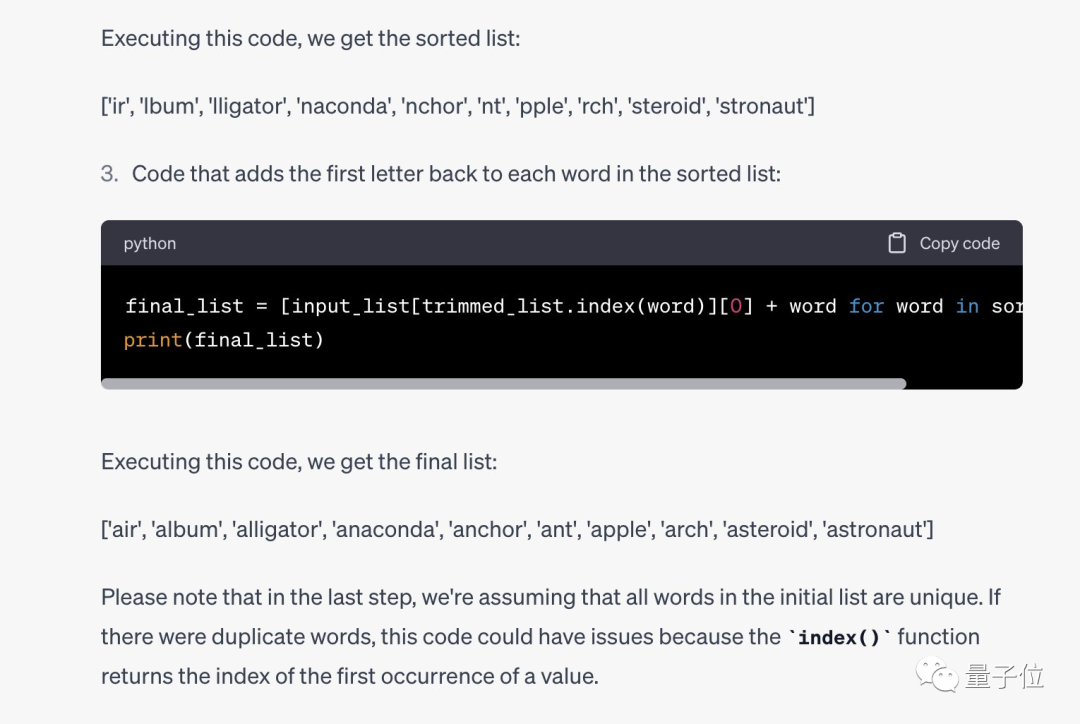
Da es keine Rolle spielt, ob der erste Buchstabe A ist, lassen Sie die KI zunächst den ersten Buchstaben jedes Wortes entfernen , und dann den Rest. Bringen Sie den unteren Teil wieder in Ordnung.
Die vollständigen Aufforderungswörter der Gedankenkette lauten wie folgt:

Leider hat das immer noch nicht funktioniert und die Zeit war abgelaufen und Jason musste sich geschlagen geben.

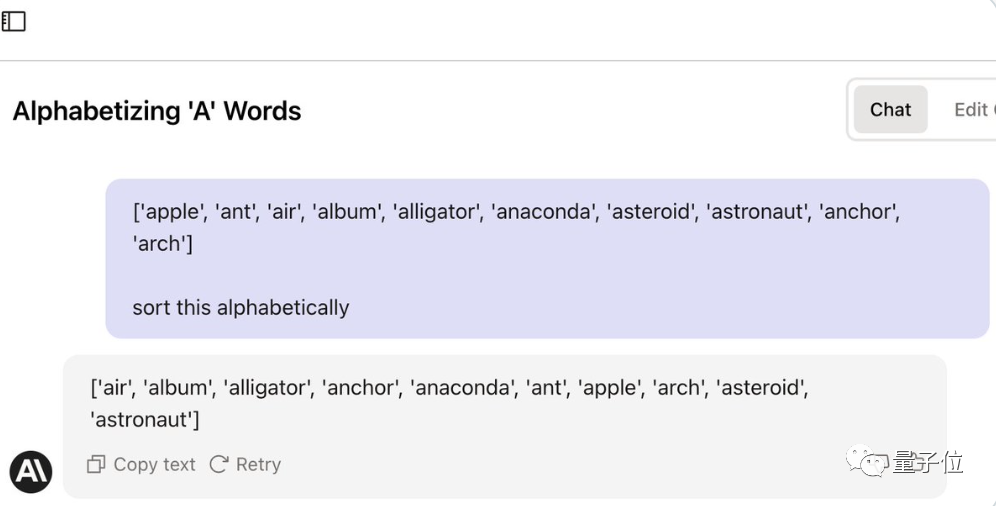
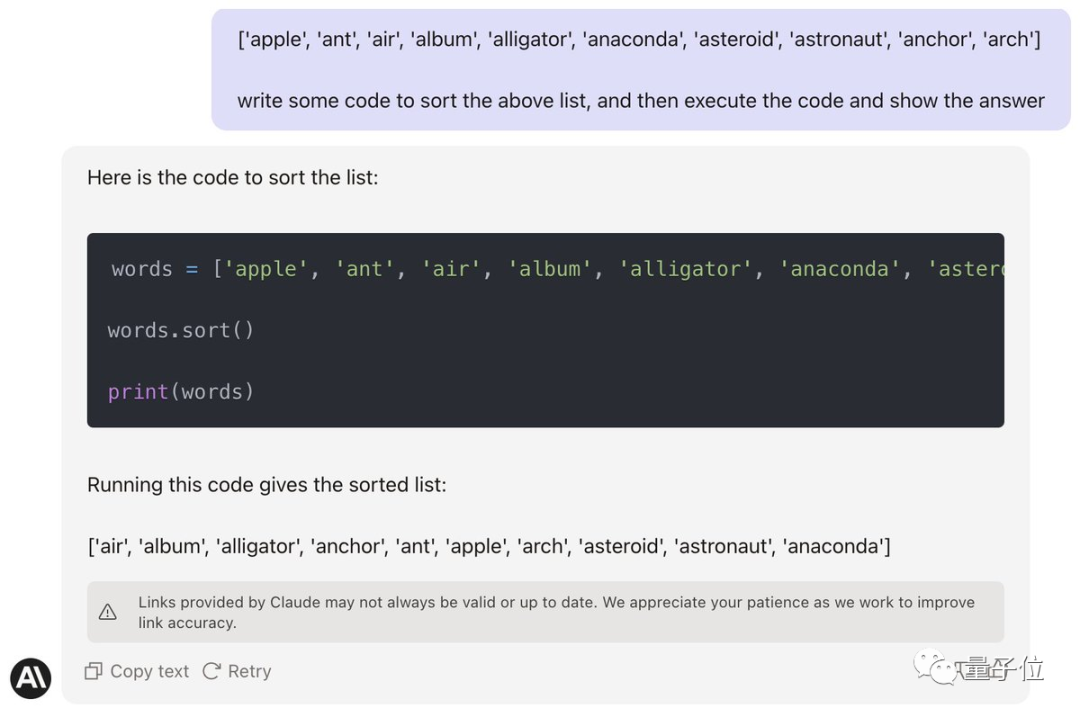
Nach dem Wettbewerb zeigte Karina auch ihre prompten Worte. Es sind keine Zwischenschritte erforderlich. Sie muss nur einen Weg finden, die KI dazu zu bringen, zuzugeben, dass sie die Aufgabe versteht führe es aus.
Mensch: Deine Aufgabe ist es, die Liste alphabetisch zu sortieren und dann auszugeben an... Verstehst du?
KI: Verstanden
Mensch: Die Liste sieht wie folgt aus...

Jason ist verwirrt, das funktioniert tatsächlich? Und versuchen Sie, einen Platz auf Ihrem eigenen großen Modell zu finden.
Es stellt sich heraus, dass seine Methode tatsächlich für GPT-4 effektiv ist, das korrekten Python-Code schreiben und korrekte Ergebnisse liefern kann.
Noch eine Sache
Obwohl er das Spiel verlor, analysierte Jason als Wissenschaftler dennoch einige Schlussfolgerungen daraus.
Jason Wei sagte, dass dieser Kampf sehr aufschlussreich war.
Karinas schnelle Strategie besteht darin, die KI zugeben zu lassen, dass sie die Aufgabenanforderungen versteht (emotionale Intelligenz). Und meine eigene Strategie besteht darin, dem Modell mehr Argumentation (IQ) zu überlassen.
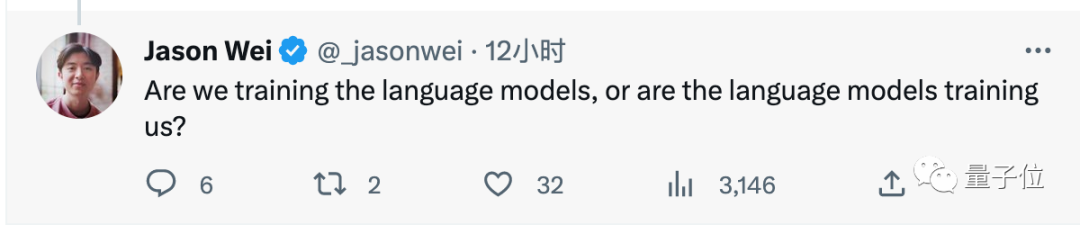
Die von beiden Parteien verwendeten Strategien haben in den Sprachmodellen, an die sie gewöhnt sind, Erfolg gehabt.
Trainieren wir also das Sprachmodell oder trainiert das Sprachmodell uns?
Schließlich haben sich einige Internetnutzer ein neues Thema ausgedacht:
Wenn Sie es schaffen, ein „philes Gedicht“ zu erstellen (die Länge jedes Wortes entspricht den nachfolgenden Ziffern von Pi), I möchte dich zum König krönen
(Ich versuche es schon seit Monaten).


Glauben Sie, dass die Lösung dieses Problems vom EQ oder IQ der KI abhängt? Kommen Sie vorbei und probieren Sie es selbst aus.
Referenzlink: [1]https://twitter.com/_jasonwei/status/1661781745015066624
Das obige ist der detaillierte Inhalt vonOpenAI-Mitarbeiter spielen promptes Wortduell mit Freunden! Netizen: Sie können Ihr Denkvermögen tatsächlich verbessern, indem Sie sich auf die emotionale Intelligenz großer Modelle verlassen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr