
Heim >Technologie-Peripheriegeräte >KI >Eine offene Umgebungslösung, die Mängel wie die Batch-Norm-Schicht behebt
Eine offene Umgebungslösung, die Mängel wie die Batch-Norm-Schicht behebt

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-26 10:01:07853Durchsuche
Die Test-Time Adaptation (TTA)-Methode leitet das Modell an, während der Testphase schnelles unbeaufsichtigtes/selbstüberwachtes Lernen durchzuführen. Sie ist derzeit ein leistungsstarkes und effektives Werkzeug zur Verbesserung der Out-of-Distribution-Generalisierungsfähigkeiten von Deep Modelle. In dynamischen offenen Szenarien ist jedoch die unzureichende Stabilität immer noch ein großer Mangel bestehender TTA-Methoden, der ihren praktischen Einsatz erheblich behindert. Zu diesem Zweck analysierte ein Forschungsteam der South China University of Technology, des Tencent AI Lab und der National University of Singapore aus einer einheitlichen Perspektive die Gründe, warum die bestehende TTA-Methode in dynamischen Szenarien instabil ist, und wies darauf hin, dass die Normalisierungsschicht darauf beruht on Batch führt zu Instabilität. Darüber hinaus können einige Proben mit Rauschen/großen Gradienten im Testdatenstrom das Modell leicht auf eine degenerierte triviale Lösung optimieren. Auf dieser Grundlage wird weiterhin eine schärfeempfindliche und zuverlässige Testzeit-Entropieminimierungsmethode SAR vorgeschlagen, um eine stabile und effiziente Online-Migration und Generalisierung von Testzeitmodellen in dynamischen offenen Szenarien zu erreichen. Diese Arbeit wurde in die mündliche Prüfung ICLR 2023 aufgenommen (Top 5 % der akzeptierten Arbeiten).

- Papiertitel: Towards Stable Test-time Adaptation in Dynamic Wild World# 🎜🎜#
- Papieradresse: https://openreview.net/forum?id=g2YraF75Tj#🎜🎜 #
- Offener Quellcode: https://github.com/mr-eggplant/SAR Was ist Test? Zeitanpassung?
Online-Migration erreicht werden, die effizienter und universeller ist. Darüber hinaus kann die vollständige Testzeit-Anpassungsmethode [2] an jedes vorab trainierte Modell angepasst werden, ohne dass Original-Trainingsdaten erforderlich sind oder der ursprüngliche Trainingsprozess des Modells beeinträchtigt wird
. Die oben genannten Vorteile haben die praktische Vielseitigkeit der TTA-Methode erheblich verbessert, gepaart mit ihrer hervorragenden Leistung ist TTA zu einer äußerst wichtigen Forschungsrichtung in den Bereichen Migration, Generalisierung und anderen verwandten Bereichen geworden.Warum wilde Testzeitanpassung?
Obwohl bestehende TTA-Methoden großes Potenzial für die Out-of-Distribution-Generalisierung gezeigt haben, wird diese hervorragende Leistung häufig unter bestimmten Testbedingungen erzielt, beispielsweise den Proben des Testdatenstroms Innerhalb eines Zeitraums stammen alle vom gleichen Verteilungsverschiebungstyp, die wahre Kategorieverteilung der Testproben ist einheitlich und zufällig, und jedes Mal ist eine Mini-Batch-Stichprobe erforderlich, bevor eine Anpassung durchgeführt werden kann. Tatsächlich ist es jedoch schwierig, diese potenziellen Annahmen in der realen offenen Welt immer zu erfüllen. In der Praxis kann der Testdatenstrom in jeder beliebigen Kombination eintreffen, und idealerweise sollte das Modell keine Annahmen über die ankommende Form des Testdatenstroms treffen. Wie in Abbildung 2 dargestellt, ist es durchaus möglich, dass der Testdatenstrom auf Folgendes trifft: (a) Proben stammen aus unterschiedlichen Verteilungsoffsets (dh (b) ); Probenchargengröße Sehr klein (gerade 1) ; (c) Die wahre Klassenverteilung der Proben über einen Zeitraum ist ungleichmäßig und ändert sich dynamisch . In diesem Artikel wird die TTA im obigen Szenario zusammenfassend als Wild TTA bezeichnet. Leider erscheinen bestehende TTA-Methoden in diesen wilden Szenarien oft fragil und instabil, weisen eine begrenzte Migrationsleistung auf und können sogar die Leistung des ursprünglichen Modells beeinträchtigen. Wenn wir daher die groß angelegte und tiefgreifende Anwendungsbereitstellung der TTA-Methode in tatsächlichen Szenarien wirklich realisieren wollen, ist die Lösung des Wild-TTA-Problems ein unvermeidlicher und wichtiger Teil.
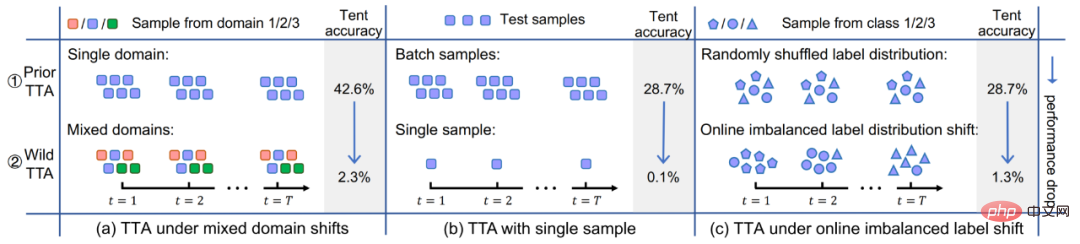
Abbildung 2 Dynamische offene Szene in der Anpassung während des Modelltests#🎜 🎜#
Lösungsideen und technische LösungenDieser Artikel analysiert die Gründe für das Scheitern von TTA in vielen Wild-Szenarien aus einer einheitlichen Perspektive. und dann eine Lösung anbieten.
1. Warum ist Wild TTA instabil?
(1) Batch Normalization (BN) ist einer der Hauptgründe für TTA-Instabilität in dynamischen Szenarien: Vorhanden TTA-Methoden basieren normalerweise auf der Anpassung der BN-Statistik, d. h. der Verwendung von Testdaten zur Berechnung des Mittelwerts und der Standardabweichung in der BN-Schicht. In den drei tatsächlichen dynamischen Szenarien wird jedoch die statistische Schätzgenauigkeit innerhalb der BN-Schicht verzerrt sein, was zu einer instabilen TTA führt:
- #🎜🎜 #Szenario (a) : Da die BN-Statistiken tatsächlich eine bestimmte Testdatenverteilung darstellen, führt die gleichzeitige Verwendung einer Reihe statistischer Parameter zur Schätzung mehrerer Verteilungen zwangsläufig zu einer eingeschränkten Leistung, siehe Abbildung 3; #
- Szenario (b): Die BN-Statistiken hängen von der Chargengröße ab. Es ist schwierig, genaue statistische Schätzungen von BN für kleine Chargengrößen zu erhalten, siehe Abbildung 4; 🎜#Szenario (c): Proben mit unausgewogener Etikettenverteilung führen zu einer Verzerrung der Statistiken innerhalb der BN-Schicht, d. h. die Statistiken sind auf eine bestimmte Kategorie (einen größeren Anteil der Charge) ausgerichtet. Kategorie), siehe Abbildung 5;
- Um die obige Analyse weiter zu überprüfen, betrachtet dieser Artikel drei weit verbreitete Modelle (ausgestattet mit unterschiedlichen BatchLayerGroup-Normen), basierend auf zwei repräsentativen Zur Validierung wurden TTA-Methoden (TTT [1] und Tent [2]) analysiert. Die endgültige Schlussfolgerung lautet: Batch-unabhängige Normebenen (Gruppen- und Ebenennorm) umgehen die Einschränkungen der Batch-Norm bis zu einem gewissen Grad und eignen sich besser für die Ausführung von TTA in dynamischen offenen Szenarien, und ihre Stabilität ist auch höher# 🎜🎜 #. Daher wird in diesem Artikel auch ein Methodendesign basierend auf dem mit GroupLayer Norm ausgestatteten Modell durchgeführt. Abbildung 3: Leistung verschiedener Methoden und Modelle (verschiedene Normalisierungsschichten) bei Mischungsverteilungsverschiebung #
- Abbildung 4: Leistung verschiedener Methoden und Modelle (verschiedene Normalisierungsschichten) bei unterschiedlichen Chargengrößen . Der schattierte Bereich in der Abbildung stellt die Standardabweichung der Modellleistung dar. Die Standardabweichung von ResNet50-BN und ResNet50-GN ist in der Abbildung zu klein und nicht signifikant (wie in der Abbildung unten)
#🎜🎜 #

Abbildung 5 Leistung verschiedener Methoden und Modelle (verschiedene Normalisierungsebenen) unter Verschiebung der Online-Ungleichgewichtskennzeichnung Je größer das Ungleichgewichtsverhältnis auf der horizontalen Achse in der Abbildung, desto schwerwiegender ist das Kennzeichnungsungleichgewicht
(2) Online-Entropieminimierung kann das Modell leicht auf eine degenerierte triviale Lösung optimieren, das heißt, jede Stichprobe derselben Klasse vorhersagen: Gemäß Abbildung 6 (a) und (b), wenn die Verteilung Wenn die Ebene schwerwiegend ist (Ebene 5), tritt während des Online-Anpassungsprozesses plötzlich das Phänomen der Modellverschlechterung und des Zusammenbruchs auf, dh alle Stichproben (mit unterschiedlichen realen Kategorien) werden gleichzeitig derselben Klasse, der Norm, vorhergesagt Der Modellgradient nimmt vor und nach dem Zusammenbruch des Modells schnell zu und fällt dann auf fast 0 ab, wie in Abbildung 6 (c) dargestellt. Dies weist darauf hin, dass einige große/Rauschgradienten möglicherweise die Modellparameter zerstört haben, wodurch das Modell beschädigt wurde zusammenbrechen.

Abbildung 6 Analyse von Fehlerfällen bei der Online-Testzeit-Entropieminimierung
2. Schärfeempfindliche und zuverlässige Methode zur Testzeit-Entropieminimierung.
Zur Schadensbegrenzung Um das oben genannte Problem der Modellverschlechterung anzugehen, schlägt dieses Papier eine schärfeempfindliche und zuverlässige Methode zur Entropieminimierung während der Testzeit vor (Sharpness-aware and Reliable Entropy Minimization Method, SAR). Es lindert dieses Problem in zweierlei Hinsicht: 1) Zuverlässige Entropieminimierung entfernt einige Proben, die große/verrauschte Gradienten aus der modelladaptiven Aktualisierung erzeugen; 2) Modellschärfeoptimierung korrigiert das Modell für einige der Rauschverläufe Die in den verbleibenden Proben erzeugten sind unempfindlich . Die spezifischen Details werden wie folgt erläutert:
Zuverlässige Entropieminimierung: Erstellen Sie einen alternativen Beurteilungsindex für die Gradientenauswahl basierend auf der Entropie und schließen Sie Proben mit hoher Entropie aus (einschließlich Proben aus den Bereichen 1 und 2 in Abbildung 6 (d). ) aus der Modellanpassung Nehmen Sie nicht an der Modellaktualisierung teil, außer:

wobei x die Testprobe darstellt, Θ den Modellparameter darstellt, 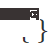 die Indikatorfunktion darstellt,
die Indikatorfunktion darstellt,  die Entropie von darstellt Das Beispielvorhersageergebnis
die Entropie von darstellt Das Beispielvorhersageergebnis  ist ein Superparameter. Nur wenn
ist ein Superparameter. Nur wenn 
die Probe an der Backpropagation-Berechnung teilnimmt.
Schärfeempfindliche Entropieoptimierung: Durch einen zuverlässigen Probenauswahlmechanismus gefilterte Proben können nicht vermeiden, dass sie immer noch Proben in Bereich 4 von Abbildung 6 (d) enthalten, und diese Proben können Rauschen erzeugen/große Gradienten setzen das Interferenzmodell fort. Zu diesem Zweck erwägt dieser Artikel die Optimierung des Modells auf ein Minimum, sodass es unempfindlich gegenüber Modellaktualisierungen ist, die durch Rauschgradienten verursacht werden, d. h. die ursprüngliche Modellleistung wird nicht beeinträchtigt:
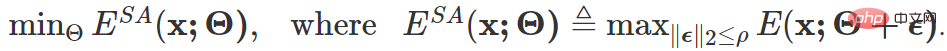
Die oben genannten Ziele Das endgültige Formular zur Aktualisierung des Farbverlaufs lautet wie folgt:
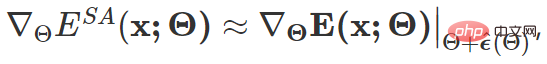
Unter ihnen 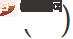 ist von SAM [4] inspiriert und wird durch Näherungslösung durch Taylor-Erweiterung erster Ordnung erhalten. Einzelheiten finden Sie im Originaltext und Code dieses Artikels.
ist von SAM [4] inspiriert und wird durch Näherungslösung durch Taylor-Erweiterung erster Ordnung erhalten. Einzelheiten finden Sie im Originaltext und Code dieses Artikels.
An diesem Punkt lautet das allgemeine Optimierungsziel dieses Artikels:
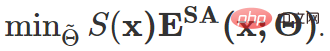
Um zu verhindern, dass das obige Schema unter extremen Bedingungen immer noch versagt, ist außerdem eine Modellwiederherstellungsstrategie erforderlich Einführung: Überwachen Sie das Modell über Mobilgeräte. Unabhängig davon, ob ein Degradationskollaps auftritt, wird entschieden, die ursprünglichen Werte der Modellaktualisierungsparameter zum erforderlichen Zeitpunkt wiederherzustellen.
Experimentelle Bewertung
Leistungsvergleich in dynamischen offenen Szenarien
SAR basiert auf den oben genannten drei dynamischen offenen Szenarien, nämlich a) Mischungsverteilungsverschiebung, b) Einzelprobenanpassung und c) Online-Ungleichgewicht Die Kategorie Die Verteilungsverschiebung wird experimentell anhand des ImageNet-C-Datensatzes überprüft und die Ergebnisse sind in den Tabellen 1, 2 und 3 dargestellt. SAR erzielt in allen drei Szenarien bemerkenswerte Ergebnisse, insbesondere in den Szenarien b) und c). SAR verwendet VitBase als Basismodell und seine Genauigkeit übertrifft die aktuelle SOTA-Methode EATA um fast 10 %.
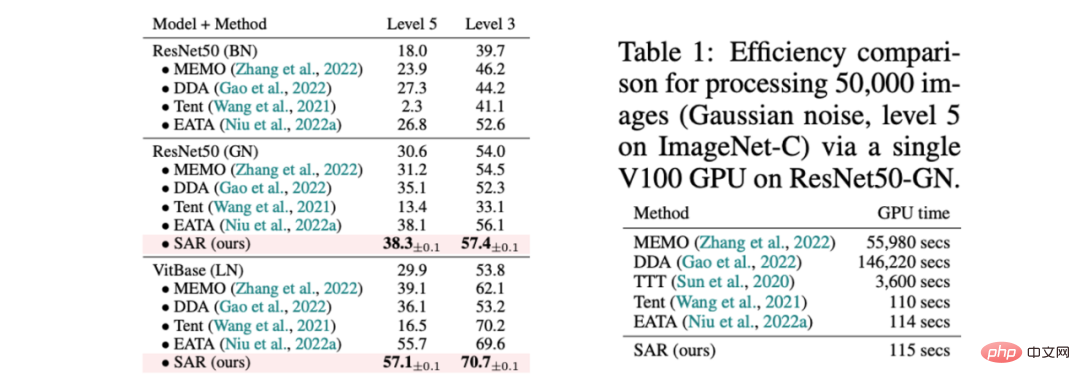
Tabelle 1 Leistungsvergleich zwischen SAR und bestehenden Methoden in gemischten Szenarien von 15 Schadensarten in ImageNet-C, entsprechend dem dynamischen Szenario (a); und Effizienzvergleich mit bestehenden Methoden 有 Tabelle 2 SAR und die vorhandene Methode zum Leistungsvergleich im Szenario in ImageNet-C, entsprechend der dynamischen Szene (B)
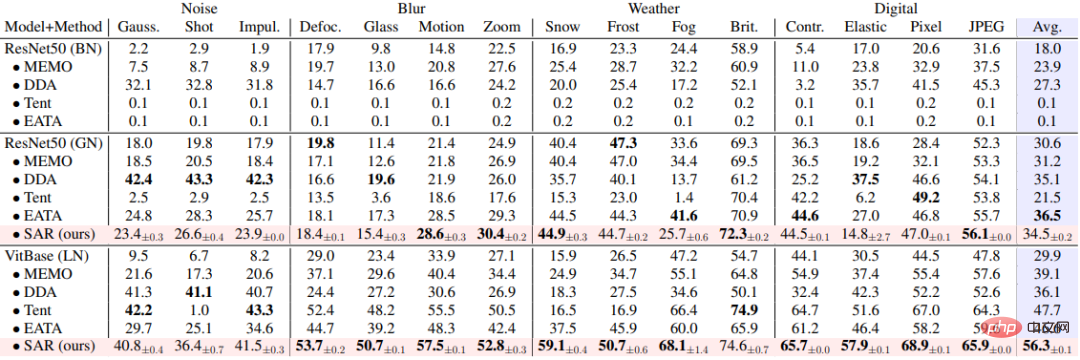
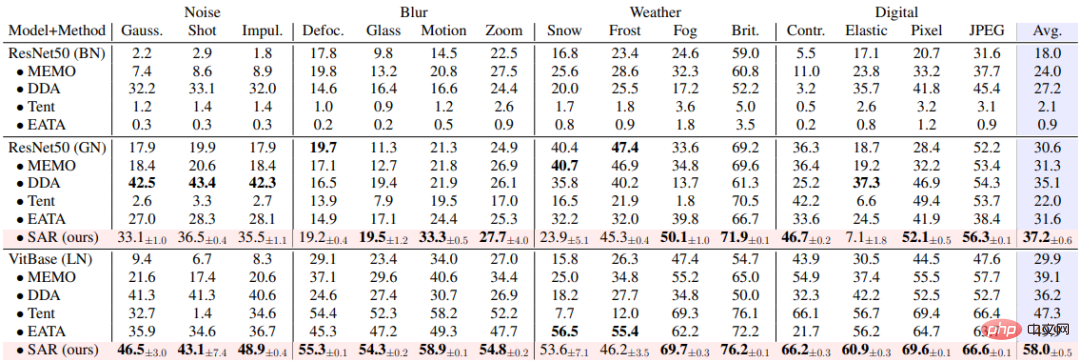
Tabelle 3 Leistungsvergleich zwischen SAR und vorhandenen Methoden in Online-Szenario mit nicht ausgeglichener Klassenverteilungsverschiebung auf ImageNet-C, entsprechend dem dynamischen Szenario (c)
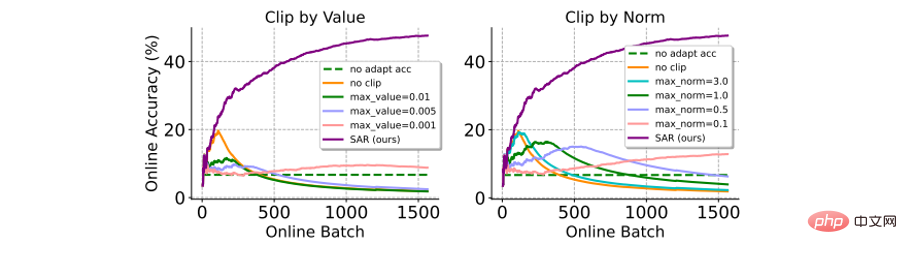
und Vergleich der Gradientenbeschneidungsmethode : Gradientenbeschneidung ist eine einfache und direkte Methode um zu vermeiden, dass große Farbverläufe Modellaktualisierungen beeinträchtigen (oder sogar zu einem Zusammenbruch führen). Hier ist ein Vergleich mit zwei Varianten der Verlaufsbeschneidung (z. B. nach Wert oder nach Norm). Wie in der folgenden Abbildung gezeigt, reagiert die Gradientenbeschneidung sehr empfindlich auf die Auswahl des Gradientenbeschneidungsschwellenwerts δ. Ein kleinerer δ entspricht dem Ergebnis, dass das Modell nicht aktualisiert wird, und ein größerer δ ist schwer zu vermeiden, dass das Modell zusammenbricht. Im Gegensatz dazu erfordert SAR keinen komplizierten Hyperparameter-Filterprozess und bietet eine deutlich bessere Leistung als Gradient Clipping.
Abbildung 7 Leistungsvergleich mit der Gradient-Clipping-Methode im Online-Szenario mit unausgeglichener Etikettenverteilungsverschiebung auf ImageNet-C (Schussrauschen, Stufe 5). Die Genauigkeit wird online basierend auf allen vorherigen Testbeispielen berechnet
: Wie in der folgenden Tabelle gezeigt, arbeiten die verschiedenen Module von SAR zusammen, um den Test im dynamischen offenen Modus effektiv zu verbessern Szenarien modellieren adaptive Stabilität.
Tabelle 4 SAR-Ablationsexperiment auf ImageNet-C (Stufe 5) im Online-Szenario mit unausgeglichener Etikettenverteilungsverschiebung
Visualisierung der Verlustoberflächenschärfe: Das Ergebnis der Visualisierung der Verlustfunktion durch Hinzufügen von Störungen zum Modellgewicht ist in der folgenden Abbildung dargestellt. Unter diesen hat SAR einen größeren Bereich (dunkelblauer Bereich) innerhalb der Kontur mit dem geringsten Verlust als Tent, was darauf hinweist, dass die durch SAR erhaltene Lösung flacher, robuster gegenüber Rauschen/größeren Gradienten ist und eine stärkere Entstörungsfähigkeit aufweist. Abbildung 8: Visualisierung der Entropieverlustoberfläche Zu diesem Zweck analysiert dieser Artikel zunächst aus einer einheitlichen Perspektive die Gründe, warum bestehende Methoden in tatsächlichen dynamischen Szenarien versagen, und entwirft vollständige Experimente, um eine eingehende Überprüfung durchzuführen. Basierend auf diesen Analysen schlägt dieser Artikel schließlich eine schärfeempfindliche und zuverlässige Methode zur Minimierung der Testzeit-Entropie vor, die eine stabile und effiziente Online-Testzeitanpassung des Modells erreicht, indem der Einfluss bestimmter Testproben mit großen Gradienten/Rauschen auf Modellaktualisierungen unterdrückt wird. .
Das obige ist der detaillierte Inhalt vonEine offene Umgebungslösung, die Mängel wie die Batch-Norm-Schicht behebt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr