
Heim >Technologie-Peripheriegeräte >KI >Acht Probleme, die den Fortschritt der künstlichen Intelligenz behindern
Acht Probleme, die den Fortschritt der künstlichen Intelligenz behindern

- PHPznach vorne
- 2023-05-22 10:06:321988Durchsuche

Die heutige künstliche Intelligenz (KI) ist begrenzt. Es ist noch ein langer Weg.
Einige KI-Forscher haben herausgefunden, dass Algorithmen des maschinellen Lernens, bei denen Computer durch Versuch und Irrtum lernen, zu einer „mysteriösen Kraft“ geworden sind.
Verschiedene Arten künstlicher Intelligenz
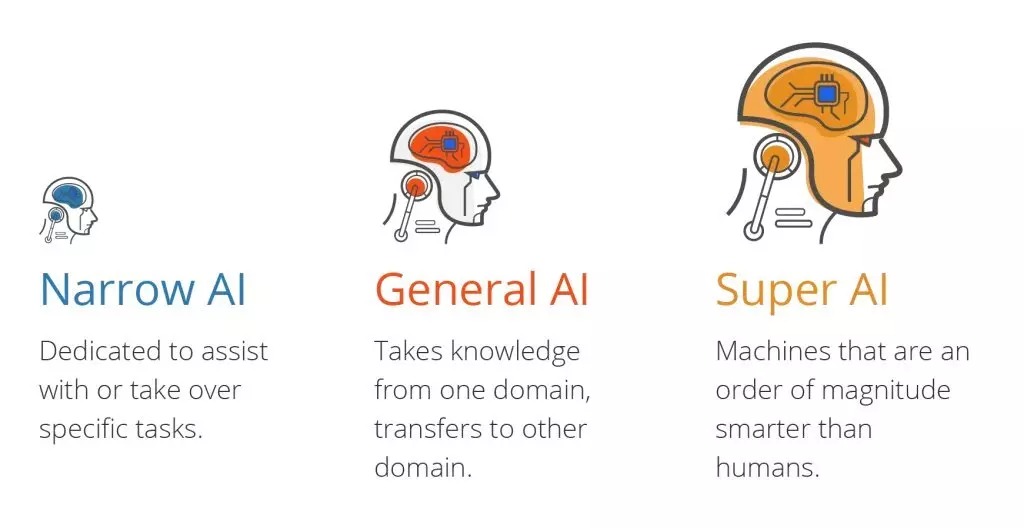
Die jüngsten Fortschritte in der künstlichen Intelligenz (KI) verbessern viele Aspekte unseres Lebens.
Es gibt drei Arten von künstlicher Intelligenz:
- Artificial Intelligence Narrow (ANI), die über einen engen Funktionsumfang verfügt.
- Allgemeine künstliche Intelligenz (AGI), entspricht den menschlichen Fähigkeiten.
- Künstliche Superintelligenz (ASI), intelligenter als Menschen.
Was stimmt heute nicht mit künstlicher Intelligenz?
Die heutige künstliche Intelligenz wird hauptsächlich durch statistische Lernmodelle und Algorithmen namens Datenanalyse, maschinelles Lernen, künstliche neuronale Netze oder Deep Learning angetrieben. Es wird als Kombination aus IT-Infrastruktur (ML-Plattform, Algorithmen, Daten, Berechnung) und Entwicklungsstack (von Bibliotheken bis hin zu Sprachen, IDEs, Workflows und Visualisierungen) implementiert.
Zusammenfassend umfasst es:
- Einige angewandte Mathematik, Wahrscheinlichkeitstheorie und Statistik
- Einige statistische Lernalgorithmen, logistische Regression, lineare Regression, Entscheidungsbäume und Zufallswälder
- Einige Algorithmen für maschinelles Lernen, überwacht, unüberwacht und Verstärkung
- Einige künstliche neuronale Netze, Deep-Learning-Algorithmen und Modelle zum Filtern von Eingabedaten über mehrere Ebenen, um Informationen vorherzusagen und zu klassifizieren.
- Einige optimierte (Komprimierung und Quantisierung) trainierte neuronale Netzmodelle.
- Einige statistische Muster und Schlussfolgerungen, wie z. B. das Qualcomm Neural Handling SDK ,
- Einige Programmiersprachen wie Python und R.
- Einige ML-Plattformen, Frameworks und Laufzeiten wie PyTorch, ONNX, Apache MXNet, TensorFlow, Caffe2, CNTK, SciKit-Learn und Keras,
- Einige integrierte Entwicklungsumgebung (IDE). ), wie PyCharm, Microsoft VS Code, Jupyter, MATLAB usw.,
- Einige physische Server, virtuelle Maschinen, Container, spezielle Hardware (wie GPU), Cloud-basierte Computerressourcen (einschließlich virtueller Maschinen, Container und serverloses Computing). ).
Die meisten heute verwendeten KI-Anwendungen können als schmale KI, sogenannte schwache KI, klassifiziert werden.
Allen mangelt es an allgemeiner künstlicher Intelligenz und maschinellem Lernen, die durch drei wichtige Interaktionsmaschinen definiert werden:
- Die Weltmodellmaschine [Darstellung, Lernen und Denken] oder der Realitätssimulator (das Welt-Hypergraphen-Netzwerk).
- World Knowledge Engine (Global Knowledge Graph)
- World Data Engine (Global Data Graph Network)
Der Unterschied zwischen allgemeinen KI- und ML- und DL-Anwendungen/Maschinen/Systemen besteht im Verständnis der Welt als mehrere plausible Weltzustandsdarstellungen , Seine Realitätsmaschine und globale Wissensmaschine und Weltdatenmaschine.
Es ist die wichtigste Komponente des General/Real AI Stack, interagiert mit seiner realen Daten-Engine und bietet intelligente Funktionen/Fähigkeiten:
- Informationen über die Welt verarbeiten
- Schätzen/berechnen/lernen Sie den Zustand von das Weltmodell
- Verallgemeinern Sie seine Datenelemente, Punkte, Mengen
- Spezifizieren Sie seine Datenstrukturen und -typen
- Übertragen Sie sein Lernen
- Kontextualisieren Sie seinen Inhalt
- Bilden/entdecken Sie kausale Datenmuster wie kausale Muster, Regeln und Regelmäßigkeiten
- Ableiten alle möglichen Wechselwirkungen, Ursachen, Wirkungen, Schleifen, Kausalbeziehungen in Systemen und Netzwerken
- Den Zustand der Welt in verschiedenen Bereichen und Maßstäben und auf verschiedenen Ebenen der Generalisierung und Spezifikation antizipieren/überprüfen
- Effektiv und effizient mit der Welt interagieren, sich anpassen zu ihm navigieren, darin navigieren und seine Umgebung gemäß seinen intelligenten Vorhersagen und Vorschriften manipulieren.
Tatsächlich handelt es sich hauptsächlich um eine statistische induktive Inferenzmaschine, die auf Big-Data-Computing, algorithmischer Innovation sowie statistischer Lerntheorie und konnektionistischer Philosophie basiert.
Für die meisten Menschen geht es lediglich darum, ein einfaches Modell für maschinelles Lernen (ML) zu erstellen, Daten zu sammeln, zu verwalten, zu erkunden, Features zu entwickeln, das Modell zu trainieren, zu bewerten und schließlich bereitzustellen.
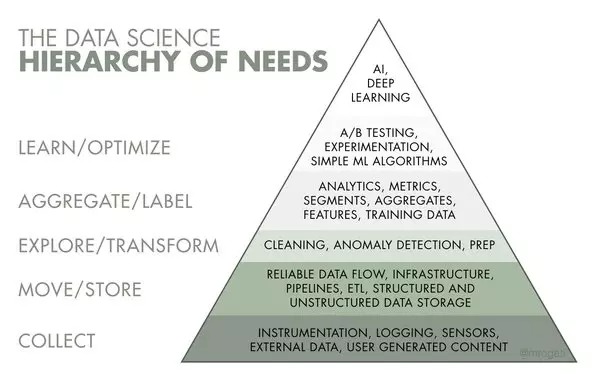
EDA: Explorative Datenanalyse
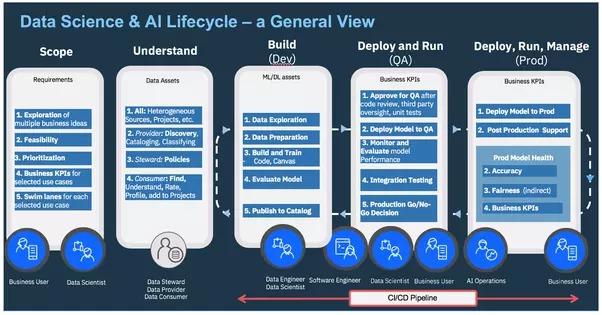
AI Ops – Verwaltung des End-to-End-Lebenszyklus von KI
Die heutigen KI-Fähigkeiten basieren auf „maschinellem Lernen“, das die Konfiguration und Optimierung von Algorithmen für jedes unterschiedliche Szenario in der realen Welt erfordert. Dies macht es sehr manuell und erfordert viel Zeit, um seine Entwicklung zu überwachen. Dieser manuelle Prozess ist außerdem fehleranfällig, ineffizient und schwer zu verwalten. Ganz zu schweigen von der mangelnden Fachkenntnis, verschiedene Arten von Algorithmen konfigurieren und optimieren zu können.
Konfiguration, Anpassung und Modellauswahl werden immer mehr automatisiert, und alle großen Technologieunternehmen wie Google, Microsoft, Amazon und IBM haben ähnliche AutoML-Plattformen eingeführt, um den Prozess der Modellerstellung für maschinelles Lernen zu automatisieren.
AutoML umfasst die Automatisierung der Aufgaben, die zum Erstellen von Vorhersagemodellen auf der Grundlage von Algorithmen für maschinelles Lernen erforderlich sind. Zu diesen Aufgaben gehören Datenbereinigung und -vorverarbeitung, Feature-Engineering, Feature-Auswahl, Modellauswahl und Hyperparameter-Tuning, deren manuelle Durchführung mühsam sein kann.
SAS4485-2020.pdf
Die vorgestellte End-to-End-ML-Pipeline besteht aus drei Schlüsselphasen, wobei die Quelle aller Daten, die Welt selbst, fehlt:
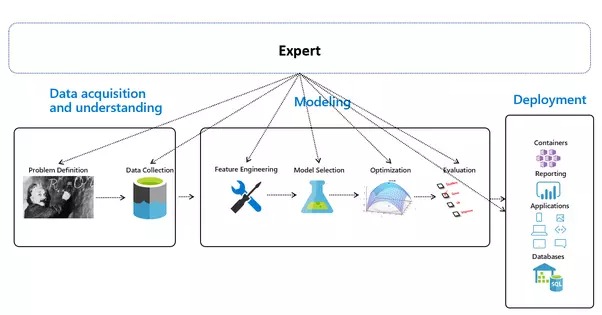
Automatisiertes maschinelles Lernen – Überblick
Das Schlüsselgeheimnis der Big-Tech-KI ist Skin-Deep Machine Learning als Dark-Deep-Neuronales Netzwerk. Sein Modell muss mithilfe einer großen Menge gekennzeichneter Daten und einer neuronalen Netzwerkarchitektur mit möglichst vielen Schichten trainiert werden.
Jede Aufgabe erfordert ihre spezielle Netzwerkarchitektur:
- Künstliche Neural Networks (ANN) für Regression und Klassifizierung
- Convolutional Neural Networks (CNN) für Computer Vision
- Für die Zeitreihenanalyse Recurrent Neural Network (RNN)
- Selbst- Organisieren von Karten für die Merkmalsextraktion
- Deep Boltzmann-Maschinen für Empfehlungssysteme
- Autoencoder für Empfehlungssysteme
ANN wurde als Informationsverarbeitungsparadigma eingeführt. Scheint von der Art und Weise inspiriert zu sein, wie biologische Nervensysteme/Gehirne Informationen verarbeiten. Und solche künstlichen neuronalen Netze werden als „universelle Funktionsnäherungen“ dargestellt, die verschiedene Aktivierungsfunktionen lernen/berechnen können.
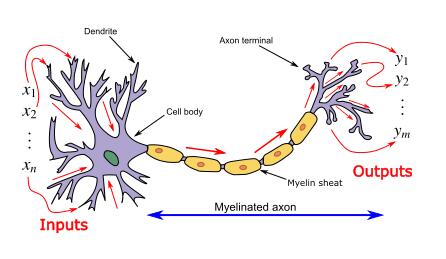
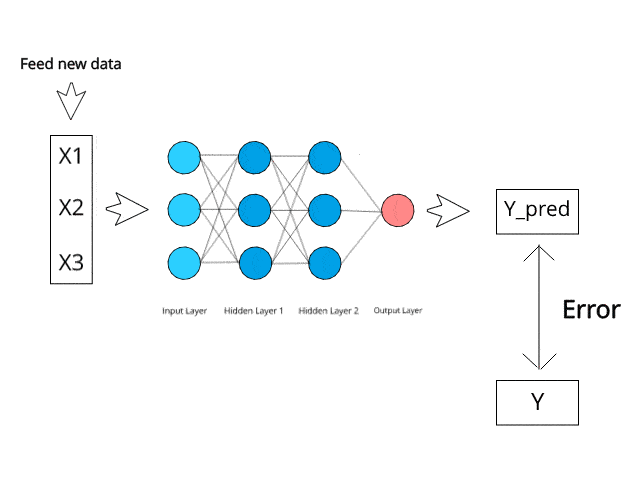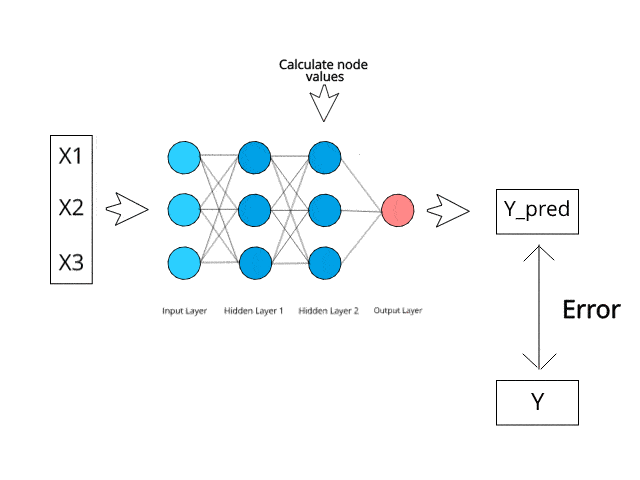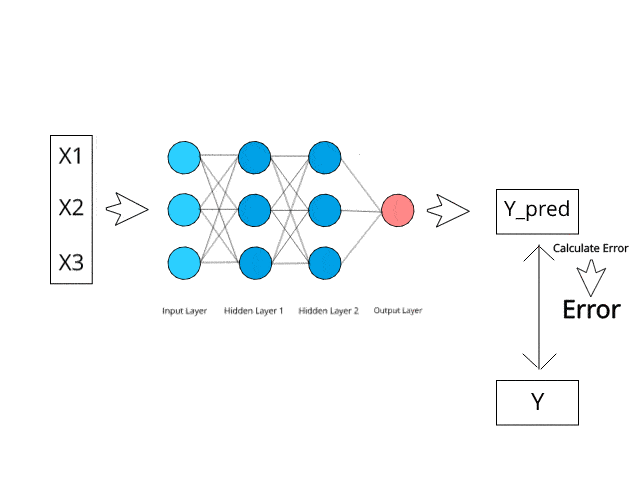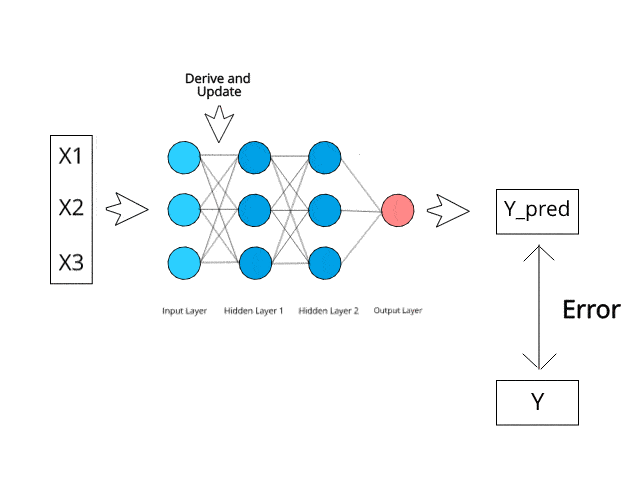
Das neuronale Netzwerk berechnet/lernt durch spezifische Backpropagation- und Fehlerkorrekturmechanismen während der Testphase.
Stellen Sie sich vor, durch die Minimierung von Fehlern könnten diese vielschichtigen Systeme eines Tages selbst lernen und Ideen konzipieren.
Einführung in künstliche neuronale Netze (KNN)
Alles in allem reichen ein paar Zeilen R- oder Python-Code aus, um maschinelle Intelligenz zu implementieren, und es gibt jede Menge Online-Ressourcen und Tutorials zum Trainieren quasi-neuronaler Netze, wie z.B. verschiedene Deepfake-Netzwerke, die Bilder – Videos – Audiotext manipulieren, ohne die Welt zu verstehen, wie Generative Adversarial Networks, BigGAN, CycleGAN, StyleGAN, GauGAN, Artbreeder, DeOldify usw.
Sie erstellen und modifizieren Gesichter, Landschaften, allgemeine Bilder usw., ohne zu verstehen, worum es geht.
Die Verwendung zykluskonsistenter gegnerischer Netzwerke für die ungepaarte Bild-zu-Bild-Übersetzung macht 2019 zum neuen KI-Zeitalter für 14 Anwendungen von Deep Learning und maschinellem Lernen.
Es gibt unzählige digitale Tools und Frameworks, die auf ihre eigene Weise funktionieren:
- Offene Sprachen – Python ist am beliebtesten, R und Scala gehören auch dazu.
- Offenes Framework – Scikit-learn, XGBoost, TensorFlow usw.
- Methoden und Techniken – Klassische ML-Techniken von der Regression bis hin zu hochmodernen GANs und RL
- Produktivitätssteigernde Funktionen – Visuelle Modellierung, AutoAI zur Unterstützung bei Feature Engineering, Algorithmenauswahl und Hyperparameteroptimierung
- Entwicklungstools – — DataRobot, H2O, Watson Studio, Azure ML Studio, Sagemaker, Anaconda und mehr.
Es ist eine Schande, dass Datenwissenschaftler arbeiten in: scikit-learn, R, SparkML, Jupyter, R, Python, XGboost, Hadoop, Spark, TensorFlow, Keras, PyTorch, Docker, Plumbr, und die Liste geht weiter und weiter. .
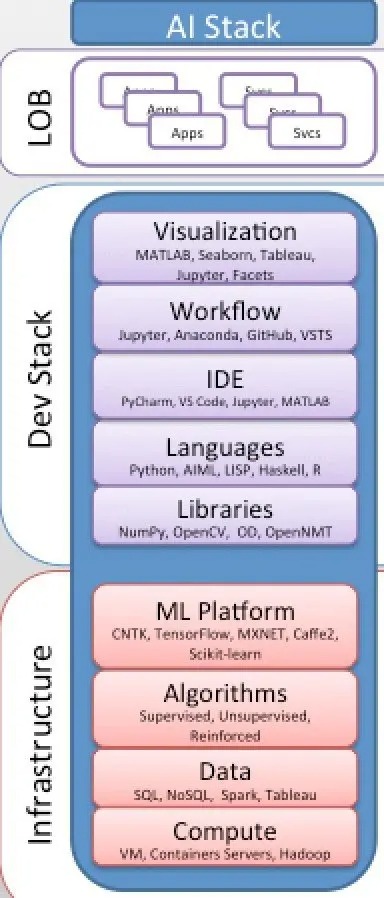
Moderner KI-Stack und AI-as-a-Service-Verbrauchsmodell
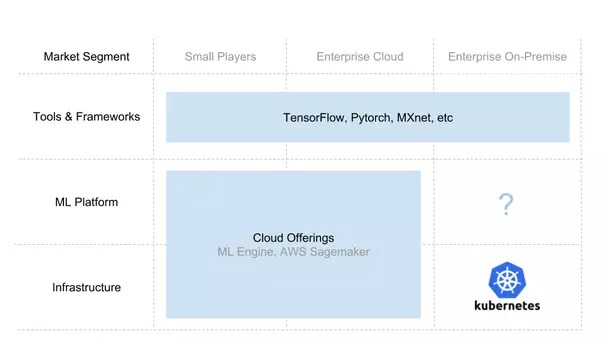
Aufbau eines KI-Stacks
Was vorgibt, künstliche Intelligenz zu sein, ist in Wirklichkeit gefälschte künstliche Intelligenz. Im besten Fall handelt es sich um eine automatische Lerntechnik, einen ML/DL/NN-Mustererkenner mathematischer und statistischer Natur, der nicht in der Lage ist, intuitiv zu handeln oder seine Umgebung zu modellieren, ohne Intelligenz, ohne Lernen und ohne Verständnis.
Probleme, die den Fortschritt der künstlichen Intelligenz behindern
Trotz ihrer vielen Vorteile ist künstliche Intelligenz nicht perfekt. Hier sind 8 Probleme, die den Fortschritt der künstlichen Intelligenz behindern, und was sind die grundlegenden Fehler:
1 Mangel an Daten
KI erfordert große Datensätze für das Training, und diese Datensätze sollten inklusiv/unvoreingenommen und von guter Qualität sein. Manchmal müssen sie warten, bis neue Daten generiert werden.
2. Zeitaufwändig
Künstliche Intelligenz benötigt genügend Zeit, damit der Algorithmus lernen und sich ausreichend entwickeln kann, um seinen Zweck mit beträchtlicher Genauigkeit und Relevanz zu erreichen. Es erfordert auch erhebliche Ressourcen, um zu funktionieren. Dies kann zusätzliche Anforderungen an Ihre Computerkenntnisse mit sich bringen.
3. Schlechte Interpretation der Ergebnisse
Eine weitere große Herausforderung ist die Fähigkeit, die von einem Algorithmus generierten Ergebnisse sorgfältig auszuwählen.
4. Sehr fehleranfällig
Künstliche Intelligenz ist autonom, aber sehr fehleranfällig. Angenommen, der Algorithmus wird auf einem Datensatz trainiert, der klein genug ist, um ihn nicht inklusiv zu machen. Am Ende erhält man verzerrte Vorhersagen aus einem verzerrten Trainingssatz. Beim maschinellen Lernen können solche Fehltritte eine Kaskade von Fehlern auslösen, die lange Zeit unentdeckt bleiben können. Wenn sie bemerkt werden, kann es einige Zeit dauern, die Ursache des Problems zu identifizieren, und noch länger, es zu beheben.
5. Ethische Fragen
Die Idee, Daten und Algorithmen über unser eigenes Urteil zu vertrauen, hat seine Vor- und Nachteile. Natürlich profitieren wir von diesen Algorithmen, sonst würden wir sie gar nicht erst nutzen. Diese Algorithmen ermöglichen es uns, Prozesse zu automatisieren, indem wir anhand der verfügbaren Daten fundierte Urteile fällen. Manchmal bedeutet dies jedoch, den Job einer Person durch einen Algorithmus zu ersetzen, was ethische Konsequenzen hat. Und wem sollen wir die Schuld geben, wenn etwas schiefgeht?
6. Mangel an technischen Ressourcen
Künstliche Intelligenz ist noch eine relativ neue Technologie. Für die Aufrechterhaltung des Prozesses werden Experten für maschinelles Lernen benötigt, vom Startup-Code bis zur Wartung und Überwachung des Prozesses. Die Branche der künstlichen Intelligenz und des maschinellen Lernens ist noch relativ neu auf dem Markt. Es ist auch schwierig, angemessene Ressourcen in menschlicher Form zu finden. Daher mangelt es an talentierten Vertretern, die wissenschaftliches Material zum maschinellen Lernen entwickeln und verwalten können. Datenforscher benötigen oft von Anfang bis Ende eine Mischung aus räumlichen Erkenntnissen sowie mathematischen, technischen und naturwissenschaftlichen Kenntnissen.
7. Unzureichende Infrastruktur
Künstliche Intelligenz erfordert viele Datenverarbeitungsfähigkeiten. Vererbungsframeworks können unter Druck nicht mit Verantwortlichkeiten und Einschränkungen umgehen. Die Infrastruktur sollte auf ihre Bewältigung der KI-Probleme überprüft werden. Wenn nicht, sollte sie komplett mit guter Hardware und anpassbarem Speicher aufgerüstet werden.
8. Langsame Ergebnisse und Voreingenommenheit
Künstliche Intelligenz ist sehr zeitaufwändig. Aufgrund der Daten- und Anforderungsüberlastung dauert die Bereitstellung der Ergebnisse länger als erwartet. Die Konzentration auf bestimmte Funktionen in einer Datenbank zur Verallgemeinerung der Ergebnisse ist bei Modellen für maschinelles Lernen üblich, was zu Verzerrungen führen kann.
Fazit
Künstliche Intelligenz hat viele Aspekte unseres Lebens übernommen. Obwohl künstliche Intelligenz nicht perfekt ist, ist sie ein wachsendes Feld und sehr gefragt. Es liefert Echtzeitergebnisse unter Verwendung bereits vorhandener und verarbeiteter Daten ohne menschliches Eingreifen. Es hilft bei der Analyse und Auswertung großer Datenmengen, häufig durch die Entwicklung datengesteuerter Modelle. Obwohl es viele Probleme mit der künstlichen Intelligenz gibt, handelt es sich um ein sich entwickelndes Feld. Von der medizinischen Diagnose über die Impfstoffentwicklung bis hin zu fortschrittlichen Handelsalgorithmen ist künstliche Intelligenz zum Schlüssel für den wissenschaftlichen Fortschritt geworden.
Das obige ist der detaillierte Inhalt vonAcht Probleme, die den Fortschritt der künstlichen Intelligenz behindern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr