
Heim >Technologie-Peripheriegeräte >KI >Wie kann man Reinforcement Learning nutzen, um die Benutzerbindung von Kuaishou zu verbessern?
Wie kann man Reinforcement Learning nutzen, um die Benutzerbindung von Kuaishou zu verbessern?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-07 18:31:082254Durchsuche
Das Hauptziel des Kurzvideo-Empfehlungssystems besteht darin, das DAU-Wachstum durch eine verbesserte Benutzerbindung voranzutreiben. Daher ist die Kundenbindung einer der wichtigsten Indikatoren für die Geschäftsoptimierung jeder APP. Bei der Aufbewahrung handelt es sich jedoch um ein langfristiges Feedback nach mehreren Interaktionen zwischen Benutzern und dem System, und es ist schwierig, es in ein einzelnes Element oder eine einzelne Liste zu zerlegen. Daher ist es für herkömmliche punktweise und listenweise Modelle schwierig, es direkt zu erfassen Optimieren Sie die Bindung.
Die Methode des Reinforcement Learning (RL) optimiert langfristige Belohnungen durch Interaktion mit der Umgebung und eignet sich zur direkten Optimierung der Nutzerbindung. Diese Arbeit modelliert das Aufbewahrungsoptimierungsproblem als Markov-Entscheidungsprozess (MDP) mit unendlicher Horizontanforderungsgranularität. Jedes Mal, wenn der Benutzer das Empfehlungssystem auffordert, über eine Aktion zu entscheiden, wird es verwendet, um mehrere verschiedene kurzfristige Feedbackschätzungen zu aggregieren (Beobachtungsdauer, Likes, Follows, Kommentare, Retweets usw.) Ranking-Modellbewertung. Das Ziel dieser Arbeit besteht darin, die Richtlinie zu erlernen, das kumulative Zeitintervall zwischen mehreren Benutzersitzungen zu minimieren, die Häufigkeit von App-Öffnungen zu erhöhen und dadurch die Benutzerbindung zu erhöhen.
Aufgrund der Eigenschaften des zurückgehaltenen Signals bringt die direkte Anwendung des vorhandenen RL-Algorithmus jedoch die folgenden Herausforderungen mit sich: 1) Unsicherheit: Das zurückgehaltene Signal ist nicht nur wird durch den Empfehlungsalgorithmus bestimmt, wird aber auch von vielen Faktoren beeinflusst. 2) Verzerrung: Bei unterschiedlichen Zeiträumen und Benutzergruppen gibt es Abweichungen. 3) Instabilität: Im Gegensatz zu Spielumgebungen, die sofort Belohnungen zurückgeben Retentionssignale kehren normalerweise innerhalb von Stunden bis Tagen zurück, was zu Instabilitätsproblemen beim Online-Training von RL-Algorithmen führt.
Diese Arbeit schlägt den Reinforcement Learning for User Retention-Algorithmus (RLUR) vor, um die oben genannten Herausforderungen zu lösen und die Bindung direkt zu optimieren. Durch Offline- und Online-Verifizierung kann der RLUR-Algorithmus den sekundären Aufbewahrungsindex im Vergleich zum State-of-Art-Basiswert deutlich verbessern. Der RLUR-Algorithmus wurde vollständig in der Kuaishou-App implementiert und kann kontinuierlich erhebliche Sekundärbindungs- und DAU-Umsätze erzielen. Es ist das erste Mal in der Branche, dass die RL-Technologie zur Verbesserung der Benutzerbindung in einer realen Produktionsumgebung eingesetzt wird. Diese Arbeit wurde in den WWW 2023 Industry Track aufgenommen.

Autor: Cai Qingqian, Liu Shuchang, Wang Xueliang, Zuo Tianyou, Xie Wentao, Yang Bin, Zheng Dong, Jiang Peng
Papieradresse: https://arxiv.org/pdf/2302.01724.pdf#🎜🎜 ##🎜 🎜#Problemmodellierung
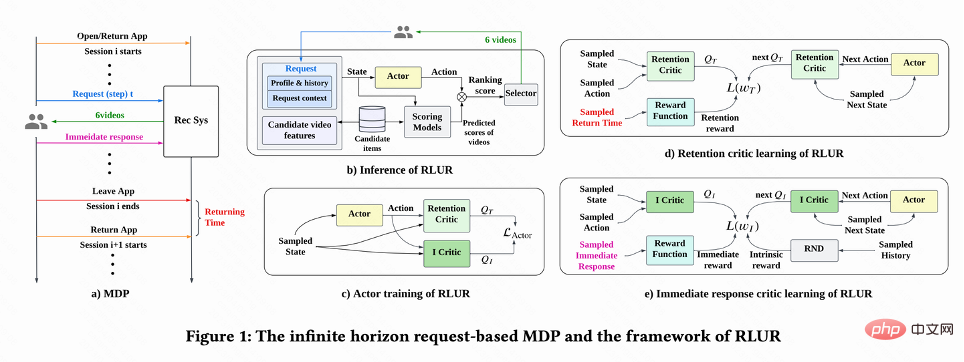
Wie in Abbildung 1(a) dargestellt, modelliert diese Arbeit das Problem der Aufbewahrungsoptimierung als unendlich Horizont Anforderungsgranularität Markov-Entscheidungsprozess (Infinite Horizon Request-based Markov Decision Process), bei dem das Empfehlungssystem der Agent und der Benutzer die Umgebung ist. Jedes Mal, wenn der Benutzer die App öffnet, wird eine neue Sitzung geöffnet. Wie in Abbildung 1(b) dargestellt, entscheidet das Empfehlungssystem jedes Mal, wenn der Benutzer
anfordert, über einen Parametervektor  #🎜 basierend auf dem Benutzerstatus #🎜 🎜# 🎜#
#🎜 basierend auf dem Benutzerstatus #🎜 🎜# 🎜# , während n Ranking-Modelle, die verschiedene kurzfristige Indikatoren (Sehzeit, Likes, Aufmerksamkeit usw.) schätzen, jedes Kandidatenvideo j#🎜🎜 bewerten #. Dann gibt die Sortierfunktion die Aktion und den Bewertungsvektor jedes Videos ein, um die Endbewertung jedes Videos zu erhalten, und wählt die 6 Videos mit der höchsten Bewertung aus, die dem Benutzer angezeigt werden sollen. Der Benutzer gibt sofortiges Feedback zurück
, während n Ranking-Modelle, die verschiedene kurzfristige Indikatoren (Sehzeit, Likes, Aufmerksamkeit usw.) schätzen, jedes Kandidatenvideo j#🎜🎜 bewerten #. Dann gibt die Sortierfunktion die Aktion und den Bewertungsvektor jedes Videos ein, um die Endbewertung jedes Videos zu erhalten, und wählt die 6 Videos mit der höchsten Bewertung aus, die dem Benutzer angezeigt werden sollen. Der Benutzer gibt sofortiges Feedback zurück . Wenn der Benutzer die App verlässt, endet die Sitzung. Wenn der Benutzer die App das nächste Mal öffnet, wird die Sitzung i+1 geöffnet. Das Zeitintervall zwischen dem Ende der vorherigen Sitzung und dem Beginn der nächsten Sitzung wird als Rückkehrzeit bezeichnet Zeit),
. Wenn der Benutzer die App verlässt, endet die Sitzung. Wenn der Benutzer die App das nächste Mal öffnet, wird die Sitzung i+1 geöffnet. Das Zeitintervall zwischen dem Ende der vorherigen Sitzung und dem Beginn der nächsten Sitzung wird als Rückkehrzeit bezeichnet Zeit),  . Das Ziel dieser Forschung besteht darin, eine Strategie zu trainieren, die die Summe der Rückrufzeiten für mehrere Sitzungen minimiert.
. Das Ziel dieser Forschung besteht darin, eine Strategie zu trainieren, die die Summe der Rückrufzeiten für mehrere Sitzungen minimiert. 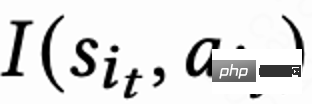
RLUR-Algorithmus
In dieser Arbeit wird zunächst erörtert, wie die kumulative Wiederbesuchszeit geschätzt werden kann, und dann werden Methoden zur Lösung mehrerer Probleme vorgeschlagen Probleme der zurückgehaltenen Signale. Schlüsselherausforderungen. Diese Methoden werden im Reinforcement Learning for User Retention-Algorithmus zusammengefasst, abgekürzt als RLUR. Wie in Abbildung 1 gezeigt( d) Wie in der Abbildung gezeigt, verwendet diese Arbeit die Zeitdifferenz-Lernmethode (TD) des DDPG-Algorithmus, um die Zeit des erneuten Besuchs abzuschätzen, da die Aktionen kontinuierlich sind.
Da jede Sitzung nur eine Rückbesuchszeitbelohnung für die letzte Anfrage hat, ist die Zwischenbelohnung ist 0. Der Autor legt den Rabattfaktor
für die letzte Anfrage in jeder Sitzung auf
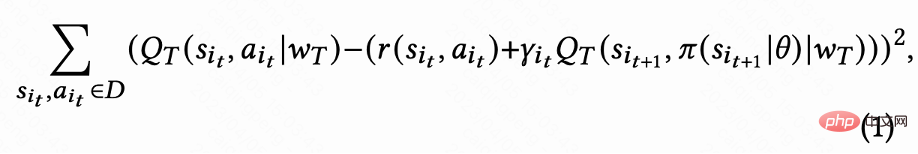 fest, und für andere Anfragen ist er 1 . Mit dieser Einstellung kann der exponentielle Abfall der Wiederbesuchszeit vermieden werden. Und es kann theoretisch bewiesen werden, dass Q tatsächlich die kumulative Wiederbesuchszeit mehrerer Sitzungen schätzt, wenn Verlust (1) 0 ist,
fest, und für andere Anfragen ist er 1 . Mit dieser Einstellung kann der exponentielle Abfall der Wiederbesuchszeit vermieden werden. Und es kann theoretisch bewiesen werden, dass Q tatsächlich die kumulative Wiederbesuchszeit mehrerer Sitzungen schätzt, wenn Verlust (1) 0 ist,
. #? 🎜#Da der Rückbesuch erst am Ende jeder Sitzung stattfindet, führt dies zu dem Problem einer geringen Lerneffizienz. Die Autoren verwenden daher heuristische Belohnungen, um das politische Lernen zu verbessern. Da kurzfristiges Feedback positiv mit der Bindung zusammenhängt, verwendet der Autor kurzfristiges Feedback als erste heuristische Belohnung. Und der Autor verwendet das Random Network Distillation (RND)-Netzwerk, um die intrinsische Belohnung jeder Probe als zweite heuristische Belohnung zu berechnen. Insbesondere verwendet das RND-Netzwerk zwei identische Netzwerkstrukturen. Ein Netzwerk wird zufällig auf Festnetz initialisiert, und das andere Netzwerk passt sich dem Festnetz an, und der Anpassungsverlust wird als intrinsische Belohnung verwendet. Wie in Abbildung 1 (e) gezeigt, lernt diese Arbeit ein separates Kritikernetzwerk, um die Summe aus kurzfristigem Feedback und intrinsischer Belohnung zu schätzen, um die Beeinträchtigung heuristischer Belohnungen auf Bindungsbelohnungen zu verringern. Das ist  .
. 
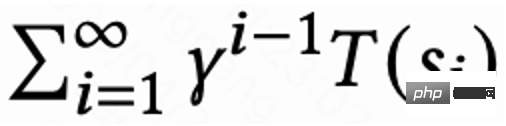 Das Problem der Unsicherheit lösen
Das Problem der Unsicherheit lösen
# 🎜🎜#Da die Zeit des Rückbesuchs von vielen anderen Faktoren als den Empfehlungen beeinflusst wird, ist die Unsicherheit hoch, was sich auf den Lerneffekt auswirkt. Diese Arbeit schlägt eine Regularisierungsmethode vor, um die Varianz zu reduzieren: Schätzen Sie zunächst ein Klassifizierungsmodell , um die Wahrscheinlichkeit der Wiederbesuchszeit abzuschätzen, dh ob die geschätzte Wiederbesuchszeit kürzer als #🎜 ist 🎜##🎜 🎜# Verwenden Sie dann die Markov-Ungleichung, um die Untergrenze der Rückbesuchszeit zu ermitteln,
; Verwenden Sie schließlich die tatsächliche Rückbesuchszeit/geschätzte Rückkehr Untergrenze der Besuchszeit als regulierte Gegenbesuchsprämie. 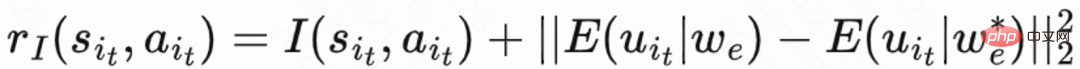
aufgrund unterschiedliche Aktivitäten Die Verhaltensgewohnheiten hochaktiver Benutzer sind sehr unterschiedlich und die Anzahl der Trainingsproben ist deutlich höher als die von niedrig aktiven Benutzern hochaktive Benutzer. Um dieses Problem zu lösen, erlernt diese Arbeit zwei unabhängige Strategien für verschiedene Gruppen mit hoher und niedriger Aktivität und verwendet unterschiedliche Datenströme für das Training. Der Schauspieler minimiert die Rückbesuchszeit und maximiert gleichzeitig die Zusatzbelohnung. Wie in Abbildung 1(c) dargestellt, beträgt der Akteurverlust am Beispiel der Gruppe mit hoher Aktivität:
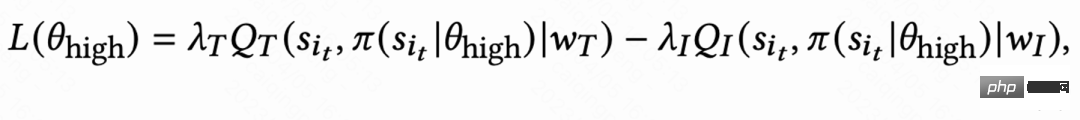
Lösen Sie das Instabilitätsproblem
Aufgrund der Signalverzögerung der Rückbesuchszeit kehrt sie normalerweise innerhalb weniger Stunden bis zu mehreren Tagen zurück, was dazu führt, dass das RL-Online-Training instabil wird. Die direkte Verwendung vorhandener Methoden zum Klonen von Verhalten schränkt entweder die Lerngeschwindigkeit erheblich ein oder kann kein stabiles Lernen garantieren. Daher schlägt diese Arbeit eine neue sanfte Regularisierungsmethode vor, die darin besteht, den Akteurverlust mit einem weichen Regularisierungskoeffizienten zu multiplizieren: Wenn die Strategie und die Beispielstrategie groß sind, wird der Verlust kleiner und das Lernen stabiler. Wenn die Lerngeschwindigkeit stabil wird, wird der Verlust wieder größer und die Lerngeschwindigkeit beschleunigt sich. Wenn
, bedeutet dies, dass es keine Einschränkungen für den Lernprozess gibt.
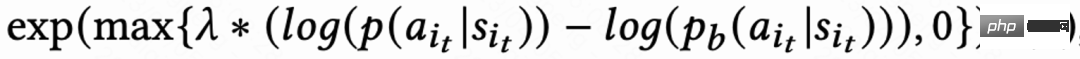
Diese Arbeit vergleicht RLUR mit dem Reinforcement-Learning-Algorithmus TD3 von State of the Art und der Black-Box-Optimierungsmethode Cross Entropy Method (CEM) am öffentlichen Datensatz KuaiRand. In dieser Arbeit wird zunächst ein Aufbewahrungssimulator erstellt, der auf dem KuaiRand-Datensatz basiert und drei Module umfasst: unmittelbares Feedback des Benutzers, Verlassen der Sitzung durch Benutzer und erneuter Besuch der App durch den Benutzer. Anschließend wird diese Bewertungsmethode des Aufbewahrungssimulators verwendet. 
und
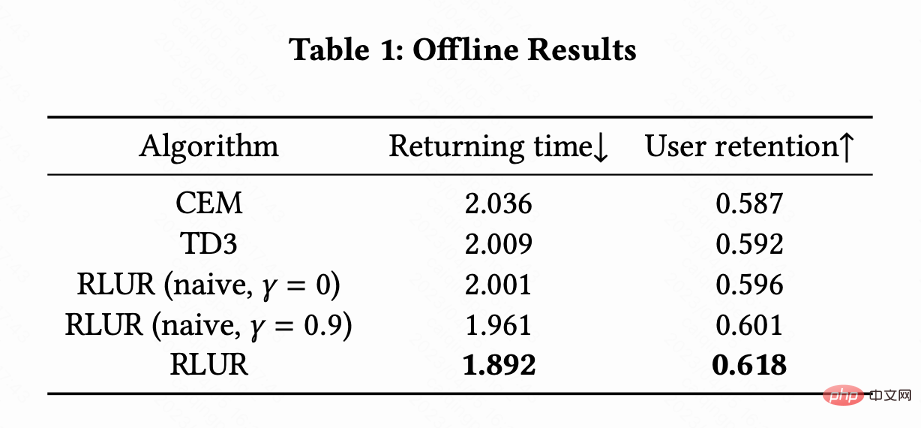 wird gezeigt, dass der Algorithmus zur Minimierung der Rückbesuchszeit mehrerer Sitzungen besser ist als die Minimierung der Rückbesuchszeit einer einzelnen Sitzung.
wird gezeigt, dass der Algorithmus zur Minimierung der Rückbesuchszeit mehrerer Sitzungen besser ist als die Minimierung der Rückbesuchszeit einer einzelnen Sitzung.
Online-Experiment
 Diese Arbeit führt A/B-Tests auf dem Kuaishou-Kurzvideoempfehlungssystem durch, um RLUR- und CEM-Methoden zu vergleichen. Abbildung 2 zeigt die Verbesserungsprozentsätze der App-Öffnungshäufigkeit, DAU, Erstbindung und Siebtbindung im Vergleich zu RLUR bzw. CEM. Es lässt sich feststellen, dass die Häufigkeit der App-Öffnungen allmählich zunimmt und sich sogar von 0 auf 100 Tage annähert. Es führt auch zu Verbesserungen bei den Zweitbindungs-, Siebtenbindungs- und DAU-Indikatoren (0,1 % DAU und 0,01 % Zweitbindungsverbesserung gelten als statistisch signifikant).
Diese Arbeit führt A/B-Tests auf dem Kuaishou-Kurzvideoempfehlungssystem durch, um RLUR- und CEM-Methoden zu vergleichen. Abbildung 2 zeigt die Verbesserungsprozentsätze der App-Öffnungshäufigkeit, DAU, Erstbindung und Siebtbindung im Vergleich zu RLUR bzw. CEM. Es lässt sich feststellen, dass die Häufigkeit der App-Öffnungen allmählich zunimmt und sich sogar von 0 auf 100 Tage annähert. Es führt auch zu Verbesserungen bei den Zweitbindungs-, Siebtenbindungs- und DAU-Indikatoren (0,1 % DAU und 0,01 % Zweitbindungsverbesserung gelten als statistisch signifikant).
Diese Arbeit untersucht, wie die Benutzerbindung von Empfehlungssystemen durch RL-Technologie verbessert werden kann. Diese Arbeit modelliert die Aufbewahrungsoptimierung als Markov-Entscheidungsprozess mit unendlicher Horizont-Anforderungsgranularität Optimieren Sie die Signalspeicherung direkt und bewältigen Sie effektiv mehrere wichtige Herausforderungen der Signalspeicherung. Der RLUR-Algorithmus wurde vollständig in der Kuaishou-App implementiert und kann erhebliche sekundäre Bindungs- und DAU-Umsätze erzielen. Im Hinblick auf zukünftige Arbeiten ist die Frage, wie man Offline-Reinforcement Learning, Decision Transformer und andere Methoden nutzen kann, um die Benutzerbindung effektiver zu verbessern, eine vielversprechende Richtung. 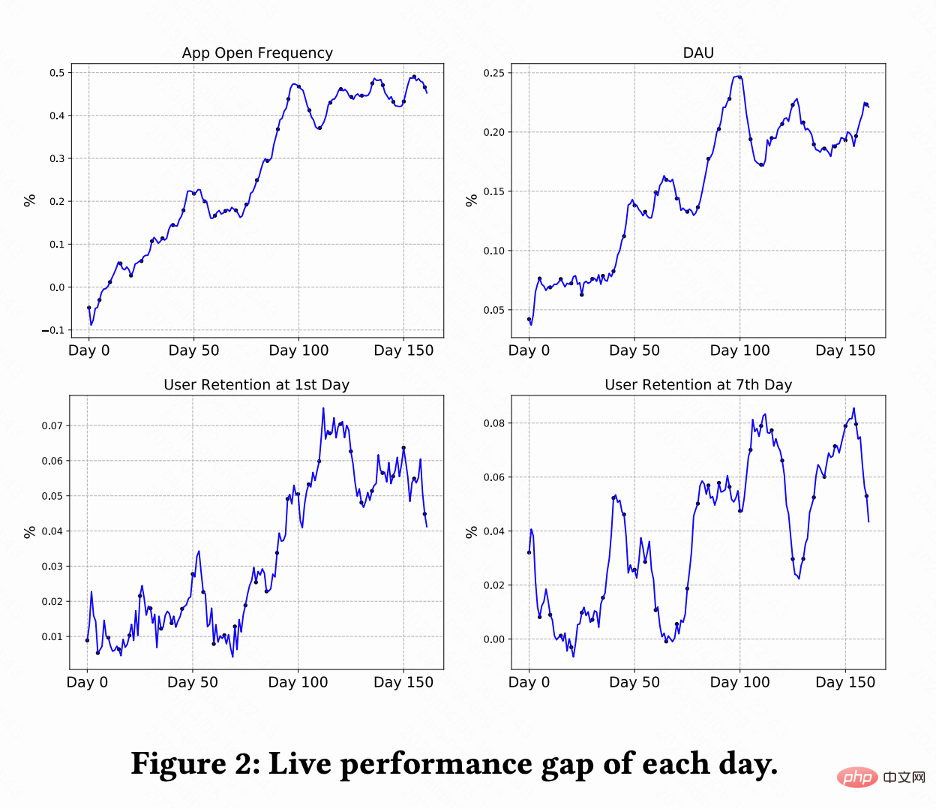
Das obige ist der detaillierte Inhalt vonWie kann man Reinforcement Learning nutzen, um die Benutzerbindung von Kuaishou zu verbessern?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr