
Heim >Technologie-Peripheriegeräte >KI >Huang Bin, ein Experte für Forschung und Entwicklung der NetEase Cloud Music Algorithm Platform: Praxis und Gedanken zum NetEase Cloud Music Online Prediction System
Huang Bin, ein Experte für Forschung und Entwicklung der NetEase Cloud Music Algorithm Platform: Praxis und Gedanken zum NetEase Cloud Music Online Prediction System

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-10 19:21:011370Durchsuche
Gast |. Huang Bin
Zusammenstellung |. Tu Chengye
Kürzlich hielt Huang Bin, ein Experte für Forschung und Entwicklung der NetEase Cloud Music Algorithm Platform, eine Grundsatzrede „The Praxis des NetEase Cloud Music Online-Vorhersagesystems“ und Gedanken“ aus der Perspektive der Technologieforschung und -entwicklung werden verwandte Praktiken und Gedanken zum Aufbau eines leistungsstarken, benutzerfreundlichen und funktionsreichen Prognosesystems geteilt.
Der Inhalt der Rede ist nun wie folgt gegliedert, ich hoffe, Sie zu inspirieren.
Gesamtsystemarchitektur
Werfen wir zunächst einen Blick auf die Architektur des gesamten Vorhersagesystems, wie in der folgenden Abbildung dargestellt:
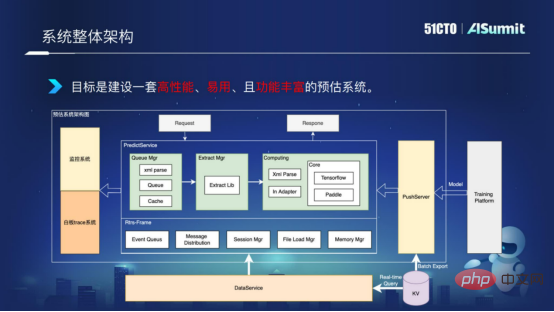
Gesamtsystemarchitektur
Der Vorhersageserver in der Mitte ist die Kernkomponente von das Vorhersagesystem, einschließlich Abfragekomponente, Merkmalsverarbeitungskomponente und Modellberechnungskomponente. Das Überwachungssystem auf der linken Seite dient der Überwachung von Leitungsnetzdiensten, um den reibungslosen Ablauf des Anlagennetzes sicherzustellen. Der PushServer auf der rechten Seite wird für den Modell-Push verwendet und überträgt das neueste Modell zur Vorhersage in das Online-Vorhersagesystem.
Ziel ist es, ein leistungsstarkes, benutzerfreundliches und funktionsreiches Prognosesystem aufzubauen.
Hochleistungsrechnen
Wie kann die Rechenleistung verbessert werden? Was sind unsere häufigsten Rechenleistungsprobleme? Ich werde sie unter drei Gesichtspunkten näher erläutern.
- Feature-Verarbeitung
In der allgemeinen Lösung werden unsere Feature-Berechnung und Modellberechnung in separaten Prozessen bereitgestellt, was dazu führt, dass eine große Anzahl von Features über Dienste und Sprachen hinweg übertragen wird, was zu mehreren Codierungen und Decodierungen sowie Speicherkopien führt , was zu einem relativ großen Leistungsaufwand führt.
- Modellaktualisierung
Wir wissen, dass bei der Aktualisierung des Modells große Typenblöcke angewendet und freigegeben werden. Bei einigen allgemeinen Lösungen ist jedoch keine Lösung zum Vorheizen des Modells enthalten, was zu einem relativ hohen zeitaufwändigen Jitter im Modellaktualisierungsprozess führt und keine Echtzeitaktualisierung des Modells unterstützen kann.
- Computing Scheduling
Allgemeine Frameworks verwenden einen Synchronisationsmechanismus, der eine unzureichende Parallelität und eine geringe CPU-Auslastung aufweist und hohe Anforderungen an die Parallelitätsberechnung nicht erfüllen kann.
Wie lösen wir also diese Leistungsengpässe im Vorhersagesystem?
1. Nahtlose Integration von Bibliotheken für maschinelles Lernen
Warum sollten wir so etwas tun? Denn wir alle wissen, dass bei herkömmlichen Lösungen die Funktionsverarbeitung und die Modellberechnung in separaten Prozessen bereitgestellt werden, was zu spezifischeren netzwerkübergreifenden Übertragungen, Serialisierung, Deserialisierung und häufigen Speicheranwendungen und -freigaben führt. Insbesondere wenn der Funktionsumfang der empfohlenen Szene besonders groß ist, führt dies zu einem erheblichen Leistungsaufwand. In der folgenden Abbildung zeigt das Flussdiagramm oben die spezifische Situation in der allgemeinen Lösung.
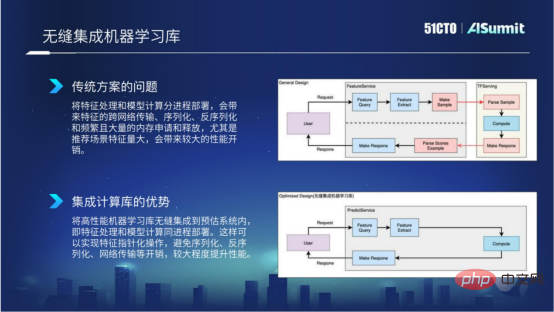
Nahtlose Integration der Computer-Lernbibliothek
Um die oben genannten Probleme zu lösen, integrieren wir das Hochleistungs-Computing-Lernframework in das Vorhersagesystem. Der Vorteil davon besteht darin, dass wir die Funktionsverarbeitung und Modellberechnung sicherstellen können kann im selben Prozess bereitgestellt werden, und die Feature-Operation kann in Form von Zeigern implementiert werden, wodurch der Overhead der Serialisierung, Deserialisierung und Netzwerkübertragung vermieden wird, wodurch eine bessere Rechenleistung bei der Feature-Berechnung und Feature-Verarbeitung erzielt wird. Das ist der Vorteil von Seamless Integration von maschinellem Lernen.
2. Überlegungen zum Architekturdesign
Zunächst übernimmt das gesamte System ein vollständig asynchrones Architekturdesign. Der Vorteil der asynchronen Architektur besteht darin, dass externe Aufrufe nicht blockieren und warten, sodass der asynchrone Mechanismus sicherstellen kann, dass die zeitaufwändige Stabilität des Netzwerkdienstes auch bei hoher CPU-Auslastung, beispielsweise 60 % bis 70 %, aufrechterhalten bleibt.
Zweitens Optimierung des Speicherzugriffs. Die Optimierung des Speicherzugriffs basiert hauptsächlich auf der NUMA-Architektur des Servers, und wir verwenden eine kerngebundene Betriebsmethode. Auf diese Weise können wir das Problem des Remote-Speicherzugriffs lösen, das in der vorherigen NUMA-Architektur bestand, und so die Rechenleistung unseres Dienstes verbessern.
Drittens paralleles Rechnen. Wir verarbeiten Rechenaufgaben in Slices und verwenden Multithread-Parallelität, um Berechnungen durchzuführen, was den Servicezeitverbrauch erheblich reduzieren und die Ressourcennutzung verbessern kann.
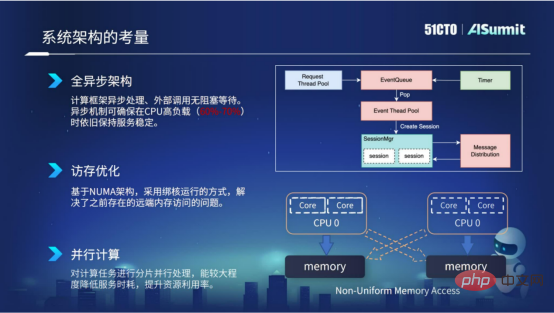
Überlegungen zum architektonischen Design
Das Obige ist unsere Praxis bei der Abschätzung der Überlegungen zur Systemarchitektur des Systems.
3. Mehrstufiges Caching
Mehrstufiges Caching wird hauptsächlich in der Feature-Abfragephase und der Primärphase verwendet. Der von uns gekapselte Caching-Mechanismus kann einerseits externe Aufrufe von Abfragen reduzieren und andererseits wiederholte ungültige Berechnungen aufgrund der Merkmalsextraktion reduzieren.
Durch Caching kann die Effizienz der Abfrage und Extraktion erheblich verbessert werden. Insbesondere in der Abfragephase kapseln wir eine Vielzahl von Komponenten basierend auf der Wichtigkeit der Features und der Größe der Features, z. B. synchrone Abfragen, asynchrone Abfragen und Batch-Import von Features.
Die erste ist die synchrone Abfrage, die hauptsächlich für einige wichtigere Funktionen geeignet ist. Natürlich ist die Leistung der synchronen Abfrage nicht so effizient.
Die zweite ist die asynchrone Abfrage, die hauptsächlich auf einige „Aite-Dimension“-Funktionen abzielt. Diese Funktionen sind möglicherweise nicht so wichtig, daher können Sie diese asynchrone Abfragemethode verwenden.
Die dritte Methode ist der Feature-Batch-Import, der hauptsächlich für Feature-Daten geeignet ist, deren Feature-Größe nicht besonders groß ist. Indem wir diese Features stapelweise in den Prozess importieren, können wir lokalisierte Abfragen von Features implementieren, und die Leistung ist sehr effizient.
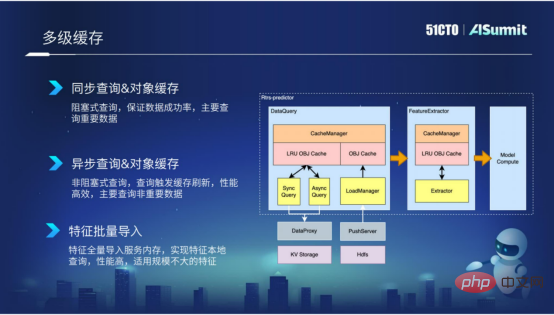
Mehrstufiger Cache
4. Modellberechnungsoptimierung
Nach der Einführung des Caching-Mechanismus Werfen wir einen Blick auf die Verhaltensoptimierung von Modellberechnungen. Für die Modellberechnung optimieren wir hauptsächlich unter drei Aspekten: Modelleingabeoptimierung, Modellladeoptimierung und Kerneloptimierung.
- Modelleingabeoptimierung
Im Modelleingabebereich weiß jeder, dass TF Servering die Eingabe von Beispiel verwendet. Die Beispieleingabe umfasst die Konstruktion von Beispiel, die Serialisierung und Deserialisierung von Beispiel sowie den Aufruf von Parse Beispiel innerhalb des Modells, was relativ zeitaufwändig ist.
Im Bild unten sehen wir uns den Screenshot von [Vor der Optimierung] an, um die Datenstatistiken vor der Modellberechnungsoptimierung anzuzeigen. Wir können sehen, dass es ein relativ langes Parse-Beispiel gibt, dessen Analyse sehr lange dauert. Bevor das Parse-Beispiel analysiert wird, können andere Operationen keine parallele Planung durchführen. Um das Leistungsproblem des Modellbaums zu lösen, haben wir eine leistungsstarke Modelleingabelösung in das Vorhersagesystem gekapselt. Durch die neue Lösung können wir erreichen, dass keine Kopie der Feature-Eingabe erfolgt, wodurch die zeitaufwändige Erstellung und Analyse dieses Beispiels reduziert wird.
Im Bild unten sehen wir uns den Screenshot von [Nach der Optimierung] an, um die Datenstatistik nach der Modellberechnungsoptimierung anzuzeigen. Wir können sehen, dass keine Parse-Beispiel-Analysezeit mehr vorhanden ist, sondern nur noch Beispiel . Die Analyse braucht Zeit.

Modellberechnungsoptimierung
- Modellladeoptimierung
Nachdem wir die Modelleingabeoptimierung eingeführt haben, werfen wir einen Blick auf die Modellladeoptimierung. Beim Modellladen von Tensorflow handelt es sich um einen Lazy-Loading-Modus. Nach dem internen Laden wird das Modell nicht vorgewärmt, bis eine formelle Anfrage vom Netzwerk eingeht wird zu ernsthaftem, zeitaufwändigem Jitter führen.
Um dieses Problem zu lösen, haben wir eine automatische Modellvorheizfunktion innerhalb des Vorhersagesystems, Hot-Switching zwischen dem alten und neuen Modell sowie asynchrones Entladen und Speicherfreigabe des alten Modells implementiert. Auf diese Weise wird durch einige Optimierungsmethoden zum Laden dieser Modelle die Aktualisierungsfähigkeit des Modells auf Minutenebene erreicht.
- Kerneloptimierung
Als nächstes werfen wir einen Blick auf die Optimierung des Modellkerns. Derzeit führen wir hauptsächlich eine Optimierung der Kernel-Synchronisierung am Tensorflow-Kernel durch und werden einige Thread-Pools zwischen Operationen und innerhalb von Operationen entsprechend dem Modell usw. anpassen.
Das Obige sind einige unserer Versuche, die Leistung in Modellberechnungen zu optimieren.
Nachdem wir den oben genannten Leistungsoptimierungsplan vorgestellt haben, werfen wir einen Blick auf die endgültigen Ergebnisse der Leistungsoptimierung.
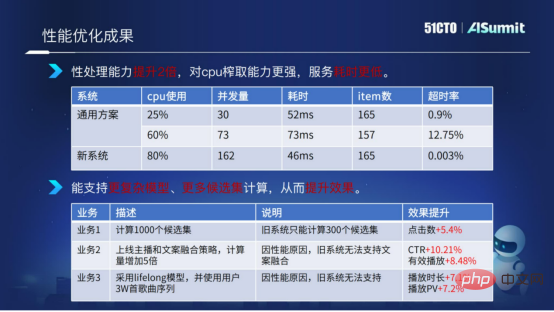
Ergebnisse der Leistungsoptimierung
Hier führen wir einen Vergleich unter Verwendung des Schätzsystems und des allgemeinen Lösungssystems durch. Wir können sehen, dass die Berechnungszeit und die Timeout-Rate des gesamten Dienstes sehr stabil und sehr niedrig sind, wenn die CPU-Auslastung des geschätzten Systems 80 % erreicht. Durch den Vergleich können wir den Schluss ziehen, dass die neue Lösung (Vorhersagesystem) in Bezug auf Berechnung und Verarbeitung die doppelte Leistung aufweist, über stärkere CPU-Extraktionsfunktionen verfügt und eine kürzere Servicezeit aufweist.
Dank unserer Optimierung des Systems können wir mehr Modellkomplexitätsberechnungen und mehr Kandidatenmengenberechnungen für Geschäftsalgorithmen bereitstellen.
Die obige Abbildung zeigt ein Beispiel. Der Kandidatensatz wurde von bisher 300 Kandidatensätzen auf 1000 Kandidatensätze erweitert. Gleichzeitig haben wir die Komplexität der Modellberechnung erhöht und einige komplexere Funktionen verwendet bzw. Es hat in mehreren Unternehmen zu besseren Ergebnissen geführt.
Das Obige ist eine Einführung in die Leistungsoptimierung und die Leistungsoptimierungsergebnisse des Schätzsystems.
So verbessern Sie die Entwicklungseffizienz
1. Systemschichtiges Design
Das System verwendet ein mehrschichtiges Architekturdesign. Wir unterteilen das gesamte Schätzsystem in drei Schichten, einschließlich der zugrunde liegenden Architekturschicht, der Zwischenvorlagenschicht und der oberen Strukturschicht.
Die zugrunde liegende Architekturschicht bietet hauptsächlich asynchrone Mechanismen, Aufgabenwarteschlangen, gleichzeitige Planung, Netzwerkkommunikation usw.
Die mittlere Vorlagenebene stellt hauptsächlich Komponenten im Zusammenhang mit der Modellberechnung bereit, einschließlich Abfrageverwaltung, Cache-Verwaltung, Modellladeverwaltung und Modellberechnungsverwaltung.
Die obere Schnittstellenschicht stellt hauptsächlich High-Level-Schnittstellen bereit. Unternehmen müssen nur diese Schichtschnittstelle implementieren, was die Codeentwicklung erheblich reduziert.
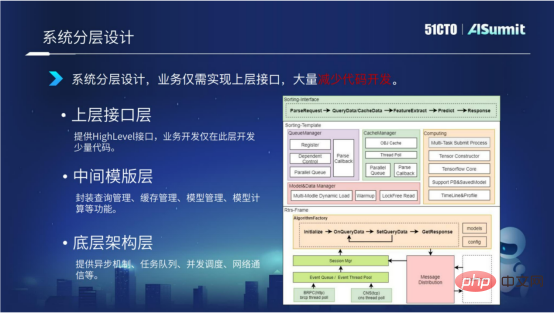
Durch das geschichtete Architekturdesign des Systems kann der Code der unteren und mittleren Schichten zwischen verschiedenen Unternehmen wiederverwendet werden. Die Entwicklung muss sich nur auf die Entwicklung einer kleinen Menge Code auf der oberen Schicht konzentrieren. Gleichzeitig denken wir auch weiter darüber nach, wie wir die Codeentwicklung der oberen Schnittstellenschicht weiter reduzieren können. Lassen Sie uns es unten im Detail vorstellen.
2. Universelle Abfragekapselung
Durch die Kapselung einer allgemeinen Lösung basierend auf Feature-Abfrage und Feature-Parsing basierend auf der dynamischen PB-Technologie können Features nur über den Namen der XML-Konfigurationstabelle, den Abfrageschlüssel, die Cache-Zeit, die Abfrageabhängigkeit usw. implementiert werden gesamter Prozess der Abfrage, Analyse und Zwischenspeicherung.
Wie in der Abbildung unten gezeigt, können wir mit wenigen Konfigurationszeilen eine komplexe Abfragelogik implementieren. Gleichzeitig wird die Abfrageeffizienz durch die Abfragekapselung verbessert.

3. Feature-Berechnungspaket
Man kann sagen, dass die Feature-Berechnung das Modul mit der höchsten Codeentwicklungskomplexität im gesamten Vorhersagesystem ist.
Die Merkmalsberechnung umfasst Offline-Prozess und Online-Prozess. Beim Offline-Prozess handelt es sich tatsächlich um Offline-Beispiele, die verarbeitet werden, um einige von der Offline-Trainingsplattform benötigte Formate zu erhalten, beispielsweise das Format von TF Recocd. Der Online-Prozess führt hauptsächlich einige Funktionsberechnungen für Online-Anfragen durch und erhält durch Verarbeitung einige Formate, die von der Online-Vorhersageplattform benötigt werden. Tatsächlich ist die Berechnungslogik für die Merkmalsverarbeitung im Offline-Prozess und im Online-Prozess genau gleich. Da jedoch die Computerplattformen des Offline-Prozesses und des Online-Prozesses unterschiedlich sind und die verwendeten Sprachen unterschiedlich sind, müssen mehrere Codesätze entwickelt werden, um die Merkmalsberechnung zu implementieren, sodass die folgenden drei Probleme auftreten.
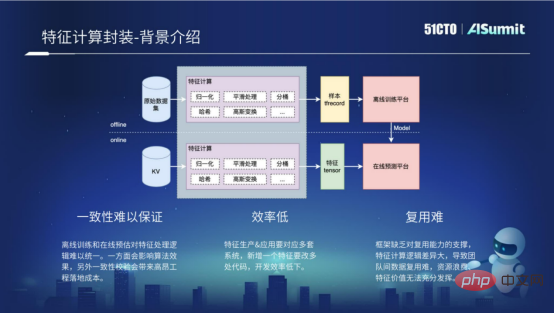
- Konsistenz ist schwer zu garantieren
Der Hauptgrund, warum Konsistenz schwer zu garantieren ist, besteht darin, dass es schwierig ist, die Funktionsverarbeitungslogik zwischen Offline-Training und Online-Vorhersage zu vereinheitlichen. Dies wirkt sich einerseits auf die Wirkung des Algorithmus aus und führt andererseits zu relativ hohen einmaligen Verifizierungskosten während des Entwicklungsprozesses.
- Geringe Effizienz
Wenn Sie eine neue Funktion hinzufügen möchten, müssen Sie mehrere Codesätze entwickeln, die Offline-Prozesse und Online-Prozesse umfassen, was zu einer sehr geringen Entwicklungseffizienz führt.
- Schwierigkeit bei der Wiederverwendung
Schwierigkeit bei der Wiederverwendung Der Hauptgrund ist, dass das Framework keine Wiederverwendungsfunktionen unterstützt, was die Wiederverwendung von Funktionsberechnungen zwischen verschiedenen Unternehmen sehr erschwert.
Die oben genannten sind einige Probleme mit dem Feature-Berechnungs-Framework.
Um diese Probleme zu lösen, werden wir sie schrittweise gemäß den folgenden vier Punkten lösen.
Zuerst schlagen wir das Konzept von Operatoren und abstrakten Merkmalsberechnungen in der Operatorkapselung vor. Zweitens erstellen wir nach der Kapselung des Operators eine Operatorbibliothek, die die Möglichkeit bietet, Operatoren zwischen Unternehmen wiederzuverwenden. Anschließend definieren wir die Merkmalsberechnungsbeschreibungssprache DSL basierend auf den Operatoren. Durch diese Beschreibungssprache können wir den Konfigurationsausdruck der Merkmalsberechnung vervollständigen. Schließlich müssen wir, wie bereits erwähnt, das Problem der einmaligen Funktionen lösen, da es im Online-Prozess und im Offline-Prozess mehrere Logiksätze gibt, die zu logischen Inkonsistenzen führen.
Die oben genannten vier Punkte sind unsere Ideen zur Kapselung des Feature-Berechnungs-Frameworks.

- Operatorabstraktion
Um die Operatorabstraktion zu realisieren, muss zunächst das Datenprotokoll vereinheitlicht werden. Wir verwenden die dynamische PB-Technologie, um jedes Feature anhand einheitlicher Daten basierend auf den Originaldateninformationen des Features zu verarbeiten. Dies stellt eine Datenbasis für unsere Operatorkapselung dar. Als Nächstes haben wir den Feature-Verarbeitungsprozess abgetastet und gekapselt, den Feature-Berechnungsprozess in Analyse-, Berechnungs-, Montage- und Ausnahmebehandlungsprozesse abstrahiert und die Berechnungsprozess-API vereinheitlicht, um eine Operatorabstraktion zu erreichen.
- Erstellen Sie eine Operatorbibliothek
Nachdem wir die Operatoren abstrahiert haben, können wir eine Operatorbibliothek erstellen. Die Operator-Bibliothek ist in eine allgemeine Plattform-Operator-Bibliothek und eine geschäftsspezifische Operator-Bibliothek unterteilt. Die allgemeine Operatorbibliothek der Plattform wird hauptsächlich verwendet, um eine Wiederverwendung auf Unternehmensebene zu erreichen. Die benutzerdefinierte Operatorbibliothek für Unternehmen ist hauptsächlich auf einige benutzerdefinierte Szenarien und Merkmale des Unternehmens ausgerichtet, um eine Wiederverwendung innerhalb der Gruppe zu erreichen. Durch die Kapselung von Operatoren und den Aufbau von Operatorbibliotheken realisieren wir die Wiederverwendung von Feature-Berechnungen in mehreren Szenarien und verbessern die Entwicklungseffizienz.
- Berechnungsbeschreibungssprache DSL
Der konfigurierte Ausdruck der Merkmalsberechnung bezieht sich auf die konfigurierte Sprache, die den Merkmalsberechnungsausdruck namens DSL definiert. Durch die Konfigurationssprache können wir mehrstufige verschachtelte Operatorausdrücke, vier arithmetische Operationen usw. realisieren. Der erste Screenshot unten zeigt die spezifische Syntax der konfigurierten Sprache.

Welche Vorteile können wir durch die Konfigurationssprache der Feature-Berechnung bringen?
Zuerst können wir die gesamte Funktionsberechnung durch Konfiguration abschließen und so die Entwicklungseffizienz verbessern.
Zweitens können wir Hot-Updates von Feature-Berechnungen erreichen, indem wir konfigurierte Ausdrücke von Feature-Berechnungen veröffentlichen.
Drittens verwenden Training und Vorhersage dieselbe Funktionsberechnungskonfiguration, um Online- und Offline-Konsistenz zu erreichen.
Dies ist der Vorteil, den der Merkmalsberechnungsausdruck mit sich bringt.
- Feature-Konsistenz
Wie bereits erwähnt, ist die Feature-Berechnung in Offline-Prozess und Online-Prozess unterteilt. Aufgrund der Multiplattform-Gründe von Offline und Online ist die logische Berechnung inkonsistent. Um dieses Problem zu lösen, haben wir die plattformübergreifende Lauffähigkeit des Feature-Computing-Frameworks im Feature-Computing-Framework implementiert. Die Kernlogik wird in C++ entwickelt und die C++-Schnittstelle und die Java-Schnittstelle werden der Außenwelt zugänglich gemacht. Während des Paketierungs- und Erstellungsprozesses können die C++-Bibliothek und das JAR-Paket mit einem Klick implementiert werden, wodurch sichergestellt wird, dass die Feature-Berechnung auf der C++-Plattform für Online-Berechnungen und auf der Offline-Spark-Plattform oder Flink-Plattform ausgeführt und ausgedrückt werden kann Feature-Berechnung, um sicherzustellen, dass Feature-Berechnung die Konsistenz der Online- und Offline-Logik erreicht.
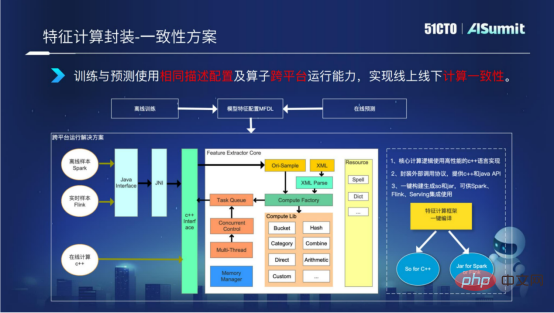
Das Obige beschreibt die spezifische Situation der Merkmalsberechnung. Werfen wir einen Blick auf einige der Ergebnisse, die Feature Computing bisher erzielt hat.
Mittlerweile haben wir Betreiber aus 120 Unternehmen zusammengetragen. Durch die DSL-Sprache zur Funktionsberechnung können wir die Konfiguration realisieren und die gesamte Funktionsberechnung abschließen. Durch die von uns bereitgestellten plattformübergreifenden Betriebsfunktionen wird das Problem der Online- und Offline-Logikinkonsistenz gelöst.
Der Screenshot unten zeigt, dass mit einem geringen Konfigurationsaufwand der gesamte Feature-Berechnungsprozess realisiert werden kann, was die Entwicklungseffizienz der Feature-Berechnung erheblich verbessert.

Das Obige stellt unsere Untersuchung zur Verbesserung der Entwicklungseffizienz vor. Im Allgemeinen können wir die Wiederverwendbarkeit von Code durch das hierarchische Design des Systems verbessern und durch die Kapselung von Abfragen, Extraktionen und Modellberechnungen einen konfigurierbaren Entwicklungsprozess erreichen.
4. Modellberechnungskapselung
Die Modellberechnung erfolgt ebenfalls in Form einer Kapselung. Durch die Form des Konfigurationsausdrucks werden das Laden des Modells, die Eingabestruktur des Modells, die Berechnung des Modells usw. realisiert. Mithilfe einiger Konfigurationszeilen wird der Ausdrucksprozess der gesamten Modellberechnung realisiert.

Echtzeitimplementierung des Modells
Werfen wir einen Blick auf einen Fall der Echtzeitimplementierung des Modells.
1. Hintergrund eines Echtzeitprojekts
Warum wollen wir so ein Modell-Echtzeitprojekt machen?
Der Hauptgrund dafür ist, dass das traditionelle Empfehlungssystem ein System ist, das die Ergebnisse der Benutzerempfehlungen täglich aktualisiert. Seine Echtzeitleistung ist sehr schlecht und kann solche Szenarien mit hohen Echtzeitanforderungen, wie beispielsweise unsere Live-Übertragungsszenarien, nicht erfüllen oder andere Echtzeitszenarien mit relativ hohen Anforderungen.
Ein weiterer Grund ist, dass bei der herkömmlichen Musterherstellungsmethode das Problem der Merkmalsüberschneidung besteht. Was ist Feature-Crossing? Die folgende Abbildung zeigt den grundlegenden Grund für das Überkreuzen von Merkmalen. Beim Probenspleißen verwenden wir die vom Modell geschätzte Struktur zum Zeitpunkt „T-1“ und verbinden sie mit den Merkmalen zum Zeitpunkt „T“. Kreuzung wird entstehen. Das Überqueren von Merkmalen hat großen Einfluss auf die Wirkung der Leitungsnetzempfehlung. Um das Echtzeitproblem und das Problem der Probenkreuzung zu lösen, haben wir eine solche Modell-Echtzeitlösung im Vorhersagesystem implementiert.
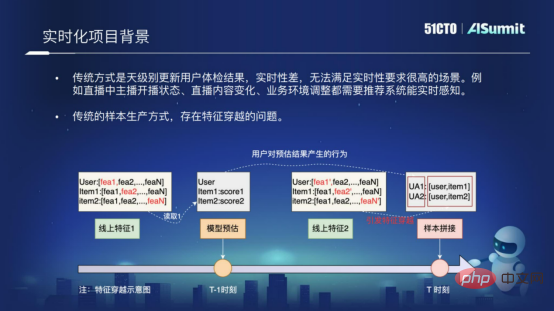
2. Einführung in die Echtzeitlösung
Die Modell-Echtzeitlösung wird aus drei Dimensionen erklärt.
- Echtzeitgenerierung von Stichproben
- Inkrementelles Modelltraining
- Echtzeitvorhersagesystem
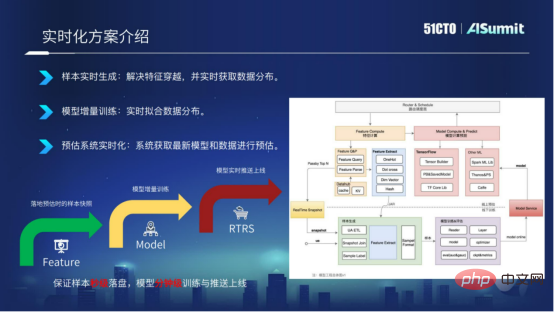
Samples werden in Echtzeit generiert. Basierend auf dem Online-Vorhersagesystem implementieren wir die Funktionen des Vorhersagesystems in Echtzeit in Kafka und verknüpfen sie in Form einer RACE-ID. Auf diese Weise können wir sicherstellen, dass Proben innerhalb von Sekunden auf der Festplatte platziert werden und das Problem lösen können Merkmalskreuzung.
Modelliertes inkrementelles Training. Nachdem die Proben in Sekundenschnelle auf der Festplatte platziert wurden, können wir das Trainingsmodul ändern, um ein inkrementelles Training des Modells zu implementieren und Aktualisierungen des Modells auf Minutenebene zu erreichen.
Das Vorhersagesystem ist in Echtzeit. Nachdem wir das Modell auf Minutenebene exportiert haben, übertragen wir das neueste Modell über den Modell-Push-Dienst Push Server an das Online-Vorhersagesystem, wodurch das Vor-Ort-Vorhersagesystem das neueste Modell für die Vorhersage verwenden kann.
Im Allgemeinen besteht die Echtzeit-Modelllösung darin, eine Probenplatzierung in Sekunden, ein Training auf Minutenebene und eine Online-Aktualisierung des Modells auf Minutenebene zu erreichen.
Unsere aktuelle Modell-Echtzeitlösung wurde in mehreren Szenarien implementiert. Durch die Echtzeit-Modelllösung konnten die Geschäftsergebnisse deutlich verbessert werden.
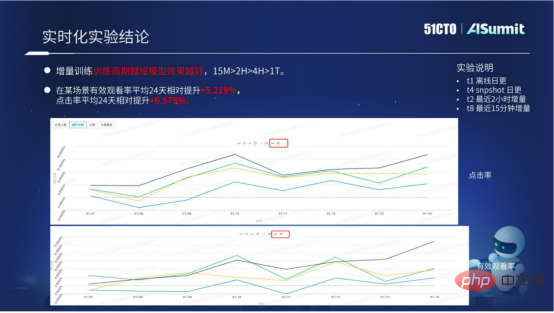
Die obige Abbildung zeigt hauptsächlich die spezifischen experimentellen Daten der Modell-Echtzeitlösung. Wir können inkrementelles Training sehen: Je kürzer die Trainingsdauer, desto besser. Anhand spezifischer Daten können wir erkennen, dass die Wirkung eines Zyklus von 15 Minuten weitaus größer ist als die von 2 Stunden, 10 Stunden oder einem Tag. Das aktuelle Modell der Echtzeitlösung verfügt bereits über einen standardisierten Zugriffsprozess, der dem Unternehmen stapelweise bessere Ergebnisse bringen kann.
Das Obige stellt die Erforschung und Versuche in drei Aspekten vor: wie das Vorhersagesystem die Rechenleistung verbessert, wie die Entwicklungseffizienz verbessert werden kann und wie Projektalgorithmen durch technische Mittel verbessert werden können.
Der Plattformwert des gesamten Schätzungssystems oder der Plattformzweck des gesamten Schätzungssystems lässt sich in drei Worten zusammenfassen: „schnell, gut und wirtschaftlich“.
„Schnell“ bezieht sich auf die zuvor vorgestellte angewandte Konstruktion. Wir hoffen, dass die Geschäftsiteration durch kontinuierliche Anwendungskonstruktion effizienter sein kann.
„Gut“ bedeutet, dass wir hoffen, dass wir durch technische Mittel, wie Echtzeit-Modelllösungen und logische Online- und Offline-Konsistenzlösungen durch Merkmalsberechnung, bessere Ergebnisse für das Unternehmen erzielen können.
„Speichern“ bedeutet, die höhere Leistung des geschätzten Systems zu nutzen, wodurch mehr Rechenressourcen und Rechenkosten eingespart werden können.
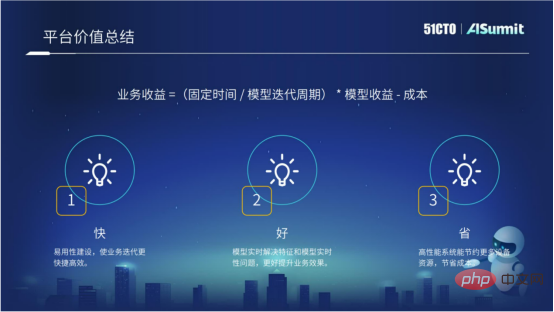
Auch in Zukunft werden wir weiterhin auf diese drei Ziele hinarbeiten.
Das Obige ist meine Einführung in das Cloud-Musikvorhersagesystem. Mein Teilen endet hier, vielen Dank an alle!
Das obige ist der detaillierte Inhalt vonHuang Bin, ein Experte für Forschung und Entwicklung der NetEase Cloud Music Algorithm Platform: Praxis und Gedanken zum NetEase Cloud Music Online Prediction System. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr