
Heim >Technologie-Peripheriegeräte >KI >Optimieren Sie die Verbindungsleistung des Transfertransportplans von Ctrip
Optimieren Sie die Verbindungsleistung des Transfertransportplans von Ctrip

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-25 18:31:091488Durchsuche
Über den Autor
Kurz gesagt, Ctrip-Back-End-Entwicklungsmanager mit Schwerpunkt auf technischer Architektur, Leistungsoptimierung, Transportplanung und anderen Bereichen.
1. Hintergrundeinführung
Aufgrund der Einschränkungen der Transportplanung und der Transportressourcen gibt es möglicherweise keinen direkten Transport zwischen den beiden vom Benutzer abgefragten Orten oder an wichtigen Feiertagen ist der direkte Transportausverkauft. Benutzer können ihr Ziel jedoch weiterhin durch Hin- und Rücktransfers wie Züge, Flugzeuge, Autos, Schiffe usw. erreichen. Darüber hinaus ist der Transfertransport manchmal preislich und zeitlich vorteilhafter. Beispielsweise kann die Verbindung mit dem Zug von Shanghai nach Yuncheng schneller und günstiger sein als mit einem Direktzug.
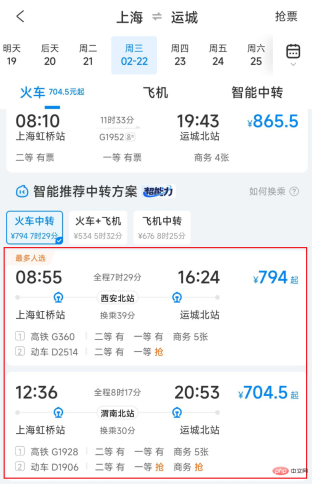
Abbildung 1 Liste der Ctrip-Zugtransfertransporte
Bei der Bereitstellung von Transfertransportlösungen besteht eine sehr wichtige Verbindung darin, zwei oder mehr Fahrten mit Zügen, Flugzeugen, Autos, Schiffen usw. zusammenzufügen, um eine zu bilden realisierbarer Transferplan. Die erste Schwierigkeit beim Zusammenführen des Transitverkehrs besteht darin, dass allein in Shanghai als Transitstadt fast 100 Millionen Kombinationen generiert werden können, da sich die Daten der Produktionslinie ständig ändern jederzeit und muss ständig aktualisiert werden. Abfragedaten zu Zügen, Flugzeugen, Autos und Schiffen. Das Spleißen des Transitverkehrs erfordert viel Rechenressourcen und E/A-Overhead, daher ist die Optimierung der Leistung besonders wichtig.
In diesem Artikel werden anhand von Beispielen die Prinzipien, Analyse- und Optimierungsmethoden vorgestellt, die bei der Optimierung der Übertragungsleistung beim Spleißen des Datenverkehrs angewendet werden, um den Lesern wertvolle Referenzen und Inspirationen zu bieten.
2. OptimierungsprinzipienLeistungsoptimierung erfordert einen Ausgleich und Kompromisse zwischen verschiedenen Ressourcen und Einschränkungen unter der Prämisse, dass die Einhaltung einiger wichtiger Prinzipien dazu beitragen kann, Unsicherheiten zu beseitigen und die optimale Lösung zu finden. Insbesondere werden während des Optimierungsprozesses für das Spleißen des Übertragungsverkehrs hauptsächlich die folgenden drei Prinzipien befolgt:
2.1 Leistungsoptimierung ist eher ein Mittel als ein Zweck. Auch wenn es in diesem Artikel um Leistungsoptimierung geht, muss sie am Anfang dennoch hervorgehoben werden : Tun Sie es nicht zur Optimierung, sondern optimieren Sie es. Es gibt viele Möglichkeiten, Geschäftsanforderungen zu erfüllen, und die Leistungsoptimierung ist nur eine davon. Manchmal ist das Problem sehr komplex und es gibt viele Einschränkungen, ohne die Benutzererfahrung wesentlich zu beeinträchtigen. Eine Reduzierung der Auswirkungen auf Benutzer durch die Lockerung von Einschränkungen oder die Einführung anderer Prozesse ist auch eine gute Möglichkeit, Leistungsprobleme zu lösen. In der Softwareentwicklung gibt es viele Beispiele für erhebliche Kostensenkungen, die durch geringe Leistungseinbußen erreicht werden. Beispielsweise benötigt der HyperLogLog-Algorithmus, der für Kardinalitätsstatistiken (Entfernung von Duplikaten) in Redis verwendet wird, nur 12 KB Speicherplatz, um 264 Daten mit einem Standardfehler von 0,81 % zu zählen.Zurück zum Problem selbst: Aufgrund der Notwendigkeit, häufig Produktionsliniendaten abzufragen und umfangreiche Verbindungsvorgänge durchzuführen, sind die Kosten sehr hoch, wenn jeder Benutzer bei der Abfrage sofort den aktuellsten Übertragungsplan zurückgeben muss. Um die Kosten zu senken, muss ein Gleichgewicht zwischen Reaktionszeit und Datenaktualität gefunden werden. Nach sorgfältiger Überlegung akzeptieren wir Dateninkonsistenzen auf Minutenebene. Für einige unbeliebte Routen und Daten gibt es bei der ersten Abfrage möglicherweise keinen guten Transferplan. Bitten Sie den Benutzer in diesem Fall einfach, die Seite zu aktualisieren.
2.2 Falsche Optimierung ist die Wurzel allen Übels
Donald Knuth erwähnte in „Structured Programming With Go To Statements“: „Programmierer verschwenden viel Zeit damit, über die Leistung unkritischer Pfade nachzudenken und sich Sorgen darüber zu machen, und versuchen es.“ Die Optimierung dieses Teils der Leistung wird sehr schwerwiegende negative Auswirkungen auf das Debuggen und die Wartung des gesamten Codes haben, daher sollten wir in 97 % der Fälle kleine Optimierungspunkte vergessen.“ Kurz gesagt, bevor das eigentliche Leistungsproblem entdeckt wird, wird eine übermäßige und auffällige Optimierung auf Codeebene nicht nur die Leistung nicht verbessern, sondern möglicherweise auch zu mehr Fehlern führen. Allerdings betonte der Autor auch: „Für die verbleibenden kritischen 3 % sollten wir uns die Gelegenheit zur Optimierung nicht entgehen lassen.“ Daher müssen Sie immer auf Leistungsprobleme achten, keine Entscheidungen treffen, die sich auf die Leistung auswirken, und bei Bedarf die richtigen Optimierungen vornehmen.2.3 Analysieren Sie die Leistung quantitativ und klären Sie die Richtung der Optimierung.
Wie im vorherigen Abschnitt erwähnt, müssen Sie vor der Optimierung zunächst die Leistung quantifizieren und Engpässe identifizieren, damit die Optimierung gezielter erfolgen kann. Zur quantitativen Analyse der Leistung können zeitaufwändige Überwachungstools, Profiler-Leistungsanalysetools, Benchmark-Benchmark-Testtools usw. eingesetzt werden, wobei der Schwerpunkt auf Bereichen liegt, die besonders viel Zeit in Anspruch nehmen oder eine besonders hohe Ausführungshäufigkeit aufweisen. In Amdahls Gesetz heißt es: „Der Grad der Verbesserung der Systemleistung, der durch die Verwendung einer schnelleren Ausführungsmethode für eine bestimmte Komponente im System erreicht werden kann, hängt von der Häufigkeit ab, mit der diese Ausführungsmethode verwendet wird, oder vom Anteil der gesamten Ausführungszeit.“ "
Darüber hinaus ist es auch wichtig zu beachten, dass die Leistungsoptimierung ein langwieriger Kampf ist. Da sich das Unternehmen weiterentwickelt, ändern sich Architektur und Code ständig. Daher ist es umso notwendiger, die Leistung kontinuierlich zu quantifizieren, Engpässe kontinuierlich zu analysieren und Optimierungseffekte zu bewerten.
3. Der Weg zur Leistungsanalyse
3.1 Den Geschäftsprozess ordnen
Vor der Leistungsanalyse müssen wir zunächst den Geschäftsprozess ordnen. Das Zusammenfügen von Transfertransportplänen umfasst hauptsächlich die folgenden vier Schritte:
a. Laden Sie die Routenkarte, z. B. den Transfer von Peking nach Shanghai, wobei nur die Informationen der Route selbst berücksichtigt werden und nichts damit zu tun haben spezifischer Zug;
b Überprüfen Sie die Zug-, Produktionsliniendaten von Flugzeugen, Autos und Schiffen, einschließlich Abfahrtszeit, Ankunftszeit, Abfahrtsbahnhof, Preis und verbleibende Ticketinformationen usw.; c. Kombinieren Sie alle möglichen Transfertransportlösungen und berücksichtigen Sie dabei hauptsächlich den Transfer. Die Fahrzeit sollte nicht zu kurz sein, um zu vermeiden, dass der Transfer gleichzeitig abgeschlossen werden kann. Sie sollte nicht zu lang sein, um zu lange Wartezeiten zu vermeiden. Nachdem Sie praktikable Lösungen zusammengestellt haben, müssen Sie noch die Geschäftsfelder verbessern, z. B. Gesamtpreis, Gesamtzeit und Transferinformationen.
d Wählen Sie nach bestimmten Regeln einige Benutzer aus allen möglichen Transferplänen aus Programme, die von Interesse sein könnten.
3.2 Quantitative Analyseleistung
(1) Fügen Sie eine zeitaufwändige Überwachung hinzu
Die zeitaufwändige Überwachung ist die intuitivste Möglichkeit, die zeitaufwändige Situation jeder Phase aus einer Makroperspektive zu beobachten. Es kann nicht nur den zeitaufwändigen Wert und den zeitaufwändigen Anteil in jeder Phase des Geschäftsprozesses anzeigen, sondern auch den zeitaufwändigen Änderungstrend über einen langen Zeitraum hinweg beobachten.
Zeitaufwändige Überwachung kann das unternehmensinterne Indikatorüberwachungs- und Alarmsystem nutzen, um zeitaufwändiges Management zum Hauptprozess der Verbindung von Transportlösungen hinzuzufügen. Zu diesen Prozessen gehören das Laden von Streckenkarten, das Abfragen und Zusammenfügen von Schichtdaten, das Filtern und Speichern von Verbindungsplänen usw. Die zeitaufwändige Situation jeder Phase ist in Abbildung 2 dargestellt. Es ist ersichtlich, dass das Spleißen (einschließlich der Daten der Produktionslinie) den höchsten Zeitaufwand in Anspruch nimmt und daher in Zukunft zu einem wichtigen Optimierungsziel geworden ist. Abbildung 2: Zeitaufwändige Überwachung des Spleißens des Transitverkehrs. Daher sollte es nicht überschritten werden. Mehr, besser geeignet für die Überwachung von Hauptprozessen. Das entsprechende Profiler-Leistungsanalysetool (z. B. Async-Profiler) kann einen spezifischeren Aufrufbaum und das CPU-Auslastungsverhältnis jeder Funktion generieren und so dabei helfen, kritische Pfade und Leistungsengpässe zu analysieren und zu lokalisieren.
Abbildung 3 Spleiß-Aufrufbaum und CPU-Verhältnis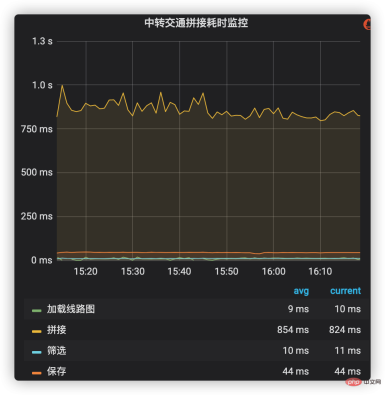
Wie in Abbildung 3 dargestellt, macht die Spleißlösung (combineTransferLines) 53,80 % aus und die Daten der Abfrageproduktionslinie (querySegmentCacheable, verwendeter Cache). 21,45 %. Im Spleißschema sind die Berechnung des Schema-Scores (computeTripScore, 48,22 % ausmachend), das Erstellen einer Schema-Entität (buildTripBO, 4,61 % ausmachend) und die Überprüfung der Spleißdurchführbarkeit (checkCombineMatchCondition, 0,91 % ausmachend) die drei größten Verknüpfungen.
Abbildung 4 Lösungsbewertungsaufrufbaum und CPU-Verhältnis
Während wir die Berechnungsplanbewertung (computeTripScore) mit dem höchsten Anteil weiter analysierten, stellten wir fest, dass sie hauptsächlich mit der benutzerdefinierten Zeichenfolgenformatierungsfunktion (StringUtils.format) zusammenhängt, einschließlich direkter Aufrufe (die zum Anzeigen von Planbewertungsdetails verwendet werden) und indirekte Aufrufe über getTripId Call (die ID, die zum Generieren des Schemas verwendet wird). Der größte Anteil des angepassten StringUtils.format ist java/lang/String.replace. Der native String-Ersatz von Java 8 wird durch reguläre Ausdrücke implementiert, was relativ ineffizient ist (dieses Problem wurde nach Java 9 behoben).
// 计算方案评分(computeTripScore) 中调用的StringUtils.format代码示例
StringUtils.format("AAAA-{0},BBBB-{1},CCCC-{2},DDDD-{3},EEEE-{4},FFFF-{5},GGGG-{6},HHHH-{7},IIII-{8},JJJJ-{9}",
aaaa, bbbb, cccc, dddd, eeee, ffff, gggg, hhhh, iiii, jjjj)
// getTripId 中调用StringUtils.format代码示例
StringUtils.format("{0}_{1}_{2}_{3}_{4}_{5}_{6}", aaaa, bbbb, cccc, dddd, eeee, ffff)
// 通过Java replace实现的自定义format函数
public static String format(String template, Object... parameters) {
for (int i = 0; i < parameters.length; i++) {
template = template.replace("{" + i + "}", parameters[i] + "");
}
return template;
}(3) Benchmark-Benchmark-Test
Mit Hilfe des Benchmark-Benchmark-Tools können Sie die Ausführungszeit Ihres Codes genauer messen. In Tabelle 1 verwenden wir JMH (Java Microbenchmark Harness), um zeitaufwändige Tests für drei String-Formatierungsmethoden und eine String-Spleißmethode durchzuführen. Die Testergebnisse zeigen, dass die String-Formatierung mit der Ersetzungsmethode von Java8 die schlechteste Leistung bringt, während die Verwendung der String-Splicing-Funktion von Apache die beste Leistung bringt.
Tabelle 1 Leistungsvergleich von String-Formatierung und Spleißen
Implementierung |
Durchschnittlicher Zeitaufwand (uns) für 1000. Ausführungen |
StringUtils .format implementiert mit Java8-Ersatz |
1988.982 |
StringUtils.format implementiert mit Apache-Ersatz |
656. 537 |
Java8 wird mit String geliefert. Format: 1417.474: 1417.474 |



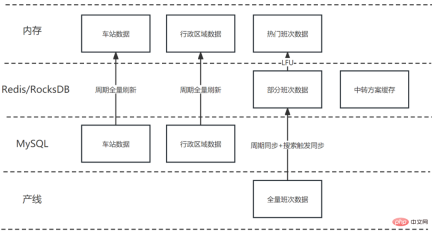
 Abbildung 10 Zusammenfassung der Spleißoptimierung des Transfertransportplans
Abbildung 10 Zusammenfassung der Spleißoptimierung des TransfertransportplansDas obige ist der detaillierte Inhalt vonOptimieren Sie die Verbindungsleistung des Transfertransportplans von Ctrip. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr