
Heim >Technologie-Peripheriegeräte >KI >Multimodales selbstüberwachtes Lernen: Erforschung objektiver Funktionen, Datenausrichtung und Modellarchitektur – am Beispiel des neuesten Edinburgh-Reviews
Multimodales selbstüberwachtes Lernen: Erforschung objektiver Funktionen, Datenausrichtung und Modellarchitektur – am Beispiel des neuesten Edinburgh-Reviews

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-26 10:04:081439Durchsuche
Multimodales Lernen zielt darauf ab, Informationen aus mehreren Modalitäten zu verstehen und zu analysieren. In den letzten Jahren wurden bei den Überwachungsmechanismen erhebliche Fortschritte erzielt.
Allerdings behindert die starke Abhängigkeit von Daten in Verbindung mit kostspieligen manuellen Anmerkungen die Modellskalierung. Gleichzeitig ist selbstüberwachtes Lernen angesichts der Verfügbarkeit umfangreicher, unbeschrifteter Daten in der realen Welt zu einer attraktiven Strategie geworden, um den Etikettierungsengpass zu lindern.
Basierend auf diesen beiden Richtungen bietet selbstüberwachtes multimodales Lernen (SSML) eine Methode, um die Überwachung anhand ursprünglicher multimodaler Daten zu nutzen.

Papieradresse: https://arxiv.org/abs/2304.01008
Projektadresse: https://github. com/ys-zong/awesome-self-supervised-multimodal-learning
In dieser Rezension bieten wir einen umfassenden Überblick über den Stand der Technik in SSML, den wir entlang dreier orthogonaler Achsen klassifizieren: Zielfunktion, Datenausrichtung und Modellarchitektur. Diese Achsen entsprechen den inhärenten Merkmalen selbstüberwachter Lernmethoden und multimodaler Daten.
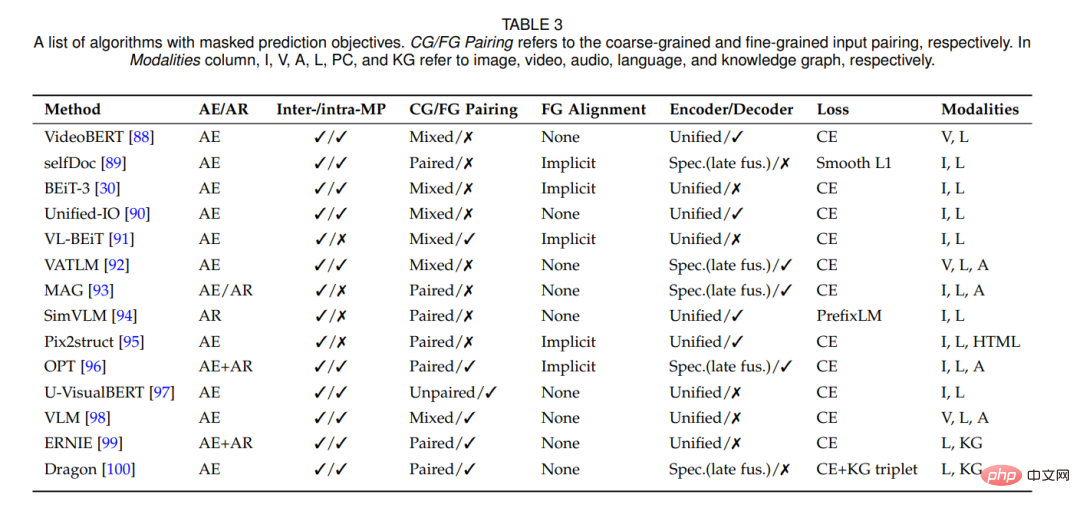
Konkret unterteilen wir die Trainingsziele in die Kategorien Instanzunterscheidung, Clustering und Maskenvorhersage. Wir diskutieren auch multimodale Eingabedatenpaarungs- und Ausrichtungsstrategien während des Trainings. Abschließend wird die Modellarchitektur überprüft, einschließlich des Designs von Encodern, Fusionsmodulen und Decodern, die wichtige Komponenten von SSML-Methoden sind.
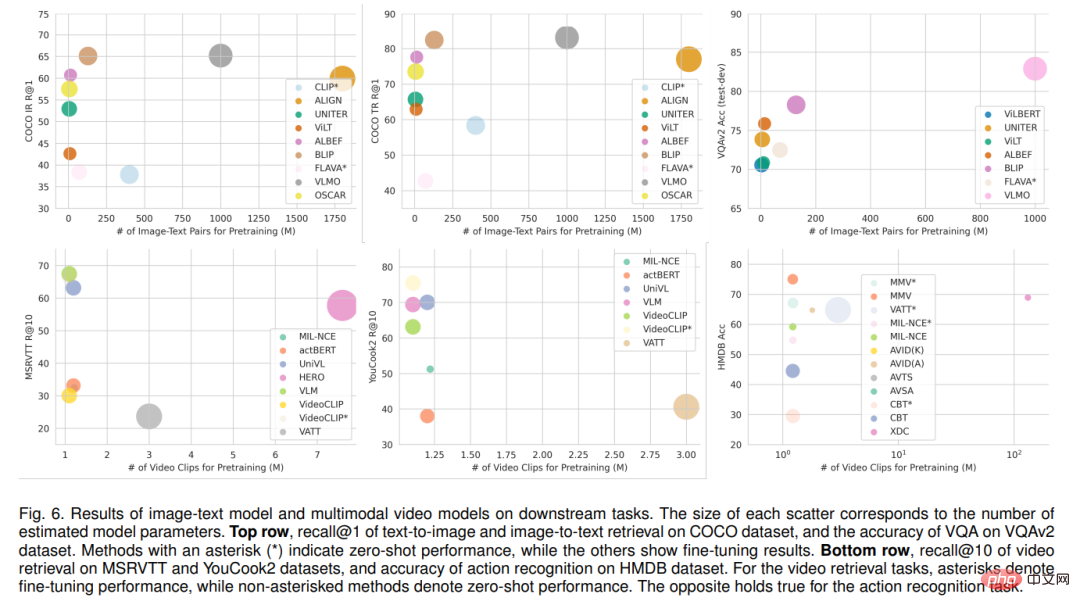
Überprüft nachgelagerte multimodale Anwendungsaufgaben, berichtet über die spezifische Leistung hochmoderner Bild-Text-Modelle und multimodaler Videomodelle und überprüft auch praktische Anwendungen von SSML-Algorithmen in verschiedenen Bereichen, beispielsweise im Gesundheitswesen , Fernerkundung und maschinelle Übersetzung. Abschließend werden Herausforderungen und zukünftige Richtungen für SSML diskutiert.
1. Einführung
Der Mensch nimmt die Welt mit verschiedenen Sinnen wahr, darunter Sehen, Hören, Fühlen und Riechen. Wir gewinnen ein umfassendes Verständnis unserer Umgebung, indem wir ergänzende Informationen aus jeder Modalität nutzen. Die KI-Forschung konzentriert sich auf die Entwicklung intelligenter Agenten, die menschliches Verhalten nachahmen und die Welt auf ähnliche Weise verstehen. Zu diesem Zweck zielt das Gebiet des multimodalen maschinellen Lernens [1], [2] darauf ab, Modelle zu entwickeln, die in der Lage sind, Daten aus mehreren verschiedenen Modalitäten zu verarbeiten und zu integrieren. In den letzten Jahren hat das multimodale Lernen erhebliche Fortschritte gemacht, die zu einer Reihe von Anwendungen im visuellen und sprachlichen Lernen [3], im Videoverständnis [4], [5], in der Biomedizin [6], im autonomen Fahren [7] und in anderen Bereichen geführt haben. Noch grundlegender ist, dass multimodales Lernen seit langem bestehende Grundprobleme der künstlichen Intelligenz vorantreibt [8] und uns einer allgemeineren künstlichen Intelligenz näher bringt.
Allerdings erfordern multimodale Algorithmen für ein effektives Training oft immer noch teure manuelle Annotationen, was ihre Erweiterung behindert. Vor kurzem hat selbstüberwachtes Lernen (SSL) [9], [10] begonnen, dieses Problem zu lindern, indem Supervision aus leicht verfügbaren annotierten Daten generiert wird. Die Selbstüberwachung beim monomodalen Lernen ist ziemlich genau definiert und hängt nur von den Trainingszielen ab und davon, ob menschliche Anmerkungen zur Überwachung verwendet werden. Im Kontext des multimodalen Lernens ist seine Definition jedoch differenzierter. Beim multimodalen Lernen fungiert eine Modalität häufig als Überwachungssignal für eine andere Modalität. Im Hinblick auf das Ziel der Aufwärtsskalierung durch Beseitigung des Engpasses bei der manuellen Annotation besteht eine zentrale Frage bei der Definition des Umfangs der Selbstüberwachung darin, ob modalübergreifende Paarungen frei erfasst werden.
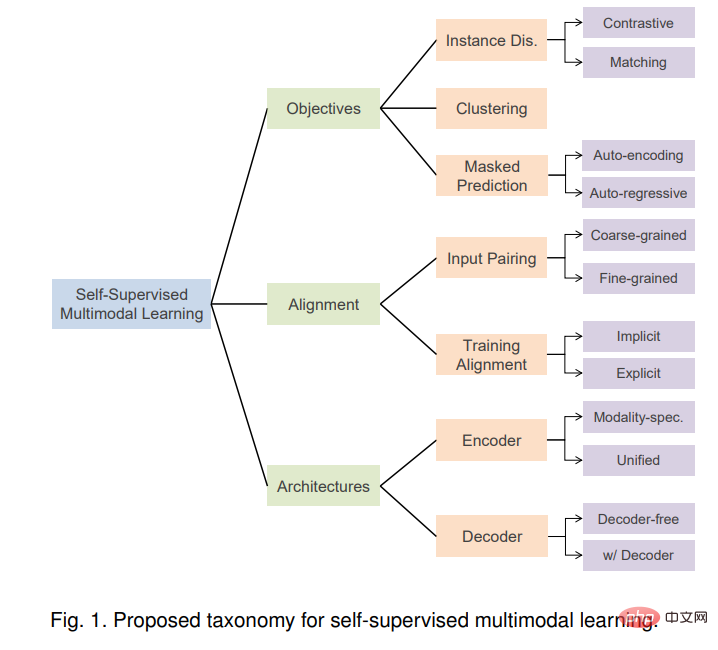
Selbstüberwachtes multimodales Lernen (SSML) verbessert die Fähigkeiten multimodaler Modelle erheblich, indem frei verfügbare multimodale Daten und selbstüberwachte Ziele genutzt werden. In dieser Rezension besprechen wir SSML-Algorithmen und ihre Anwendungen. Wir zerlegen die verschiedenen Methoden entlang dreier orthogonaler Achsen: Zielfunktion, Datenausrichtung und Modellarchitektur. Diese Achsen entsprechen den Merkmalen selbstüberwachter Lernalgorithmen und den spezifischen Überlegungen, die für multimodale Daten erforderlich sind. Abbildung 1 gibt einen Überblick über die vorgeschlagene Taxonomie. Basierend auf der Voraufgabe unterteilen wir die Trainingsziele in die Kategorien Instanzunterscheidung, Clustering und Maskenvorhersage. Es werden auch hybride Ansätze diskutiert, die zwei oder mehr dieser Ansätze kombinieren.
Einzigartig bei der multimodalen Selbstüberwachung ist das Problem der multimodalen Datenpaarung. Paarungen oder allgemeiner Ausrichtungen zwischen Modalitäten können von SSML-Algorithmen als Eingabe (z. B. wenn eine Modalität verwendet wird, um eine andere zu überwachen), aber auch als Ausgabe (z. B. Lernen aus ungepaarten Daten und Induzieren von Paarungen als) genutzt werden ein Nebenprodukt). Wir diskutieren die verschiedenen Rollen der Ausrichtung auf grobkörniger Ebene, von denen oft angenommen wird, dass sie in der multimodalen Selbstüberwachung frei verfügbar sind (z. B. im Internet gecrawlte Bilder und Bildunterschriften [11]), manchmal explizit oder implizit induzierte feinkörnige Ausrichtung (z. B. , Korrespondenz zwischen Titelwörtern und Bildfeldern [12]). Darüber hinaus untersuchen wir die Schnittstelle zwischen Zielfunktionen und Datenausrichtungsannahmen.
analysiert auch das Design zeitgenössischer SSML-Modellarchitektur. Konkret betrachten wir den Designraum von Encoder- und Fusionsmodulen und vergleichen modusspezifische Encoder (ohne Fusion oder mit später Fusion) und einheitliche Encoder mit früher Fusion. Wir untersuchen auch Architekturen mit spezifischen Decoder-Designs und diskutieren die Auswirkungen dieser Design-Entscheidungen.
Schließlich die Anwendungen dieser Algorithmen in mehreren realen Bereichen, einschließlich Gesundheitswesen, Fernerkundung, maschinelle Übersetzung usw., sowie die technischen Herausforderungen und sozialen Auswirkungen davon SSML werden diskutiert. Es wird eine ausführliche Diskussion geführt und mögliche zukünftige Forschungsrichtungen aufgezeigt. Wir fassen die jüngsten Fortschritte bei Methoden, Datensätzen und Implementierungen zusammen, um Forschern und Praktikern auf diesem Gebiet einen Ausgangspunkt zu bieten.
Vorhandene Übersichtsarbeiten konzentrieren sich entweder nur auf überwachtes multimodales Lernen [1], [2], [13], [14] oder auf einzelnes -modales selbstüberwachtes Lernen [9], [10], [15] oder ein bestimmter Teilbereich von SSML, wie beispielsweise das visuelle Sprach-Vortraining [16]. Die relevanteste Rezension ist [17], aber sie konzentriert sich mehr auf zeitliche Daten und ignoriert die wichtigsten Überlegungen der multimodalen Selbstüberwachung von Ausrichtung und Architektur. Im Gegensatz dazu bieten wir einen umfassenden und aktuellen Überblick über SSML-Algorithmen und eine neue Taxonomie, die Algorithmen, Daten und Architektur abdeckt.
2. Hintergrundwissen
Im multimodalen Lernen Selbst -supervised
Wir beschreiben zunächst den in dieser Umfrage berücksichtigten Umfang von SSML, da dieser Begriff in der bisherigen Literatur uneinheitlich verwendet wurde. Die Definition von Selbstüberwachung in einem einmodalen Kontext ist einfacher, wenn man sich auf die etikettenfreie Natur verschiedener Vorwandaufgaben beruft, z. B. die bekannte Instanzunterscheidung [20] oder das maskierte Vorhersageziel [21], die Selbstüberwachung implementieren. Im Gegensatz dazu ist die Situation beim multimodalen Lernen komplizierter, da die Rollen von Modalität und Bezeichnung verschwimmen. Beispielsweise wird Text bei der überwachten Bildunterschrift [22] normalerweise als Beschriftung behandelt, beim selbstüberwachten multimodalen Lernen visueller und sprachlicher Darstellungen [11] wird Text jedoch als Eingabemodalität behandelt.
Im multimodalen Kontext wird der Begriff Selbstüberwachung verwendet, um sich auf mindestens vier Situationen zu beziehen: (1) aus automatisch gepaarten multimodalen Daten Etikettenfreies Lernen – z.B. Filme mit Video- und Audiospuren [23] oder Bild- und Tiefendaten von RGBD-Kameras [24]. (2) Lernen aus multimodalen Daten, bei denen eine Modalität manuell annotiert wurde oder zwei Modalitäten manuell gepaart wurden, diese Annotation jedoch für einen anderen Zweck erstellt wurde und daher für das SSML-Vortraining als kostenlos betrachtet werden kann. Beispielsweise sind passende Bild-Untertitel-Paare aus dem Internet, wie sie im bahnbrechenden CLIP [11] verwendet werden, tatsächlich ein Beispiel für überwachtes metrisches Lernen [25], [26], bei dem die Paarung überwacht wird. Da jedoch sowohl Muster als auch Paarungen im großen Maßstab frei verfügbar sind, wird es oft als selbstüberwacht bezeichnet. Diese nicht kuratierten, zufällig erstellten Daten sind häufig von geringerer Qualität und verrauschter als speziell kuratierte Datensätze wie COCO [22] und Visual Genome [27]. (3) Lernen Sie aus hochwertigen, zweckannotierten multimodalen Daten (z. B. manuell beschriftete Bilder in COCO [22]), jedoch mit einem selbstüberwachten Stilziel wie Pixel-BERT [28]. (4) Schließlich gibt es „selbstüberwachte“ Methoden, die eine Mischung aus freien und manuell gekennzeichneten multimodalen Daten verwenden [29], [30]. Für den Zweck dieser Untersuchung folgen wir der Idee der Selbstüberwachung und streben eine Skalierung an, indem wir den Engpass der manuellen Annotation überwinden. Daher schließen wir die ersten beiden Kategorien und die vierte Kategorie von Methoden ein, um auf frei verfügbaren Daten trainieren zu können. Wir schließen Methoden aus, die nur für manuell kuratierte Datensätze gezeigt werden, da sie typische „Selbstüberwachungs“-Ziele auf kuratierte Datensätze anwenden (z. B. maskierte Vorhersage).
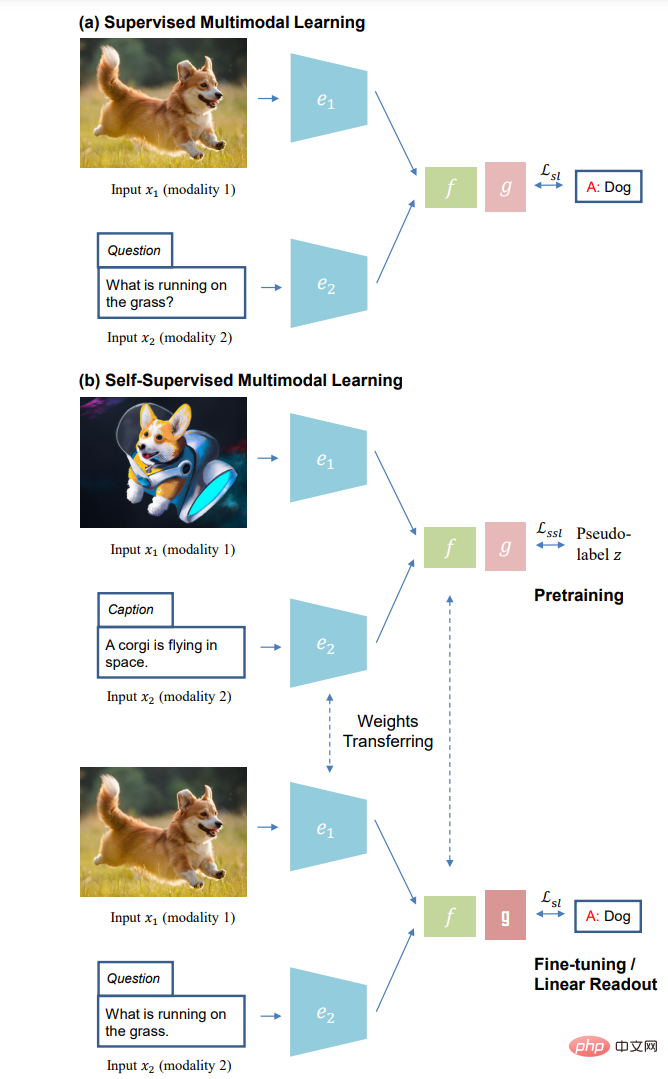
(a) Überwachtes multimodales Lernen und (b) selbstüberwachtes Lernparadigma des multimodalen Lernens: selbstüberwachtes Vortraining ohne manuelle Annotation (oben); unten) ).
3. Zielfunktion
In diesem Abschnitt stellen wir die Zielfunktion vor, die zum Trainieren von drei Kategorien selbstüberwachter multimodaler Algorithmen verwendet wird: Instanzunterscheidung, Clustering und Maskenvorhersage. Schließlich haben wir auch Hybridziele diskutiert.
3.1 Instanzunterscheidung
Beim Single-Mode-Lernen behandelt die Instanzunterscheidung (ID) jede Instanz in den Originaldaten als separate Klasse und trainiert das Modell, um verschiedene Instanzen zu unterscheiden. Im Kontext des multimodalen Lernens zielt die Instanzunterscheidung normalerweise darauf ab, festzustellen, ob Stichproben aus zwei Eingabemodalitäten von derselben Instanz stammen, also gepaart sind. Auf diese Weise wird versucht, den Darstellungsraum von Musterpaaren auszurichten und gleichzeitig den Darstellungsraum verschiedener Instanzpaare weiter auseinanderzuschieben. Es gibt zwei Arten von Instanzerkennungszielen: kontrastive Vorhersage und Matching-Vorhersage, je nachdem, wie die Eingabe abgetastet wird.
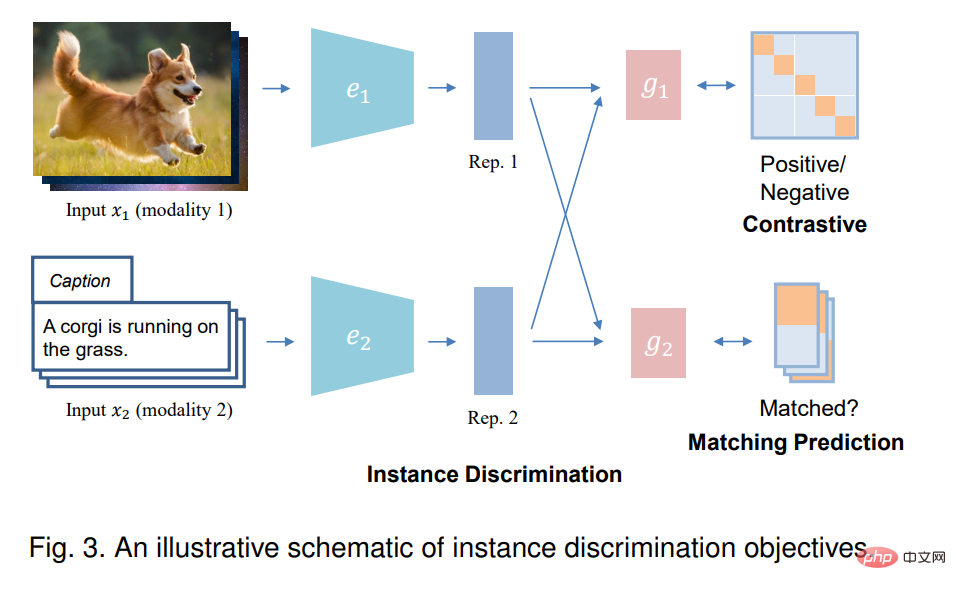
3.2 Clustering
Clustering-Methoden gehen davon aus, dass die Anwendung von trainiertem End-to-End-Clustering zu einer Gruppierung der Daten basierend auf semantisch hervorstechenden Merkmalen führt. In der Praxis sagen diese Methoden iterativ Clusterzuordnungen codierter Darstellungen voraus und verwenden diese Vorhersagen (auch Pseudo-Labels genannt) als Überwachungssignale zur Aktualisierung von Merkmalsdarstellungen. Multimodales Clustering bietet die Möglichkeit, multimodale Darstellungen zu erlernen und auch das traditionelle Clustering zu verbessern, indem andere Modalitäten mithilfe von Pseudobezeichnungen für jede Modalität überwacht werden.
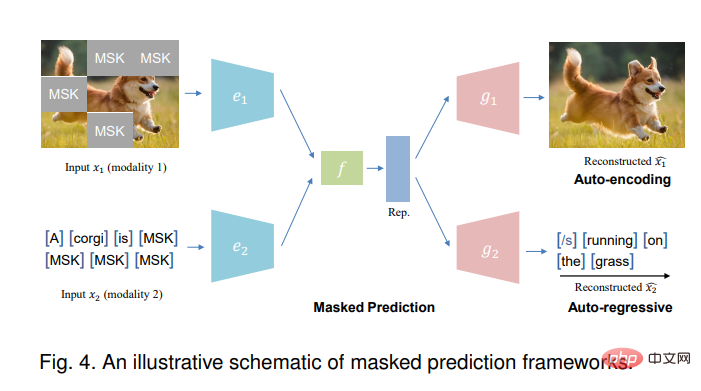
3.3 Maskenvorhersage
Die Maskenvorhersageaufgabe kann mithilfe automatischer Codierung (ähnlich BERT [101]) oder automatischer Regressionsmethoden (ähnlich GPT [102]) durchgeführt werden.
Das obige ist der detaillierte Inhalt vonMultimodales selbstüberwachtes Lernen: Erforschung objektiver Funktionen, Datenausrichtung und Modellarchitektur – am Beispiel des neuesten Edinburgh-Reviews. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr