
Heim >Technologie-Peripheriegeräte >KI >Erfahren Sie in einem Artikel, was maschinelles Lernen ist
Erfahren Sie in einem Artikel, was maschinelles Lernen ist

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-21 23:01:583679Durchsuche
Die Welt ist voller Daten – Bilder, Videos, Tabellenkalkulationen, Audio und Texte, die von Menschen und Computern generiert werden, überschwemmen das Internet und ertränken uns in einem Meer von Informationen.
Traditionell analysieren Menschen Daten, um intelligentere Entscheidungen zu treffen und versuchen, Systeme anzupassen, um Änderungen in Datenmustern zu kontrollieren. Mit zunehmender Menge an eingehenden Informationen nimmt jedoch unsere Fähigkeit ab, diese zu verstehen, was uns vor die folgende Herausforderung stellt:
Wie nutzen wir all diese Daten, um Bedeutungen automatisiert statt manuell abzuleiten?
Hier kommt maschinelles Lernen ins Spiel. In diesem Artikel wird Folgendes vorgestellt:
- Was ist maschinelles Lernen?
- Schlüsselelemente von Algorithmen für maschinelles Lernen.
- Wie maschinelles Lernen funktioniert mit den Tools und Algorithmen zur Analyse und Verarbeitung von Daten, um genaue Vorhersagen zu treffen.
- Diese Vorhersagen werden durch maschinelles Lernen von Mustern aus einem Datensatz namens „Trainingsdaten“ getroffen und können die weitere technologische Entwicklung vorantreiben, um das Leben der Menschen zu verbessern.
- 一Was ist maschinelles Lernen?
– bezieht sich auf die Text-, Bild-, Video- oder Zeitreiheninformationen, aus denen das maschinelle Lernsystem lernen muss. Trainingsdaten werden häufig beschriftet, um dem ML-System die „richtige Antwort“ anzuzeigen, z. B. Begrenzungsrahmen um Gesichter in einem Gesichtsdetektor oder die zukünftige Aktienentwicklung in einem Aktienprädiktor.
steht für- – es bezieht sich auf die codierte Darstellung von Objekten in den Trainingsdaten, beispielsweise Gesichter, die durch Merkmale wie „Augen“ dargestellt werden. Das Codieren einiger Modelle ist einfacher als andere, und dies ist es, was die Modellauswahl bestimmt. Beispielsweise bilden neuronale Netze eine Darstellung, während Support-Vektor-Maschinen eine andere Darstellung bilden. Die meisten modernen Methoden nutzen neuronale Netze.
- Bewertung – Hier geht es darum, wie wir ein Modell beurteilen oder gegenüber einem anderen identifizieren. Wir nennen es normalerweise Nutzenfunktion, Verlustfunktion oder Bewertungsfunktion. Der mittlere quadratische Fehler (die Ausgabe des Modells im Vergleich zur Datenausgabe) oder die Wahrscheinlichkeit (die geschätzte Wahrscheinlichkeit des Modells angesichts der beobachteten Daten) sind Beispiele für verschiedene Bewertungsfunktionen.
- Optimierung – Dies bezieht sich darauf, wie der Raum durchsucht wird, der das Modell darstellt, oder wie die Beschriftungen in den Trainingsdaten verbessert werden, um eine bessere Auswertung zu erhalten. Optimierung bedeutet, die Modellparameter zu aktualisieren, um den Wert der Verlustfunktion zu minimieren. Dadurch kann das Modell seine Genauigkeit schneller verbessern.
- Das Obige ist eine detaillierte Klassifizierung der vier Komponenten von Algorithmen für maschinelles Lernen.
- Merkmale maschineller LernsystemeBeschreibend: Das System sammelt historische Daten, organisiert sie und präsentiert sie dann auf leicht verständliche Weise.
Entscheidungsprozess
Modelle für maschinelles Lernen sind darauf ausgelegt, Muster aus Daten zu lernen und dieses Wissen anzuwenden, um Vorhersagen zu treffen. Die Frage ist: Wie trifft das Modell Vorhersagen?
Der Prozess ist sehr einfach: Finden Sie Muster aus Eingabedaten (beschriftet oder unbeschriftet) und wenden Sie sie an, um ein Ergebnis abzuleiten.
Fehlerfunktion
Modelle für maschinelles Lernen sind darauf ausgelegt, die von ihnen gemachten Vorhersagen mit der Realität zu vergleichen. Das Ziel besteht darin, zu verstehen, ob das Lernen in die richtige Richtung erfolgt. Dies bestimmt die Genauigkeit des Modells und gibt Hinweise darauf, wie wir das Training des Modells verbessern können.
Modelloptimierungsprozess
Das ultimative Ziel des Modells besteht darin, Vorhersagen zu verbessern, was bedeutet, die Differenz zwischen bekannten Ergebnissen und entsprechenden Modellschätzungen zu verringern.
Das Modell muss sich durch ständige Aktualisierung der Gewichte besser an die Trainingsdatenproben anpassen. Der Algorithmus arbeitet in einer Schleife, bewertet und optimiert die Ergebnisse und aktualisiert die Gewichte, bis ein Maximalwert hinsichtlich der Genauigkeit des Modells erreicht wird.
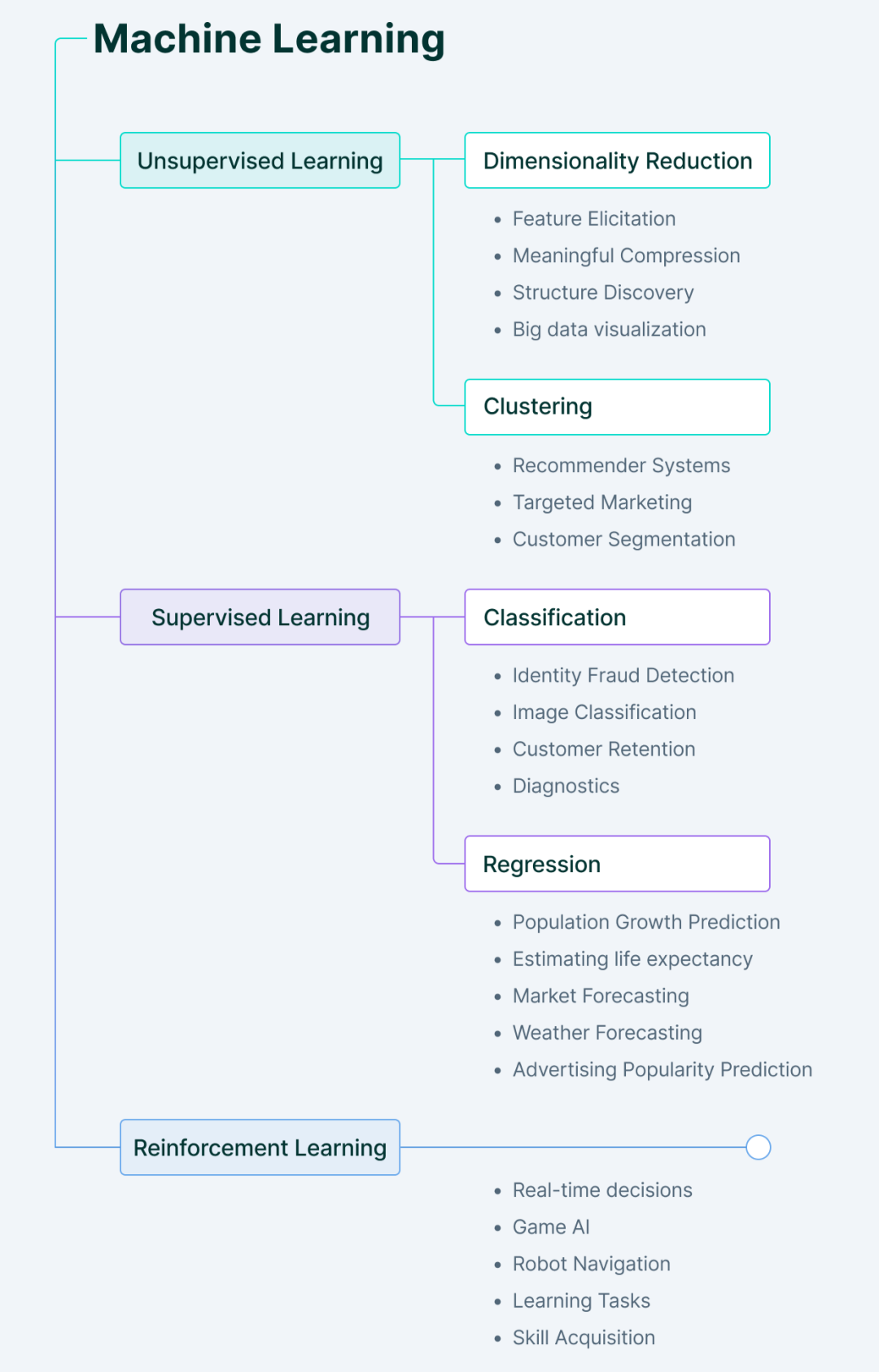
Arten von Methoden des maschinellen Lernens
Maschinelles Lernen umfasst hauptsächlich vier Arten.
1. Überwachtes maschinelles Lernen
Beim überwachten Lernen lernt die Maschine, wie der Name schon sagt, unter Anleitung.
Dies geschieht, indem dem Computer ein Satz gekennzeichneter Daten zugeführt wird, damit die Maschine versteht, was die Eingabe ist und was die Ausgabe sein soll. Hier fungieren Menschen als Führer und versorgen das Modell mit gekennzeichneten Trainingsdaten (Input-Output-Paare), aus denen die Maschine Muster lernt.
Sobald die Beziehung zwischen Eingabe und Ausgabe aus früheren Datensätzen gelernt wurde, kann die Maschine den Ausgabewert neuer Daten leicht vorhersagen.
Wo können wir überwachtes Lernen einsetzen?
Die Antwort lautet: Wenn wir wissen, worauf wir in den Eingabedaten achten müssen und was wir als Ausgabe wünschen.
Zu den Haupttypen überwachter Lernprobleme gehören Regressions- und Klassifizierungsprobleme.
2. Unüberwachtes maschinelles Lernen
Unüberwachtes Lernen funktioniert genau das Gegenteil von überwachtem Lernen.
Es werden unbeschriftete Daten verwendet – die Maschine muss die Daten verstehen, versteckte Muster finden und entsprechende Vorhersagen treffen.
Hier liefern uns Maschinen neue Erkenntnisse, indem sie selbstständig verborgene Muster aus Daten ableiten, ohne dass der Mensch angeben muss, wonach er suchen soll.
Zu den Haupttypen unbeaufsichtigter Lernprobleme gehören Clustering und Assoziationsregelanalyse.
3. Reinforcement Learning
Reinforcement Learning beinhaltet einen Agenten, der lernt, sich in einer Umgebung zu verhalten, indem er Aktionen ausführt.
Basierend auf den Ergebnissen dieser Aktionen gibt es Feedback und passt seinen zukünftigen Kurs an – für jede gute Aktion erhält der Agent ein positives Feedback und für jede schlechte Aktion erhält der Agent ein negatives Feedback oder eine Strafe.
Reinforcement Learning lernt ohne gekennzeichnete Daten. Da es keine gekennzeichneten Daten gibt, kann der Agent nur auf der Grundlage seiner eigenen Erfahrung lernen.
4. Halbüberwachtes Lernen
Halbüberwacht ist der Zustand zwischen überwachtem und unüberwachtem Lernen.
Es nutzt die positiven Aspekte jedes Lernens, d. h. es verwendet kleinere beschriftete Datensätze als Leitfaden für die Klassifizierung und führt eine unbeaufsichtigte Merkmalsextraktion aus größeren unbeschrifteten Datensätzen durch.
Der Hauptvorteil des halbüberwachten Lernens besteht in seiner Fähigkeit, Probleme zu lösen, wenn nicht genügend beschriftete Daten zum Trainieren des Modells vorhanden sind oder wenn die Daten einfach nicht beschriftet werden können, weil Menschen nicht wissen, wonach sie darin suchen sollen.
Vier 6 reale Anwendungen für maschinelles Lernen
Maschinelles Lernen ist heutzutage das Herzstück fast aller Technologieunternehmen, einschließlich Unternehmen wie Google oder der YouTube-Suchmaschine.
Nachfolgend haben wir einige Beispiele für reale Anwendungen des maschinellen Lernens zusammengestellt, mit denen Sie vielleicht vertraut sind:
Selbstfahrende Autos
Fahrzeuge begegnen auf der Straße einer Vielzahl von Situationen.
Damit selbstfahrende Autos besser funktionieren als Menschen, müssen sie lernen und sich an veränderte Straßenverhältnisse und das Verhalten anderer Fahrzeuge anpassen.
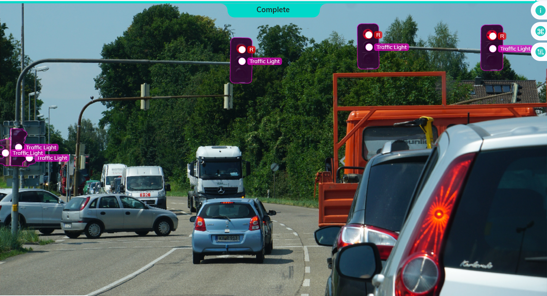
Selbstfahrende Autos sammeln von Sensoren und Kameras Daten über ihre Umgebung, interpretieren diese und reagieren entsprechend. Es nutzt überwachtes Lernen, um Objekte in der Umgebung zu identifizieren, unüberwachtes Lernen, um Muster in anderen Fahrzeugen zu erkennen, und ergreift schließlich mithilfe von Verstärkungsalgorithmen entsprechende Maßnahmen.
Bildanalyse und Objekterkennung
Bildanalyse wird verwendet, um verschiedene Informationen aus Bildern zu extrahieren.
Es gibt Anwendungen in Bereichen wie der Prüfung auf Herstellungsfehler, der Analyse des Autoverkehrs in Smart Cities oder visuellen Suchmaschinen wie Google Lens.
Die Hauptidee besteht darin, mithilfe von Deep-Learning-Techniken Merkmale aus Bildern zu extrahieren und diese Merkmale dann auf die Objekterkennung anzuwenden.
Kundenservice-Chatbots
Heutzutage ist es für Unternehmen weit verbreitet, KI-Chatbots zu verwenden, um Kundensupport und Vertrieb anzubieten. KI-Chatbots helfen Unternehmen bei der Bewältigung großer Mengen an Kundenanfragen, indem sie rund um die Uhr Support bieten, wodurch die Supportkosten gesenkt und zusätzliche Einnahmen und zufriedene Kunden generiert werden.
KI-Robotik nutzt die Verarbeitung natürlicher Sprache (NLP), um Text zu verarbeiten, Abfrageschlüsselwörter zu extrahieren und entsprechend zu reagieren.
Medizinische Bildgebung und Diagnostik
Die Wahrheit ist: Medizinische Bildgebungsdaten sind sowohl die umfangreichste als auch eine der komplexesten Informationsquellen.
Die manuelle Analyse Tausender medizinischer Bilder ist eine mühsame Aufgabe und verschwendet wertvolle Zeit für Pathologen, die effizienter genutzt werden könnte.
Aber es geht nicht nur um Zeitersparnis – kleine Merkmale wie Artefakte oder Knötchen sind möglicherweise mit bloßem Auge nicht sichtbar, was zu Verzögerungen bei der Krankheitsdiagnose und falschen Vorhersagen führt. Aus diesem Grund bietet der Einsatz von Deep-Learning-Techniken mit neuronalen Netzen, mit denen sich Merkmale aus Bildern extrahieren lassen, großes Potenzial.
Betrugserkennung
Mit der Expansion des E-Commerce-Sektors können wir einen Anstieg der Zahl der Online-Transaktionen und eine Diversifizierung der verfügbaren Zahlungsmethoden beobachten. Leider nutzen manche Menschen diese Situation aus. Betrüger in der heutigen Welt sind hochqualifiziert und können neue Technologien sehr schnell übernehmen.
Deshalb brauchen wir ein System, das Datenmuster analysieren, genaue Vorhersagen treffen und auf Online-Cybersicherheitsbedrohungen wie gefälschte Anmeldeversuche oder Phishing-Angriffe reagieren kann.
Beispielsweise können Betrugspräventionssysteme anhand der Tatsache, wo Sie in der Vergangenheit Einkäufe getätigt haben oder wie lange Sie online waren, erkennen, ob ein Kauf legitim ist. Ebenso können sie erkennen, ob jemand online oder am Telefon versucht, sich als Sie auszugeben.
Empfehlungsalgorithmus
Diese Relevanz von Empfehlungsalgorithmen basiert auf der Untersuchung historischer Daten und hängt von mehreren Faktoren ab, einschließlich Benutzerpräferenzen und -interessen.
Unternehmen wie JD.com oder Douyin nutzen Empfehlungssysteme, um relevante Inhalte oder Produkte zu kuratieren und Benutzern/Käufern anzuzeigen.
Fünf Herausforderungen und Einschränkungen des maschinellen Lernens
Unter- und Überanpassung
In den meisten Fällen liegt der Grund für die schlechte Leistung eines Algorithmus für maschinelles Lernen in Unter- und Überanpassung.
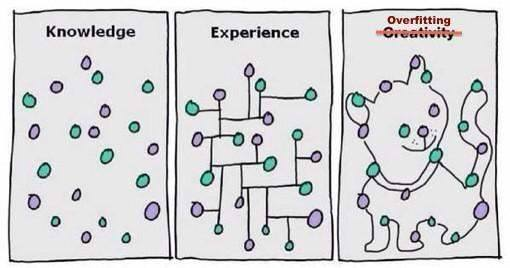
Lassen Sie uns diese Begriffe im Kontext des Trainings von Modellen für maschinelles Lernen aufschlüsseln.
- Unteranpassung ist ein Szenario, in dem ein maschinelles Lernmodell weder die Beziehungen zwischen Variablen in den Daten lernen noch neue Datenpunkte korrekt vorhersagen kann. Mit anderen Worten: Das maschinelle Lernsystem erkennt keine Trends über Datenpunkte hinweg.
- Überanpassung tritt auf, wenn ein Modell für maschinelles Lernen zu viel aus den Trainingsdaten lernt und dabei auf Datenpunkte achtet, die von Natur aus verrauscht oder für den Bereich des Datensatzes irrelevant sind. Es versucht, jeden Punkt auf der Kurve anzupassen und sich daher das Datenmuster zu merken.
Da das Modell nur über sehr geringe Flexibilität verfügt, kann es keine neuen Datenpunkte vorhersagen. Mit anderen Worten: Es konzentriert sich zu sehr auf die gegebenen Beispiele und sieht nicht das Gesamtbild.
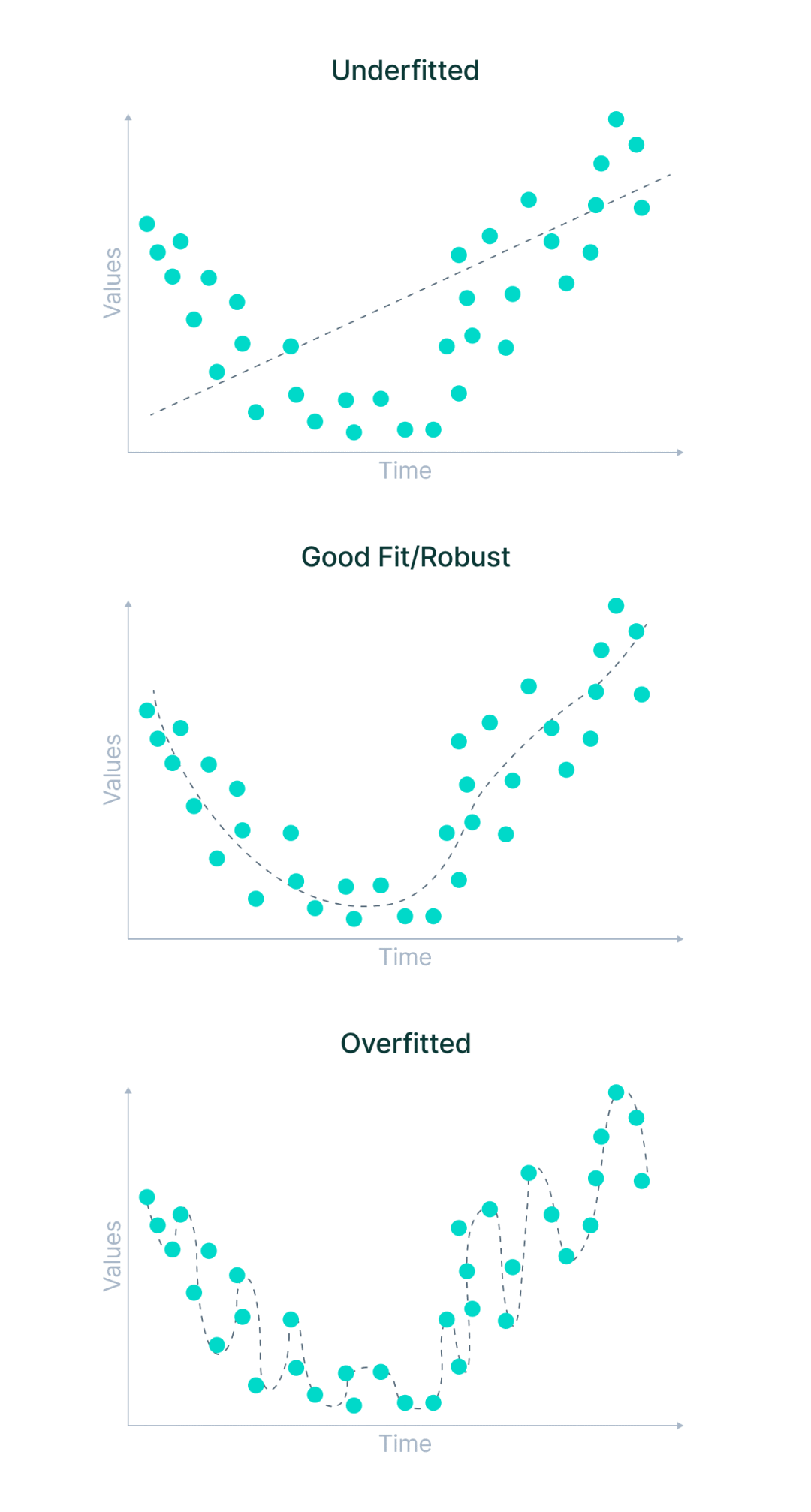
Was sind die Ursachen für Unter- und Überanpassung?
Allgemeinere Fälle umfassen Situationen, in denen die für das Training verwendeten Daten nicht sauber sind und viele Rausch- oder Müllwerte enthalten oder die Datengröße zu klein ist. Es gibt jedoch einige spezifischere Gründe.
Werfen wir einen Blick darauf.
Eine Unteranpassung kann aus folgenden Gründen auftreten:
- Das Modell wurde mit den falschen Parametern trainiert und die Trainingsdaten wurden nicht vollständig eingehalten
- Das Modell ist zu einfach und kann sich nicht genügend Funktionen merken
- Die Trainingsdaten sind zu vielfältig oder komplex
Dies kann in den folgenden Situationen passieren Überanpassung:
- Das Modell wurde mit den falschen Parametern trainiert und hat die Trainingsdaten überbeobachtet.
- Das Modell war zu komplex und nicht auf vielfältigere Daten vorab trainiert.
- Die Bezeichnungen der Trainingsdaten sind zu streng oder die Originaldaten sind zu einheitlich und stellen nicht die wahre Verteilung dar.

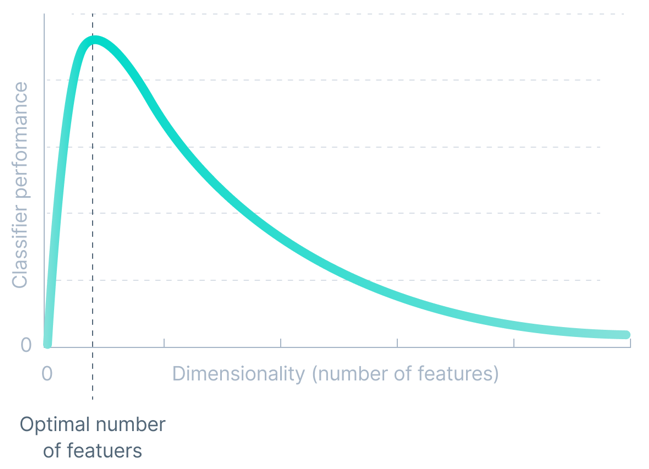
Dimensionalität
Die Genauigkeit jedes maschinellen Lernmodells ist direkt proportional zur Dimensionalität des Datensatzes. Aber es funktioniert nur bis zu einer bestimmten Schwelle.
Die Dimensionalität eines Datensatzes bezieht sich auf die Anzahl der im Datensatz vorhandenen Attribute/Merkmale. Eine exponentielle Erhöhung der Anzahl der Dimensionen führt zur Hinzufügung nicht wesentlicher Attribute, die das Modell verwirren und dadurch die Genauigkeit des maschinellen Lernmodells verringern.
Wir nennen diese Schwierigkeiten, die mit dem Training von Modellen für maschinelles Lernen verbunden sind, den „Fluch der Dimensionalität“.
Datenqualität
Maschinelle Lernalgorithmen reagieren empfindlich auf Trainingsdaten von geringer Qualität.
Die Datenqualität kann durch Rauschen in den Daten aufgrund falscher Daten oder fehlender Werte beeinträchtigt werden. Selbst relativ kleine Fehler in den Trainingsdaten können zu großen Fehlern in der Systemausgabe führen.
Wenn ein Algorithmus eine schlechte Leistung erbringt, liegt dies normalerweise an Problemen mit der Datenqualität, z. B. an unzureichender Menge/Schiefe/verrauschten Daten oder unzureichenden Funktionen zur Beschreibung der Daten.
Vor dem Training eines Modells für maschinelles Lernen ist daher häufig eine Datenbereinigung erforderlich, um qualitativ hochwertige Daten zu erhalten.
Das obige ist der detaillierte Inhalt vonErfahren Sie in einem Artikel, was maschinelles Lernen ist. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr