
Heim >Technologie-Peripheriegeräte >KI >Erforschung der Möglichkeit, aus einer Reihe von Wörtern ein visuelles Sprachmodell zu erstellen
Erforschung der Möglichkeit, aus einer Reihe von Wörtern ein visuelles Sprachmodell zu erstellen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-21 23:22:041434Durchsuche
Übersetzer |. Zhu Xianzhong
Rezensent |. Chonglou
Aktuell Multimodale künstliche Intelligenz Werden Sie zum Streettalk und heißen Diskussionsthemen. Mit der jüngsten Veröffentlichung von GPT-4 sehen wir unzählige mögliche neue Anwendungen und zukünftige Technologien, die noch vor sechs Monaten undenkbar waren. Tatsächlich sind visuelle Sprachmodelle im Allgemeinen für viele verschiedene Aufgaben nützlich. Sie können beispielsweise CLIP (Contrastive Language-Image Pre-training, , also „Contrastive Language-Image Pre-training“, Link: https://www.php.cn/link verwenden /b02d46e8a3d8d9fd6028f3f2c2495864 Zero-Shot-Bildklassifizierung für unsichtbare Datensätze; Typischerweise kann eine hervorragende Leistung ohne jegliche Schulung erzielt werden
Mittlerweile visuelle Sprachmodelle nicht. Perfekt In diesem Artikel werden wir die Einschränkungen dieser Modelle untersuchen und hervorheben, wo und warum sie versagen können. Tatsächlich dieser Artikel wird eine kurze/hochrangige Beschreibung veröffentlichen des Artikels , der als ICLR 2023 veröffentlicht werden soll. Klicken Sie einfach auf den -Link https://www.php.cn/link/afb992000fcf79ef7a53fffde9c8e044. EinführungWas ist ein visuelles Sprachmodell? Synergie zwischen visuellen und sprachlichen Daten zur Ausführung verschiedener Aufgaben. Während in der vorhandenen -Literatur viele visuelle Sprachmodelle eingeführt wurden, bleibt CLIP ( Contrast Language-Image Pre-training) das bekannteste und Das am weitesten verbreitete Modell.
Durch die Einbettung von Bildern und Bildunterschriften in denselben Vektorraum ermöglicht das CLIP-Modell
Musterschlussfolgerungen und ermöglicht es Benutzern, Aufgaben wie die Zero-Shot-Bildklassifizierung und Text- Das CLIP-Modell verwendet kontrastive Lernmethoden, um das Einbetten von Bildern und Bildunterschriften zu erlernen Bildunterschriften durch Minimierung des Abstands zwischen Bildern in einem gemeinsamen Vektorraum. Die durch das CLIP-Modell und andere kontrastbasierte Modelle erzielten Ergebnisse zeigen, dass dieser Ansatz sehr effektiv ist um Bild- und Titelpaare stapelweise zu vergleichen, und das Modell ist optimiert, um die Bild-Text-Ähnlichkeit zwischen Einbettungspaaren zu maximieren und die Ähnlichkeit zwischen anderen Bild-Text-Paaren im Stapel zu verringern Die folgende Abbildung zeigt ein Beispiel für mögliche Batch- und Trainingsschritte
- Das violette Quadrat enthält die Einbettungen für alle Titel und das grüne Quadrat enthält die Einbettungen für alle Bilder.
- Das Quadrat der Matrix enthält das Skalarprodukt aller Bildeinbettungen und aller Texteinbettungen im Stapel (lesen Sie „Cosinus-Ähnlichkeit“, da die Einbettungen normalisiert sind).
- Das blaue Quadrat enthält das Skalarprodukt zwischen den Bild-Text-Paaren, für die das Modell die Ähnlichkeit maximieren muss, die anderen weißen Quadrate sind die Ähnlichkeiten, die wir minimieren möchten (da jedes dieser Quadrate die Ähnlichkeit der Übereinstimmungen enthält). Bild-Text-Paare, wie zum Beispiel ein Bild einer Katze und eine Beschreibung von „meinem Vintage-Stuhl“
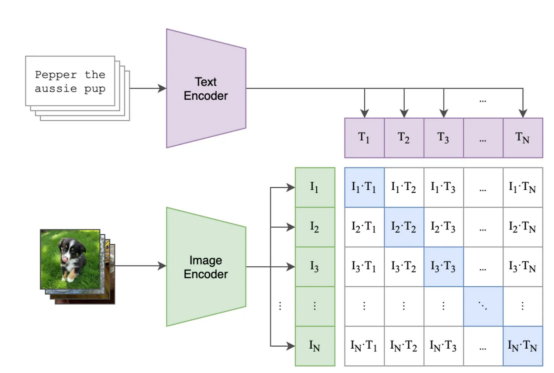
( wo sich die blauen Quadrate befinden die Bild-Text-Paare, für die wir die Ähnlichkeit optimieren möchten )
Nach dem Training sollten Sie in der Lage sein, einen Code zu generieren, in dem Sie das Bild und denTitel eines aussagekräftigen Vektorraums kodieren können, sobald Sie dies haben Wenn Sie Inhalte für jedes Bild und jeden Text einbetten, können Sie beispielsweise herausfinden, welche Bilder besser zum Titel passen (z. B. „Hunde im Sommerferien-Fotoalbum 2017“ am Strand finden) (Hund am Strand). ). Sprachmodelle wie CLIP sind zu leistungsstarken Werkzeugen zur Lösung komplexer Aufgaben der künstlichen Intelligenz geworden, indem sie visuelle und sprachliche Informationen integrieren. Ihre Fähigkeit, diese beiden Arten von Daten in einen gemeinsamen Vektorraum einzubetten, hat zu einer breiten Palette von Anwendungen geführt überlegene Leistung. Können visuelle Sprachmodelle Sprache verstehen? Inwieweit können tiefe Modelle Sprache verstehen? Unser Ziel ist es, visuelle Sprachmodelle und ihre Synthesefähigkeiten zu untersuchen. Wir schlagen zunächst einen neuen Datensatz vor, um das Inhaltsstoffverständnis zu testen.
Beziehungen, und Ordnung
:
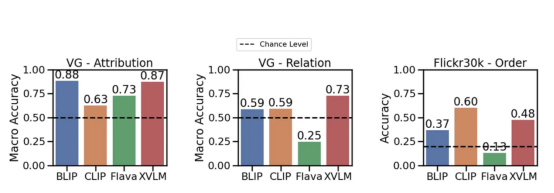
Attribute, Beziehungen und Ordnung). : ARO. (Attribute, Beziehungen und Bestellungen)Wie gut schneiden Modelle wie CLIP (und das aktuelle BLIP von Salesforce) beim Verstehen von Sprache ab Wir haben einen Satz attributbasierter zusammengesetzter Titel (z. B. „die rote Tür und der stehende Mann“(rote Tür und der stehende Mann)) und einen Satz zusammengestellt Beziehungsbasierte Synthese von Titeln (z. B. „Das Pferd frisst das Gras“Pferd frisst Gras)) und passenden Bildern. Dann generieren wir gefälschte Titel , die nach ersetzen, wie zum Beispiel „das Gras frisst das Pferd“ (Gras frisst das Pferd ) . Können die Models den richtigen Titel finden? Wir haben auch den Effekt des Mischens von Wörtern untersucht: Bevorzugt das Modell nicht gemischte Titel gegenüber gemischten Titeln? Die vier Datensätze, die wir für die Attribute ) Benchmark erstellt haben, werden unten angezeigt (beachten Sie, dass der Reihenfolge Teil zwei Datensätze enthält): Die verschiedenen Datensätze, die wir erstellt haben umfassen Beziehung, Attribution und Reihenfolge. Für jeden Datensatz zeigen wir ein Bildbeispiel und einen anderen Titel. Davon ist nur ein Titel korrekt, und das Modell muss diesen richtigen Titel identifizieren. 🏜 „Die weiße Straße und das gepflasterte Haus“ ( Das BLIP-Modell versteht den Unterschied zwischen „Gras frisst Gras“ und „Pferd frisst Gras“ nicht Vorausgesetzt ) Jetzt , sehen wir uns die experimentellen an: Wenige Modelle können die übertreffen Möglichkeit, Zusammenhänge weitgehend zu verstehen (z Beispiel: Essen—— Essen). Allerdings ist das CLIP-Modell etwas höher als diese Möglichkeit in Bezug auf die Kanten von Eigenschaften und Beziehungen . Dies zeigt tatsächlich, dass es immer noch ein Problem mit dem visuellen Sprachmodell gibt. Leistung verschiedener Modelle in Bezug auf Attribute, Beziehungen und Reihenfolge (Flick30k) Benchmark. Wobei CLIP, BLIP andere SoTA-Modelle-Modelle verwendet wurden Nicht nur der übliche Kontrastverlust . Warum ist das so? Fangen wir von vorne an: Visuelle Sprachmodelle werden oft in Retrieval-Aufgaben evaluiert: Nehmen Sie einen Titel und finden Sie das Bild, dem er zugeordnet ist. Wenn Sie sich die Datensätze ansehen, die zur Bewertung dieser Modelle verwendet werden (z. B. MSCOCO, Flickr30K), werden Sie feststellen, dass sie häufig Bilder enthalten, die mit Titeln Die orange Katze ist auf dem roten Tisch). Wenn also der Titel komplex ist, warum kann das Modell dann nicht das Kompositionsverständnis erlernen? ]Die Suche in diesen Datensätzen erfordert nicht unbedingt ein Verständnis der Zusammensetzung. Wir haben versucht, das Problem besser zu verstehen, und haben die Leistung des Modells beim Abrufen beim Neuordnen der Wortreihenfolge in Titeln getestet. Können wir das richtige Bild für den Titel „books the looking at people are“ finden? Wenn die Antwort „Ja “ lautet, bedeutet dies, dass , keine Anleitungsinformationen erforderlich sind, um das richtige Bild zu finden.
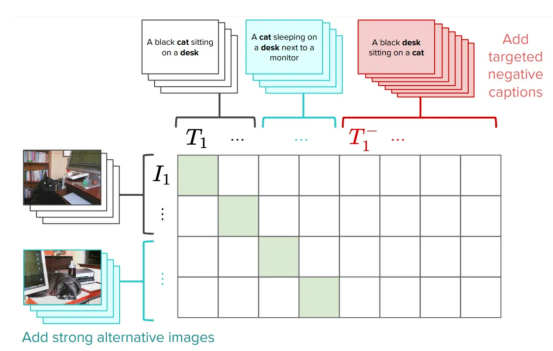
Die Aufgabe unseres Testmodells besteht darin, verschlüsselte Titel abzurufen. Selbst wenn wir die Bildunterschriften verschlüsseln, kann das Modell das entsprechende Bild korrekt finden (und umgekehrt). Dies deutet darauf hin, dass die Abrufaufgabe möglicherweise zu einfach ist , Bild vom Autor bereitgestellt. Wir haben verschiedene Shuffle-Verfahren getestet und die Ergebnisse sind positiv: Auch wenn unterschiedliche Shuffle-Techniken zum Einsatz kommen, wird die Abrufleistung grundsätzlich nicht beeinträchtigt. Sagen wir es noch einmal: Visuelle Sprachmodelle erzielen bei diesen Datensätzen einen leistungsstarken Abruf, selbst wenn auf die Anweisungsinformationen nicht zugegriffen werden kann. Diese Modelle verhalten sich möglicherweise wie ein Stapel von Wörtern , wobei die Reihenfolge keine Rolle spielt: Wenn das Modell die Wortreihenfolge nicht verstehen muss, um beim Abrufen gute Ergebnisse zu erzielen, was messen wir dann tatsächlich beim Abrufen? ? Da wir nun wissen, dass es ein Problem gibt, möchten wir vielleicht nach einer Lösung suchen. Der einfachste Weg ist: Lassen Sie das CLIP-Modell verstehen, dass „die Katze auf dem Tisch“ und „der Tisch liegt auf der Katze“ unterschiedlich sind. Tatsächlich ist eine der Möglichkeiten vorgeschlagen haben, die Verbesserung des CLIP-Trainings durch das Hinzufügen eines harten Negativs, das speziell zur Lösung dieses Problems erstellt wurde. Dies ist eine sehr einfache und effiziente Lösung: Sie erfordert sehr kleine Änderungen am ursprünglichen CLIP-Verlust, ohne die Gesamtleistung zu beeinträchtigen (einige Vorbehalte können Sie im Artikel nachlesen). Wir nennen diese Version von CLIP NegCLIP. Einführung von Hartnegativen im CLIP-Modell (Wir haben Bild- und Text-Hartnegative hinzugefügt , ) Grundsätzlich bitten wir das NegCLIP -Modell , ein Bild einer schwarzen Katze über dem Satz „Eine schwarze Katze sitzt auf einem Schreibtisch“ zu platzieren. Nah, aber weit wegSatz „Ein schwarzer Schreibtisch“. Sitting on a Cat“ ( ). Hinweis: Letzteres wird automatisch durch die Verwendung von POS-Tags generiert. Der Effekt dieses Fixes besteht darin, dass er tatsächlich die Leistung des ARO-Benchmarks verbessert, ohne die Abrufleistung oder die Leistung nachgelagerter Aufgaben wie Abruf und Klassifizierung zu beeinträchtigen. In der folgenden Abbildung finden Sie Ergebnisse zu verschiedenen Benchmarks (Einzelheiten finden Sie in diesem entsprechenden Papier ). NegCLIPModell im Vergleich zu CLIPModell bei verschiedenen Benchmarks. Unter diesen ist der blaue Benchmark der von uns eingeführte Benchmark, und der grüne Benchmark stammt aus dem NetzwerkDokumentation(Bild vom Autor bereitgestellt) Sie Das kann man hier sehen und das ist eine enorme Verbesserung gegenüber dem ARO-Benchmark, und es gibt auch Edge-Verbesserungenoder ähnliche Leistungen bei anderen nachgelagerten Aufgaben. Mert (Hauptautor des Artikels) bei der Erstellung einer kleinen Bibliothek zum Testen visueller Sprachmodelle. Nun Erledigt. Sie können seinen Code verwenden, um unsere Ergebnisse zu reproduzieren oder mit neuen Modellen zu experimentieren. Es dauert nur ein paar Zeilen P: Zusätzlich haben wir NegCLIP implementiert. Modell (Es handelt sich tatsächlich um eine aktualisierte Kopie von OpenCLIP), seine vollständige Code-Download-Adresse lautet https://github.com/vinid/neg_clip. Kurz gesagt, das visuelle Sprachmodellkann derzeit viele Dinge tun. Als nächstes Wir können es kaum erwarten zu sehen, was zukünftige Modelle wie GPT4 leisten können! Zhu Xianzhong, 51CTO-Community-Redakteur, 51CTO-Expertenblogger, Dozent, Computerlehrer an einer Universität in Weifang und ein Veteran in der freiberuflichen Programmierbranche. Originaltitel: Your Vision-Language Model Might Be a Bag of Words, Autor: Federico Bianchi
白路和狠的屋

Was tun?
Programmierimplementierung
import clip
from dataset_zoo import VG_Relation, VG_Attribution
model, image_preprocess = clip.load("ViT-B/32", device="cuda")
root_dir="/path/to/aro/datasets"
#把 download设置为True将把数据集下载到路径`root_dir`——如果不存在的话
#对于VG-R和VG-A,这将是1GB大小的压缩zip文件——它是GQA的一个子集
vgr_dataset = VG_Relation(image_preprocess=preprocess,
download=True, root_dir=root_dir)
vga_dataset = VG_Attribution(image_preprocess=preprocess,
download=True, root_dir=root_dir)
#可以对数据集作任何处理。数据集中的每一项具有类似如下的形式:
# item = {"image_options": [image], "caption_options": [false_caption, true_caption]}Fazit
Übersetzer-Einführung
Das obige ist der detaillierte Inhalt vonErforschung der Möglichkeit, aus einer Reihe von Wörtern ein visuelles Sprachmodell zu erstellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr