
Heim >Technologie-Peripheriegeräte >KI >Die Sternemarke hat 100.000 überschritten! Nach Auto-GPT erreicht Transformer einen neuen Meilenstein
Die Sternemarke hat 100.000 überschritten! Nach Auto-GPT erreicht Transformer einen neuen Meilenstein

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-21 21:34:041248Durchsuche
Im Jahr 2017 schlug das Google-Team in der Veröffentlichung „Attention Is All You Need“ die bahnbrechende NLP-Architektur Transformer vor und schummelt seitdem.
Im Laufe der Jahre erfreute sich diese Architektur großer Beliebtheit bei großen Technologieunternehmen wie Microsoft, Google und Meta. Sogar ChatGPT, das die Welt erobert hat, wurde auf Basis von Transformer entwickelt.
Und erst heute hat Transformer die 100.000-Sterne-Marke auf GitHub überschritten!
Hugging Face, ursprünglich nur ein Chatbot-Programm, wurde als Zentrum des Transformer-Modells berühmt und wurde auf einen Schlag zu einer weltberühmten Open-Source-Community.
Um diesen Meilenstein zu feiern, hat Hugging Face außerdem 100 Projekte zusammengefasst, die auf der Transformer-Architektur basieren.
Transformer brachte den Kreis des maschinellen Lernens zur Explosion
Als Google im Juni 2017 das Papier „Attention Is All You Need“ veröffentlichte, ahnte vielleicht niemand, wie viele Überraschungen diese Deep-Learning-Architektur Transformer bringen könnte.
Seit seiner Geburt hat sich Transformer zum Eckpfeiler im KI-Bereich entwickelt. Auch Google hat 2019 eigens dafür ein Patent angemeldet.

Da Transformer eine Mainstream-Position im NLP-Bereich einnimmt und begonnen hat, auf andere Bereiche überzugehen, wird immer mehr daran gearbeitet, es in den CV-Bereich einzuführen.
Viele Internetnutzer waren sehr aufgeregt, als Transformer diesen Meilenstein durchbrach.
„Ich habe an vielen beliebten Open-Source-Projekten mitgewirkt, aber zu sehen, wie Transformer 100.000 Sterne auf GitHub erreicht, ist etwas ganz Besonderes!“
Vor einiger Zeit hat Auto- Die GitHub-Star-Anzahl von GPT übertraf die von Pytorch und sorgte für großes Aufsehen.
Netizens kommen nicht umhin, sich zu fragen, wie Auto-GPT im Vergleich zu Transformer abschneidet?

Tatsächlich übertrifft Auto-GPT Transformer bei weitem und hat bereits 130.000 Sterne.
Derzeit hat Tensorflow mehr als 170.000 Sterne. Es ist ersichtlich, dass Transformer nach diesen beiden Projekten die dritte Bibliothek für maschinelles Lernen mit einer Sternebewertung von über 100.000 ist.
Einige Internetnutzer erinnerten sich, dass die Transformers-Bibliothek bei ihrer ersten Verwendung „pytorch-pretrained-BERT“ hieß.
50 fantastische Transformer-basierte Projekte
Transformers ist nicht nur ein Toolkit für die Verwendung vorab trainierter Modelle, sondern auch eine Community von Projekten rund um Transformers und Hugging Face Hub.
In der Liste unten hat Hugging Face 100 erstaunliche und neuartige Projekte basierend auf Transformer zusammengefasst.

Nachfolgend haben wir die 50 besten Projekte zur Einführung ausgewählt:
gpt4all
gpt4all ist ein Open-Source-Chatbot-Ökosystem. Es basiert auf einer großen Sammlung sauberer Assistentendaten, einschließlich Code, Geschichten und Konversationen. Es stellt groß angelegte Open-Source-Sprachmodelle wie LLaMA und GPT-J für das Training als Assistent bereit.
Schlüsselwörter: Open Source, LLaMa, GPT-J, Befehl, Assistent
recommenders
Dieses Repository enthält Beispiele und Best Practices für den Aufbau von Empfehlungssystemen, bereitgestellt in Form von Jupiter-Notizbüchern. Es deckt mehrere Aspekte ab, die zum Aufbau eines effektiven Empfehlungssystems erforderlich sind: Datenvorbereitung, Modellierung, Bewertung, Modellauswahl und -optimierung sowie Operationalisierung.
Schlüsselwörter: Empfehlungssystem, AzureML
lama-cleaner
Bild Reparaturwerkzeug basierend auf der Stable Diffusion-Technologie. Sie können alle unerwünschten Objekte, Defekte oder sogar Personen aus dem Bild löschen und alles auf dem Bild ersetzen.
Schlüsselwörter: Reparatur, SD, stabile Diffusion
FLAIR ist ein leistungsstarkes PyTorch-Framework zur Verarbeitung natürlicher Sprache, das mehrere wichtige Aufgaben transformieren kann: NER, Sentimentanalyse, Wortart-Tagging, Text und Dualität Einbetten usw.
Schlüsselwörter: NLP, Texteinbettung, Dokumenteinbettung, Biomedizin, NER, PoS, Stimmungsanalyse
#🎜 🎜#
Schlüsselwörter: Datenbank, Low Code, KI-Tabelle
langchain
#🎜🎜 # Ziel von Langchain ist es, bei der Entwicklung von Anwendungen zu helfen, die mit LLM und anderen Wissensquellen kompatibel sind. Die Bibliothek ermöglicht die Verkettung von Aufrufen an Anwendungen und die Erstellung einer Sequenz in vielen Tools.
Schlüsselwörter: LLM, großes Sprachmodell, Agent, Kette
ParlAI
#🎜 🎜#ParlAI ist ein Python-Framework zum Teilen, Trainieren und Testen von Konversationsmodellen, vom offenen Domain-Chat über aufgabenorientierten Dialog bis hin zur visuellen Beantwortung von Fragen. Es bietet über 100 Datensätze, viele vorab trainierte Modelle, eine Reihe von Agenten und mehrere Integrationen unter derselben API.Schlüsselwörter: Dialog, Chatbot, VQA, Datensatz, Agent
Satztransformatoren #🎜🎜 #Dieses Framework bietet eine einfache Möglichkeit, dichte Vektordarstellungen von Sätzen, Absätzen und Bildern zu berechnen. Diese Modelle basieren auf Transformer-basierten Netzwerken wie BERT/RoBERTa/XLM-RoBERTa und haben SOTA bei verschiedenen Aufgaben erreicht. Text wird in einen Vektorraum eingebettet, sodass ähnliche Texte nahe beieinander liegen und durch Kosinusähnlichkeit effizient gefunden werden können.
Schlüsselwörter: dichte Vektordarstellung, Texteinbettung, Satzeinbettung
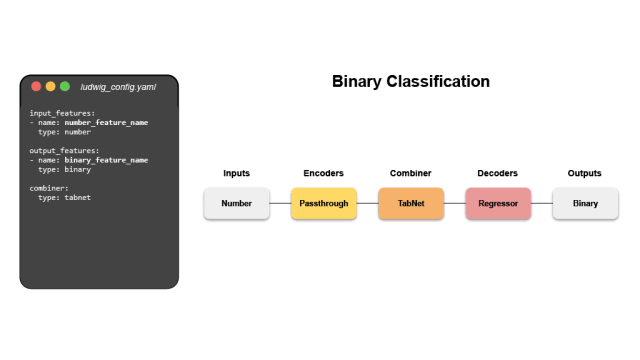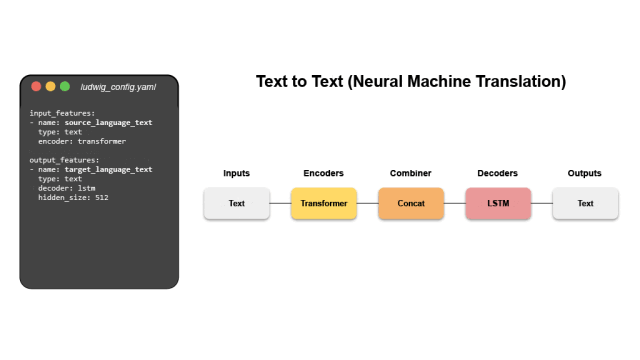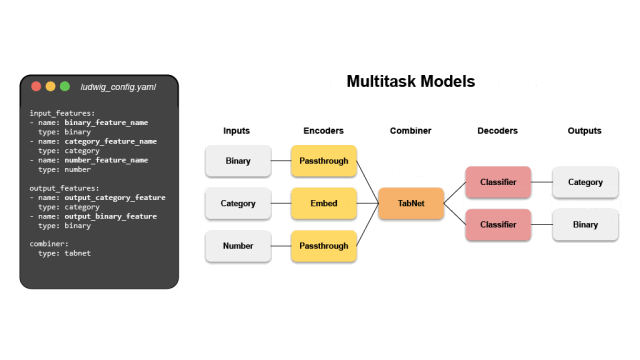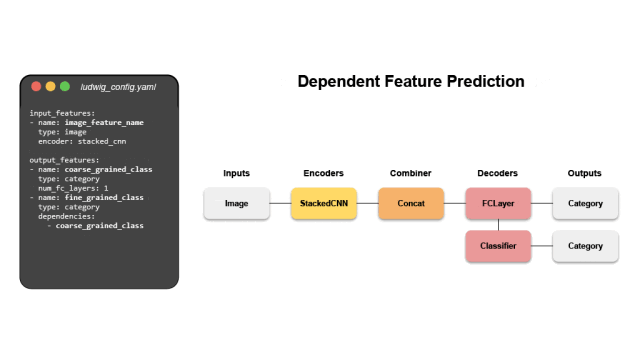
ludwig# 🎜 🎜 #Ludwig ist ein deklaratives Framework für maschinelles Lernen, das die Definition von Pipelines für maschinelles Lernen mithilfe eines einfachen und flexiblen datengesteuerten Konfigurationssystems erleichtert. Ludwig zielt auf verschiedene KI-Aufgaben ab und stellt ein datengesteuertes Konfigurationssystem, Trainings-, Vorhersage- und Bewertungsskripte sowie eine Programmier-API bereit.
Schlüsselwörter: deklarativ, datengesteuert, ML-Framework
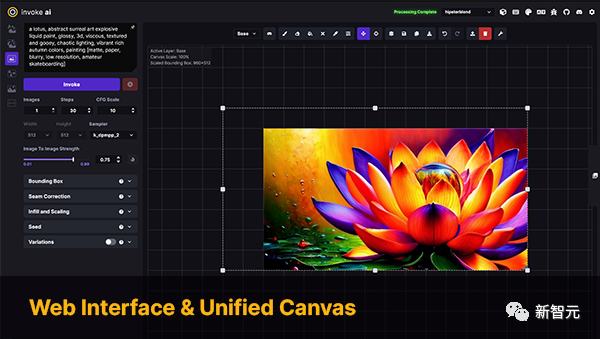
InvokeAI
InvokeAI ist eine Engine für das Stable Diffusion-Modell, die sich an Profis, Künstler und Enthusiasten richtet. Es nutzt die neueste KI-gesteuerte Technologie über CLI und WebUI.
Schlüsselwörter: Stable Diffusion, WebUI, CLI
PaddleNLP
PaddleNLP ist eine benutzerfreundliche und leistungsstarke NLP-Bibliothek, insbesondere für die chinesische Sprache. Es unterstützt mehrere vorab trainierte Modellzoos und unterstützt ein breites Spektrum an NLP-Aufgaben von der Forschung bis hin zu industriellen Anwendungen.
Schlüsselwörter: Verarbeitung natürlicher Sprache, Chinesisch, Forschung, Industrie
Strophe
Die offizielle Python-NLP-Bibliothek der Stanford University NLP Group. Es unterstützt die Ausführung einer breiten Palette präziser Tools zur Verarbeitung natürlicher Sprache in mehr als 60 Sprachen und unterstützt den Zugriff auf die Java Stanford CoreNLP-Software von Python aus.
Schlüsselwörter: NLP, mehrsprachig, CoreNLP
DeepPavlov
DeepPavlov ist eine Open-Source-Konversationsbibliothek für künstliche Intelligenz. Es ist für die Entwicklung produktionsreifer Chatbots und komplexer Dialogsysteme sowie für die Forschung im Bereich NLP, insbesondere Dialogsysteme, konzipiert.
Schlüsselwörter: Dialog, Chatbot
alpaca-lora
Alpaca-lora enthält Code zur Reproduktion der Stanford Alpaca-Ergebnisse mithilfe der Low-Rank-Adaption (LoRA). Dieses Repository bietet Schulungs- (Feinabstimmungs-) und Generierungsskripts.
Schlüsselwörter: LoRA, Parameter-effiziente Feinabstimmung
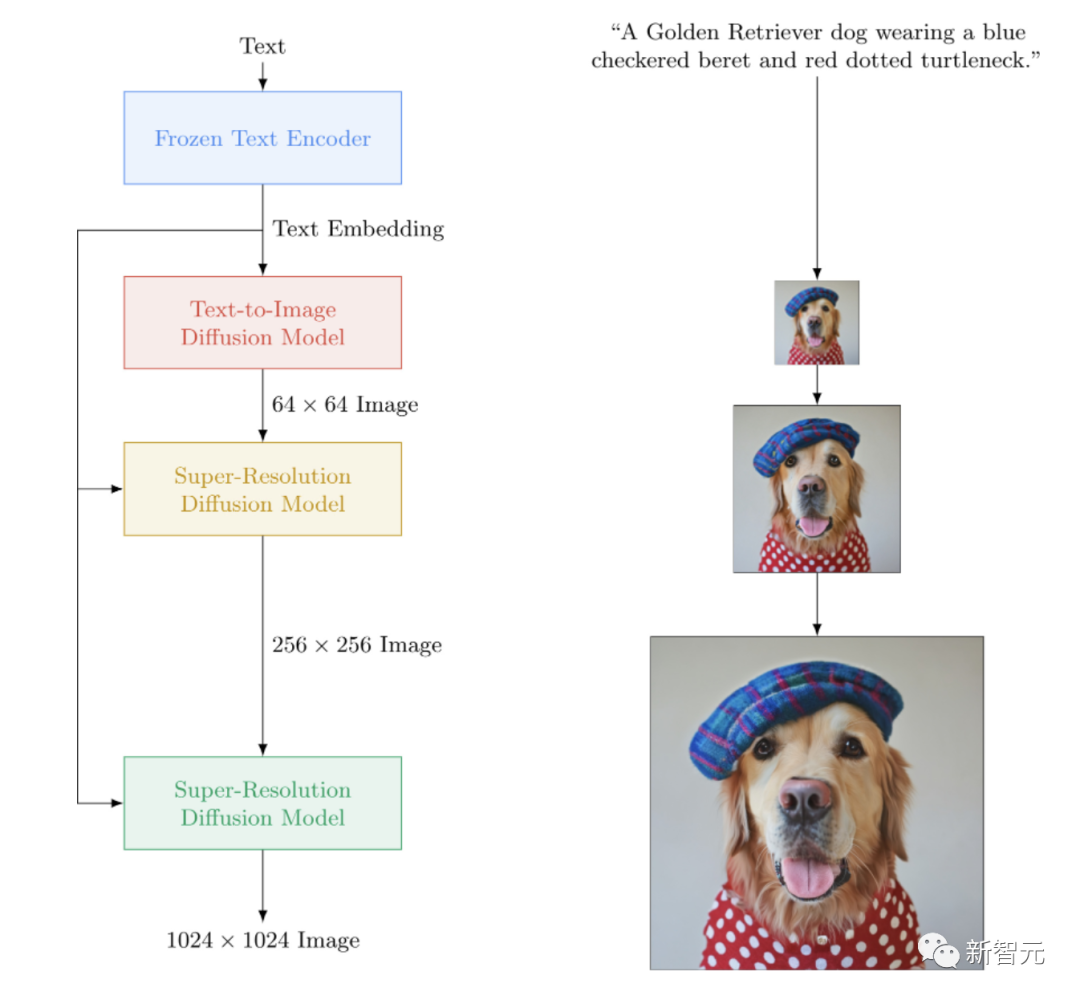
imagen-pytorch
Eine Open-Source-Implementierung von Imagen, dem Closed-Source-Text-zu-Bild-Neuronalen Netzwerk von Google, das DALL-E2 übertrifft. imagen-pytorch ist das neue SOTA für die Text-zu-Bild-Synthese.
Schlüsselwörter: Imagen, Wenshengtu
adapter-transformers
adapter-transformers ist eine Erweiterung der Transformers-Bibliothek, die Adapter in die fortschrittlichsten Sprachmodelle integriert, indem AdapterHub integriert wird Repository vorab trainierter Adaptermodule. Es ist ein direkter Ersatz für Transformers und wird regelmäßig aktualisiert, um mit den Transformers-Entwicklungen Schritt zu halten.
Schlüsselwörter: Adapter, LoRA, Parameter-effiziente Feinabstimmung, Hub
NeMo
NVIDIA NeMo ist für automatische Spracherkennung (ASR), Text-to-Speech-Synthese (TTS), große Sprachmodelle usw. konzipiert Konversations-KI-Toolkit zur Verarbeitung natürlicher Sprache, das von Forschern entwickelt wurde. Das Hauptziel von NeMo besteht darin, Forschern aus Industrie und Wissenschaft dabei zu helfen, frühere Arbeiten (Code und vorab trainierte Modelle) wiederzuverwenden und die Erstellung neuer Projekte zu erleichtern.
Schlüsselwörter: Konversation, ASR, TTS, LLM, NLP
Runhouse
Runhouse ermöglicht das Senden von Code und Daten in Python an jeden Computer oder die zugrunde liegenden Daten und funktioniert weiterhin normal mit vorhandenem Code und Umgebungen. Sie interagieren. Runhouse-Entwickler erwähnten:
Man kann es sich als Erweiterungspaket für den Python-Interpreter vorstellen, der Remote-Maschinen umgehen oder Remote-Daten bedienen kann.
Schlüsselwörter: MLOps, Infrastruktur, Datenspeicherung, Modellierung
MONAI
MONAI ist Teil des PyTorch-Ökosystems und ein auf PyTorch basierendes Open-Source-Framework für Deep Learning im Bereich der medizinischen Bildgebung. Seine Ziele sind:
- Aufbau einer gemeinsamen Gemeinschaft zwischen akademischen, industriellen und klinischen Forschern;
- Schaffung von SOTA, durchgängig geschulten Arbeitsabläufen für die medizinische Bildgebung; - Bietet Optimierungs- und Standardisierungsmethoden für die Erstellung und Bewertung von Deep-Learning-Modellen.
Schlüsselwörter: medizinische Bildgebung, Schulung, Bewertung
simpletransformers
Simple Transformers ermöglichen Ihnen das schnelle Training und Evaluieren von Transformer-Modellen. Zum Initialisieren, Trainieren und Auswerten des Modells sind nur drei Codezeilen erforderlich. Es unterstützt eine Vielzahl von NLP-Aufgaben. Schlüsselwörter: Framework, Einfachheit, NLP Aufgaben, die LLM vorgibt.Schlüsselwörter: LLM, Agent, HF Hub
transformers.js
transformers.js ist eine JavaScript-Bibliothek, die darauf abzielt, Modelle von Transformatoren direkt im Browser auszuführen.
Schlüsselwörter: Transformers, JavaScript, Browser
bumblebee
Schlüsselwörter: Elixir, Axon
argilla
Argilla ist eine Open-Source-Plattform, die erweiterte NLP-Kennzeichnung, Überwachung und Arbeitsbereiche bietet. Es ist mit vielen Open-Source-Ökosystemen wie Hugging Face, Stanza, FLAIR usw. kompatibel.Schlüsselwörter: NLP, Tags, Überwachung, Arbeitsbereich
haystack
Haystack ist ein Open-Source-NLP-Framework, das mithilfe von Transformer-Modellen und LLM mit Daten interagieren kann. Es bietet produktionsbereite Tools für die schnelle Erstellung komplexer Anwendungen für Entscheidungsfindung, Fragebeantwortung, semantische Suche, Textgenerierung und mehr.
Schlüsselwörter: NLP, Framework, LLM
SpaCy ist eine Bibliothek für die erweiterte Verarbeitung natürlicher Sprache in Python und Cython. Es basiert auf den neuesten Forschungsergebnissen und wurde von Grund auf für den Einsatz in realen Produkten entwickelt. Es bietet Unterstützung für das Transformers-Modell durch sein Drittanbieterpaket spacy-transformers.
Schlüsselwörter: NLP, Architektur

speechbrain
SpeechBrain ist ein Open-Source-Toolkit für integrierte Konversations-KI, das auf PyTorch basiert. Unser Ziel ist es, ein einziges, flexibles und benutzerfreundliches Toolkit zu erstellen, mit dem sich problemlos modernste Sprachtechnologien entwickeln lassen, darunter Spracherkennung, Sprecheridentifikation, Sprachverbesserung, Sprachtrennung, Spracherkennung und Multimikrofon Signalverarbeitung und andere Systeme.
Schlüsselwörter: Dialog, Sprache
skorch
Skorch ist eine neuronale Netzwerkbibliothek mit Scikit-Learn-Kompatibilität, die PyTorch umschließt. Es unterstützt Modelle in Transformers sowie Tokenizer von Tokenizern.
Schlüsselwörter: Scikit-Learning, PyTorch
bertviz
BertViz ist ein interaktives Tool zur Visualisierung der Aufmerksamkeit in Transformer-Sprachmodellen wie BERT, GPT2 oder T5. Es kann in Jupiter- oder Colab-Notebooks über eine einfache Python-API ausgeführt werden, die die meisten Huggingface-Modelle unterstützt. Schlüsselwörter: Visualisierung, Transformers
Diese Bibliothek ist für die Skalierung auf etwa 40B Parameter auf TPUv3 ausgelegt. Es handelt sich um eine Bibliothek zum Trainieren von GPT-J-Modellen.
Schlüsselwörter: Haiku, Modellparallelität, LLM, TPUdeepchem
Ein Open-Source-Softwarepaket (NRE) zur Extraktion neuronaler Beziehungen. Es richtet sich an ein breites Spektrum von Benutzern, vom Anfänger bis zum Entwickler, Forscher oder Studenten.
Schlüsselwörter: Extraktion neuronaler Beziehungen, Framework
pycorrectorEin Tool zur Fehlerkorrektur chinesischer Texte. Diese Methode nutzt Sprachmodellerkennungsfehler, Pinyin-Merkmale und Formmerkmale, um chinesische Textfehler zu korrigieren. Kann für chinesische Pinyin- und Stricheingabemethoden verwendet werden.
Schlüsselwörter: Chinesisch, Fehlerkorrekturtool, Sprachmodell, Pinyin
nlpaug
Diese Python-Bibliothek kann Ihnen helfen, NLP für maschinelle Lernprojekte zu verbessern. Es handelt sich um eine leichtgewichtige Bibliothek mit Funktionen zum Generieren synthetischer Daten zur Verbesserung der Modellleistung, unterstützt Audio und Text und ist mit mehreren Ökosystemen kompatibel (scikit-learn, pytorch, tensorflow).
Schlüsselwörter: Datenerweiterung, Generierung synthetischer Daten, Audio, Verarbeitung natürlicher Sprache
dream-textures
Schlüsselwörter: Microservices, Modellierung, Sprachpaketierung
open_model_zoo
Diese Bibliothek enthält optimierte Deep-Learning-Modelle und eine Reihe von Demos, um die Entwicklung leistungsstarker Deep-Learning-Inferenzanwendungen zu beschleunigen. Verwenden Sie diese kostenlosen vorab trainierten Modelle, anstatt Ihre eigenen zu trainieren, um Entwicklungs- und Produktionsbereitstellungsprozesse zu beschleunigen.
Schlüsselwörter: Optimierungsmodell, Demonstration
ml-stable-diffusion
ML-Stable-Diffusion ist ein Repository von Apple, das Core ML auf Apple-Chip-Geräten Unterstützung für stabile Diffusion bietet. Es unterstützt stabile Diffusionskontrollpunkte, die auf dem Hugging Face Hub gehostet werden. Schlüsselwörter: Stable Diffusion, Apple Chip, Core ML Leistung.
Schlüsselwörter: Text zu 3D, stabile Diffusion
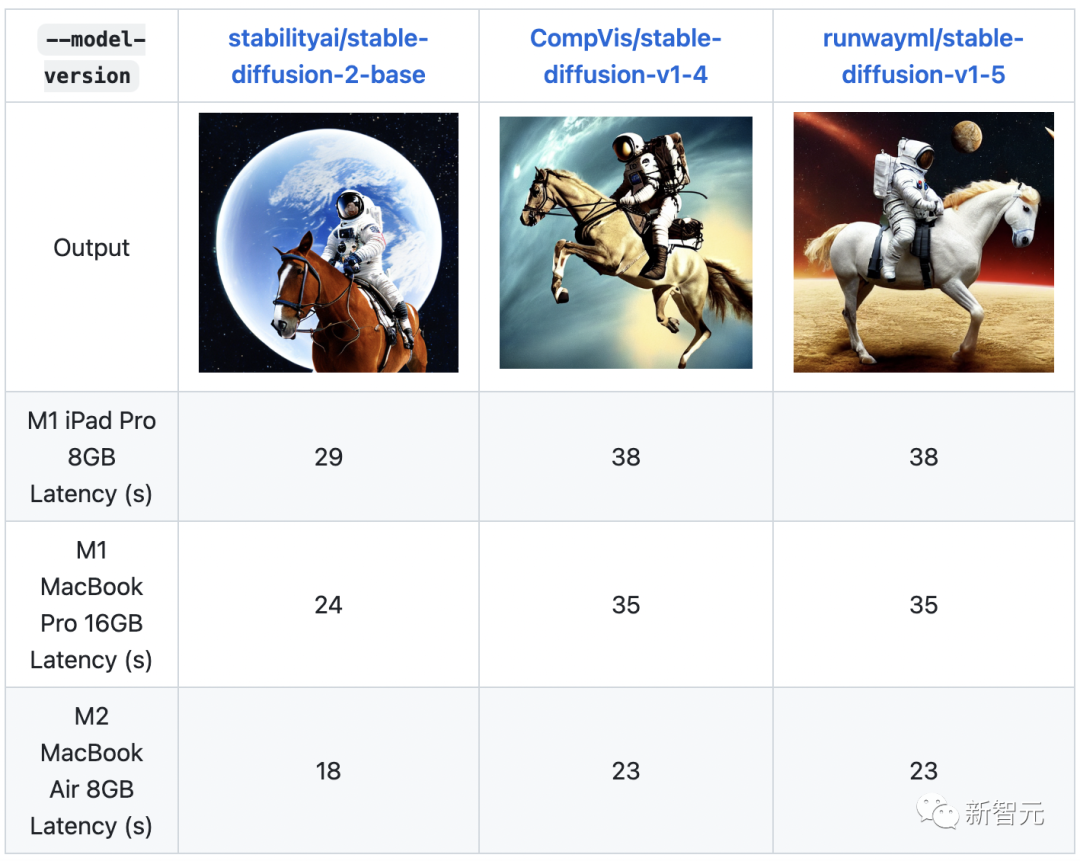
txtai
Txtai ist eine Open-Source-Plattform, die semantische Suche und sprachmodellgesteuerte Workflows unterstützt. Txtai erstellt eine eingebettete Datenbank, die eine Kombination aus Vektorindex und relationaler Datenbank ist und die SQL-Suche nach nächsten Nachbarn unterstützt. Semantische Workflows verbinden Sprachmodelle zu einheitlichen Anwendungen. Schlüsselwörter: Semantische Suche, LLM zu verwenden. DJL bietet native Java-Entwicklungserfahrung und funktioniert wie andere reguläre Java-Bibliotheken. DJL bietet Java-Bindungen für HuggingFace Tokenizer und ein einfaches Konvertierungs-Toolkit für die Bereitstellung von HuggingFace-Modellen in Java.
Schlüsselwörter: Java, Architektur

lm-evaluation-harness
Dieses Projekt bietet ein einheitliches Framework zum Testen generativer Sprachmodelle für eine große Anzahl verschiedener Bewertungsaufgaben. Es unterstützt mehr als 200 Aufgaben und unterstützt verschiedene Ökosysteme: HF Transformers, GPT-NeoX, DeepSpeed und OpenAI API.
Schlüsselwörter: LLM, Evaluierung, Few-Shot
gpt-neox

Stichwörter: Training, LLM, Megatron, DeepSpeed
muzicMuzic ist ein Forschungsprojekt zu Musik mit künstlicher Intelligenz, das durch Deep Learning und künstliche Intelligenz Musik verstehen und erzeugen kann. Muzic wurde von Forschern bei Microsoft Research Asia erstellt.
 Schlüsselwörter: Musikverständnis, Musikgenerierung
Schlüsselwörter: Musikverständnis, Musikgenerierung
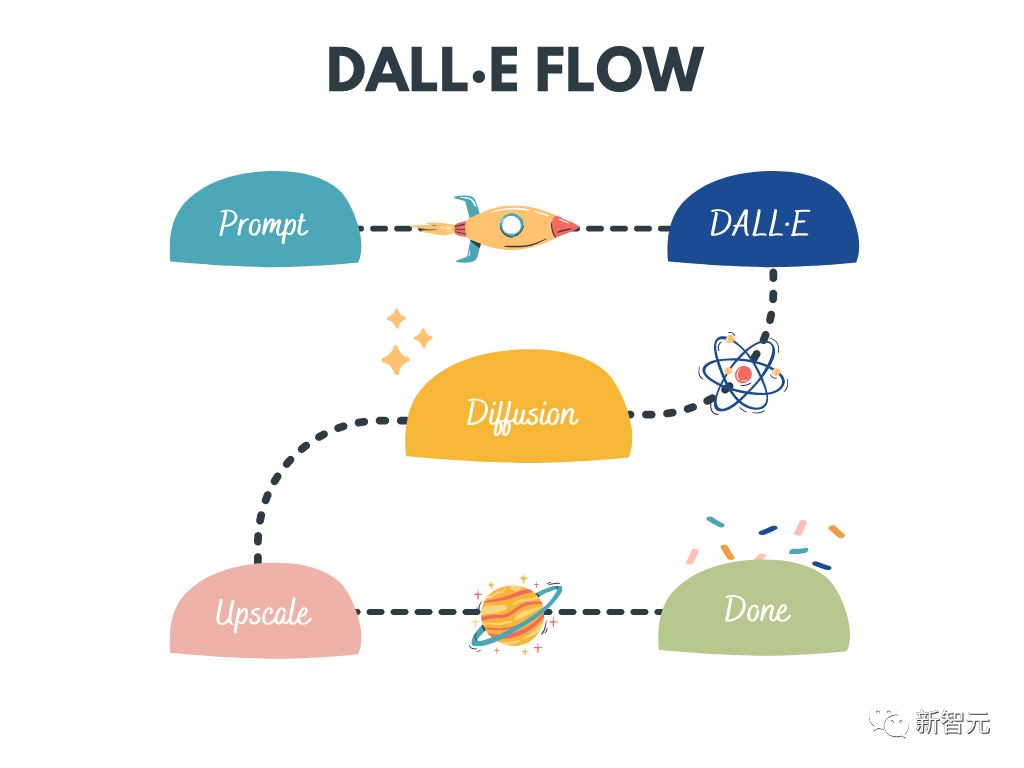
dalle-flow
DALL · E Flow ist ein interaktiver Workflow zum Generieren von HD-Bildern aus Texteingabeaufforderungen. Es verwendet DALL·E-Mega, GLID-3 XL und Stable Diffusion, um Kandidatenbilder zu generieren, und ruft dann CLIP-as-Service auf, um die Sortierung der Kandidatenbilder aufzufordern. Bevorzugte Kandidaten werden zur Diffusion an GLID-3 XL weitergeleitet, was häufig Texturen und Hintergründe bereichert. Abschließend wird der Kandidat über SwinIR auf 1024x1024 erweitert.
Schlüsselwörter: Hochauflösende Bilderzeugung, stabile Diffusion, DALL-E Mega, GLID-3 XL, CLIP, SwinIR
lightseq
LightSeq ist in CUDA für Sequenzen mit hoher Leistung implementiert Trainings- und Inferenzbibliothek für die Verarbeitung und Generierung. Es ist in der Lage, moderne NLP- und CV-Modelle wie BERT, GPT, Transformer usw. effizient zu berechnen. Daher ist es nützlich für maschinelle Übersetzung, Textgenerierung, Bildklassifizierung und andere sequenzbezogene Aufgaben.
Schlüsselwörter: Training, Inferenz, Sequenzverarbeitung, Sequenzgenerierung

LaTeX-OCR
Das Ziel dieses Projekts ist es, ein lernbasiertes System zu erstellen, das Bilder von mathematischen Formeln aufnimmt und gibt den entsprechenden LaTeX-Code zurück.
Schlüsselwörter: OCR, LaTeX, mathematische Formeln
open_clip
OpenCLIP ist eine Open-Source-Implementierung von OpenAIs CLIP.
Das Ziel dieses Repositorys ist es, Trainingsmodelle mit kontrastiver Bild-Text-Überwachung zu ermöglichen und ihre Eigenschaften wie Robustheit gegenüber Verteilungsverschiebungen zu untersuchen. Der Ausgangspunkt des Projekts ist eine Implementierung von CLIP, die beim Training mit demselben Datensatz der Genauigkeit des ursprünglichen CLIP-Modells entspricht.
Konkret erreichte ein ResNet-50-Modell, das auf der 15 Millionen Bildteilmenge YFCC von OpenAI als Codebasis trainiert wurde, die höchste Genauigkeit von 32,7 % auf ImageNet.
Schlüsselwörter: CLIP, Open Source, Vergleich, Bildtext

dalle-playground
Ein Spielplatz zum Generieren von Bildern aus jeder Textaufforderung mit Stable Diffusion und Dall-E mini. Schlüsselwörter: WebUI, Stable Diffusion, Dall-E Mini Lernen.
Schlüsselwörter: föderiertes Lernen, Analyse, kollaboratives maschinelles Lernen, dezentral
Das obige ist der detaillierte Inhalt vonDie Sternemarke hat 100.000 überschritten! Nach Auto-GPT erreicht Transformer einen neuen Meilenstein. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr